
历时一个月的构想+代码实现+调式和修改,DNA终于完工了。
项目名称:DNA - AI辅助问答笔记检索系统
随着人工智能技术的不断发展,我们的日常生活也逐渐与AI技术融合。DNA项目旨在结合人工智能和日常笔记,打造一款便捷的问答式检索系统,让用户能够通过简单的提问,快速准确地找到所需笔记信息。
项目作用:
用于AI式的管理自己的笔记内容,你的所有笔记汇集在一起就是你自己的AI数据模型。而你向AI问的问题优先向量内容来源于你自己的模型数据。类使用你拥有一个数据管家,你只需要安心记录自己的笔记文档,当你遇到问题的时候可用直接向这个管家提问。
项目背景:
最早想法来源于去年chatGPT刚刚爆火的那段时间,当时实习的我在公司所负责的项目就是接入chatGPT的API主导开发了一个GPT助手丛小程序转战到后面的桌面端,又加上自己是一个比较喜欢写文档的人。那个时候就想过如果可以指定模型数据就好了,这样自己需要找自己写的笔记的时候就不需要翻笔记了,只需要输入问题就可以找到了。但是那个时候技术和认知有限,停留在了想法。
最终确定要做还是看了鱼皮的抖音的提到了阿里百炼大模型鱼皮程序员,他们公司也是通过阿里百炼手动上传自己公司文档,然后检索。我就想这个可以啊,有了可用的模型那我二次开发不就好了,我给他来个自动的。于是我就去了解和构想是否可行,可是申请下来阿里云百炼发现,他只有开放的问答的API的接口,上传模型文件只能手动。这不简单,他不给接口那就上爬虫,于是我便就开始招兵买马开始构建这个项目。

蓝同学主页:hhxcaz
老毕主页:cxzcd45631
历程:
刚刚开始就是我一个人找找开源的笔记的软件,最后确定了用trilium,然后开始寻找trilium存储数据的地方,然后接触了sqlite数据库。把笔记软件敲定以后我就开始写后端。将笔记内容读取并且做好了定时加载打包成PDF。
我开始攻克爬虫,因为自己会selenium,打算用selenium做。但是后面遇到了阿里反爬和阿里的滑块认证。进度卡着动不了。于是我开始找人,找到了自己朋友老毕,他现在工作就是爬虫,将他骗入伙。但是他也就解决了上传模型数据这些功能,这些功能API需要的cookie和sec_token他那边还是没有办法获取。于是我就想到了使用selenium做登入获取到这两个参数在给他使用。于是我开始研究,解决了滑块验证和阿里的反爬成功登入获取到了这两个参数并且测试可用。
迎面而来遇到了第二个小问题就是老毕用的Python写的爬虫,我的项目是Java的,包括selenium也是用Java写的,起初为了偷懒,想过使用Java调用Python执行将参数给他,但是这样多多少少不方便也增加了环境依赖,主要的是不稳定不好监控。于是只能将他写好的爬虫读懂,然后写成Java的。
后端基本上干完以后我就开始自己写前端,写啊写啊写啊写啊,我发些自己写的不好,我前端属于二流的。于是写了一半的我找到了以前的合作伙伴”蓝同学“,于是他也被我骗到了这个项目中,于是两个人开始敲啊敲啊,改啊改啊改,我就像万恶的产品经理,pull他的代码,然后看,然后”指点江山“,和他说需求,让他改样式。我不知道他有没有后悔,反正我是挺爽的。
11月28号前端后端爬虫都测试完了。DNA1.0完成。
总体花了一个月时间,时间比预算超出一倍时间,因为在学校还要兼顾学业所以前期速度比较慢。
客户端源码地址:https://gitee.com/paigujun/dna_client
服务端源码地址:https://gitee.com/paigujun/dna_service
资源文件地址:https://gitee.com/paigujun/dna_assets
自己搭建流程:
在搭建开始的时候我先介绍一下项目开发环境
后端:
Java version 1.8
springboot version 2.6.13
前端:
vue version 2
nodejs version
必看
我自己搭建是搭建在自己的云服务器上,有一些友仔可能没有云服务器,也可以部署在自己虚拟机上,主要通网络就行了。首先和大家说一下云服务器和虚拟机部署的区别,唯一区别就是trilium笔记软件是否可以在哪里都可以访问,在云服务器的话只要通网络的地方就可以访问到笔记和修改查看内容,在虚拟机你就只能在自己局域网访问,想要外面也可以访问只能做内网穿透。内网穿透的教程有空我在做,网络上也有很多可以自己找一下。
以下是搭建全部流程,每个流程都单独
- 需要拥有一个自己的阿里云百炼内测资格 阿里云百炼申请很简单,按照我的这个博客一步步完成 申请流程:阿里云百炼申请流程
- 在等待申请内测资格的同时可用先搭建自己的私域trilium笔记 搭建流程:搭建trilium笔记到Linux下
- 在服务器安装Docker 安装流程:安装Docker
- 安装DNA服务端 安装流程:DNA智能笔记服务端部署流程
- 安装DNA客户端 安装流程:DNA智能笔记客户端前端部署流程
部署成功以后笔记页面和客户端页面使用流程
trilium笔记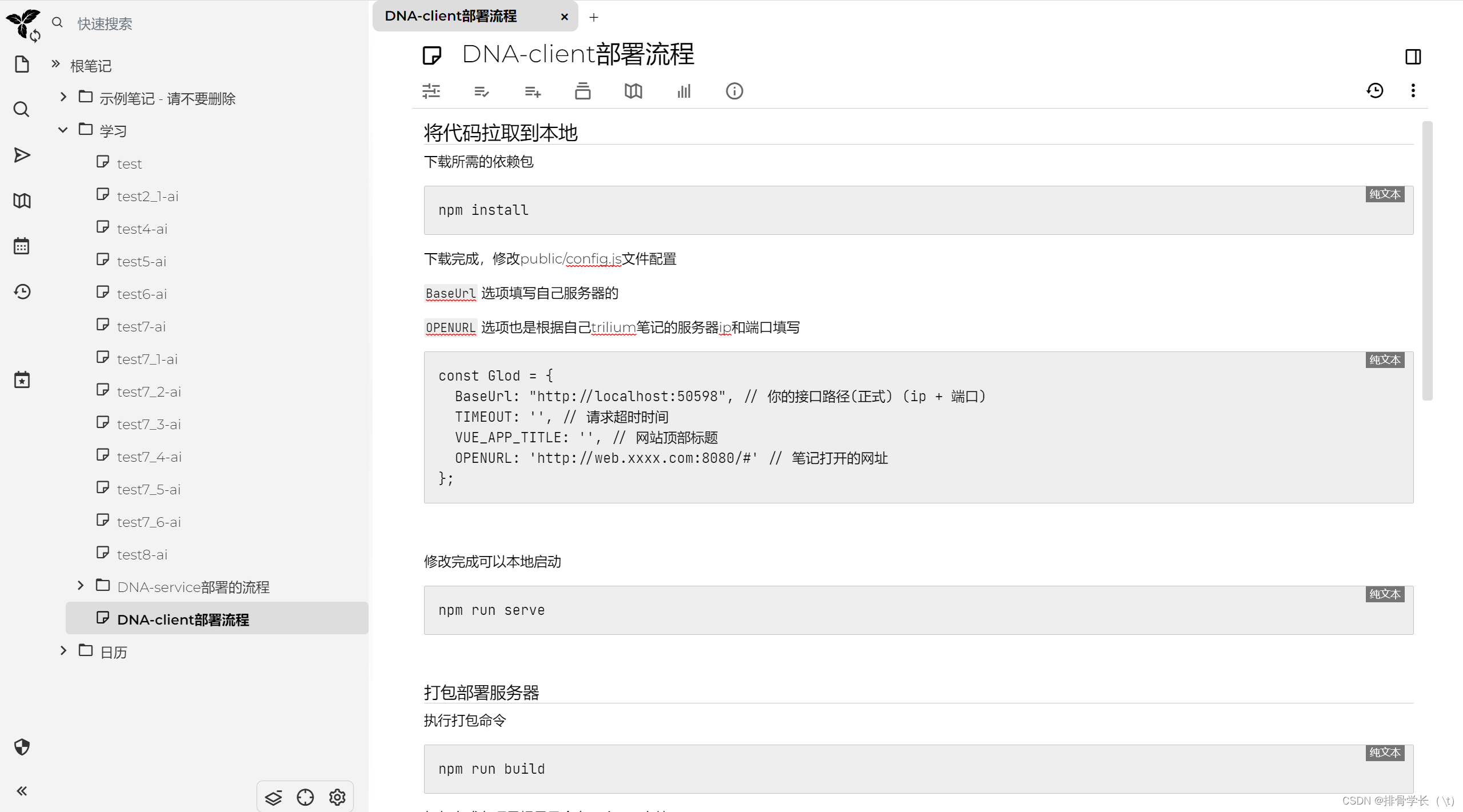
客户端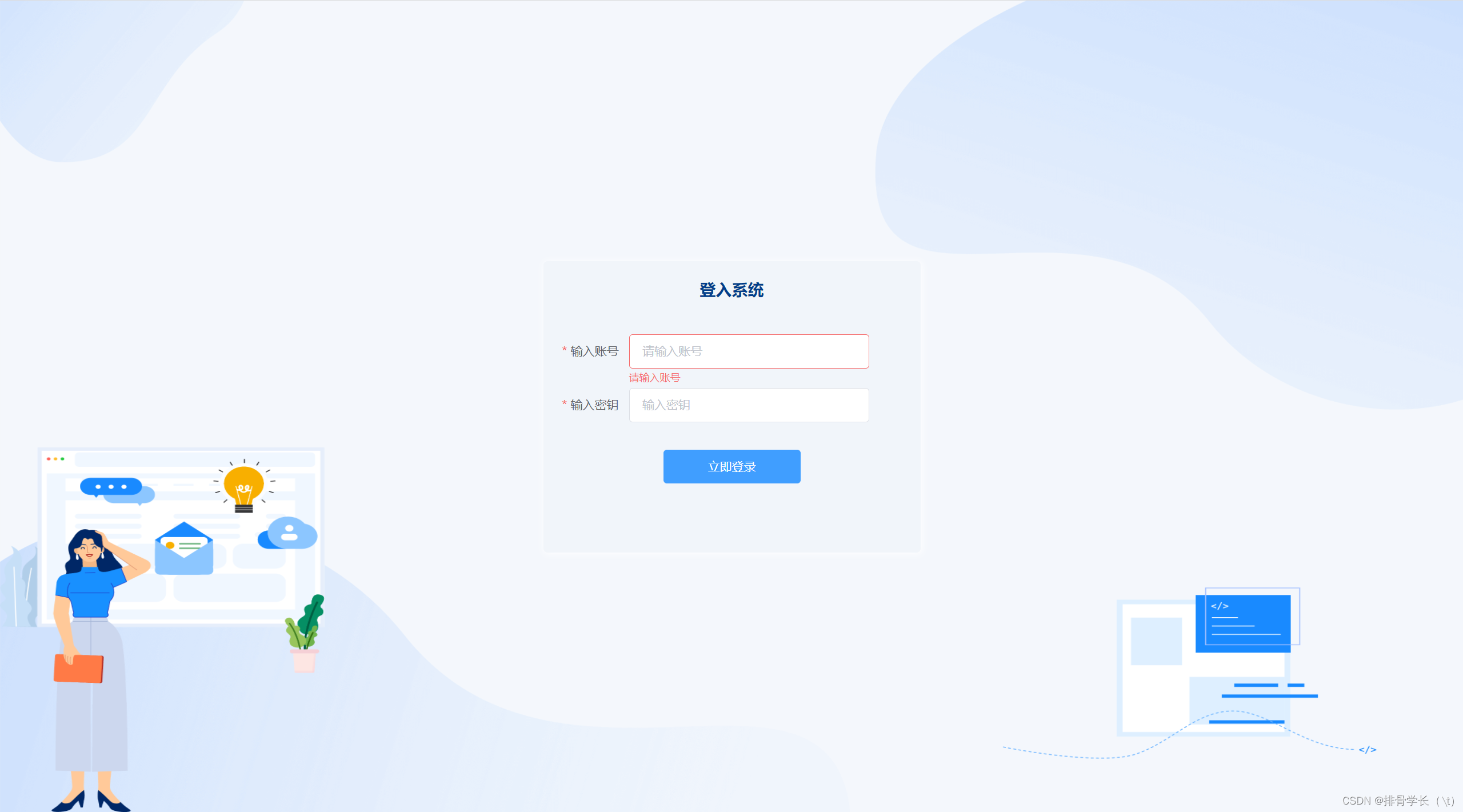
这里客户端登入账号就是你的这里账号,也就是你配置在服务端的application.yml文件中的aliyunaccount配置的账号,下面的密钥就是你的MFA验证码,就是在Google Authenticator验证器中的动态验证码
登入成功以后
这是提问检索页面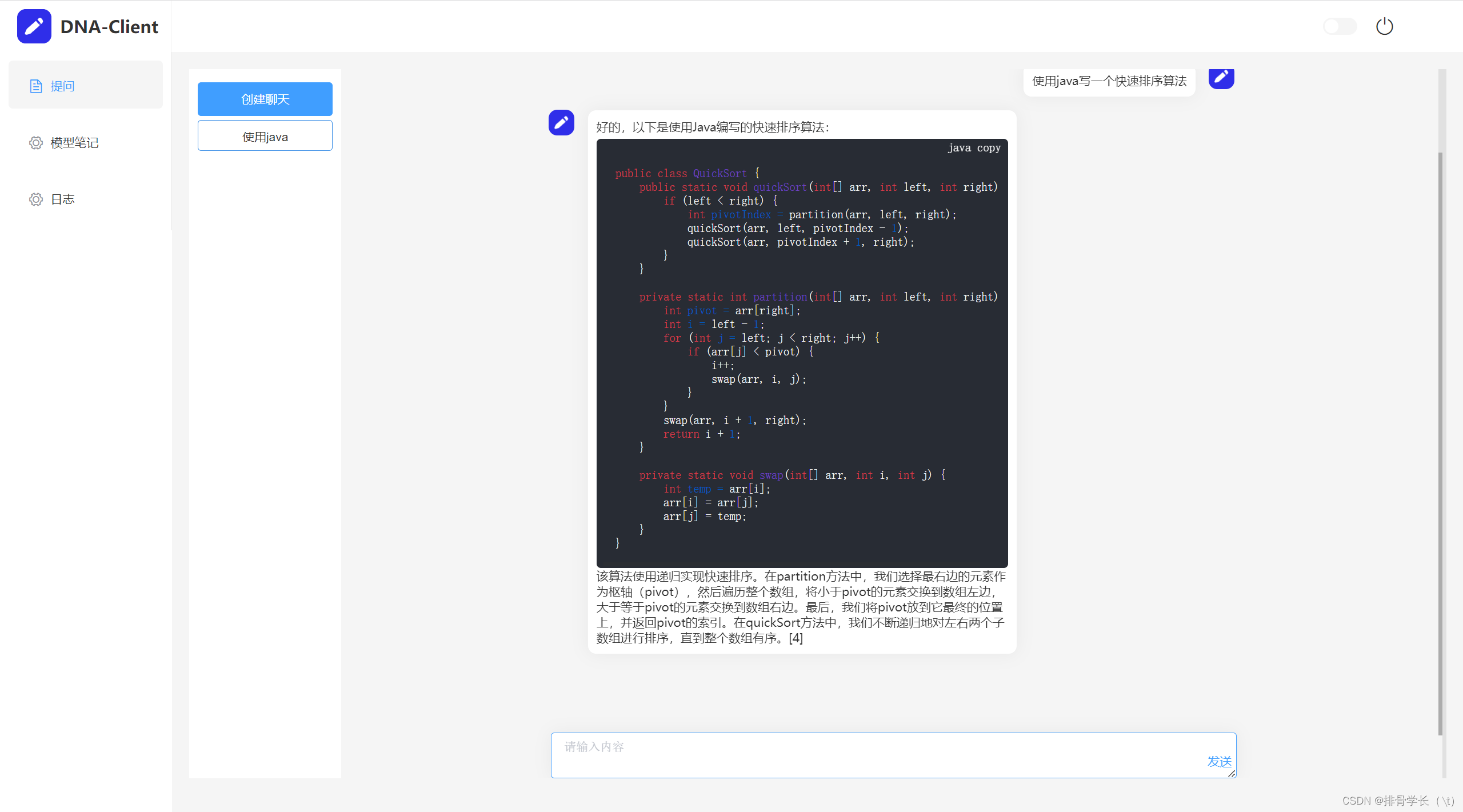
这里是已经上传到模型的笔记页面(点击查看详情可以跳转到指定的笔记页面)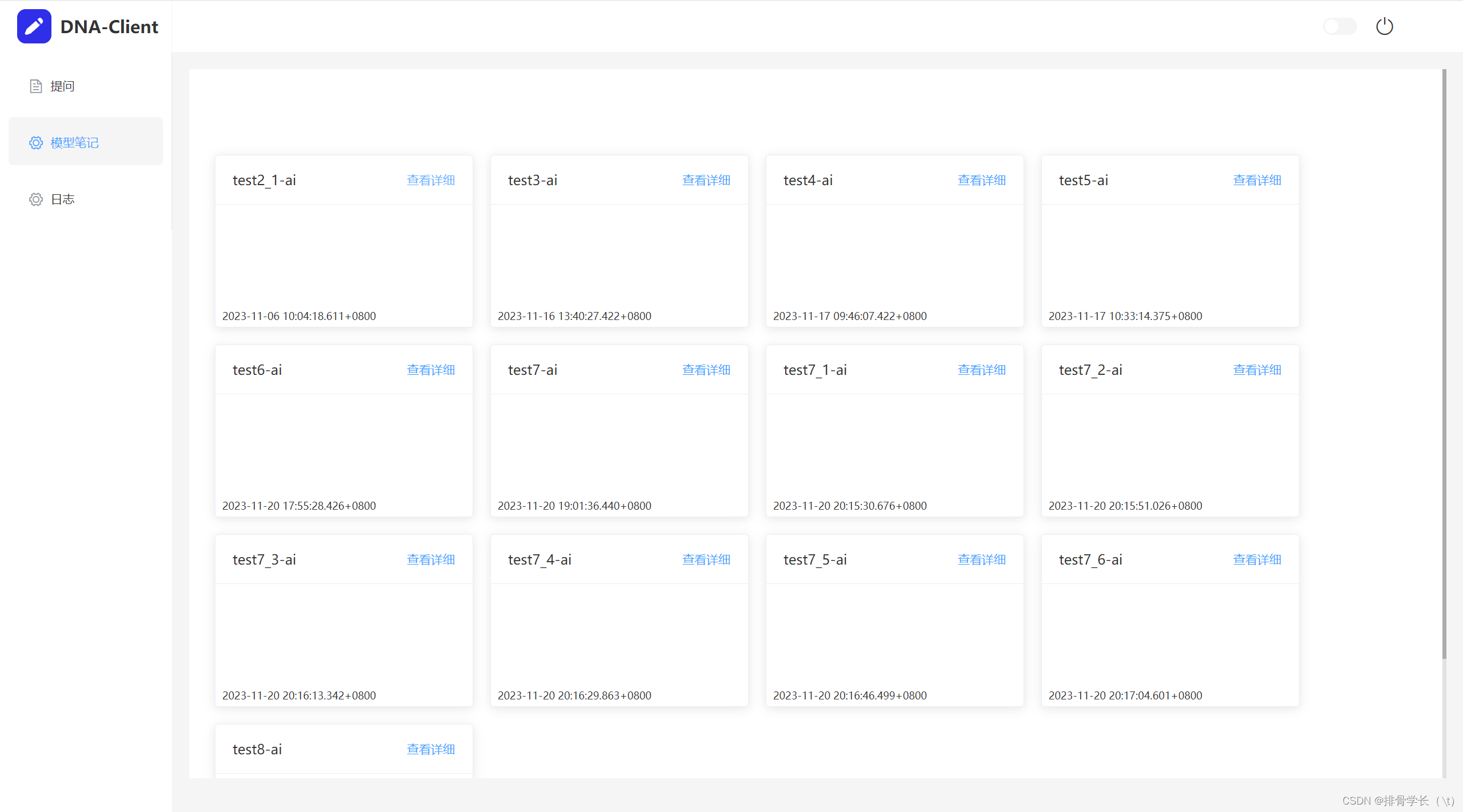
这是服务器日志页面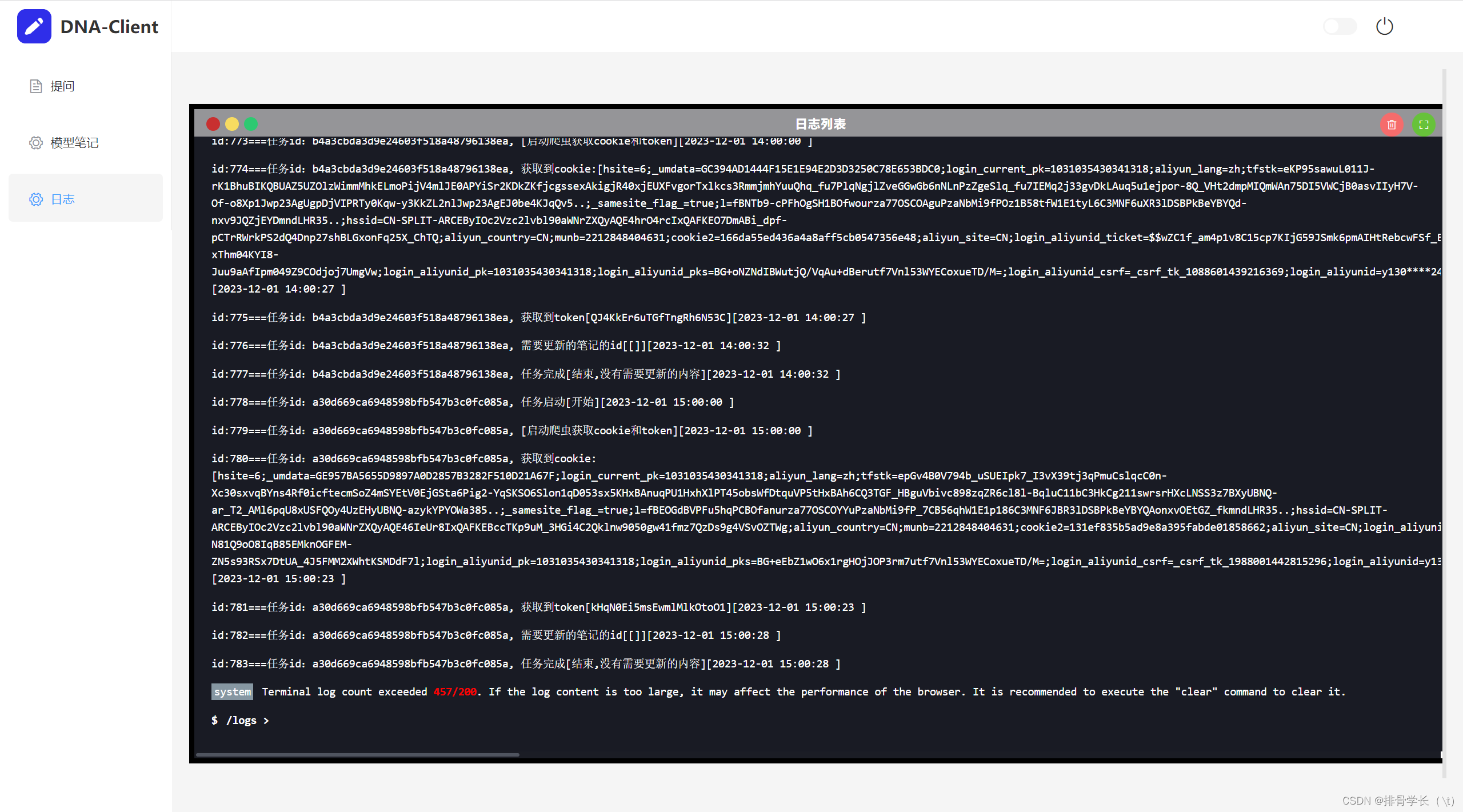
询问效果测试
我在trilium笔记创建一篇文章:一键scp-ai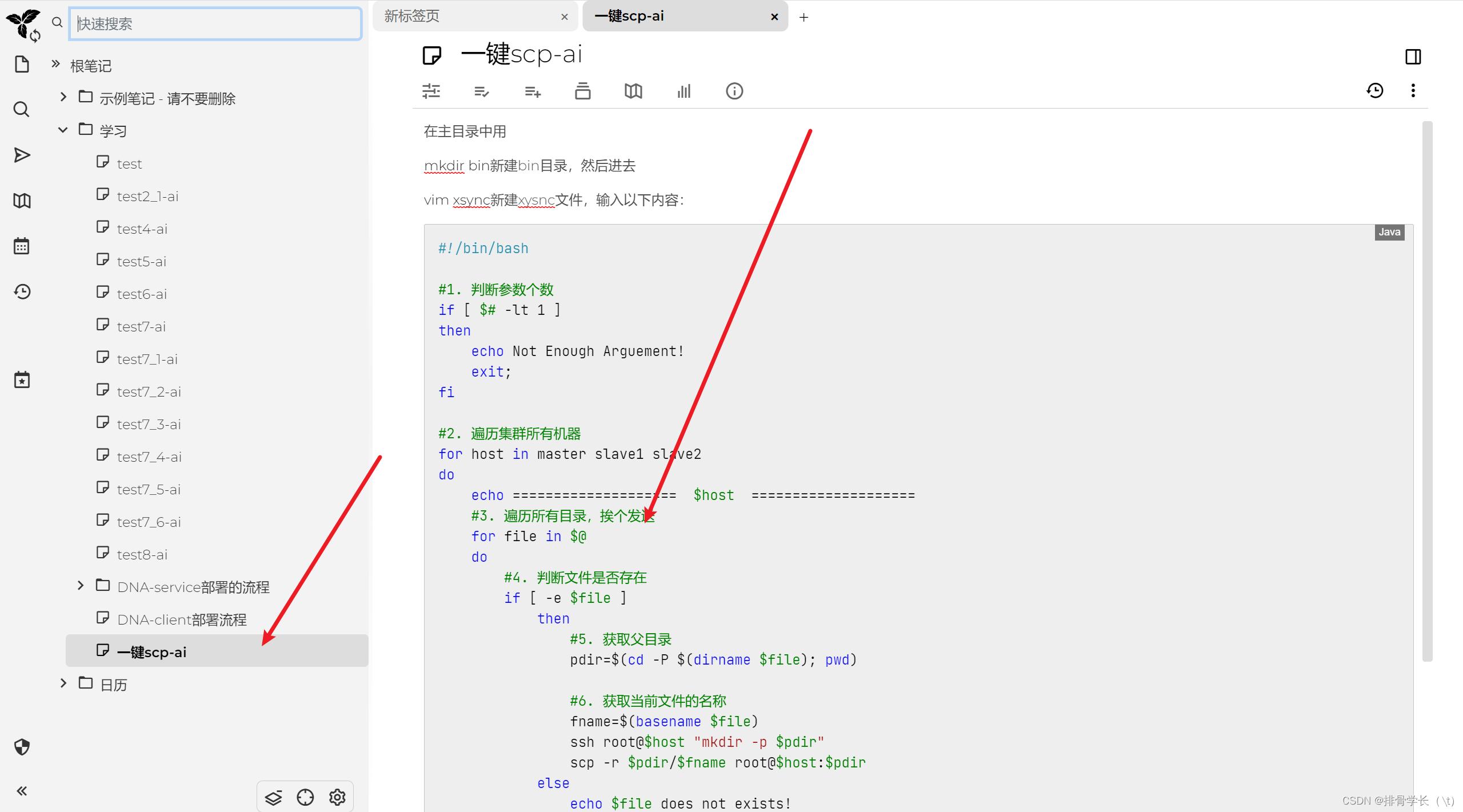
等待整点更新模型
在客户端就可以看见有这个笔记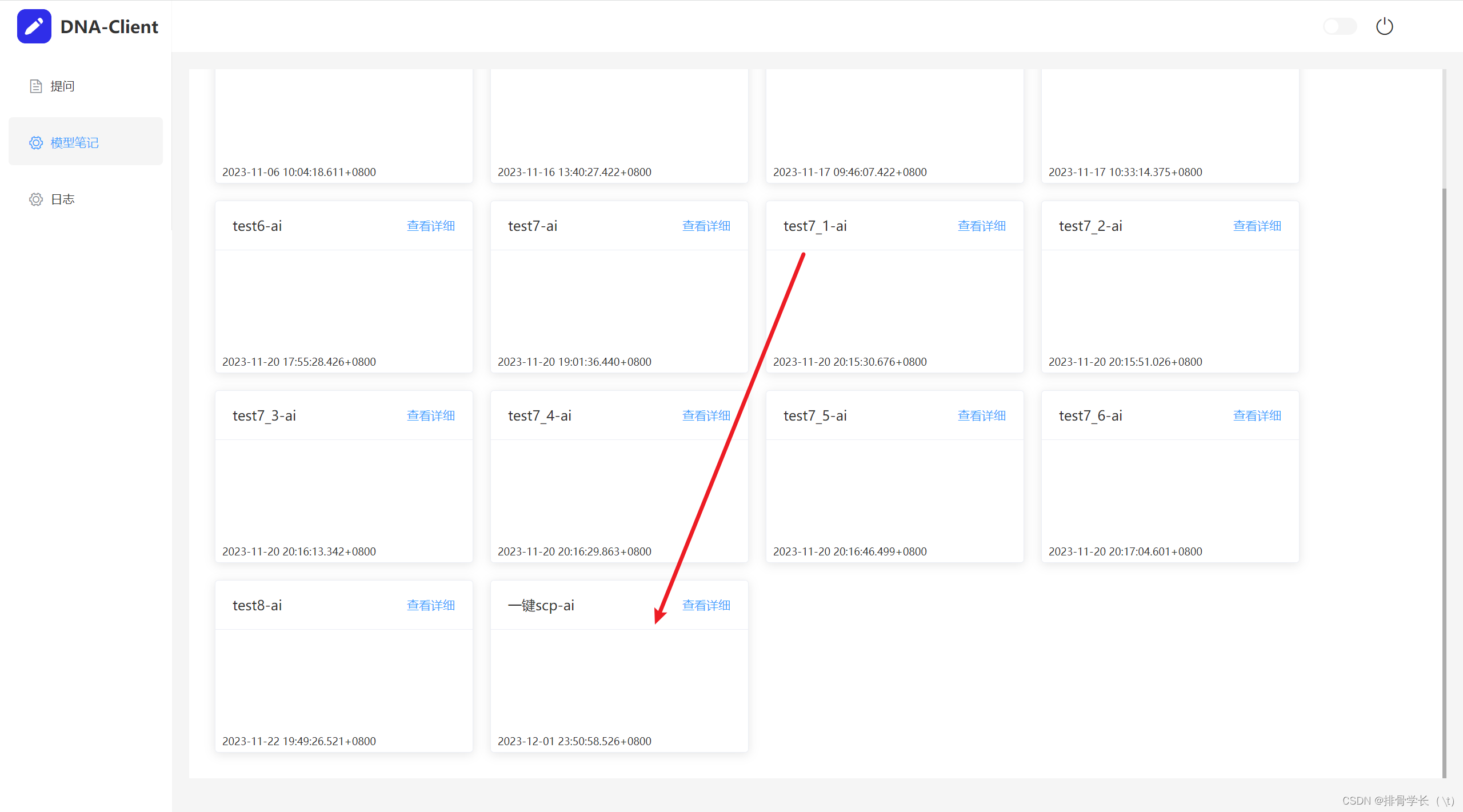
然后我们在客户端提问:一键scp
现在在这里看到他回答的内容就和我们添加的笔记内容是一样的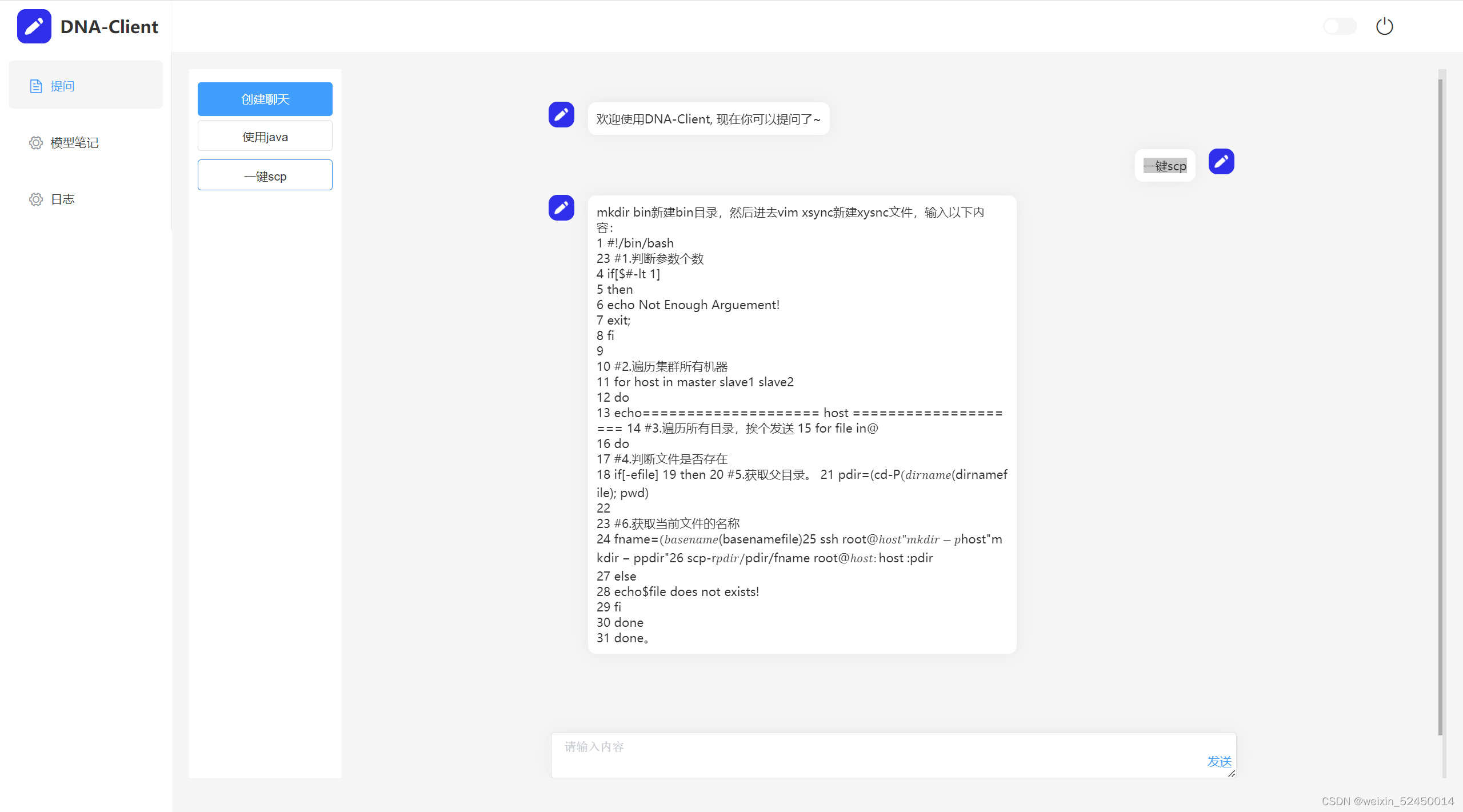
项目主体是写完了,但是还是有很多不足待优化的地方,我有空也会继续优化增加新功能更新迭代现在的系统。各位大佬看见了可以提提意见,让我们进步进步。
版权归原作者 排骨学长(\t) 所有, 如有侵权,请联系我们删除。