
前言
工作上,需要使用AI Agent,所以需要深入学习一下AI Agent,光阅读各种文章,总觉无法深入细节,所以开看各类AI Agent相关的开源项目,此为第一篇,学习一下MetaGPT的源码。
基本目标
MetaGPT是一个多智能体框架,他抽象了一个软件公司中的主要角色,用不同的AI Agent去扮演,这些AI Agent包括产品经理、软件架构师、项目经理、工程师,这些AI Agent会按照开发团队设计好的SOP去交互并最终产出一个项目。
老习惯:不为读而读,为解决某些问题或理清某些概念而读,那么面对MetaGPT,我有以下目标:
- MetaGPT是怎么抽象出的软件公司开发流程的?SOP具体在代码上是怎么实现的?
- MetaGPT中不同AI Agent是怎么交互的?
- 从效果上看,MetaGPT输出的内容是比较格式化的,要做到这样的效果,prompt是怎么写的?
- MetaGPT是怎么抽象具体的职业的?比如产品经理是怎么抽象的。
本文主要来从源码中,找到上面问题的答案。
入口
虽然README.md中说,很多同学运行时会有点问题,但我感觉,运行起来还是很轻松的,相比于早期的sd-webui,那是友好太多了,所以这里不多提,直接按README中的内容run一下就好了。
直接看到入口方法
# startup.py
async def startup(
idea: str,
investment: float = 3.0,
n_round: int = 5,
code_review: bool = False,
run_tests: bool = False,
implement: bool = True
):
# 1.开公司
company = SoftwareCompany()
# 2.雇员工
company.hire([
ProductManager(), # 产品经理
Architect(), # 架构师
ProjectManager(), # 项目经理
])
if implement or code_review:
# 3.雇开发
company.hire([Engineer(n_borg=5, use_code_review=code_review)])
if run_tests:
company.hire([QaEngineer()])
# 4.设置金额(这次运行最多能消耗多少美金的GPT4)
company.invest(investment)
# 5.老板的需求
company.start_project(idea)
# 6.跑几轮
await company.run(n_round=n_round)
从startup看,整个流程很清晰,可读性很高!
先看看SoftwareCompany类,部分代码如下:
# metagpt/software_company.py
class SoftwareCompany(BaseModel):
# 环境
environment: Environment = Field(default_factory=Environment)
investment: float = Field(default=10.0)
idea: str = Field(default="")
async def run(self, n_round=3):
"""Run company until target round or no money"""
while n_round > 0:
# self._save()
n_round -= 1
logger.debug(f"{n_round=}")
self._check_balance()
await self.environment.run()
return self.environment.history
通过SoftwareCompany类抽象一个软件公司,阅读代码后,你会发现SoftwareCompany类中的environment对象很重要,公司里的不同AI Agent都会与environment对象交互,这个抽象也很巧妙,就是在公司里,同事间的交流确实在公司这个“环境”里传播。
然后就是run方法,看到startup方法的最后,就是调用SoftwareCompany类的run方法,该方法会检测一下余额以及运行的轮数,如果余额不够或轮数超了,就会停止运行。
因为MetaGPT底层是使用openai api的,每次请求都需要花钱,你设置一个预算,默认是3美元,跑满3美元,就算任务没有完成,也会强行结束。
SoftwareCompany类的run方法会调用environment对象的run方法,代码如下:
# metagpt/environment.py/Environment
async def run(self, k=1):
"""
Process all Role runs at once
"""
for _ in range(k):
futures = []
for role in self.roles.values():
future = role.run()
futures.append(future)
# 当调用 asyncio.gather(*futures) 时,它会同时运行传递进来的协程,这些协程会在后台并发执行,而不会阻塞主线程。
await asyncio.gather(*futures)
从上面代码可知,这才是真正的入口,循环所有的roles,然后调用每个role的run方法,整个过程通过python协程异步并发的运行,从而提高程序的运行效率。
这里的role就是不同身份的员工,其本质就是使用不同Prompt的请求openai的代码逻辑。
我们需要阅读一下role相关的代码,来尝试理解顺序性的问题。
role
在startup方法中,我们首先雇佣了3个不同的role:
company.hire([
ProductManager(), # 产品经理
Architect(), # 架构师
ProjectManager(),
])
雇佣的顺序是有讲究的。一开始雇佣的是ProductManager实例,也就是,这里已经执行了实例ProductManager类的实例化代码了:
# metagpt/roles/product_manager.py
class ProductManager(Role):
def __init__(self,
name: str = "Alice",
profile: str = "Product Manager",
goal: str = "Efficiently create a successful product",
constraints: str = "") -> None:
super().__init__(name, profile, goal, constraints)
# 1.写产品需求文档(Product Requirement Document)
self._init_actions([WritePRD])
# 2.观察老板的需求
self._watch([BossRequirement])
上面代码中,_init_actions与_watch都是Role类中的方法,也就是当前产品经理这个role自己的方法。它初始化了自己的动作:写需求文档,以及定了自己要观察的东西:老板的需求。
BossRequirement怎么来的?在startup方法中,我们调用了SoftwareCompany的start_project方法,该方法会就我们的需要以BOSS的身份发送到SoftwareCompany的environment中,代码如下:
# metagpt/software_company.py/SoftwareCompany
def start_project(self, idea):
"""Start a project from publishing boss requirement."""
self.idea = idea
# Role初始观察到的message
self.environment.publish_message(Message(role="BOSS", content=idea, cause_by=BossRequirement))
这个过程类似于,公司里,老板走到产研区域,大喊一声,我要做个xxxx,然后大家就知道了,metagpt就是抽象了这个过程,其他的role可以通过SoftwareCompany的environment的读到老板和其他role的信息。
当environment对象的run方法被运行时,role的run方法就会被执行,
async def run(self, message=None):
if message:
# 1.如果有人给你发消息,则将消息存入role的短期记忆中
if isinstance(message, str):
message = Message(message)
if isinstance(message, Message):
self.recv(message)
if isinstance(message, list):
self.recv(Message("\n".join(message)))
# 2.观察环境中的信息,看看有没有需要处理的
elif not await self._observe():
# If there is no new information, suspend and wait
logger.debug(f"{self._setting}: no news. waiting.")
return
# 3.如果有需要处理的,则通过 _react 处理,并获得处理结果
rsp = await self._react()
# 4.将处理的结果发到 environment 中
self._publish_message(rsp)
return rsp
run方法的逻辑也很清晰,先观察environment中的信息,如果有需要处理的,则_react进行处理并将结果发送回environment中。
那具体怎么观察呢?看到_observe方法的代码:
# metagpt/roles/role.py/Role
async def _observe(self) -> int:
if not self._rc.env:
return 0
# 从env的短期记忆中,获取信息
env_msgs = self._rc.env.memory.get()
# 从env中观察要观察的对象,获得对应的message
observed = self._rc.env.memory.get_by_actions(self._rc.watch)
# 记下来(role自己的memory)
self._rc.news = self._rc.memory.remember(observed) # remember recent exact or similar memories
for i in env_msgs:
# 将环境中的信息记到role memory中
self.recv(i)
news_text = [f"{i.role}: {i.content[:20]}..." for i in self._rc.news]
if news_text:
logger.debug(f'{self._setting} observed: {news_text}')
return len(self._rc.news)
def recv(self, message: Message) -> None:
if message in self._rc.memory.get():
return
# 记一下信息
self._rc.memory.add(message)
上面代码中,self._rc.env 对象就是当前role所在的环境,这里用了常见的双向关联技巧。
当其他role通过publish_message方法向environment发消息时,消息其实存在environment的memory中,在_observe方法中,首先environment的memory中读取消息,然后在通过get_by_actions方法去获得需要某个action产生的message,以ProductManager为里,ProductManager通过_watch方法将BossRequirement设置为需要观察的对象。
当role调用get_by_actions时,会去找BossRequirement对应的message(其实就是需要message,然后交给GPT4去处理),get_by_actions代码如下:
# metagpt/memory.py/Memory
def get_by_action(self, action: Type[Action]) -> list[Message]:
"""Return all messages triggered by a specified Action"""
return self.index[action]
def get_by_actions(self, actions: Iterable[Type[Action]]) -> list[Message]:
"""Return all messages triggered by specified Actions"""
rsp = []
for action in actions:
if action not in self.index:
continue
rsp += self.index[action]
return rsp
def add(self, message: Message):
"""Add a new message to storage, while updating the index"""
if message in self.storage:
return
self.storage.append(message)
if message.cause_by:
self.index[message.cause_by].append(message)
因为get_by_actions其实就是从self.index中找到action这个key对应的value,所以self.index是什么就很关键,而这就需要看到add方法,以BossRequirement为例,就是将key设置为BossRequirement,然后存message。
简单而言,get_by_actions方法会获取由role的_watch方法指定的要观察的对象其对应的message,作为self._rc.news,然后role将这些news存到memory中。
如果role通过_observe方法观察到了news,那么就需要执行_react方法:
# metagpt/roles/role.py
async def _react(self) -> Message:
"""Think first, then act"""
await self._think()
logger.debug(f"{self._setting}: {self._rc.state=}, will do {self._rc.todo}")
return await self._act()
先看到_think方法:
# metagpt/roles/role.py/Role
async def _think(self) -> None:
# 1.如果只有一个动作,那么就直接让_act执行这一个动作则可
if len(self._actions) == 1:
self._set_state(0)
return
prompt = self._get_prefix()
# 2.整合role的memory和state到prompt中,让GPT4处理
prompt += STATE_TEMPLATE.format(history=self._rc.history, states="\n".join(self._states),
n_states=len(self._states) - 1)
next_state = await self._llm.aask(prompt)
logger.debug(f"{prompt=}")
if not next_state.isdigit() or int(next_state) not in range(len(self._states)):
logger.warning(f'Invalid answer of state, {next_state=}')
next_state = "0"
self._set_state(int(next_state))
_think方法的作用是设置state,然后_act才会根据设置好的state决定要执行的action,如果当前role只有一个state,那么state直接设置成0则可,如果有多个action,那么就交由GPT4去判断:将role的memory中的信息全部取出作为history,然后将role的所有state也整合起来,一起放到prompt中,交由GPT4去选择当前history下要做什么action是最好的,让其返回state。
然后看_act方法:
async def _act(self) -> Message:
logger.info(f"{self._setting}: ready to {self._rc.todo}")
# 让role执行相应的action
response = await self._rc.todo.run(self._rc.important_memory)
if isinstance(response, ActionOutput):
msg = Message(content=response.content, instruct_content=response.instruct_content,
role=self.profile, cause_by=type(self._rc.todo))
else:
msg = Message(content=response, role=self.profile, cause_by=type(self._rc.todo))
# 记下当前action返回的msg
self._rc.memory.add(msg)
# logger.debug(f"{response}")
return msg
_act方法的逻辑就是执行self._rc.todo对应的action,这个action是_think方法通过_set_state方法设置的,比如产品经理只有一个action:WritePRD,那么就会执行WritePRD的run方法,需要注意的是,为了让不同的role可以交互,_act还会产生message,每个message都会设置cause_by参数,以表明当前的message是由哪个动作产生的,其他role就可以通过_watch方法看到需要的message了。
随后,我们看到WritePRD的细节,代码如下:
# metagpt/actions/write_prd.py
class WritePRD(Action):
def __init__(self, name="", context=None, llm=None):
super().__init__(name, context, llm)
async def run(self, requirements, *args, **kwargs) -> ActionOutput:
sas = SearchAndSummarize()
rsp = ""
info = f"### Search Results\n{sas.result}\n\n### Search Summary\n{rsp}"
if sas.result:
logger.info(sas.result)
logger.info(rsp)
prompt = PROMPT_TEMPLATE.format(requirements=requirements, search_information=info,
format_example=FORMAT_EXAMPLE)
logger.debug(prompt)
prd = await self._aask_v1(prompt, "prd", OUTPUT_MAPPING)
return prd
WritePRD类的本质也是一个prompt,它会接受requirements参数,从metagpt整个流程看,requirements参数就是老板的需求message,也就是产品经理要基于老板需求message写出PRD(产品需求文档),获得结果后,自己再记到role到memory中。
role间的交互
一开始时,用户以BOSS role输入一个需求message,这个message被丢到environment上,代码如下,主要publish_message方法的cause_by使用了BossRequirement,为了方便解释,我将需求定为:开发一个Crypto的量化交易系统。
# metagpt/software_company.py/SoftwareCompany
def start_project(self, idea):
self.idea = idea
# Role初始观察到的message
self.environment.publish_message(Message(role="BOSS", content=idea, cause_by=BossRequirement))
ProductManager通过_watch方法关注BossRequirement,从而在运行ProductManager时,_observe方法会收到【开发一个Crypto的量化交易系统】的message作为self._rc.news,随后调用_think和_act方法,因为只有WritePRD这一个action,所以就调用WritePRD的run方法了,并将role memory中记忆的【开发一个Crypto的量化交易系统】的message作为requirements,传入了prompt中。
从startup方法相关代码可知,ProductManager后是Architect(架构师),Architect通过_watch方法关注WritePRD。
在ProductManager的_act中,将Message添加到environment中,cause_by为WritePRD,此时就可以被Architect通过_watch方法关注,并通过_observe方法获得WritePRD产出的结果,存入Architect的记忆中,然后作为WriteDesign这个action的输入,WriteDesign会将WritePRD的内容放到它的prompt中。
至此,role的交互流程就比较清晰了。
回答问题
Metagpt还有很多代码细节,但读到这,已经可以回答开头的问题了:
1.MetaGPT是怎么抽象出的软件公司开发流程的?SOP具体在代码上是怎么实现的?SOP就是不同role之间交互的顺序,比如产品经理需要BOSS的message作为他prompt的约束,而产品经理的产出是架构师的输入,不同角色间的输入输出,就是SOP。
2.MetaGPT中不同AI Agent是怎么交互的?role通过_watch确定要从哪个role的哪个action中获得这个action的输出,具体获取的过程在_observer方法中,获得其他role的message后,如果当前的role有多个action可执行,则通过_think去选一个action(使用env的memory,即当前环境中发生的内容),再通过_act去具体的执行action,执行action时,会从role的memory中获取需要的message。
3.从效果上看,MetaGPT输出的内容是比较格式化的,要做到这样的效果,prompt是怎么写的?MetaGPT的prompt的设计形式值得学习,它主要使用MarkDown格式来设计prompt,多数prompt中都会有context、example,从而让GPT4更好的发挥zero-shot能力,想知道具体的,建议直接拉代码下来看。
4.MetaGPT是怎么抽象具体的职业的?从职业这个角度讲,主要通过action和承接的message来抽象,比如产品经理,就抽象成,接收老板需求,产出产品需求文档,将需求文档给到架构师的对象,然后每个role生成的结果都会放到env中,其他人也可以看到(很多角色只有一个action,就不会用到env中的message)。
结尾
我自己跑了几遍MetaGPT,还是有明显的局限性的。如果我按example的形式,让他写python小游戏,过程是丝滑的,但我换成让MetaGPT帮我设计一个今日头条的广告推荐系统,他就给了我下面这样的东西,很明显,不太可用。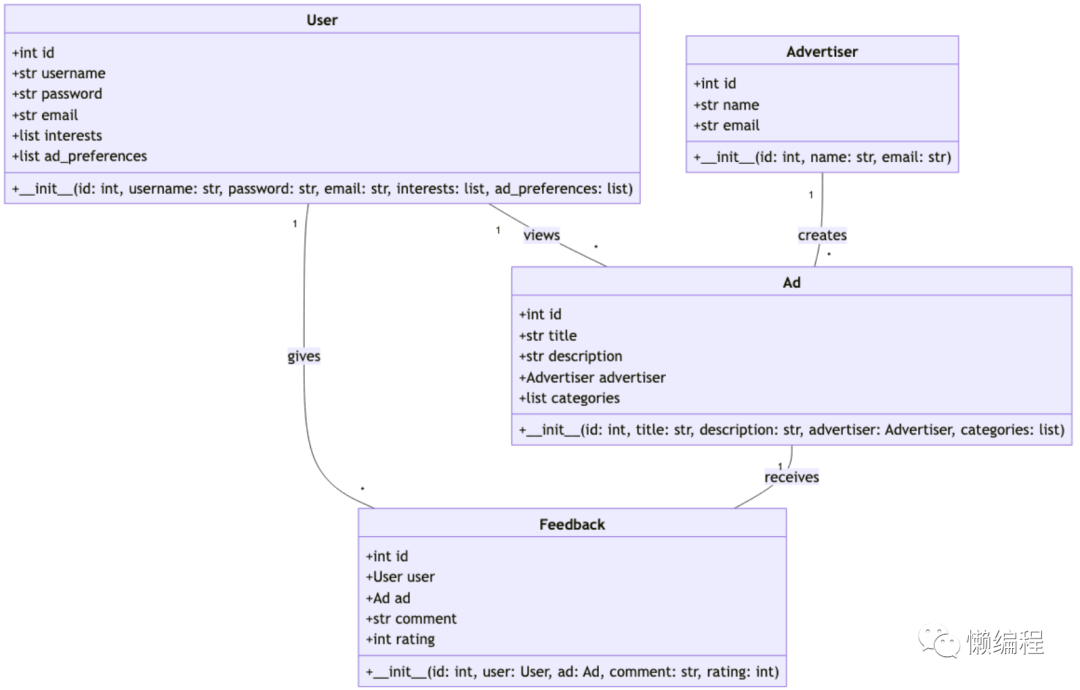
此外,在阅读源码的过程,也发现MetaGPT团队自己提出的一些问题,比如大段的代码受限GPT4的tokens限制还做不到,切开生成,可能又需要提供额外的code作为context,效果也没那么理想。
当然MetaGPT的team我还是很respect的,代码设计清晰,然后让MetaGPT可以实现自举的这个目标也很酷。
以上。
版权归原作者 懒编程-二两 所有, 如有侵权,请联系我们删除。