
大家好,今天和各位分享一下如何使用 Pytorch 构建 Transformer 模型。
本文的重点在代码复现,部分知识点介绍的不多,我会在之后的四篇博文中详细介绍 Encoder,Decoder,(Mask)MutiHeadAttention,以及实战案例。
之前我也介绍过Vision Tranformer,该模型的 Pytorch 和 TensorFlow2 的复现和实战案例可以看我的这两篇博文:
https://blog.csdn.net/dgvv4/article/details/124792386
https://blog.csdn.net/dgvv4/article/details/125184340
1. 引言
在传统的记忆网络中,RNN 模型,LSTM 模型以及 GRU 模型三个模型都是时序模型,对于每一个句子只能串行运行而不能并行,限制了模型的速度,而且虽然在一定程度上解决了长期依赖问题,但是对于跨度特别长的依赖还是没有很好的解决。
Transformer 模型内的每一个单词都可以并行的与其他单词计算Self-Attention值,并且在计算时不会受到距离过远的影响。Transformer 模型是一个序列到序列的模型,它由两个部分组成,分别是编码器和解码器。Transformer 也是一种基于注意力机制的架构,能够利用对文本的注意力权重来提取重要讯息。Transformer 具有可以并行处理顺序数据的特点,所以,它不但速度比以前的体系结构快,而且,在处理长期依赖性方面也十分优秀。
2. Muti_head_attention
自注意力层的主要功能是收集到有关句子的上下文的语意信息。
对于一个输入,自注意力机制首先会将 Embedding 向量与随机矩阵计算乘积得到三个向量矩阵,分别是 查询 Q(Query)、键 K(key)、值 V(value)权重矩阵。之后根据这三个向量矩阵计算自注意力的分数值。
计算过程如下:首先,将 Q 与 K 做点乘;之后将点乘的结果除以一个常数 ,目的是为了保证计算的稳定性;然后把得到的结果经过 Softmax 层进行计算;最后,将 Softmax 的输出结果与 V 矩阵进行相乘,得到该点的注意力分数。具体公式如下:
其中 Q,K 和 V 是由输入词向量构成的矩阵,dk 是输入词向量的维数。计算过程如下图所示:
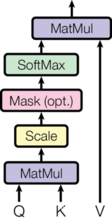
从实质上可以了解,注意力机制从大量的数据中有过滤出了一些可用的关键信息,因而集中于这部分关键信息上,而忽略了这些无用的不重要的内容。softmax 计算后的权重越大,注意力就越集中在其相应的 Value 值上,即权重就代表了数据的意义,而 Value 值也就是与它意义相对应的数据。
Transformer 模型所采用是并不是单一的自注意力机制,而是多头注意力机制。通俗的解释就是说对于一个输入向量,不仅仅只初始化一组 Q、K、V 的矩阵,而是初始化多组,最终得到多组向量矩阵,不同的头可以表示不同的语义信息,示意图如下:
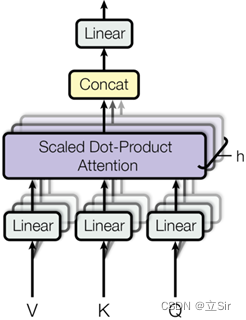
Transformer 模型中采用了 8 组权重矩阵,也就是 8 个注意力头。为了满足前馈层输入要求,定义一个权重矩阵 W0 与 8 组权重矩阵相乘,对模型进行联合训练。最终将融合所有注意力头信息的矩阵送入前馈层进行下一步的计算。
多头注意力计算公式如下,其中 、
、
是 Q、K、V 矩阵的参数矩阵,
是附加矩阵。
代码如下:
import torch
from torch import nn
# -------------------------------------------------- #
#(1)muti_head_attention
# -------------------------------------------------- #
'''
embed_size: 每个单词用多少长度的向量来表示
heads: 多头注意力的heads个数
'''
class selfattention(nn.Module):
def __init__(self, embed_size, heads):
super(selfattention, self).__init__()
self.embed_size = embed_size
self.heads = heads
# 每个head的处理的特征个数
self.head_dim = embed_size // heads
# 如果不能整除就报错
assert (self.head_dim * self.heads == self.embed_size), 'embed_size should be divided by heads'
# 三个全连接分别计算qkv
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
# 输出层
self.fc_out = nn.Linear(self.head_dim * self.heads, embed_size)
# 前向传播 qkv.shape==[b,seq_len,embed_size]
def forward(self, values, keys, query, mask):
N = query.shape[0] # batch
# 获取每个句子有多少个单词
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# 维度调整 [b,seq_len,embed_size] ==> [b,seq_len,heads,head_dim]
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
# 对原始输入数据计算q、k、v
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# 爱因斯坦简记法,用于张量矩阵运算,q和k的转置矩阵相乘
# queries.shape = [N, query_len, self.heads, self.head_dim]
# keys.shape = [N, keys_len, self.heads, self.head_dim]
# energy.shape = [N, heads, query_len, keys_len]
energy = torch.einsum('nqhd, nkhd -> nhqk', [queries, keys])
# 是否使用mask遮挡t时刻以后的所有q、k
if mask is not None:
# 将mask中所有为0的位置的元素,在energy中对应位置都置为 -1*10^10
energy = energy.masked_fill(mask==0, torch.tensor(-1e10))
# 根据公式计算attention, 在最后一个维度上计算softmax
attention = torch.softmax(energy/(self.embed_size**(1/2)), dim=3)
# 爱因斯坦简记法矩阵元素,其中query_len == keys_len == value_len
# attention.shape = [N, heads, query_len, keys_len]
# values.shape = [N, value_len, heads, head_dim]
# out.shape = [N, query_len, heads, head_dim]
out = torch.einsum('nhql, nlhd -> nqhd', [attention, values])
# 维度调整 [N, query_len, heads, head_dim] ==> [N, query_len, heads*head_dim]
out = out.reshape(N, query_len, self.heads*self.head_dim)
# 全连接,shape不变
out = self.fc_out(out)
return out
3. Muti_head_attention + FFN
前馈神经网络(Feed Forward Network,FFN)的作用主要是提供非线性变换,将多头注意力层的输出结果映射到更高维度的空间中。公式如下,可以看出就是先经过一个线性变换,再经过一个RELU激活函数,然后再经过一个线性变换。
在 Transformer 模型中,每一个子层之后都会有一个残差模块,并且有一个层归一化计算(Layer Normalization,LN)。残差模块****的作用主要是为了解决随着网络深度的增加梯度不稳定的问题。归一化****的作用主要是防止梯度消失或者梯度爆炸,加速模型收敛。Transformer 模型中采用的是层归一化方法,计算公式如下:
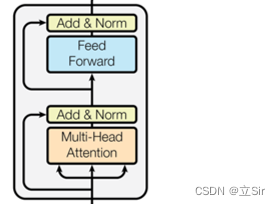
该部分代码对应的结构图如下:
# -------------------------------------------------- #
#(2)multi_head_attention + FFN
# -------------------------------------------------- #
'''
embed_size: wordembedding之后, 每个单词用多少长度的向量来表示
heads: 多头注意力的heas个数
drop: 杀死神经元的概率
forward_expansion: 在FFN中第一个全连接上升特征数的倍数
'''
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, dropout, forward_expansion):
super(TransformerBlock, self).__init__()
# 实例化自注意力模块
self.attention = selfattention(embed_size, heads)
# muti_head之后的layernorm
self.norm1 = nn.LayerNorm(embed_size)
# FFN之后的layernorm
self.norm2 = nn.LayerNorm(embed_size)
# 构建FFN前馈型神经网络
self.feed_forward = nn.Sequential(
# 第一个全连接层上升特征个数
nn.Linear(embed_size, embed_size * forward_expansion),
# relu激活
nn.ReLU(),
# 第二个全连接下降特征个数
nn.Linear(embed_size * forward_expansion, embed_size)
)
# dropout层随机杀死神经元
self.dropout = nn.Dropout(dropout)
# 前向传播, qkv.shape==[b,seq_len,embed_size]
def forward(self, value, key, query, mask):
# 计算muti_head_attention
attention = self.attention(value, key, query, mask)
# 输入和输出做残差连接
x = query + attention
# layernorm标准化
x = self.norm1(x)
# dropout
x = self.dropout(x)
# FFN
ffn = self.feed_forward(x)
# 残差连接输入和输出
forward = ffn + x
# layernorm + dropout
out = self.dropout(self.norm2(forward))
return out
4. Encoder
该部分代码对应的网络结构如下图所示,Encoder 部分堆叠了多个 TransformerBlock(Muti_head_attention 和 FFN)。输入的序列先经过 WordEmbedding,将句子中的每个单词用长度为 embed_size 的向量来表示。
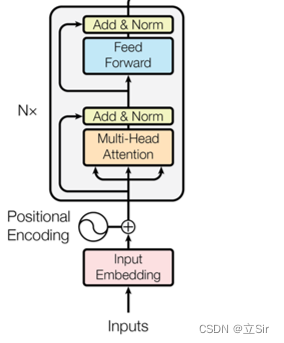
由于注意力机制更多的是关注词与词之间的重要程度,而不关心句子中词语位置的顺序关系。
例如:从北京开往济南的列车”与“从济南开往北京的列车”,词向量表示并不能对两句话中的“北京”进行区分,其编码是一样的。但是在真实语境中,两个词语所表达的语义并不相同,第一个表示的是起始站,另一个表示的是终点站,两个词所表达的语义信息并不相同。
Transformer 模型通过对输入向量额外添加位置编码PositionEmbedding来解决这个问题。Transformer 模型中利用正弦和余弦函数来生成位置编码信息,将位置编码信息与 WordEmbedding 的结果相加,作为输入送到下一层。
但是下面的代码中我没用正余弦位置编码,位置编码部分我在下一篇博文中详细讲。
# -------------------------------------------------- #
#(3)encoder
# -------------------------------------------------- #
'''
src_vocab_size: 一共有多少个单词
num_layers: 堆叠多少层TransformerBlock
device: GPU or CPU
max_len: 最长的一个句子有多少个单词
embed_size: wordembedding之后, 每个单词用多少长度的向量来表示
heads: 多头注意力的heas个数
drop: 在muti_head_atten和FFN之后的dropout层杀死神经元的概率
forward_expansion: 在FFN中第一个全连接上升特征数的倍数
'''
class Encoder(nn.Module):
def __init__(self, src_vocab_size, num_layers, device, max_len,
embed_size, heads, dropout, forward_expansion):
super(Encoder, self).__init__()
self.embed_size = embed_size
self.device = device
# wordembedding 将每个单词用长度为多少的向量来表示
self.word_embedding = nn.Embedding(src_vocab_size, embed_size)
# 对每一个单词的位置编码
self.position_embedding = nn.Embedding(max_len, embed_size)
self.dropout = nn.Dropout(dropout)
# 将多个TransformerBlock保存在列表中
self.layers = nn.ModuleList(
[TransformerBlock(embed_size, heads, dropout, forward_expansion)
for _ in range(num_layers)]
)
# 前向传播x.shape=[batch, seq_len]
def forward(self, x, mask):
# 获取输入句子的shape
N, seq_len = x.shape
# 为每个单词构造位置信息, 并搬运到GPU上
position = torch.arange(0, seq_len).expand(N, seq_len).to(self.device)
# 将输入的句子经过wordembedding和位置编码后相加 [batch, seq_len, embed_size]
out = self.word_embedding(x) + self.position_embedding(position)
# dropout层
out = self.dropout(out)
# 堆叠多个TransformerBlock层
for layer in self.layers:
out = layer(out, out, out, mask)
return out
5. DecoderBlock
该部分代码对应的网络结构如下,大体结构和 Encoder 部分相同。两点不同,首先第一个的 Muti_head_attention 中使用了掩码 mask;其次第二个 Muti_head_attention 中的 query 使用的是目标序列,key 和 value 使用的是编码器的输出序列。这部分涉及的内容较多,具体原理留到下一篇文章。
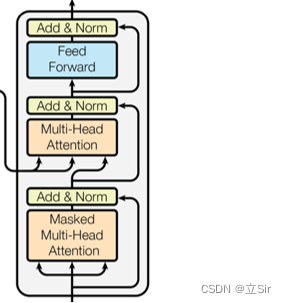
代码如下:
# -------------------------------------------------- #
#(4)decoder_block
# -------------------------------------------------- #
'''
embed_size: wordembedding之后, 每个单词用多少长度的向量来表示
heads: 多头注意力的heas个数
drop: 在muti_head_atten和FFN之后的dropout层杀死神经元的概率
forward_expansion: 在FFN中第一个全连接上升特征数的倍数
'''
class DecoderBlock(nn.Module):
def __init__(self, embed_size, heads, forward_expansion, dropout):
super(DecoderBlock, self).__init__()
# 实例化muti_head_attention
self.attention = selfattention(embed_size, heads)
# 实例化TransformerBlock
self.transformer_block = TransformerBlock(embed_size, heads, dropout, forward_expansion)
# 第一个muti_head_atten之后的LN和Dropout
self.norm = nn.LayerNorm(embed_size)
self.dropout = nn.Dropout(dropout)
# 前向传播
def forward(self, x, value, key, src_mask, trg_mask):
# 对output计算self_attention
attention = self.attention(x, x, x, trg_mask)
# 残差连接
query = self.dropout(self.norm(attention + x))
# 将encoder部分的k、v和decoder部分的q做TransformerBlock
out = self.transformer_block(value, key, query, src_mask)
return out
6. Decoder
该部分代码对应网络结构如下图所示,这部分除了上面说的两点之外,其他都和 Encoder 部分相同。首先通过** WordEmbedding 将目标序列的每个单词用长度为 embed_size 的向量来表示。经过多个 DecoderBlock 之后,输入和输出的shape保持不变[batch, seq_len, embed_size]**,最后在输出层使用一个全连接层得到结果。
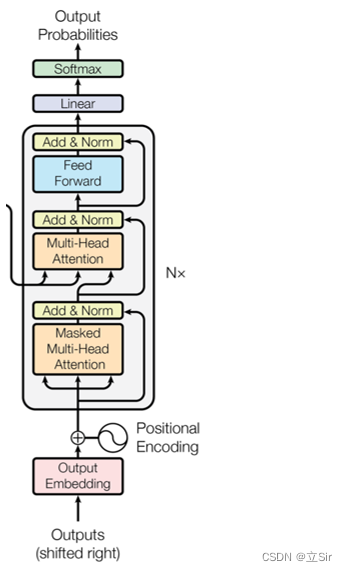
代码如下:
# -------------------------------------------------- #
#(5)decoder
# -------------------------------------------------- #
'''
trg_vocab_size: 目标句子的长度
num_layers: 堆叠多少个decoder_block
max_len: 目标句子中最长的句子有几个单词
device: GPU or CPU
embed_size: wordembedding之后, 每个单词用多少长度的向量来表示
heads: 多头注意力的heas个数
drop: 在muti_head_atten和FFN之后的dropout层杀死神经元的概率
forward_expansion: 在FFN中第一个全连接上升特征数的倍数
'''
class Decoder(nn.Module):
def __init__(self, trg_vocab_size, num_layers, device, max_len,
embed_size, heads, forward_expansion, dropout):
super(Decoder, self).__init__()
self.device = device
# trg_vocab_size代表目标句子的单词总数,embed_size代表每个单词用多长的向量来表示
self.word_embedding = nn.Embedding(trg_vocab_size, embed_size)
# 位置编码,max_len代表目标句子中最长有几个单词
self.position_embeddimg = nn.Embedding(max_len, embed_size)
# 堆叠多个decoder_block
self.layers = nn.ModuleList(
[DecoderBlock(embed_size, heads, forward_expansion, dropout)
for _ in range(num_layers)]
)
# 输出层
self.fc_out = nn.Linear(embed_size, trg_vocab_size)
self.dropout = nn.Dropout(dropout)
# 前向传播
def forward(self, x, enc_out, src_mask, trg_mask):
# 获取decoder部分输入的shape=[batch, seq_len]
N, seq_len = x.shape
# 位置编码
positions = torch.arange(0, seq_len).expand(N, seq_len).to(self.device)
# word_embedding和位置编码后的结果相加
x = self.word_embedding(x) + self.position_embeddimg(x)
x = self.dropout(x)
# 堆叠多个DecoderBlock, 其中它的key和value是用的encoder的输出 [batch, seq_len, embed_size]
for layer in self.layers:
x = layer(x, enc_out, enc_out, src_mask, trg_mask)
# 输出层
out = self.fc_out(x)
return out
7. 模型构建
完整的 Transformer 模型结构图如下,与大多数端到端的模型一样,Transformer 结构也是采用了端到端的编码器-解码器(Encoder-Decoder)架构。模型将注意力的思想发挥到了极致,编码层由 6 个编码器堆叠而成,解码层由 6 个解码器组成。结构保持一致。
对于每一个编码器,主要包含两层结构。一个是自注意力层(self_attention),自注意力层的作用是获取到句子的上下文语义信息;另一个是前馈神经网络(FFN)。此外,在每个层与层之间都会有一个残差模块和归一化操作,其作用是加速模型收敛、防止梯度消失或梯度爆炸。解码器也包含编码器中的两层网络结构,除此之外,为了获取当前节点的关注信息,在这两层结构中间还有一层编码器-解码器注意力层。
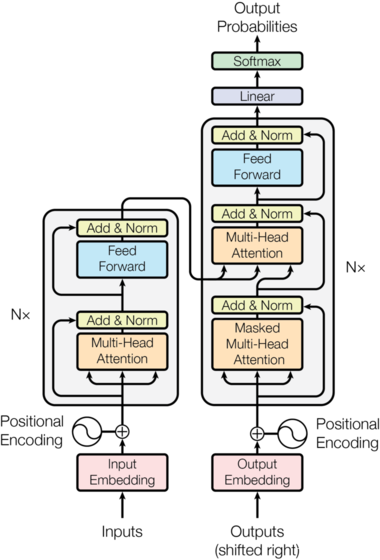
下面只需要将上面定义的 Encoder 类和 Decoder 类拼接在一起就行了。
# -------------------------------------------------- #
#(6)模型构建
# -------------------------------------------------- #
class Transformer(nn.Module):
def __init__(self,
src_vocab_size,
trg_vocab_size,
src_pad_idx,
trg_pad_idx,
embed_size=512,
num_layers=6,
forward_expansion=4,
heads=8,
dropout=0,
device='cuda',
max_len=100):
super(Transformer, self).__init__()
self.encoder = Encoder(src_vocab_size,
num_layers,
device,
max_len,
embed_size,
heads,
dropout,
forward_expansion)
self.decoder = Decoder(trg_vocab_size,
num_layers,
device,
max_len,
embed_size,
heads,
forward_expansion,
dropout)
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.device = device
# 构造mask
def make_src_mask(self, src):
# [N,src_len]==>[N,1,1,src_len]
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
return src_mask.to(self.device)
def make_trg_mask(self, trg):
# 获取目标句子的shape
N, trg_len = trg.shape
# 构造mask [trg_len, trg_len]==>[N, 1, trg_len, trg_len]
trg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(N, 1, trg_len, trg_len)
return trg_mask.to(self.device)
# 前向传播
def forward(self, src, trg):
# 对输入句子构造mask
src_mask = self.make_src_mask(src)
# 对目标句子构造mask
trg_mask = self.make_trg_mask(trg)
# encoder
enc_src = self.encoder(src, src_mask)
# decoder
out = self.decoder(trg, enc_src, src_mask, trg_mask)
return out
8. 前向传播
下面定义一个输入序列和目标序列,做一次前向传播,验证一下模型是否有误
# -------------------------------------------------- #
#(7)模型测试
# -------------------------------------------------- #
if __name__ == '__main__':
# 电脑上有GPU就调用它,没有就用CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 输入
x = torch.tensor([[1,5,6,4,3,9,5,2,0], [1,8,7,3,4,5,6,7,2]]).to(device)
# 目标
trg = torch.tensor([[1,7,4,3,5,9,2,0], [1,5,6,2,4,7,6,2]]).to(device)
src_vocab_size = 10 # 输入句子的长度
trg_vocab_size = 10 # 目标句子的长度
src_pad_idx = 0 # 对输入句子中的0值做mask
trg_pad_idx = 0
# 接收模型
model = Transformer(src_vocab_size, trg_vocab_size, src_pad_idx, trg_pad_idx)
model = model.to(device)
# 前向传播,参数:输入句子和目标句子
out = model(x, trg[:,:-1]) # 预测最后一个句子
print(out.shape)
# torch.Size([2, 7, 10])
版权归原作者 立Sir 所有, 如有侵权,请联系我们删除。