
目标网站:https://quote.eastmoney.com/center/gridlist.html#hs_a_board
需求:将东方财富网行情中心不同板块的股票数据爬取下来
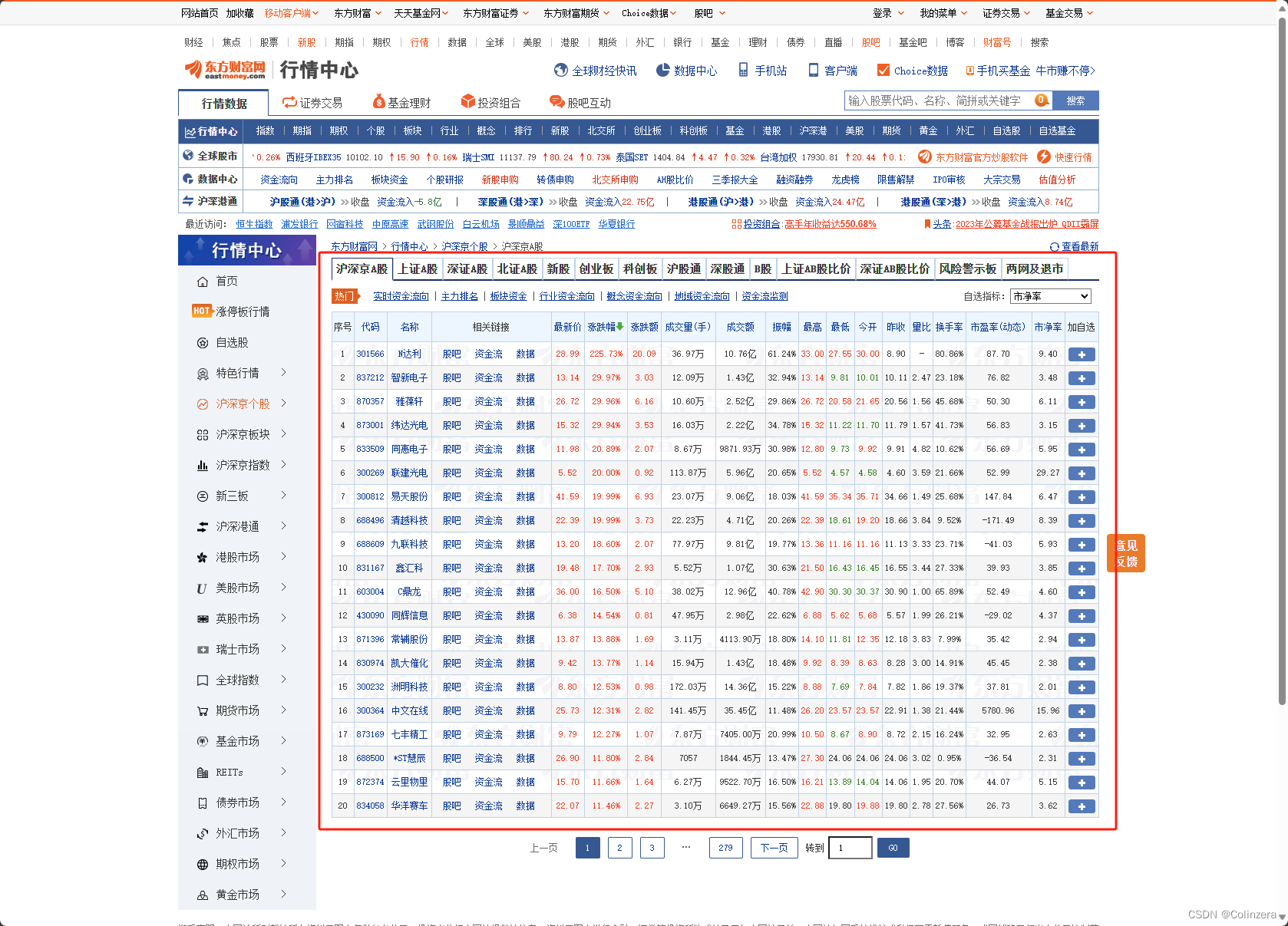
目标是将各个选项卡的股票数据全部爬取并以excel文件保存在本地。
查看网页源代码发现并没有目标数据,因此需要对网页进行抓包分析,查看哪个文件里包含目标数据,打开开发者模式(F12),找到目标文件
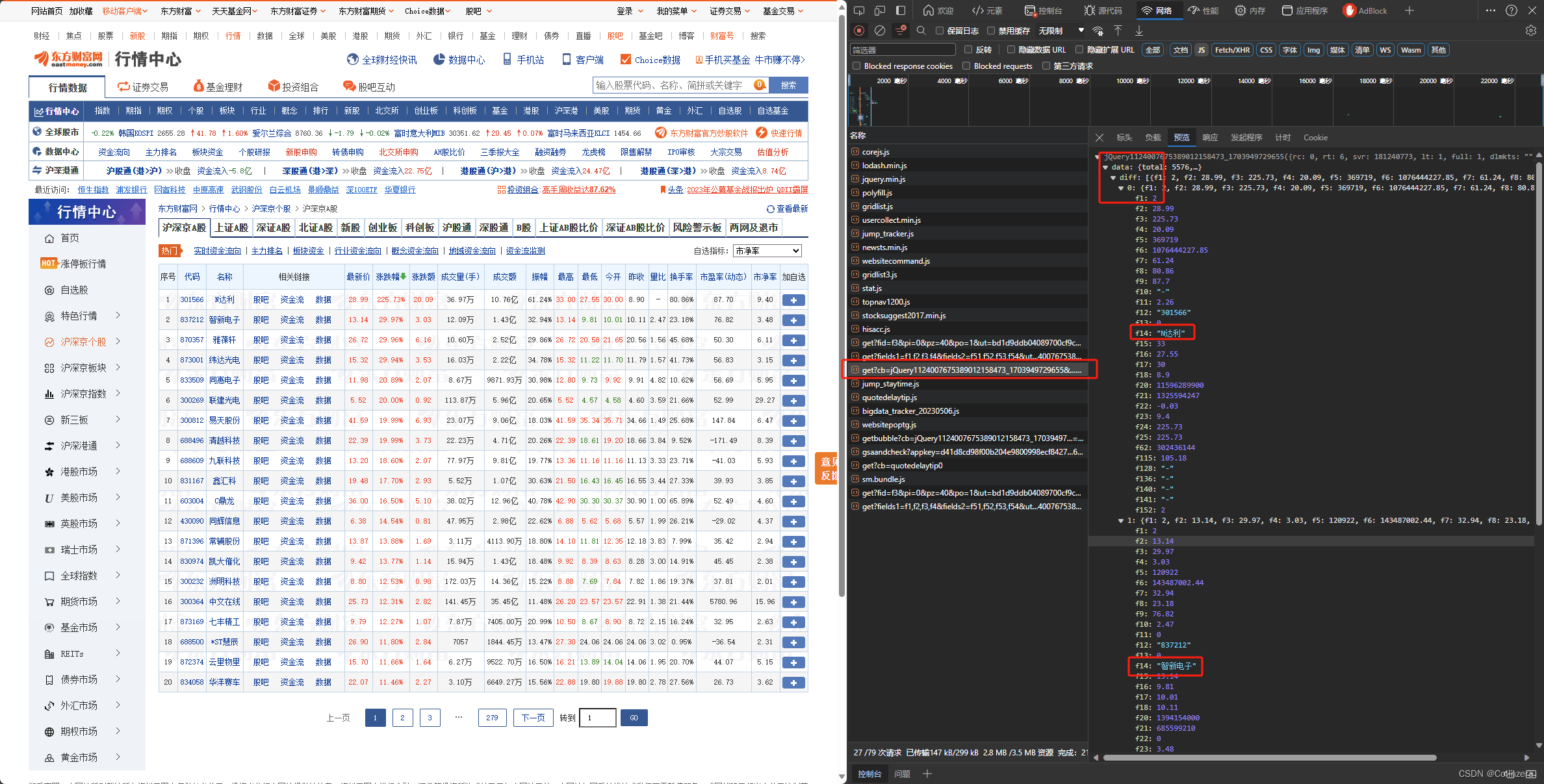
首先查看url,获取沪京深A股的第一页数据
# 沪深京A股
url = "https://62.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124007675389012158473_1703949729655&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1703949729656"
访问形式为GET
查看预览,发现需要爬取的数据在文件的‘data’中的'diff'里面,对应的文件数据如下图所示:
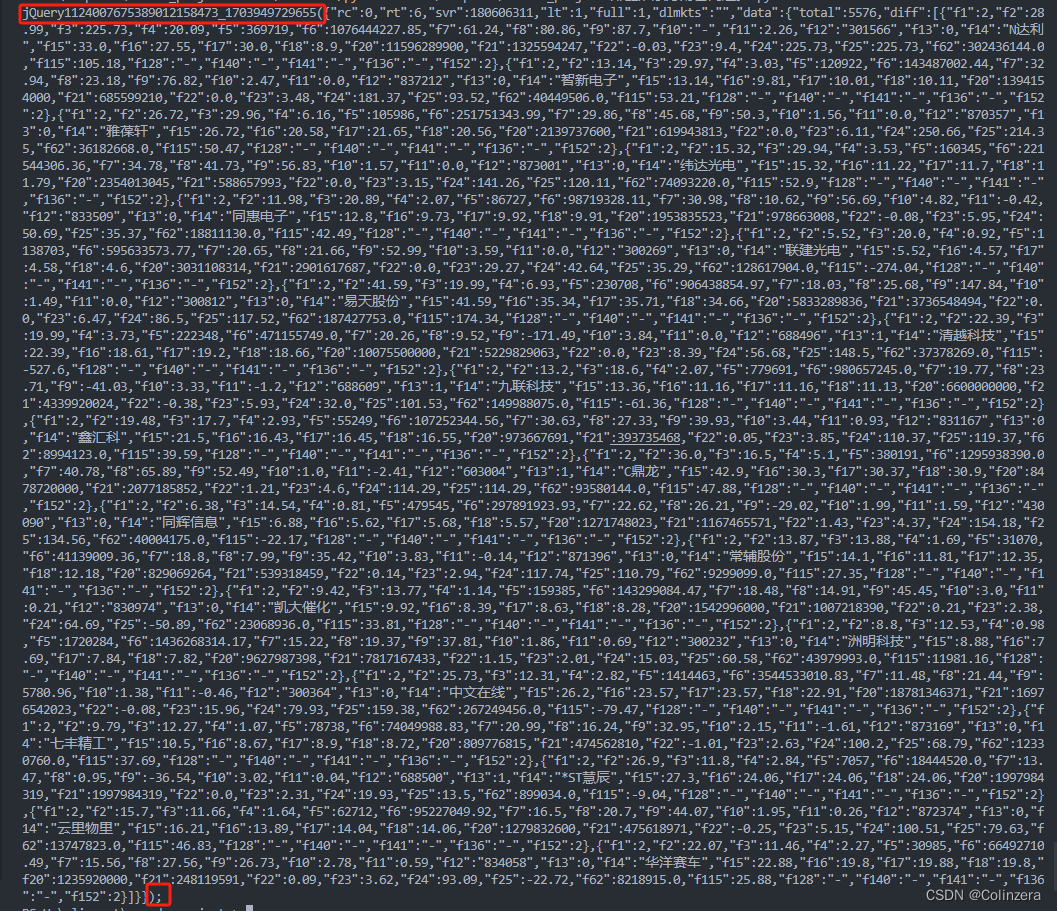
通过观察发现,该数据无法直接转换成json文件,需要删除上图中的红框内容,需要用正则表达式替换成空字符串
data = response.text
# 找到开头到第一个'('的部分
left_data = re.search(r'^.*?(?=\()', data).group()
# 将匹配到的内容加上'('替换成空字符串
data = re.sub(left_data + '\(', '', data)
# 将结尾的');'替换成空字符串
data = re.sub('\);', '', data)
# 用eval将data转换成字典
data = eval(data)
注意:这里在匹配开头内容时,如果使用下面的语句直接匹配到'jQuery1124007675389012158473_1703949729655('再进行替换的话会出现错误
left_data = re.search(r'^.*?\(', data).group()
print(left_data)
data = re.sub(left_data, '', data)
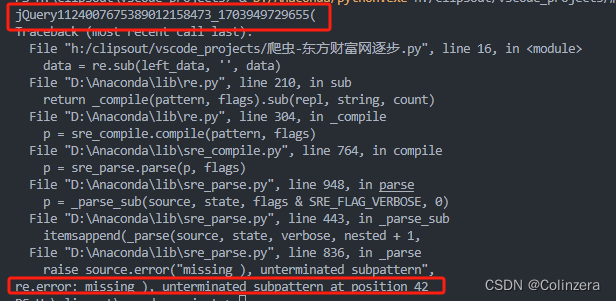
出现这个错误的原因是出现了圆括号但是没有转义,导致被当成捕获组,将括号转义(前面加上斜杠)即可解决。因此需要先匹配出'('之前的部分,在替代文本里拼接上'('才能进行成功替换。
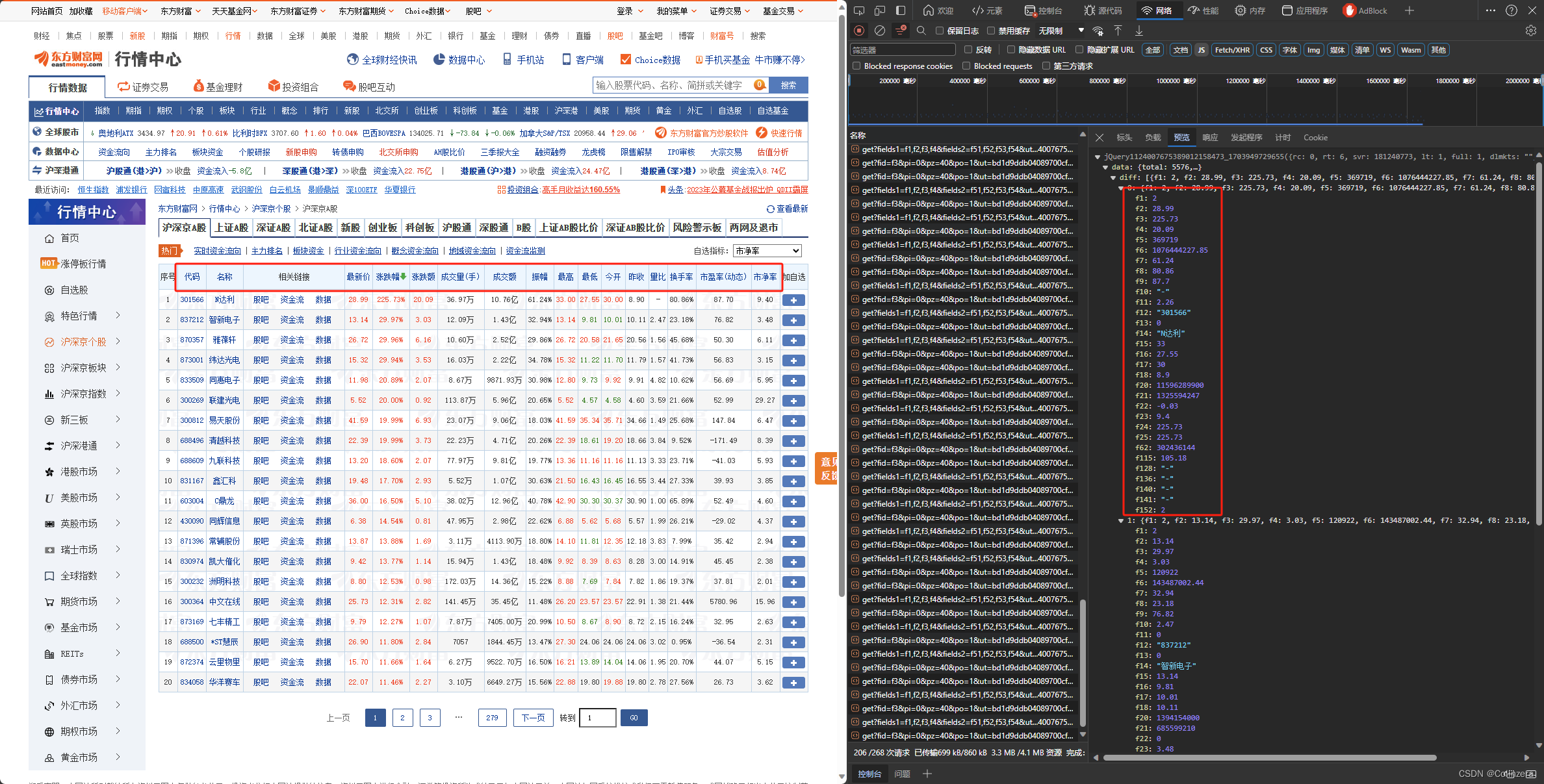
将目标数据转换成字典类型后,我们需要提取出其中data下面diff的内容,并通过定义一个字典来存储我们需要的数据,通过观察网页表头和文件代码对应关系,定义以下的字典:
df = data['data']['diff']
for index in df:
dict = {
"代码": index["f12"],
"名称": index['f14'],
"最新价": index['f2'],
"涨跌幅": index['f3'],
"涨跌额": index['f4'],
"成交量(手)": index['f5'],
"成交额": index['f6'],
"振幅(%)": index['f7'],
"最高": index['f15'],
"最低": index['f16'],
"今开": index['f17'],
"昨收": index['f18'],
"量比": index['f10'],
"换手率": index['f8'],
"市盈率(动态)": index['f9'],
"市净率": index['f23'],
}
同时通过翻页和选其他板块来观察url,发现规律如下图:
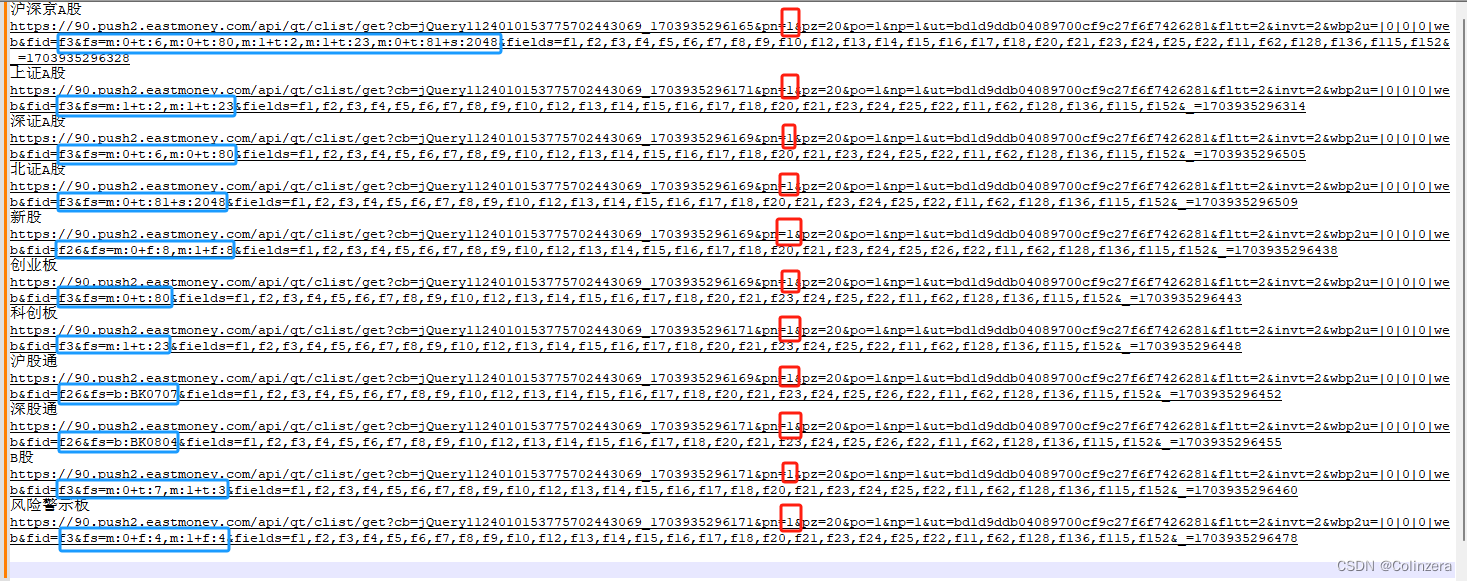 红框为页码数,蓝色代码部分为对应的不同板块,因此定义一个字典来保存各个板块的代码,用于循环抓取:
红框为页码数,蓝色代码部分为对应的不同板块,因此定义一个字典来保存各个板块的代码,用于循环抓取:
cmd = {
"沪深京A股": "f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048",
"上证A股": "f3&fs=m:1+t:2,m:1+t:23",
"深证A股": "f3&fs=m:0+t:6,m:0+t:80",
"北证A股": "f3&fs=m:0+t:81+s:2048",
"新股": "f26&fs=m:0+f:8,m:1+f:8",
"创业板": "f3&fs=m:0+t:80",
"科创板": "f3&fs=m:1+t:23",
"沪股通": "f26&fs=b:BK0707",
"深股通": "f26&fs=b:BK0804",
"B股": "f3&fs=m:0+t:7,m:1+t:3",
"风险警示板": "f3&fs=m:0+f:4,m:1+f:4",
}
在爬取时,需要判定何时停止爬取当前板块,下图显示沪深京A股有279页,我们通过修改url中的页码字段为280来查看返回什么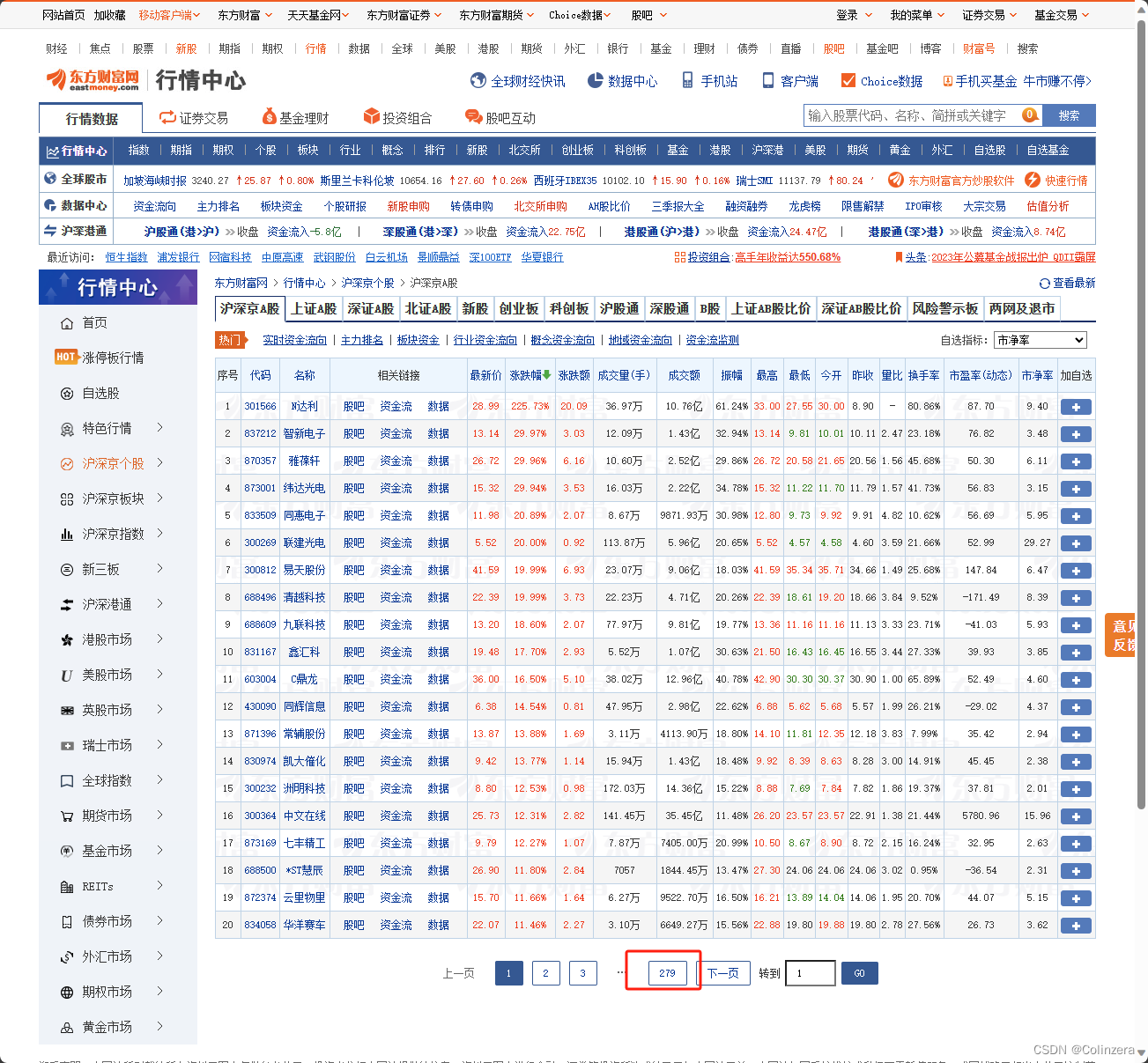

可以看到返回的文件中,data后为null,因此,在每个板块循环爬取时,只要碰到页码的返回文件中data的内容为null时,则停止爬取当前板块。同时由于返回文件中,data后的内容是以null变量的形式展示的,我们需要定义一个变量null,否则会出现报错NameError: name 'null' is not defined
null = "null"
for i in cmd.keys():
page = 0
stocks = []
while True:
page += 1
data = get_html(cmd[i], page)
if data['data'] != null:
print("正在爬取"+i+"第"+str(page)+"页")
df = data['data']['diff']
for index in df:
dict = {
"代码": index["f12"],
"名称": index['f14'],
"最新价": index['f2'],
"涨跌幅": index['f3'],
"涨跌额": index['f4'],
"成交量(手)": index['f5'],
"成交额": index['f6'],
"振幅(%)": index['f7'],
"最高": index['f15'],
"最低": index['f16'],
"今开": index['f17'],
"昨收": index['f18'],
"量比": index['f10'],
"换手率": index['f8'],
"市盈率(动态)": index['f9'],
"市净率": index['f23'],
}
stocks.append(dict)
else:
break
df = pd.DataFrame(stocks)
df.to_excel("股票_"+i+".xlsx", index=False)
执行结果如下:
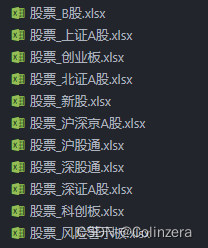
完整源代码:
import requests
import re
import pandas as pd
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Cookie": "qgqp_b_id=18c28b304dff3b8ce113d0cca03e6727; websitepoptg_api_time=1703860143525; st_si=92728505415389; st_asi=delete; HAList=ty-100-HSI-%u6052%u751F%u6307%u6570; st_pvi=46517537371152; st_sp=2023-10-29%2017%3A00%3A19; st_inirUrl=https%3A%2F%2Fcn.bing.com%2F; st_sn=8; st_psi=20231229230312485-113200301321-2076002087"
}
def get_html(cmd, page):
url = f"https://7.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409467675731682619_1703939377395&pn={page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid={cmd}&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1703939377396"
response = requests.get(url, headers=header)
data = response.text
left_data = re.search(r'^.*?(?=\()', data).group()
data = re.sub(left_data + '\(', '', data)
# right_data = re.search(r'\)', data).group()
data = re.sub('\);', '', data)
data = eval(data)
return data
cmd = {
"沪深京A股": "f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048",
"上证A股": "f3&fs=m:1+t:2,m:1+t:23",
"深证A股": "f3&fs=m:0+t:6,m:0+t:80",
"北证A股": "f3&fs=m:0+t:81+s:2048",
"新股": "f26&fs=m:0+f:8,m:1+f:8",
"创业板": "f3&fs=m:0+t:80",
"科创板": "f3&fs=m:1+t:23",
"沪股通": "f26&fs=b:BK0707",
"深股通": "f26&fs=b:BK0804",
"B股": "f3&fs=m:0+t:7,m:1+t:3",
"风险警示板": "f3&fs=m:0+f:4,m:1+f:4",
}
null = "null"
for i in cmd.keys():
page = 0
stocks = []
while True:
page += 1
data = get_html(cmd[i], page)
if data['data'] != null:
print("正在爬取"+i+"第"+str(page)+"页")
df = data['data']['diff']
for index in df:
dict = {
"代码": index["f12"],
"名称": index['f14'],
"最新价": index['f2'],
"涨跌幅": index['f3'],
"涨跌额": index['f4'],
"成交量(手)": index['f5'],
"成交额": index['f6'],
"振幅(%)": index['f7'],
"最高": index['f15'],
"最低": index['f16'],
"今开": index['f17'],
"昨收": index['f18'],
"量比": index['f10'],
"换手率": index['f8'],
"市盈率(动态)": index['f9'],
"市净率": index['f23'],
}
stocks.append(dict)
else:
break
df = pd.DataFrame(stocks)
df.to_excel("股票_"+i+".xlsx", index=False)
版权归原作者 Colinzera 所有, 如有侵权,请联系我们删除。