
背景介绍
接触过大模型应用开发的研发同学应该都或多或少地听过 Dify 这个大模型应用基础服务,这个项目自从 2023 年上线以来,截止目前(2024-6)已经获得了 35k 多的 star,是目前大模型应用基础服务中最热门的项目之一。这篇文章对 Dify 中核心的基础模块 RAG 服务进行深入解读,后续可能会更新其他模块的内容。
Dify 简介
Dify 是一个 LLMOps 服务, 涵盖了大语言模型(如GPT系列)开发、部署、维护和优化的一整套实践和流程。可以大幅简化大模型应用的开发。
基于 Dify 可以在不需要太多开发的情况下,快速搭建一个大模型应用。应用中可以调用 Dify 中内置的大量基础能力,比如知识库检索 RAG,大模型调用。通过可插拔式的组合构建大模型应用。一个典型的应用如下所示:
上面的场景中使用分类场景,RAG 服务以及大模型调用的基础模块,组合生成一个大模型应用。
RAG 核心流程
RAG 服务的基础流程在之前的 搭建离线私有大模型知识库 文章中已经介绍过了。RAG 服务的开源框架 有道 QAnything 和 Ragflow 也都解读过基础的 RAG 流程了,这部分就不详细展开了。一般情况下,RAG 服务会包含如下所示的功能模块:
- 文件加载的支持;
- 文件的预处理策略;
- 文件检索的支持;
- 检索结果的重排;
- 大模型的处理;
因为 RAG 服务只是 Dify 中的一个基础模块,官方没有过多强调 RAG 服务的独特设计,但是依旧可以看到一个独特点:
- 支持 Q&A 模式,与上述普通的「Q to P」(问题匹配文本段落)匹配模式不同,它是采用「Q to Q」(问题匹配问题)匹配工作;
- 丰富的召回模式,支持
N 选 1 召回和多路召回;
下面的部分会对独特之处进行详细展开。
核心模块解读
之前介绍过来自中科院的 RAG 服务 GoMate 采取的是模块化设计,方便进行上层应用的组合。从目前的实现来看,Dify 的 RAG 设计也是采用模块化设计,RAG 的代码实现都在
api/core/rag
中,从代码结构上也很容易理解各个模块的作用:

深入来看代码的实现质量也比较高,对 RAG 的模块化设计感兴趣的可以深入了解下实现细节。
文件加载
Dify 的文件加载都是在
api/core/rag/extractor/extract_processor.py
中实现的,主要的文件解析是基于 unstructured 实现,另外基于其他第三方库实现了特定格式文件的处理
比如对于 pdf 文件,会基于 pypdfium2 进行解析,html 是基于 BeautifulSoup 进行解析,这部分代码实现都比较简单,就不展开介绍了。
文件预处理
加载的模型中的内容可能会存在一些问题,比如多余的无用字符,编码错误或其他的一些问题,因此需要对文件解析的内容进行必要的清理,这部分代码实现在
api/core/rag/cleaner
中。实际的清理都是基于 unstructured cleaning 实现的,Dify 主要就是将不同的清理策略封装为同样的接口,方便应用层自由选择。这部分实现也比较简单,感兴趣可以自行了解下。
Q&A 模式
Q&A 分段模式功能,与上述普通的「Q to P」(问题匹配文本段落)匹配模式不同,它是采用「Q to Q」(问题匹配问题)匹配工作,在文档经过分段后,经过总结为每一个分段生成 Q&A 匹配对,当用户提问时,系统会找出与之最相似的问题,然后返回对应的分段作为答案,实际的流程如下所示:
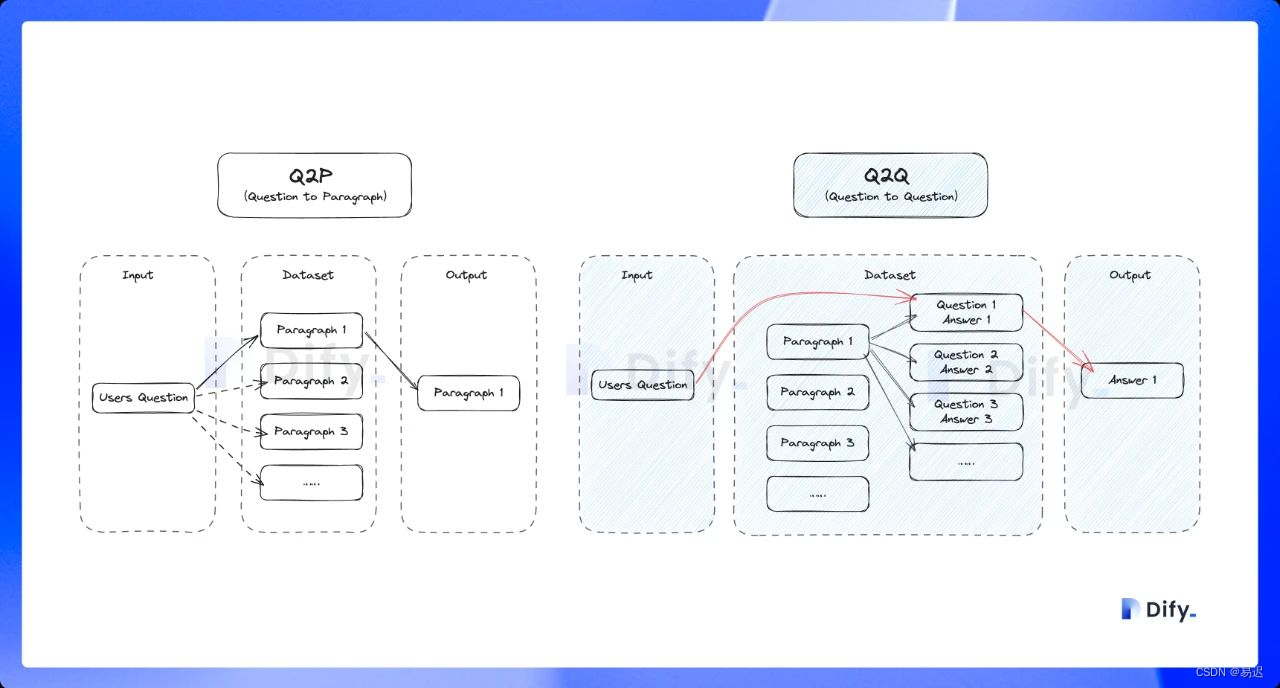
从上面的流程可以看到,Q&A 模式下会根据原始文档生成问答对,实现实现是在
api/core/llm_generator/llm_generator.py
中:
# 构造 prompt
GENERATOR_QA_PROMPT =('<Task> The user will send a long text. Generate a Question and Answer pairs only using the knowledge in the long text. Please think step by step.''Step 1: Understand and summarize the main content of this text.\n''Step 2: What key information or concepts are mentioned in this text?\n''Step 3: Decompose or combine multiple pieces of information and concepts.\n''Step 4: Generate questions and answers based on these key information and concepts.\n''<Constraints> The questions should be clear and detailed, and the answers should be detailed and complete. ''You must answer in {language}, in a style that is clear and detailed in {language}. No language other than {language} should be used. \n''<Format> Use the following format: Q1:\nA1:\nQ2:\nA2:...\n''<QA Pairs>')defgenerate_qa_document(cls, tenant_id:str, query, document_language:str):
prompt = GENERATOR_QA_PROMPT.format(language=document_language)
model_manager = ModelManager()
model_instance = model_manager.get_default_model_instance(
tenant_id=tenant_id,
model_type=ModelType.LLM,)# 拼接出完整的调用 prompt
prompt_messages =[
SystemPromptMessage(content=prompt),
UserPromptMessage(content=query)]# 调用大模型直接生成问答对
response = model_instance.invoke_llm(
prompt_messages=prompt_messages,
model_parameters={'temperature':0.01,"max_tokens":2000},
stream=False)
answer = response.message.content
return answer.strip()
可以看到就是通过一个 prompt 就完成了原始文档到问答对的转换,可以看到大模型确实可以帮助实现业务所需的基础能力。
文件检索
知识库的检索是在
api/core/workflow/nodes/knowledge_retrieval/knowledge_retrieval_node.py
中实现的,与常规的 RAG 存在明显不同之处在于支持了丰富的召回模式。
丰富的召回模式
用户可以自由选择所需的召回模式:

N 选 1 召回:先根据用户输入的意图选择合适的知识库,然后从知识库检索所需的文档,适用于知识库彼此隔离,不需要互相联合查询的场景;多路召回:此时会同时从多个知识库检索,然后进行重新排序,适用于知识库需要联合查询的场景。
常规的 RAG 服务需要先手工选择知识库,然后从对应的知识库进行检索,无法支持跨库检索。相对而言,Dify 的这个设计还是要更方便一些。下面以
N 选 1 召回
为例介绍下文件的检索,对应的流程如下所示:
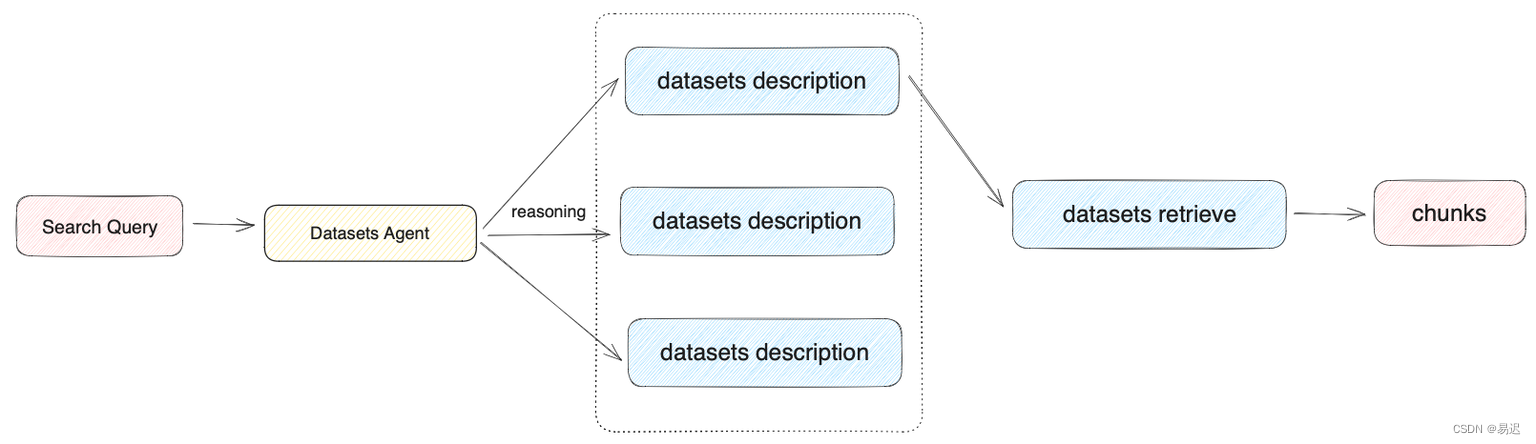
N 选 1 召回
的知识库选择是基于用户问题与知识库描述的语义匹配性来进行选择,存在
Function Call
/
ReAct
两种模式,实现代码在
api/core/rag/retrieval/dataset_retrieval.py
中,具体如下所示:
tools =[]# 根据用户输入的意图,使用知识库的描述构造 promptfor dataset in available_datasets:
description = dataset.description
ifnot description:
description ='useful for when you want to answer queries about the '+ dataset.name
description = description.replace('\n','').replace('\r','')
message_tool = PromptMessageTool(
name=dataset.id,
description=description,
parameters={"type":"object","properties":{},"required":[],})
tools.append(message_tool)# 支持 ReAct 模式if planning_strategy == PlanningStrategy.REACT_ROUTER:
react_multi_dataset_router = ReactMultiDatasetRouter()
dataset_id = react_multi_dataset_router.invoke(query, tools, model_config, model_instance,
user_id, tenant_id)# 支持 Function Call 模式elif planning_strategy == PlanningStrategy.ROUTER:
function_call_router = FunctionCallMultiDatasetRouter()
dataset_id = function_call_router.invoke(query, tools, model_config, model_instance)
Function Call模式就是构造了一个 prompt,让大模型根据描述选择合适的知识库,实现比较简单ReAct模式则是基于 ReAct , 通过推理 + 任务的结合选择正确的知识库
知识库检索
在前面根据模式选择了对应的知识库之后,就可以在单个知识库内进行检索,目前支持的检索方式包含下面三种:
向量检索,通过生成查询嵌入并查询与其向量表示最相似的文本分段。全文检索,索引文档中的所有词汇,从而允许用户查询任意词汇,并返回包含这些词汇的文本片段。混合检索,同时执行全文检索和向量检索,并附加重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果。
从实际的代码来看,还有一个
关键词检索
的能力,但是没有特别介绍,不确定是否是效果上还不够稳定,可以关注下后续的进展。混合检索的流程如下所示:

实际的实现在
api/core/rag/datasource/retrieval_service.py
:
# 关键词检索if retrival_method =='keyword_search':
keyword_thread = threading.Thread(target=RetrievalService.keyword_search, kwargs={'flask_app': current_app._get_current_object(),'dataset_id': dataset_id,'query': query,'top_k': top_k,'all_documents': all_documents,'exceptions': exceptions,})
threads.append(keyword_thread)
keyword_thread.start()# 向量检索(混合检索中也会调用)if RetrievalMethod.is_support_semantic_search(retrival_method):
embedding_thread = threading.Thread(target=RetrievalService.embedding_search, kwargs={'flask_app': current_app._get_current_object(),'dataset_id': dataset_id,'query': query,'top_k': top_k,'score_threshold': score_threshold,'reranking_model': reranking_model,'all_documents': all_documents,'retrival_method': retrival_method,'exceptions': exceptions,})
threads.append(embedding_thread)
embedding_thread.start()# 文本检索(混合检索中也会调用)if RetrievalMethod.is_support_fulltext_search(retrival_method):
full_text_index_thread = threading.Thread(target=RetrievalService.full_text_index_search, kwargs={'flask_app': current_app._get_current_object(),'dataset_id': dataset_id,'query': query,'retrival_method': retrival_method,'score_threshold': score_threshold,'top_k': top_k,'reranking_model': reranking_model,'all_documents': all_documents,'exceptions': exceptions,})
threads.append(full_text_index_thread)
full_text_index_thread.start()for thread in threads:
thread.join()# 混合检索之后会执行向量和文本检索结果合并后的重排序if retrival_method == RetrievalMethod.HYBRID_SEARCH:
data_post_processor = DataPostProcessor(str(dataset.tenant_id), reranking_model,False)
all_documents = data_post_processor.invoke(
query=query,
documents=all_documents,
score_threshold=score_threshold,
top_n=top_k
)
检索结果重排
检索结果的重排也比较简单,就是通过外部模型进行打分,之后基于打分的结果进行排序,实际的实现在
api/core/model_manager.py
中:
definvoke_rerank(self, query:str, docs:list[str], score_threshold: Optional[float]=None,
top_n: Optional[int]=None,
user: Optional[str]=None) \
-> RerankResult:
self.model_type_instance = cast(RerankModel, self.model_type_instance)# 轮询调用重排序模型,获得重排序得分,并基于得分进行排序return self._round_robin_invoke(
function=self.model_type_instance.invoke,
model=self.model,
credentials=self.credentials,
query=query,
docs=docs,
score_threshold=score_threshold,
top_n=top_n,
user=user
)
总结
本文主要介绍了 Dify 的知识库 RAG 服务,作为完整 Agent 中一个基础模块,Dify 没有特别强调 RAG 独特之处,但是依旧存在一些独特的亮点:
- 多种召回模式,支持根据用户意图自动选择合适的知识库,也可以跨知识库进行检索,弥补了常规的 RAG 服务需要用户手工选择知识库的不便之处;
- 独特的 Q&A 模式,可以直接根据文本生成问答对,可以解决常规情况下用户问题与文本匹配度不够的问题,但是应该只适用于特定类型的场景,否则可能会因为转换导致的信息损耗导致效果更差;
总体而言,Dify 中的 RAG 服务是一个设计完备的服务,模块化的设计方便组合与拓展,一些独特的设计也可以提升易用性,代码质量也很高,感兴趣的可以深入研究下。
版权归原作者 易迟 所有, 如有侵权,请联系我们删除。