
来源:投稿 作者:王同学
编辑:学姐
今天我们继续上次的YOLOv5参数解析,这次主要解析源码中train.py文件中包含的参数。
- 1.1'--weights'
- 1.2'--cfg'
- 1.3'--data'
- 1.4'--hyp'
- 1.5'--epochs'
- 1.6'--batch-size'
- 1.7'--imgsz', '--img', '--img-size'
- 1.8'--rect'🍀
- 1.9'--resume'🍀
- 1.10'--nosave'
- 1.11'--noval'
- 1.12'--noautoanchor'🍀
- 1.13'--evolve'🍀
- 1.14'--bucket'
- 1.15'--cache'
- 1.16'--image-weights'
- 1.17'--device'
- 1.18'--multi-scale'🍀
- 1.19'--single-cls'
- 1.20'--optimizer'
- 1.21'--sync-bn'
- 1.22'--workers'
- 1.23'--project'
- 1.24'--name'
- 1.25'--exist-ok'
- 1.26'--quad'
- 1.27'--cos-lr'🍀
- 1.28'--label-smoothing'🍀
- 1.29'--patience'
- 1.30'--freeze'🍀
- 1.31'--save-period'
- 1.32'--local_rank'
- 1.33'--entity'
- 1.34'--upload_dataset'
- 1.35'--bbox_interval'
- 1.36'--artifact_alias'
0.首次运行常见错误🍀
刚拿到代码可以运行train.py文件看看,一般都会出现这个错误:
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.
解决方案:在train.py文件里加入以下代码:
import os
os.environ['KMP_DUPLICATE_LIB_OK']='TRUE'
1.train.py参数解析🚀
首先还是打开根目录下的
train.py
,直接看
parse_opt()
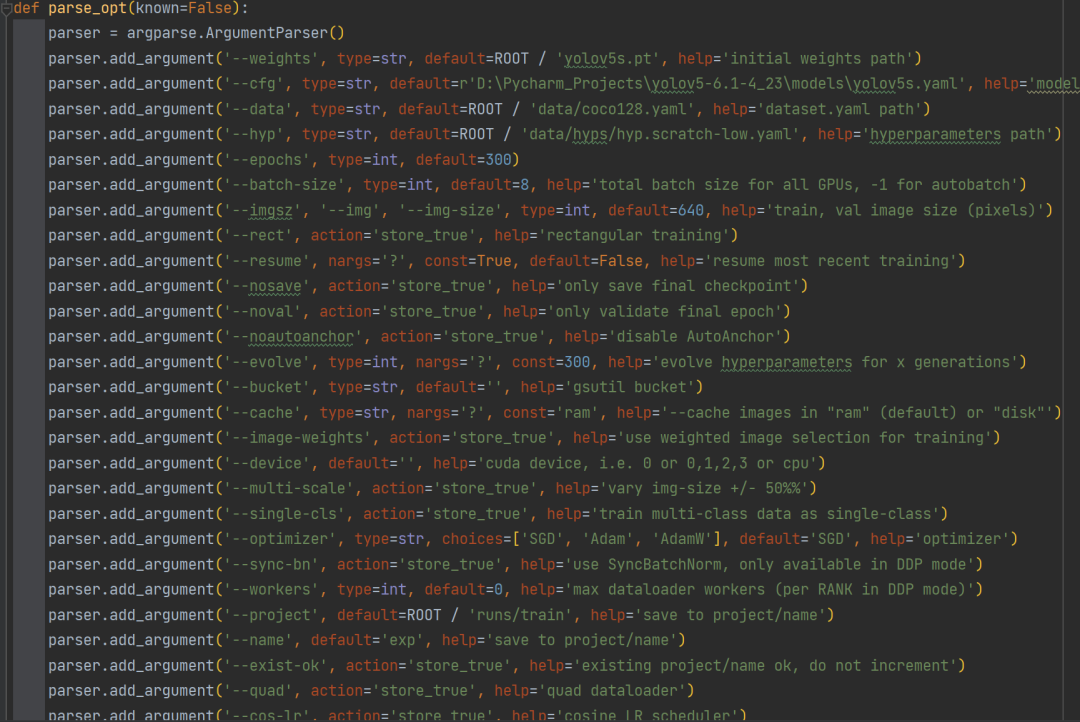
1.1'--weights'
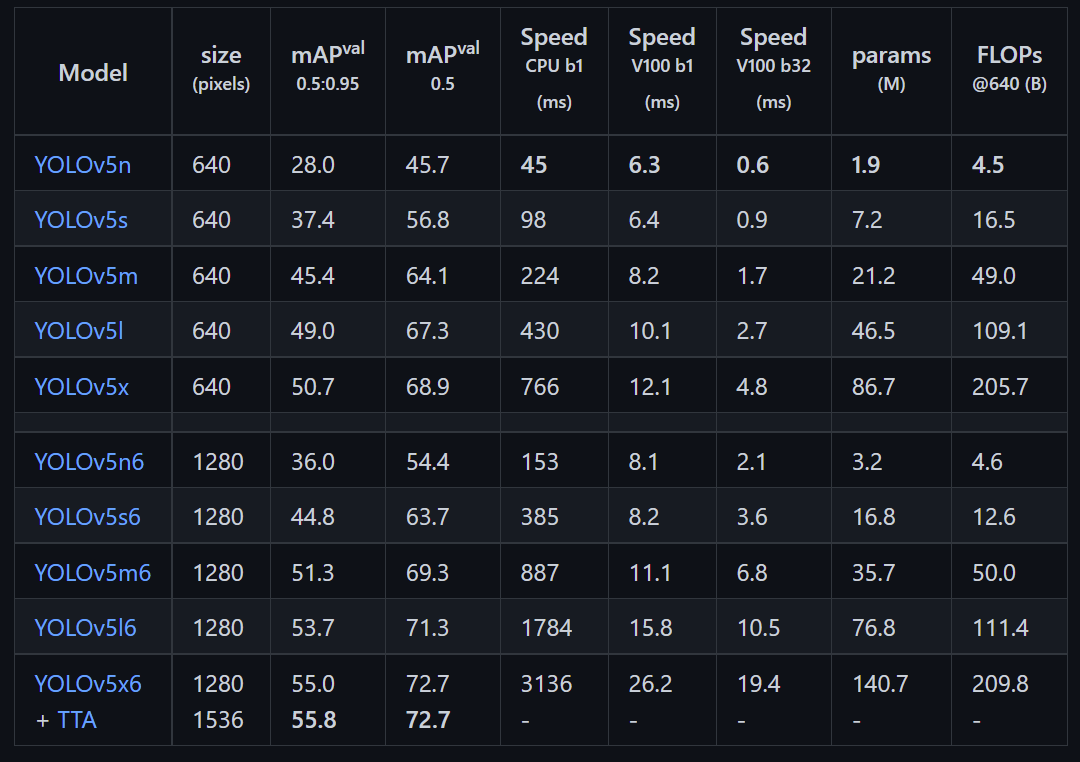
指定预训练权重路径;如果这里设置为空的话,就是自己从头开始进行训练;下图是官方提供的预训练权重
1.2'--cfg'
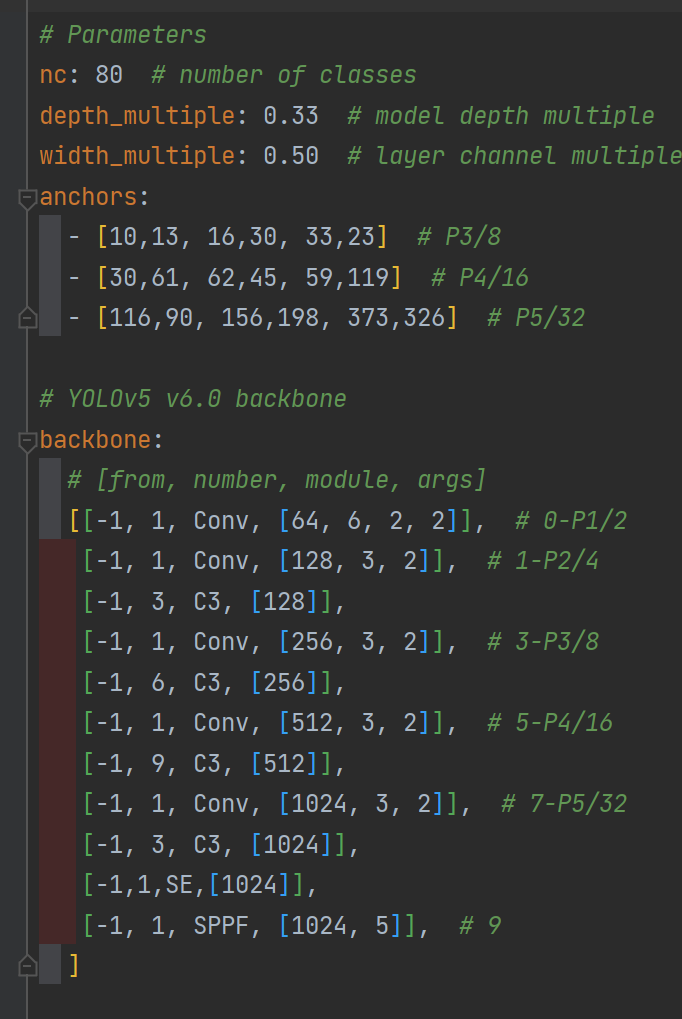
指定模型配置文件路径的;源码里面提供了这5个配置文件,配置文件里面指定了一些参数信息和backbone的结构信息。
1.3'--data'

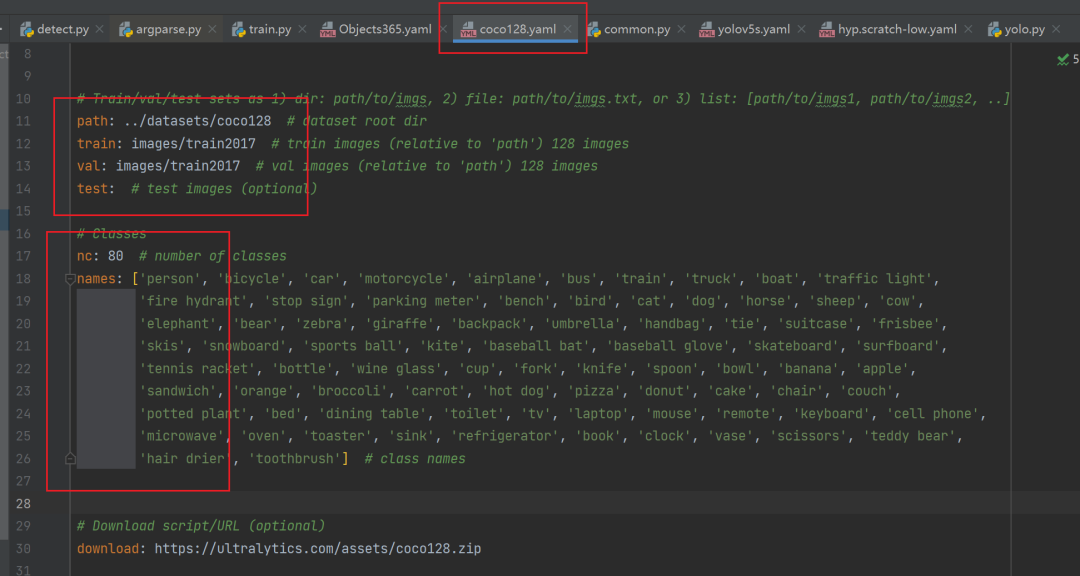
数据集对应的参数文件;里面主要存放数据集的类别和路径信息。
yolo源码里面提供了9种数据集的配置文件
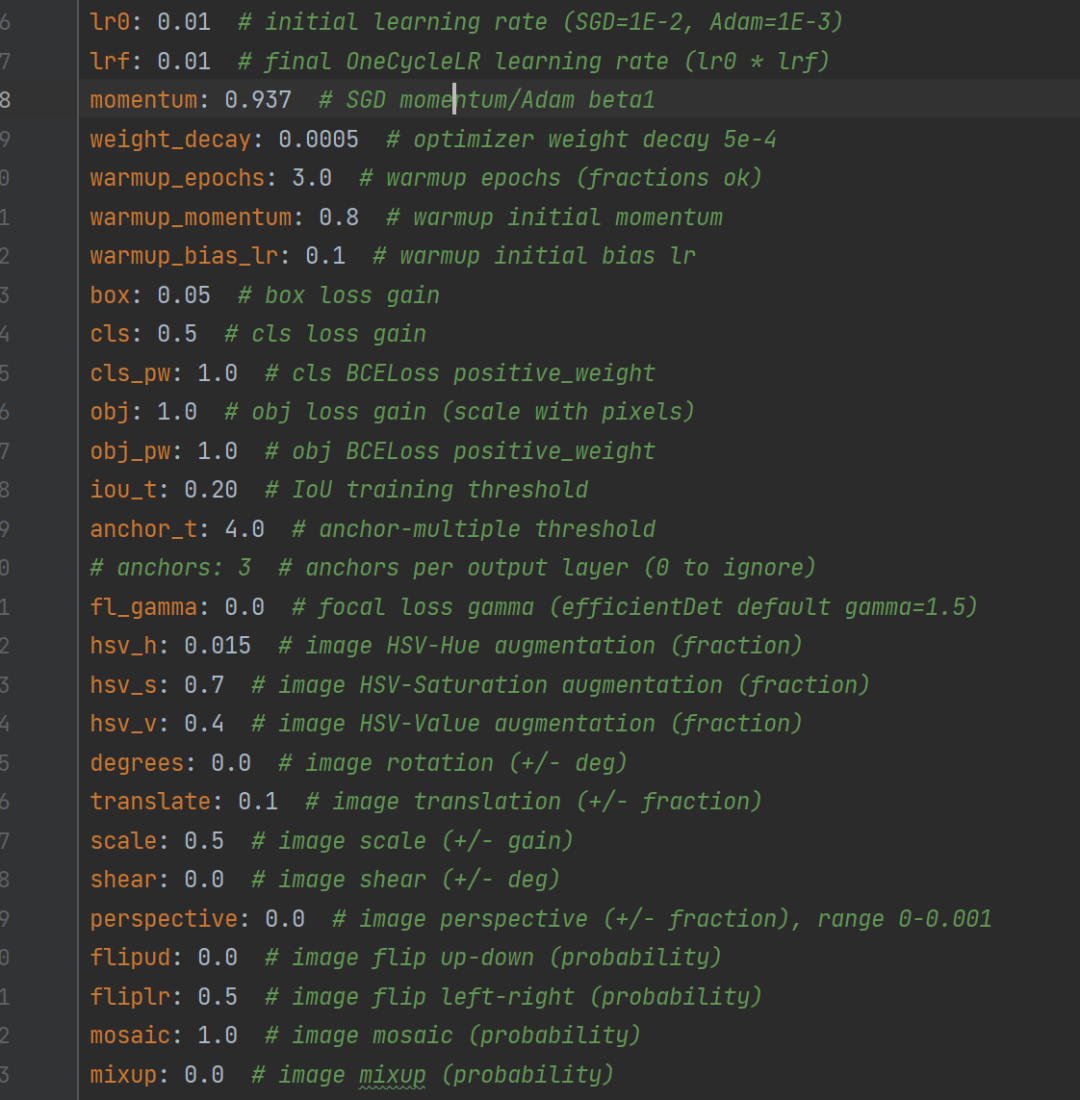
1.4'--hyp'

指定超参数文件的路径;超参数里面包含了大量的参数信息,同样提供了5个
1.5'--epochs'

训练的轮数;默认为300轮,显示效果是0-299
1.6'--batch-size'

每批次的输入数据量;
default=-1
将时自动调节
batchsize
大小。
这里说一下epoch、batchsize、iteration三者之间的联系
1、batchsize是批次大小,假如取batchsize=24,则表示每次训练时在训练集中取24个训练样本进行训练。
2、iteration是迭代次数,1个iteration就等于一次使用24(batchsize大小)个样本进行训练。
3、epoch:1个epoch就等于使用训练集中全部样本训练1次。
1.7'--imgsz', '--img', '--img-size'

训练集和测试集图片的像素大小;输入默认640*640,这个参数在你选择yolov5l那些大一点的权重的时候,要进行适当的调整,这样才能达到好的效果。
1.8'--rect'🍀

是否采用矩阵推理的方式去训练模型;
所谓矩阵推理就是不再要求你训练的图片是正方形了;矩阵推理会加速模型的推理过程,减少一些冗余信息。
下图分别是方形推理方式和矩阵推理方式


1.9'--resume'🍀

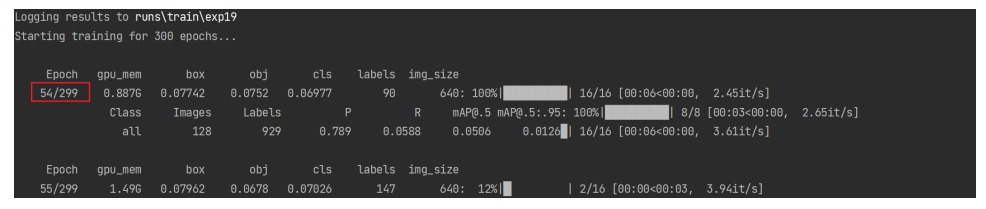
断点续训:即是否在之前训练的一个模型基础上继续训练,default 值默认是 false;如果想采用断点续训的方式,这里我推荐一种写法,即首先将default=False 改为 default=True 随后在终端中键入如下指令
python train.py --resume D:\Pycharm_Projects\yolov5-6.1-4_23\runs\train\exp19\weights\last.pt
==D:\Pycharm_Projects\yolov5-6.1-4_23\runs\train\exp19\weights\last.pt==为你上一次中断时保存的pt文件路径
输入指令后就可以看到模型是继续从上次结束时开始训练的
1.10'--nosave'

是否只保存最后一轮的pt文件;我们默认是保存best.pt和last.pt两个的
1.11'--noval'

只在最后一轮测试;正常情况下每个epoch都会计算mAP,但如果开启了这个参数,那么就只在最后一轮上进行测试,不建议开启
1.12'--noautoanchor'🍀

是否禁用自动锚框;默认是开启的,自动锚点的好处是可以简化训练过程;
yolov5中预先设定了一下锚定框,这些锚框是针对coco数据集的,其他目标检测也适用,可以在models/yolov5.文件中查看,例如如图所示,这些框针对的图片大小是640640。这是默认的anchor大小。需要注意的是在目标检测任务中,一般使用大特征图上去检测小目标,因为大特征图含有更多小目标信息,因此大特征图上的anchor数值通常设置为小数值,小特征图检测大目标,因此小特征图上anchor数值设置较大。
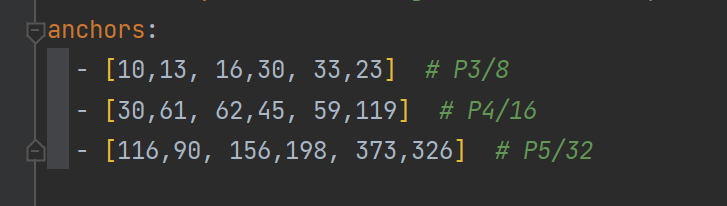
在yolov5 中自动锚定框选项,训练开始前,会自动计算数据集标注信息针对默认锚定框的最佳召回率,当最佳召回率大于等于0.98时,则不需要更新锚定框;如果最佳召回率小于0.98,则需要重新计算符合此数据集的锚定框。在parse_opt设置了默认自动计算锚框选项,如果不想自动计算,可以设置这个,建议不要改动。
1.13'--evolve'🍀

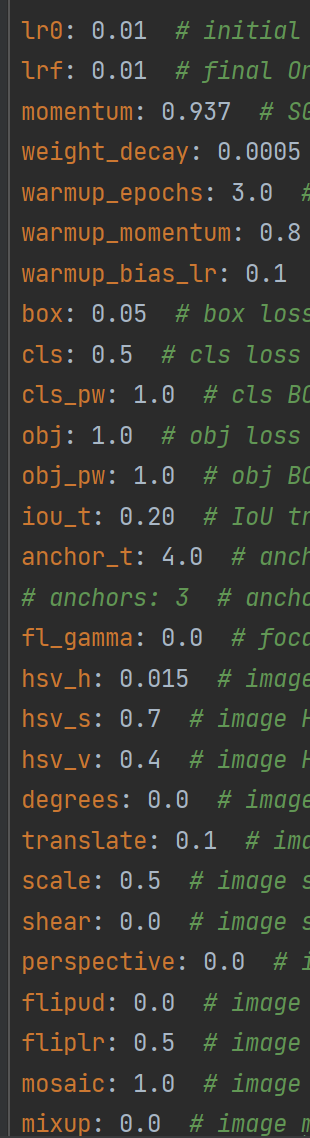
遗传超参数进化;yolov5使用遗传超参数进化,提供的默认参数是通过在COCO数据集上使用超参数进化得来的(也就是下图这些参数)。由于超参数进化会耗费大量的资源和时间,所以建议大家不要动这个参数。
遗传算法是利用种群搜索技术将种群作为一组问题解,通过对当前种群施加类似生物遗传环境因素的选择、交叉、变异等一系列的遗传操作来产生新一代的种群,并逐步使种群优化到包含近似最优解的状态,遗传算法调优能够求出优化问题的全局最优解,优化结果与初始条件无关,算法独立于求解域,具有较强的鲁棒性,适合于求解复杂的优化问题,应用较为广泛。
1.14'--bucket'

谷歌云盘;通过这个参数可以下载谷歌云盘上的一些东西,但是现在没必要使用了
1.15'--cache'

是否提前缓存图片到内存,以加快训练速度,默认False;开启这个参数就会对图片进行缓存,从而更好的训练模型。
1.16'--image-weights'

是否启用加权图像策略,默认是不开启的;主要是为了解决样本不平衡问题;开启后会对于上一轮训练效果不好的图片,在下一轮中增加一些权重;
1.17'--device'

设备选择;这个参数就是指定硬件设备的,系统会自己判断的
1.18'--multi-scale'🍀

是否启用多尺度训练,默认是不开启的;多尺度训练是指设置几种不同的图片输入尺度,训练时每隔一定iterations随机选取一种尺度训练,这样训练出来的模型鲁棒性更强。
多尺度训练在比赛中经常可以看到他身影,是被证明了有效提高性能的方式。输入图片的尺寸对检测模型的性能影响很大,在基础网络部分常常会生成比原图小数十倍的特征图,导致小物体的特征描述不容易被检测网络捕捉。通过输入更大、更多尺寸的图片进行训练,能够在一定程度上提高检测模型对物体大小的鲁棒性。
1.19'--single-cls'

设定训练数据集是单类别还是多类别;默认为 false多类别
1.20'--optimizer'

选择优化器;默认为SGD,可选SGD,Adam,AdamW
1.21'--sync-bn'

是否开启跨卡同步BN;开启参数后即可使用 SyncBatchNorm多 GPU 进行分布式训练
1.22'--workers'

最大worker数量;这里经常出问题,建议设置成0
1.23'--project'

指定训练好的模型的保存路径;默认在runs/train
1.24'--name'

设定保存的模型文件夹名,默认在exp;
1.25'--exist-ok'

每次预测模型的结果是否保存在原来的文件夹;如果指定了这个参数的话,那么本次预测的结果还是保存在上一次保存的文件夹里;如果不指定就是每次预测结果保存一个新的文件夹下。
1.26'--quad'

官方给出的开启这个功能后的实际效果:
- 好处是在比默认 640 大的数据集上训练效果更好
- 副作用是在 640 大小的数据集上训练效果可能会差一些
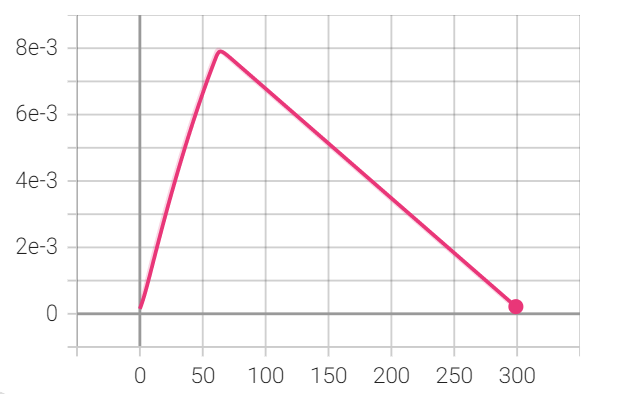
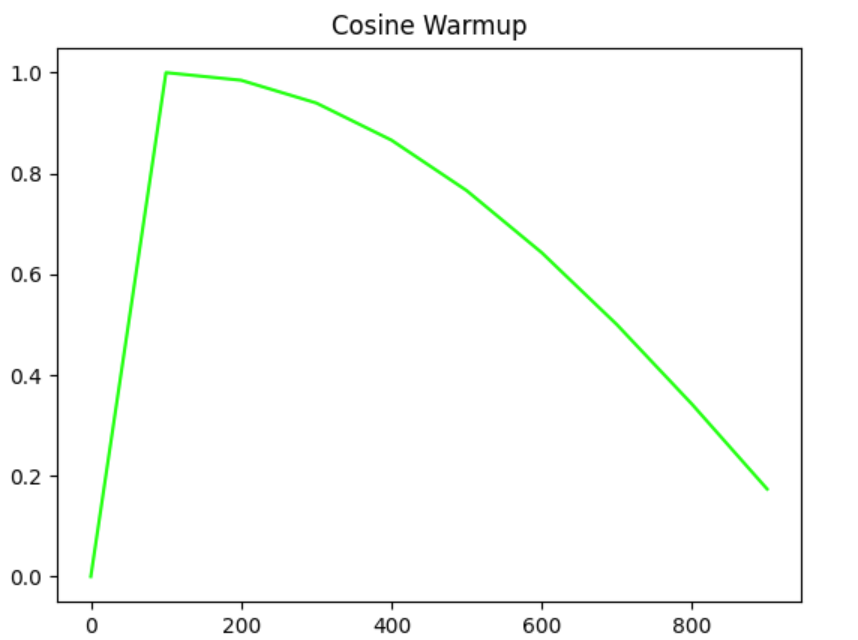
1.27'--cos-lr'🍀

是否开启余弦学习率;

这是我不采用cos-lr时学习率的曲线:
开启后的学习率应该是这样子:
1.28'--label-smoothing'🍀

是否对标签进行平滑处理,默认是不启用的;
在训练样本中,我们并不能保证所有sample都标注正确,如果某个样本标注错误,就可能产生负面印象,如果我们有办法“告诉”模型,样本的标签不一定正确,那么训练出来的模型对于少量的样本错误就会有“免疫力”采用随机化的标签作为训练数据时,损失函数有1-ε的概率与上面的式子相同,比如说告诉模型只有0.95概率是那个标签。
1.29'--patience'

早停;如果模型在default值轮数里没有提升,则停止训练模型
1.30'--freeze'🍀

指定冻结层数量;可以在yolov5s.yaml中查看主干网络层数。
冻结训练是迁移学习常用的方法,当我们在使用数据量不足的情况下,通常我们会选择公共数据集提供权重作为预训练权重,我们知道网络的backbone主要是用来提取特征用的,一般大型数据集训练好的权重主干特征提取能力是比较强的,这个时候我们只需要冻结主干网络,fine-tune后面层就可以了,不需要从头开始训练,大大减少了实践而且还提高了性能。
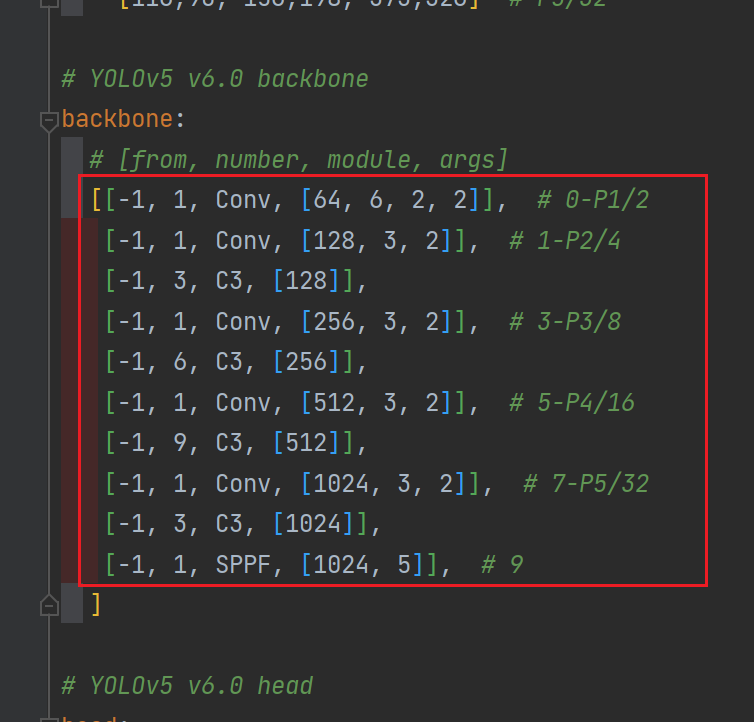
例如如下指令,代表冻结前8层,因为只有9层,注意不要超过9
python train.py --freeze 8
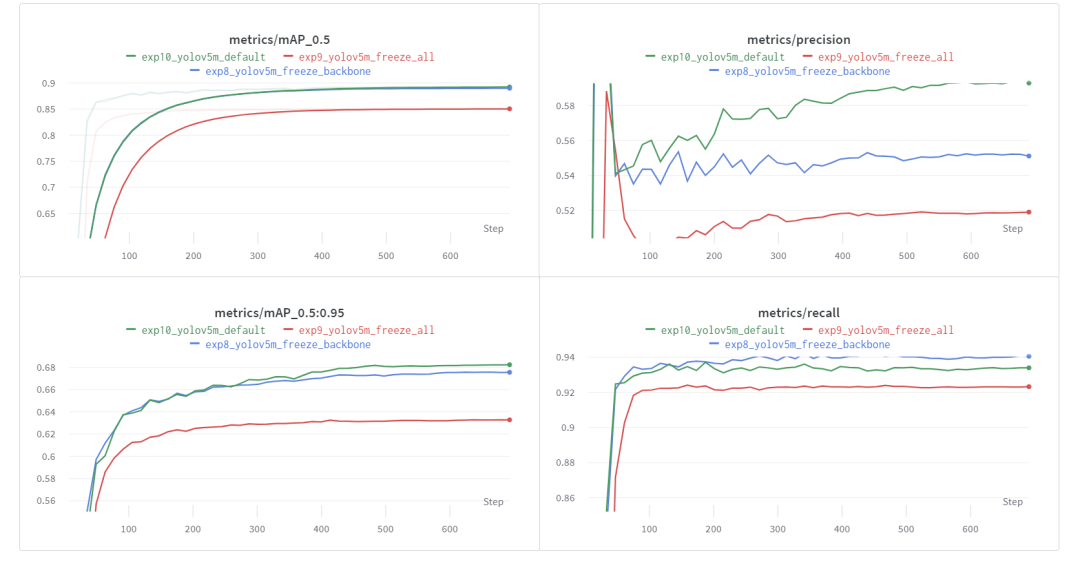
这里分享一个对比冻结效果的项目
这里是项目的部分截图
1.31'--save-period'

用于设置多少个epoch保存一下checkpoint;
1.32'--local_rank'

DistributedDataParallel 单机多卡训练,单GPU设备不需要设置;
1.33'--entity'

在线可视化工具,类似于tensorboard
1.34'--upload_dataset'

是否上传dataset到wandb tabel(将数据集作为交互式 dsviz表 在浏览器中查看、查询、筛选和分析数据集) 默认False
1.35'--bbox_interval'

设置界框图像记录间隔 Set bounding-box image logging interval for W&B 默认-1
1.36'--artifact_alias'

功能作者还未实现
小彩蛋🎉
当我们设置完参数以后,可以通过如下的方式来查看参数具体的值,这里拿detect.py文件举例
第一步:在这个位置打个断点

第二步:点击“debug”
第三步:点击“步过”
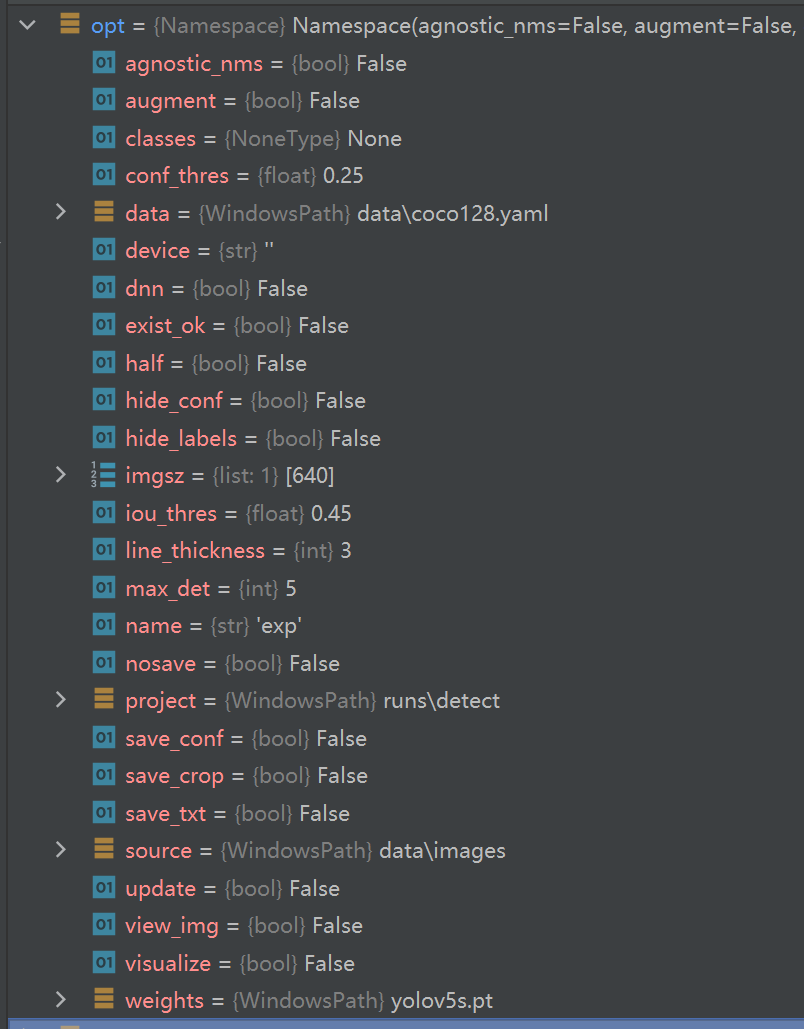
最后一步:展开opt就可以看到我们的参数信息啦
有问题欢迎大家指正,如果感觉有帮助的话请点赞支持下👍📖🌟
Yolo系列论文+代码数据集🚀🚀🚀
点击下方卡片关注****《学姐带你玩AI》回复“YOLO”即可领取
码字不易,欢迎大家点赞评论收藏!
版权归原作者 深度之眼 所有, 如有侵权,请联系我们删除。