
系列文章目录
上手第一关,手把手教你安装kafka与可视化工具kafka-eagle
Kafka是什么,以及如何使用SpringBoot对接Kafka
架构必备能力——kafka的选型对比及应用场景
Kafka存取原理与实现分析,打破面试难关
防止消息丢失与消息重复——Kafka可靠性分析及优化实践
保障效率与可靠性,详细分析Kafka的消费者组与Rebalance机制

我们上一期从可靠性分析了消息可靠性方面来分析Kafka的机制与原理,知晓了Kafka为了保障消息不丢失、不重复,所作出的种种设计。今天我们来讲关于Kafka在消费端所作出的一些机制与原理
📕作者简介:战斧,从事金融IT行业,有着多年一线开发、架构经验;爱好广泛,乐于分享,致力于创作更多高质量内容
📗本文收录于 kafka 专栏,有需要者,可直接订阅专栏实时获取更新
📘高质量专栏 云原生、RabbitMQ、Spring全家桶 等仍在更新,欢迎指导
📙Zookeeper Redis dubbo docker netty等诸多框架,以及架构与分布式专题即将上线,敬请期待
一、消费者组概念
我们其实在很多MQ组件种都有消费者组的概念,在Kafka中也不例外。消费者组与Kafka的Rebalance机制是保障Kafka消息消费效率与可用性的重要手段。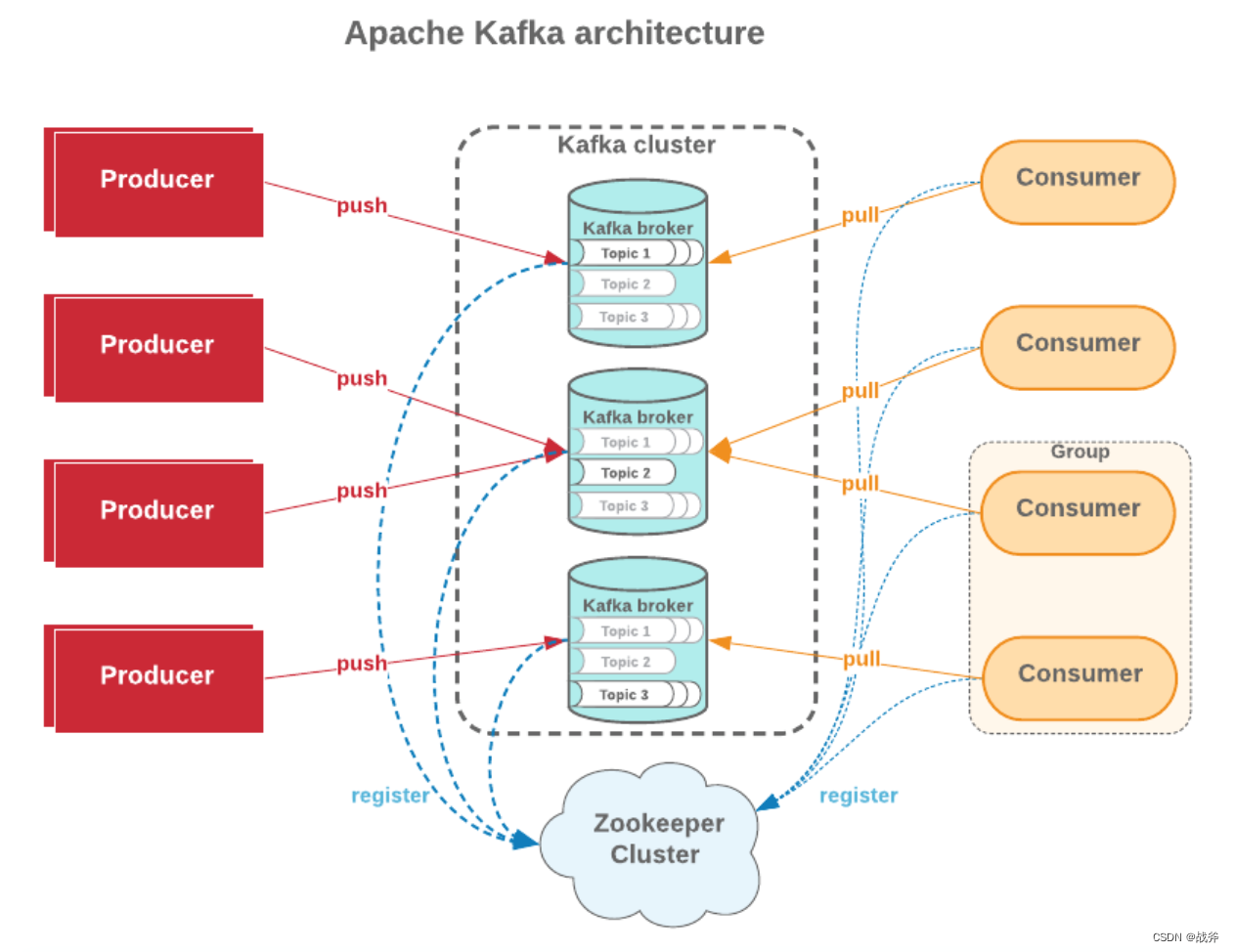
我们可以把多个消费者合成一个
消费者组(Group)
,每个消费者组可以消费一个或多个主题的消息。
二、消费者组的作用
1. 分区分配策略
消费者组是Kafka中实现消息分发与负载均衡的重要机制,它可以分摊消息的处理压力,并提高消息的处理效率和可用性。消费者组中的每个消费者可以独立消费分配给该消费者组的消息,在消费过程中,消费者不会相互干扰,不会重复消费同一条消息,也不会漏掉任何一条消息。
Kafka的消费者组工作流程如下图所示: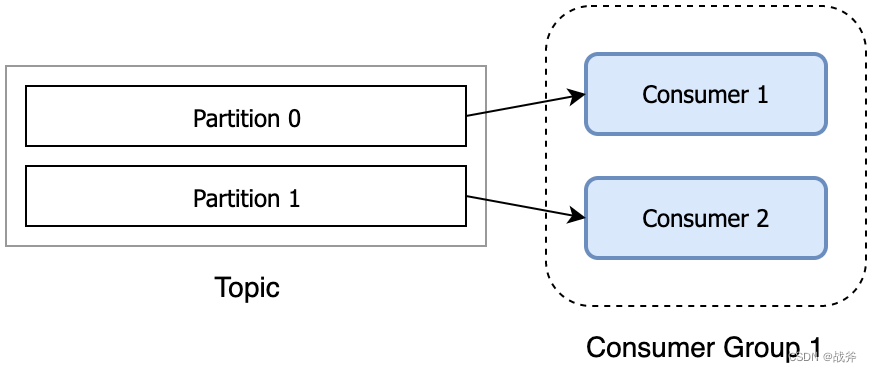
如上图,某个Topic里有两个分区,而我们的消费者组有两个消费者,那么两个消费者就会各自订阅一个分区,互不干扰。
当然,有些同学会问,你这里正好是两个分区、两个消费者,那如果两边数量不一样呢?
那么这就涉及到partition的分配问题,即确定那个partition由哪个consumer来消费。
Kafka有三种分配策略,一是
roundrobin
,一是
range
,还有一个
StickyAssignor
策略
- range策略 Range是对每个Topic而言的(即一个Topic一个Topic分),首先对同一个Topic里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。然后用Partitions分区的个数除以消费者线程的总数来决定每个消费者线程消费几个分区。每个消费者消费的分区是连续的,如果除不尽,那么前面几个消费者线程将会多消费一个分区。
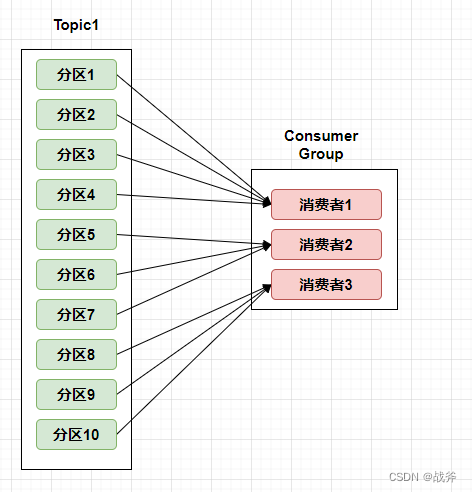
但其弊端也比较明显,排名靠前的消费者压力比较大,如果该消费者组仅订阅1个Topic还好,如果订阅多个主题,前面的消费者压力就明显更大了,如下图,消费者1订阅8个分区,而消费者3订阅6个分区
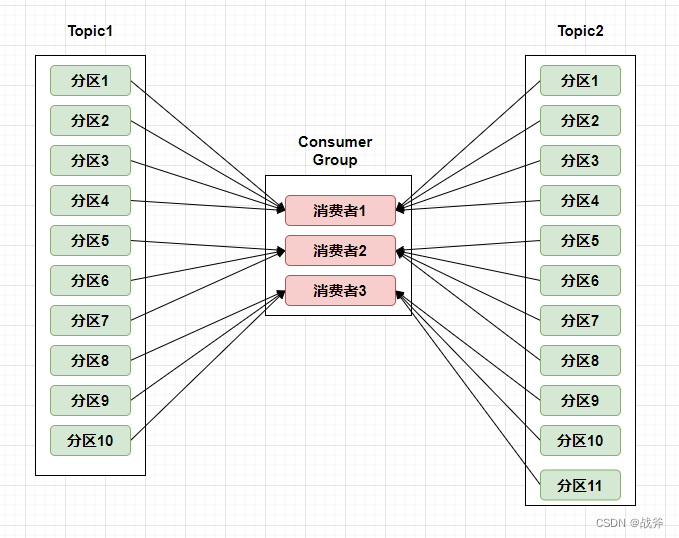
- roundrobin策略 为了解决排名靠前的消费者压力过大的问题,一种思路就是全局考虑,把一个消费者组消费的所有分区都罗列出来并字典序排序,然后再轮询的分给消费者,我们按照上面的例子,大概的分配示意图如下
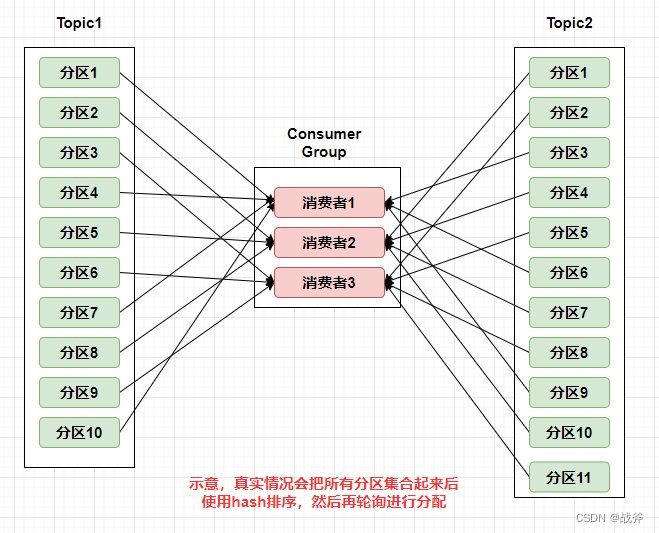 如图,当Topic1的分区10被分给消费者1后,Topic2的分区1就分配给消费者2了。那这样最后看到每个消费都订阅了7个分区,很平均了。但就完美了吗?非也,我们上面看的都是以消费者组为单位的订阅行为,但是别忘记,消费者组里面的某个消费者可能还有其他的任务,如下:
如图,当Topic1的分区10被分给消费者1后,Topic2的分区1就分配给消费者2了。那这样最后看到每个消费都订阅了7个分区,很平均了。但就完美了吗?非也,我们上面看的都是以消费者组为单位的订阅行为,但是别忘记,消费者组里面的某个消费者可能还有其他的任务,如下: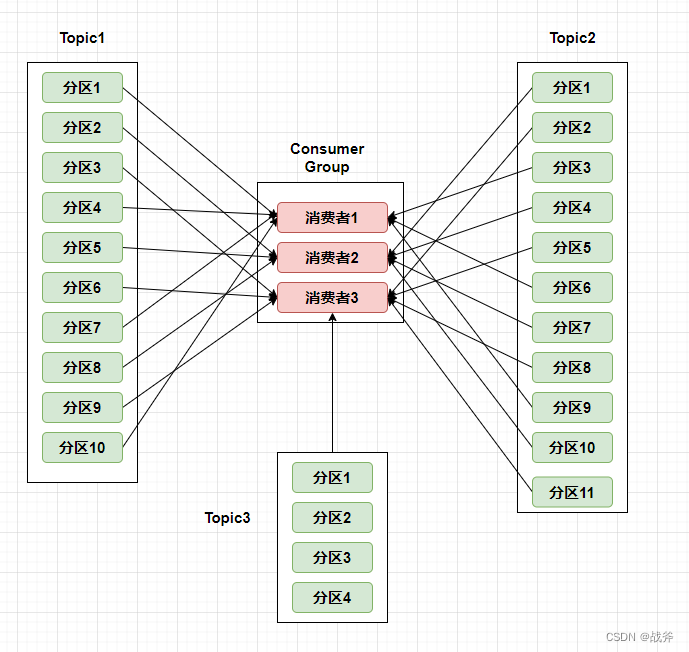 上面的消费者3除了作为消费者组的一份子,承接了Topic1和Topic2的部分分区,它还订阅了Topic3,那么消费者3的压力明显就大的太多了
上面的消费者3除了作为消费者组的一份子,承接了Topic1和Topic2的部分分区,它还订阅了Topic3,那么消费者3的压力明显就大的太多了 - StickyAssignor策略 该策略的实现更加复杂,它要求从一种更加全局的视角来分配,充分考虑到消费者组内每个消费者组的实际订阅数。它有两个目的: ①分区的分配要尽可能的均匀,分配给消费者者的主题分区数最多相差一个; ②分区的分配尽可能的与上次分配的保持相同。 至于其具体原理,可以参考官方文档,这里不继续深入探讨了
2. 分配原理
我们上面说了几种分区分配的方案,这种分配任务的方式被称为
协作分区
(cooperative partitioning)。在cooperative partitioning过程中,那么协作分区的结果谁来保存呢?其实是
组协调器
(Group Coordinator),Kafka通过组协调器来保存消费者间的划分,实现了消费者组的自动管理,使得消费者组可以根据实际情况动态地扩容、缩容。
当然,这里需要介绍下
协调器
的概念,每一个Kafka集群都有若干个Coordinator,它们分别负责不同的任务。目前Kafka中的Coordinator主要有以下几种:
- Group Coordinator:负责管理消费者组,包括新增、删除和重平衡操作。
- Transaction Coordinator:负责事务的管理,包括启动、提交和回滚等操作。
- Metadata Coordinator:负责维护Kafka集群中各个Partition的元数据信息,包括分区的leader和ISR等信息。
- Admin Coordinator:负责管理Kafka集群的各种配置信息,包括topic的创建、删除和分区的增、删、改等操作。
我们这里要讲的就是其中的
组协调器
(Group Coordinator),Group Coordinator是一个服务,每个Broker在启动的时候都会启动一个该服务。Group Coordinator的作用是用来存储Group的相关Meta信息,并将对应Partition的Offset信息记录到Kafka内置Topic(__consumer_offsets)中,当我们建立一个组的时候,都会选择一个Coordinator来操作与存储自己组内各Partition的Offset信息
三、Rebalance机制
1. Rebalance的作用
我们前面提到,消费者组里的各个消费者会被做分配操作。那如果某一个消费者挂掉了怎么办呢?这个消费者负责的那些分区岂不是没人订阅了?
别担心,Kafka提供了
Rebalance
机制。Rebalance机制可以动态地分配分区,使得每个消费者负载均衡,提高消费效率和可用性。一般来说,Rebalance机制会在以下情况下发生:
- 消费者加入或退出消费者组,当消费者加入或退出消费者组时,协调器会触发Rebalance机制
- 分区数目发生变化:当Kafka的主题被扩容或缩容时,会触发Rebalance机制,重新分配分区。。
- Kafka Broker发生变化:当Kafka Broker发生变化时,例如节点重启或宕机等,会触发Rebalance机制
其实很好理解,A 订阅 B,那显然只有当A 或 B 的数量发生变动的时候,才需要再次平衡
2. Rebalance的实现
我们已增添一个消费者为例,说明下Rebalance发生的全过程:
- 消费者加入/退出:当一个消费者加入或退出消费者组时,它会向Group Coordinator发送JOIN GROUP或LEAVE GROUP请求。
- 协调者选举:如果Group Coordinator收到的是JOIN GROUP请求,则会根据Group Leader选举机制选举一个Group Leader。Group Leader的职责是进行rebalance操作,分配partition给消费者。(注意Group Leader是消费者组内的某个消费者,和Group Coordinator不是一个东西)
- 分组协商:Group Leader选举完成后,它会向其他消费者发送SYNC GROUP请求,要求其他消费者加入rebalance操作。其他消费者加入后,Group Leader会根据消费者的订阅信息,计算出新的分配方案。分配方案会以ASSIGN PARTITIONS请求的形式发送给每个消费者。
- 重新分配partition:每个消费者在收到ASSIGN PARTITIONS请求后,会按照分配方案重新分配自己需要消费的partition,然后完成rebalance操作。
- 继续消费:重新分配partition后,消费者会继续从分配的partition中消费数据。
借用网上的图来说明下情况,你也可以把整个Rebalance分为两步:Join 和 Sync。
- Join阶段,所有成员都向coordinator发送JoinGroup请求,请求加入消费组,最后由Group Coordinator来选出其中一个消费者作为Leader,Leader能知道组内所有消费者。
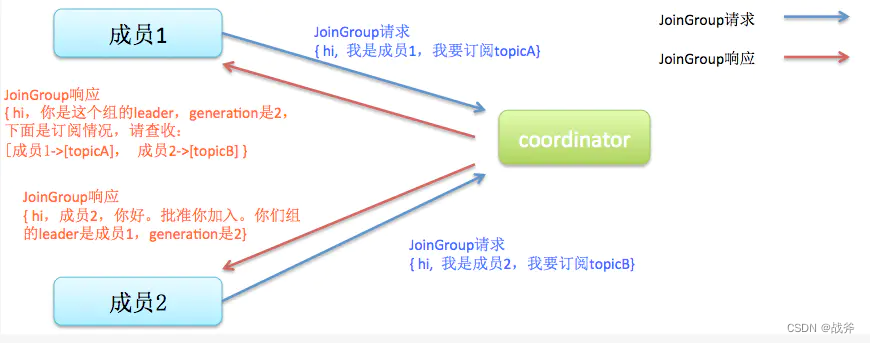
- Sync阶段,leader开始分配消费方案,一旦完成分配,leader会将这个方案封装进SyncGroup请求中发给coordinator,非leader也会发SyncGroup请求,只是内容为空。coordinator接收到分配方案之后会把方案塞进SyncGroup的response中发给各个consumer
 而至于分配方案具体是怎样的,其实就是在上一小节已经说过的 分区分配策略
而至于分配方案具体是怎样的,其实就是在上一小节已经说过的 分区分配策略
3. Rebalance的优劣
Kafka的rebalance主要是为了实现消费者的负载均衡。通过上面的学习,相信大家也能总结出rebalance机制的优点就是
增强容错性
和
支持动态扩容
:
- 增强容错性:当某个消费者意外退出或宕机,rebalance可以重新分配该消费者所消费的partition给其他消费者,从而保障消费的连续性,并减少对业务的影响。
- 支持动态扩容:在Kafka系统运行中,如果需要增加消费者数量,rebalance可以根据新的消费者加入,重新分配partition,确保消费者的负载均衡。
但凡事有利有弊,rebalance最大的缺点就是
延迟影响性
:rebalance操作会涉及到分区的重新分配,会导致系统有一定的延迟。如果消费者数量很大,rebalance操作会更加复杂且耗时长。在这个期间,所有的消费者都无法执行消费,可以说影响面还是非常广的。
四、减少Rebalance的发生
我们在生产中,如非必要,应该尽量避免Rebalance,这会暂停运行中的消费过程。最好是提前就做好各种预防措施,而不是依靠Kafka的Rebalance来处理。
我们在前面说到,消费者 和 分区 的数量变化会导致Rebalance,一般其实是由于消费者的变动导致的,如果是意外的宕机我们无法防止,但是我们可以调整“短暂掉线”及“消费能力不足”的消费者,对他们更加“宽容”一点,具体如下:
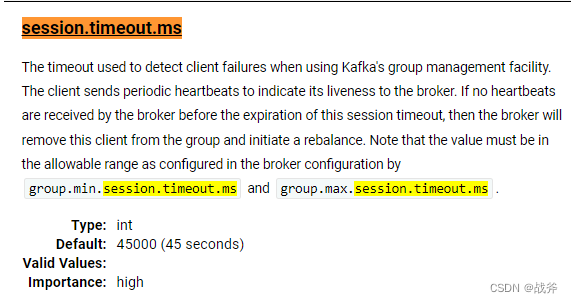
每个 Consumer 实例都会定期地向 Coordinator 发送心跳请求,表明它还存活着。如果某个 Consumer 实例不能及时地发送这些心跳请求,Coordinator 就会认为该 Consumer 已经 “死” 了,从而将其从 Group 中移除,然后开启新一轮 Rebalance。这个时间可以通过Consumer 端的参数
session.timeout.ms
进行配置。默认值是 45 秒
Consumer 端还有一个参数,用于控制 Consumer 实际消费能力对 Rebalance 的影响,即
max.poll.interval.ms
参数。它限定了 Consumer 端应用程序两次调用 poll 方法的最大时间间隔。它的默认值是 5 分钟,表示你的 Consumer 程序如果在 5 分钟之内无法消费完 poll 方法返回的消息,那么 Consumer 会主动发起 “离开组” 的请求,Coordinator 也会开启新一轮 Rebalance

一般来说,为了预防Rebalance,我们可以调大上面两个参数,同时加快心跳频率,也就是调小
heartbeat.interval.ms

总结
本期我们讲了Kafka消费端的成组设置,也了解了组内的分配规则,以及消费者发生变动后会导致的Rebalance机制,最后介绍了减少Rebalance发生的一些参数调整。希望大家能有所收获,下次我们将继续深入讲解Kafka的其他原理,如果你对此有兴趣,可以直接订阅本
kafka
专栏
版权归原作者 战斧 所有, 如有侵权,请联系我们删除。