
在人工智能领域,大型语言模型(LLMs)的迅猛发展极大地推动了机器在语言理解和生成方面的能力。然而,如何让这些模型更好地与人类偏好和价值观对齐,成为了一个重要而紧迫的课题。为此清华团队推出一项免费服务ChatGLM-RLHF,一个基于人类反馈的强化学习系统,旨在解决大型语言模型(LLMs)与人类偏好对齐的问题。该系统通过收集人类对模型生成文本的偏好反馈,训练一个奖励模型来评估响应质量,并以此指导策略模型的优化,从而生成更符合人类价值观和期望的响应。
ChatGLM-RLHF系统主要由三个部分组成:人类偏好数据的收集、奖励模型的训练以及策略的优化。
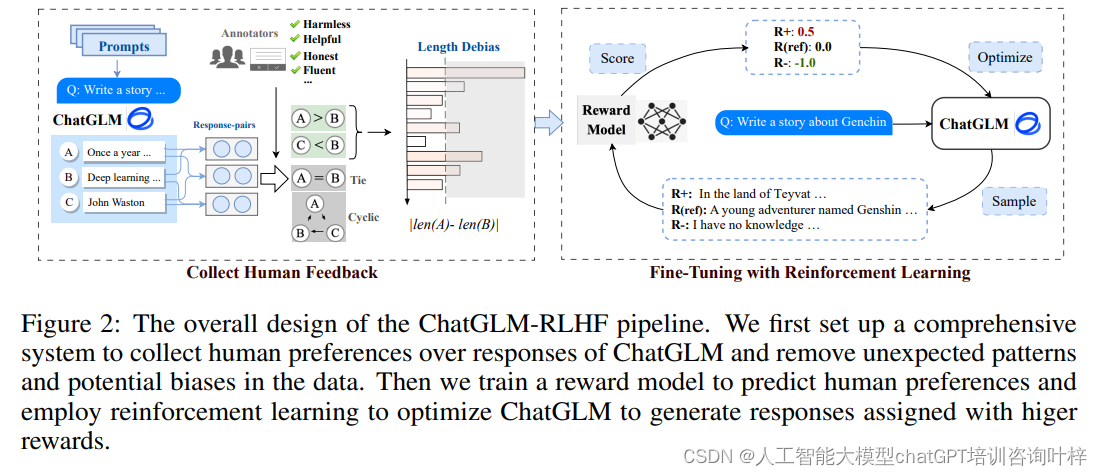
ChatGLM-RLHF的构建始于对人类偏好数据的细致收集,这是整个系统的基础。Zhipu AI和清华大学的团队设计了一个系统化的方法,通过成对比较机制,让注释者在两个由监督微调(SFT)模型生成的响应中选择一个他们认为更优的。这种机制不仅帮助收集数据,还确保了注释的一致性,因为所有注释者都依据同样的标准——即响应的有用性、无害性和流畅性——来做出选择。

Table 1 展示了不同质量的提示(prompts)的例子,这些例子反映了在收集过程中对提示质量的严格把控。
表中列出的提示被分为几个类别,包括具有清晰意图和语义的、意图不明确的、语义不清晰的,以及无法回答的提示。例如,一个高质量的提示可能是:“Assist me in crafting a three-day travel itinerary to Beijing with a budget of under 5000。” 这个提示具有明确的意图,即帮助制定一个预算在5000元以下的北京三天旅行计划,它的语义清晰,且是可以回答的。
相比之下,低质量的提示可能包含不明确的意图,如:“The gentleman attended the meeting, dressed in formal attire。” 这个提示的意图不明确,它没有给出一个具体的任务或问题。另外,还有语义不清晰的提示,例如:“Christmas, Reindeer, Christmas Tree”,这些词汇放在一起没有形成清晰的问题或请求。最后,无法回答的提示是指超出模型能力范围的,比如:“What is the winning lottery number for tomorrow?”,因为模型无法预测彩票中奖号码。
在数据收集阶段,为了确保注释的一致性和高质量,每个注释者都会得到一个提示和两个由SFT模型生成的响应,并被要求选择他们认为更好的那个响应。他们需要基于响应的有用性、无害性和流畅性来做出选择。有用性涉及到响应是否满足了提示的所有要求,是否提供了准确且有价值的信息,并且保持了逻辑一致性。安全性则确保响应中不包含有害或有毒的内容,也不会引发争议。流畅性则与语言的规范性和自然性有关。
收集到的数据随后被用于训练奖励模型,该模型的核心任务是预测普通用户会偏好哪种类型的响应。

Table 2提供了对奖励模型训练所使用人类偏好数据的统计信息,这些数据包括比较次数、每个对话的平均轮次、历史中的平均令牌数、提示的平均令牌数以及响应的平均令牌数。例如,表中显示了总共有221,866次比较,平均每个对话有2.4轮,提示和响应的平均令牌数分别为104.1和267.7。
为了确保奖励模型能够准确预测普通用户的偏好,而不仅仅是学习到数据中的表面特征或偏见,开发团队采取了一系列策略来去除数据中的偏差。
人类在评估响应时可能会有天生的倾向,比如偏好那些更长、结构更完整的答案。这种倾向如果不加以控制,可能会导致奖励模型过分强调响应的长度和结构,而不是内容的实际质量和相关性。为了解决这个问题,团队实施了一种被称为“Bucket-Based Length Balancing”的去偏方法。
这种方法的第一步是计算每对偏好响应之间的长度差异。然后,根据这个长度差异,将响应对分配到不同的“桶”中,每个桶代表一个特定的长度差异范围。在每个桶内,团队会平衡那些较长或较短响应被选为更好响应的例子数量。通过这种方法,可以减少对长度的偏好,从而避免奖励模型学习到错误的偏见。
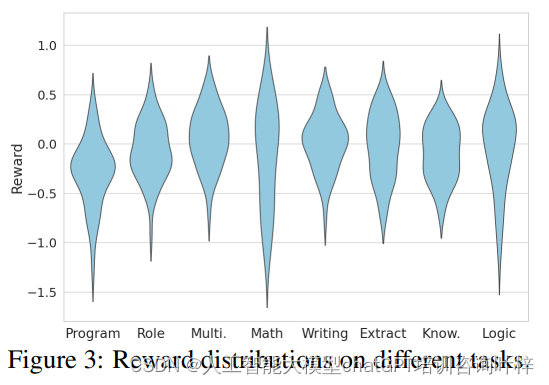
Figure 3表明奖励模型在不同任务和提示上的打分存在显著差异。这种差异可能源于响应风格、长度以及奖励模型的辨别力等因素。例如,某些任务可能倾向于更长的响应,而其他任务可能更注重简洁性。为了解决这个问题,团队实施了一种去偏方法,称为“Bucket-Based Length Balancing”,以减少对长度的偏见。
除了长度偏差之外,奖励模型在训练过程中还可能遇到其他类型的偏差,比如任务样本偏差或值不稳定性。为了应对这些挑战,团队引入了一个新的损失组件,类似于L2正则化损失。这个损失项通过对得分分布施加高斯先验,均值为零,来限制得分分布的波动性,从而增加了训练过程的稳定性。
为了减少能力遗忘的问题,即在强化学习后训练阶段模型在处理特定场景时出现的意外行为,团队还提出了在奖励最大化过程中加入额外的监督下一个词预测损失作为正则化手段。这个策略旨在保留SFT模型的现有能力,同时通过强化学习鼓励模型输出与人类偏好更加一致的响应。
完成奖励模型的训练后,这个模型充当了一个代理,其目的是引导语言模型的策略优化,使其生成的响应更贴近人类的偏好。这一过程是ChatGLM-RLHF中的一个关键环节,它决定了模型能否有效地学习并模仿人类的评估标准。
在这个环节中,研究团队采用了两种不同的强化学习算法:在线的近端策略优化(PPO)和离线的直接偏好优化(DPO)。PPO算法是一种在线学习方法,它在训练过程中动态地更新模型的权重。具体来说,PPO通过比较新策略和旧策略产生的结果,来调整模型参数,使得模型更倾向于产生那些能够获得更高奖励的响应。这种方法的优势在于它能够实时地对模型进行微调,以便更好地捕捉到人类反馈中的细微差别。
与此同时,DPO算法则采用了一种离线学习的方式。与PPO不同,DPO不依赖于实时的模型权重更新,而是直接利用已经标注好的偏好数据来训练模型。这种方法简化了训练过程,因为它不需要模型在生成响应的同时进行复杂的权重更新。DPO通过直接从偏好数据中学习,模型可以更加专注于理解哪些类型的响应更可能获得人类的偏好,从而在策略优化中更加有的放矢。
无论是PPO还是DPO,这两种方法的最终目标都是一致的:使语言模型生成的响应获得更高的奖励,即更符合人类的偏好。奖励模型在这个过程中起到了至关重要的作用,它为策略优化提供了一个量化的评估标准。
研究团队通过一系列精心设计的实验来评估ChatGLM-RLHF系统的性能。这些实验旨在验证经过RLHF训练的模型是否能够比传统的监督微调(SFT)模型更好地符合人类的偏好和期望。
实验的自动评估部分使用了AlignBench测试集,这是一个针对中文语言的大型语言模型对齐的基准测试。AlignBench包含8个主要类别和36个子类别,涵盖了683个问题,每个问题都配有参考答案和评估标准。研究团队使用GPT-4作为评估标准,自动评估模型生成的响应质量。
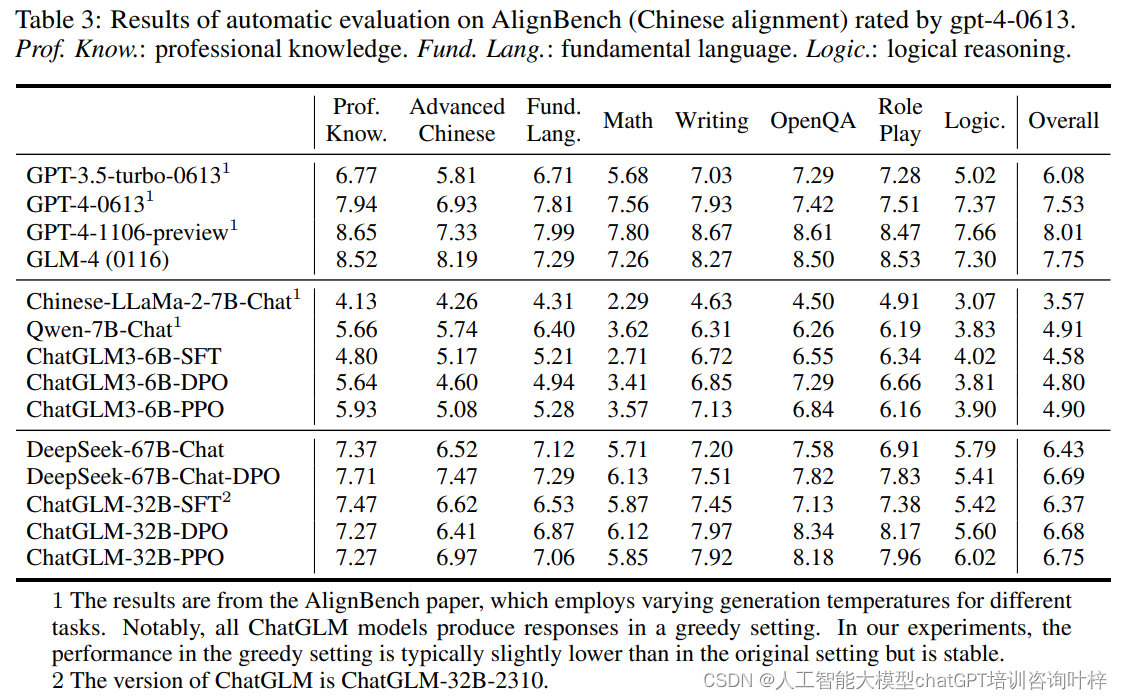
实验结果显示,在表3中,ChatGLM-32B的RLHF模型在多个任务上相较于SFT模型有显著提升,尤其是在写作、开放式问答(OpenQA)和角色扮演(Role Play)等任务上。这表明奖励模型在创意写作类任务上特别有效,而在需要高级推理能力的数学和逻辑任务上提升有限。
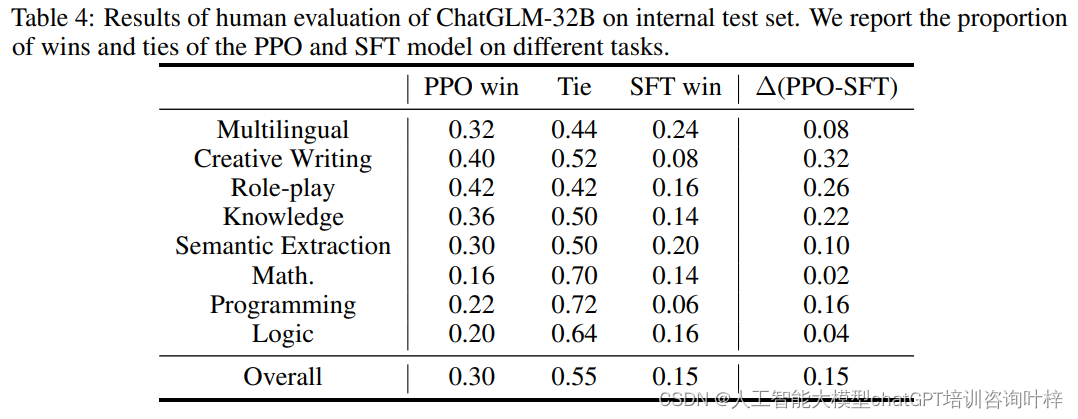 为了进一步验证RLHF的效果,研究团队还进行了人类评估。他们收集了400条涵盖多个领域的中文指令,并采用成对比较方法让人类评估者选择他们认为更合适的响应。表4展示了人类评估的结果,其中PPO模型在30%的情况下胜过SFT模型,而在创意写作和角色扮演等任务上,PPO模型的表现尤为出色。此外,表6提供了不同模型生成响应的长度数据,显示RLHF方法,特别是DPO,显著增加了响应的长度,这可能部分解释了在自动评估中创意写作任务得分提高的原因。
为了进一步验证RLHF的效果,研究团队还进行了人类评估。他们收集了400条涵盖多个领域的中文指令,并采用成对比较方法让人类评估者选择他们认为更合适的响应。表4展示了人类评估的结果,其中PPO模型在30%的情况下胜过SFT模型,而在创意写作和角色扮演等任务上,PPO模型的表现尤为出色。此外,表6提供了不同模型生成响应的长度数据,显示RLHF方法,特别是DPO,显著增加了响应的长度,这可能部分解释了在自动评估中创意写作任务得分提高的原因。
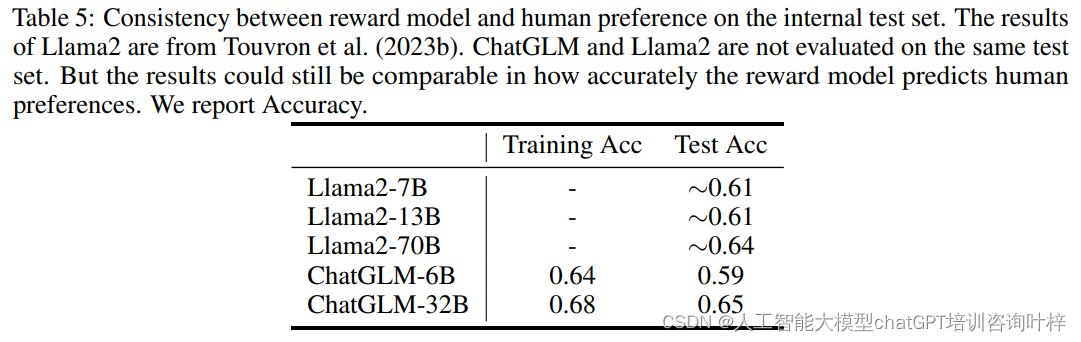 为了评估奖励模型预测人类偏好的准确性,研究团队创建了一个测试集,包含人类评估中任务的成对比较,并附有仔细检查过的人类注释。表5展示了奖励模型与人类偏好一致性的评估结果。尽管ChatGLM-32B的准确性略高于ChatGLM-6B,但最高只有65%,这表明尽管奖励模型能够以大约65%的准确率反映人类判断,但仍有改进空间。
为了评估奖励模型预测人类偏好的准确性,研究团队创建了一个测试集,包含人类评估中任务的成对比较,并附有仔细检查过的人类注释。表5展示了奖励模型与人类偏好一致性的评估结果。尽管ChatGLM-32B的准确性略高于ChatGLM-6B,但最高只有65%,这表明尽管奖励模型能够以大约65%的准确率反映人类判断,但仍有改进空间。
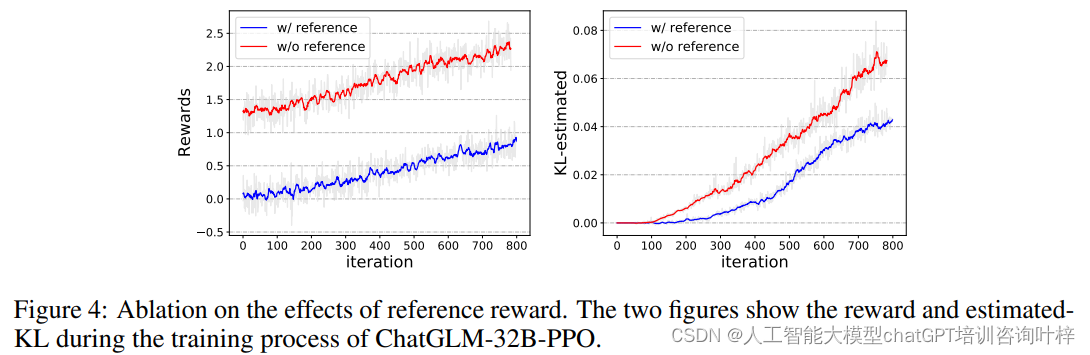 为了评估参考奖励的有效性,研究团队还进行了消融研究,比较了在相同超参数设置下,使用(w/)和不使用(w/o)参考奖励的PPO训练。图4展示了训练过程中奖励和估计的KL散度的变化,表明使用参考奖励有助于稳定训练过程,并减少模型偏离原始SFT模型的程度。
为了评估参考奖励的有效性,研究团队还进行了消融研究,比较了在相同超参数设置下,使用(w/)和不使用(w/o)参考奖励的PPO训练。图4展示了训练过程中奖励和估计的KL散度的变化,表明使用参考奖励有助于稳定训练过程,并减少模型偏离原始SFT模型的程度。
ChatGLM-RLHF的成功实施展示了通过人类反馈来对齐大型语言模型与人类偏好的巨大潜力。实验结果表明,与SFT模型相比,ChatGLM-RLHF平均在15%的情况下更符合人类偏好,这强调了所提出管道的有效性。尽管在数学和逻辑等需要高级推理能力的任务上,RLHF方法的提升有限,但在创意写作等任务上,它已经证明了其显著的价值。
随着技术的不断进步和优化,我们可以期待,未来ChatGLM-RLHF将在更多领域展现出其强大的能力,为人类提供更加精准、安全和有帮助的服务。
版权归原作者 人工智能大模型讲师培训咨询叶梓 所有, 如有侵权,请联系我们删除。