
默认大家都装好了Anaconda和Pycharm,且知晓基本操作
一、创建新环境
打开cmd窗口,输入conda create -n yolov5 python=3.7,回车

等待一会,输入y,回车
再等待一会,出现done,说明新环境创建成功!

名字可以随便取,但是建议跟我取一样的,建议后续所有操作都跟我保持一致,方便大家第一次上手;Python解释器版本就选3.7吧,因为我之前选3.10遇到过不明问题
二、导入Pytorch库
我的电脑是R7-5800H的Thinkbook14p,没有独显,所以我使用的是CPU版的PyTorch
首先在cmd窗口输入conda activate yolov5,回车,激活刚刚创建的新环境

路径前出现(yolov5)就说明激活成功啦!
然后进入PyTorch官网PyTorch,选择如下配置:
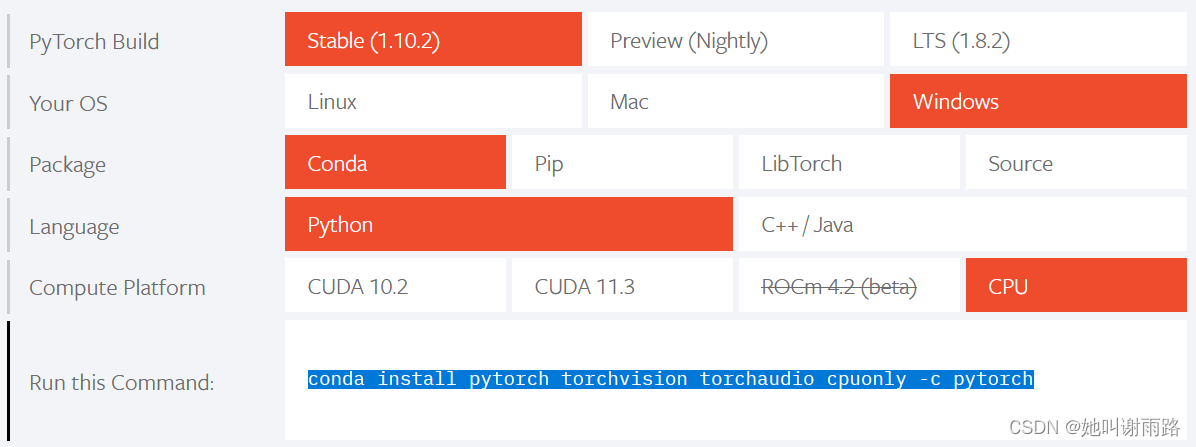
复制最后一行的代码到cmd窗口中,回车

等待一会,输入y,回车;再等待一会,出现done,说明Pytorch库导入成功!
三、新建项目
首先从这个网站下载yolov5安装包mirrors / ultralytics / yolov5 · GitCode
下载完成后解压,右键解压后的文件夹,选择作为Pycharm项目打开
打开后的Pycharm界面是这样的:
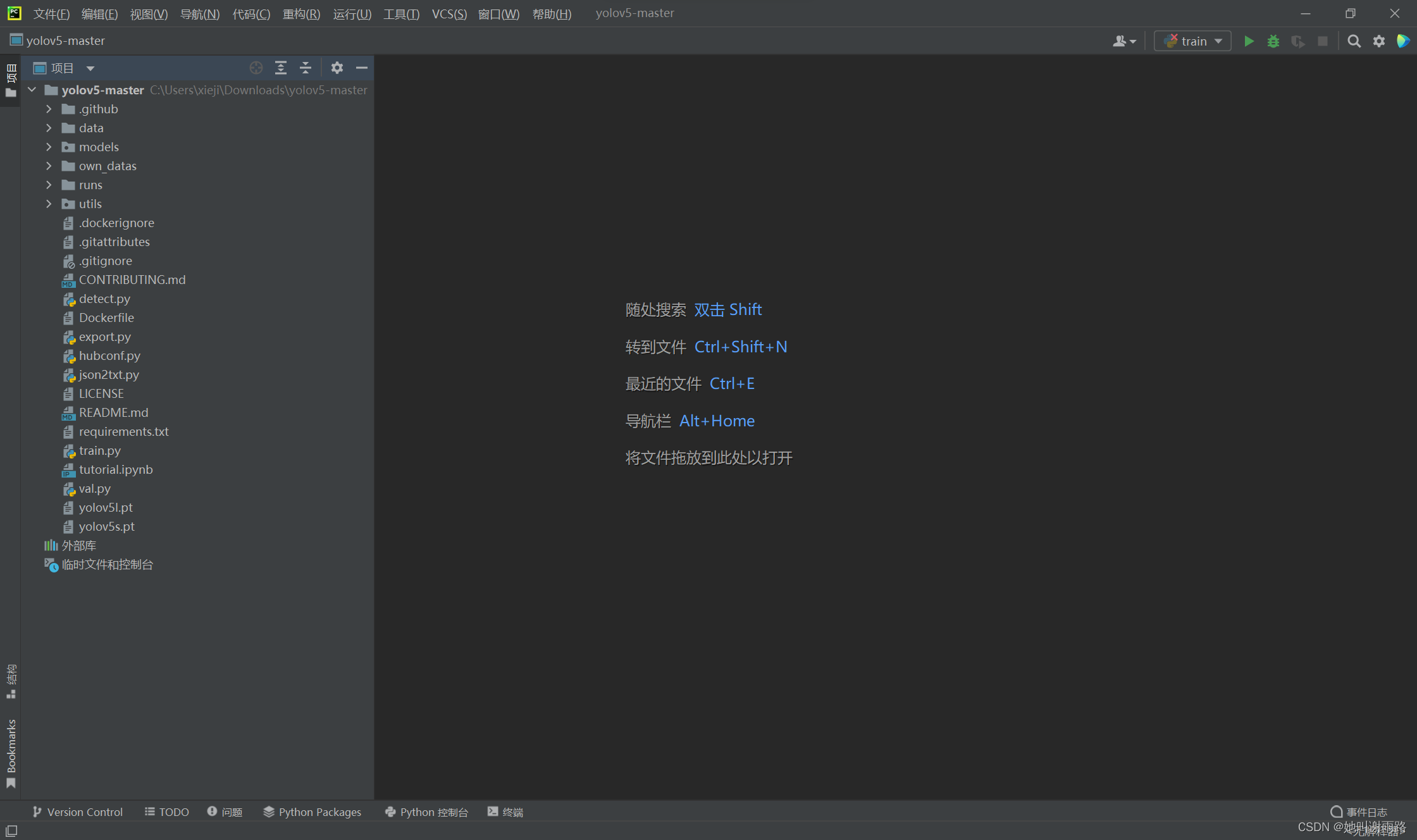
点击右下角的<无解释器>,选择添加解释器
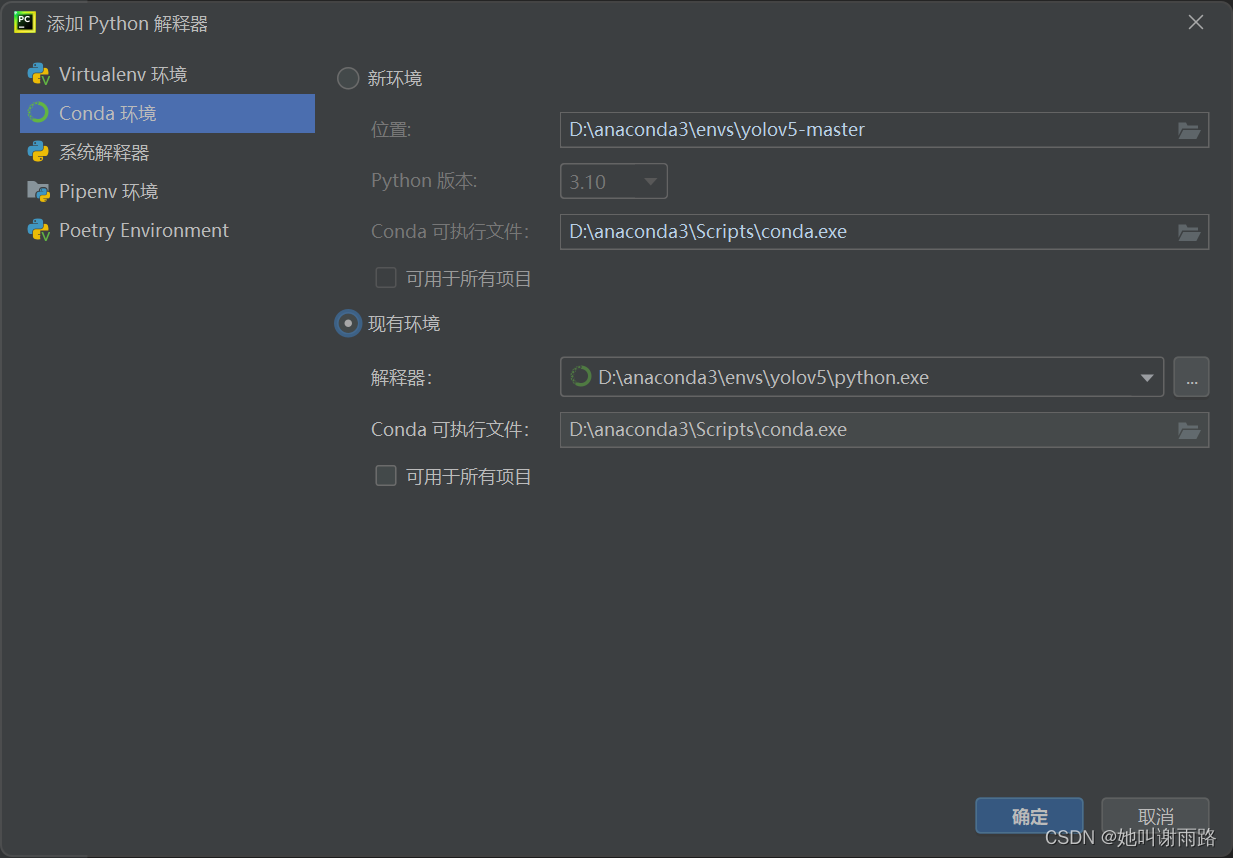
在弹出的界面左侧点击Conda环境,点击现有环境,解释器选择之前创建的新环境下的python可执行文件,点击确定
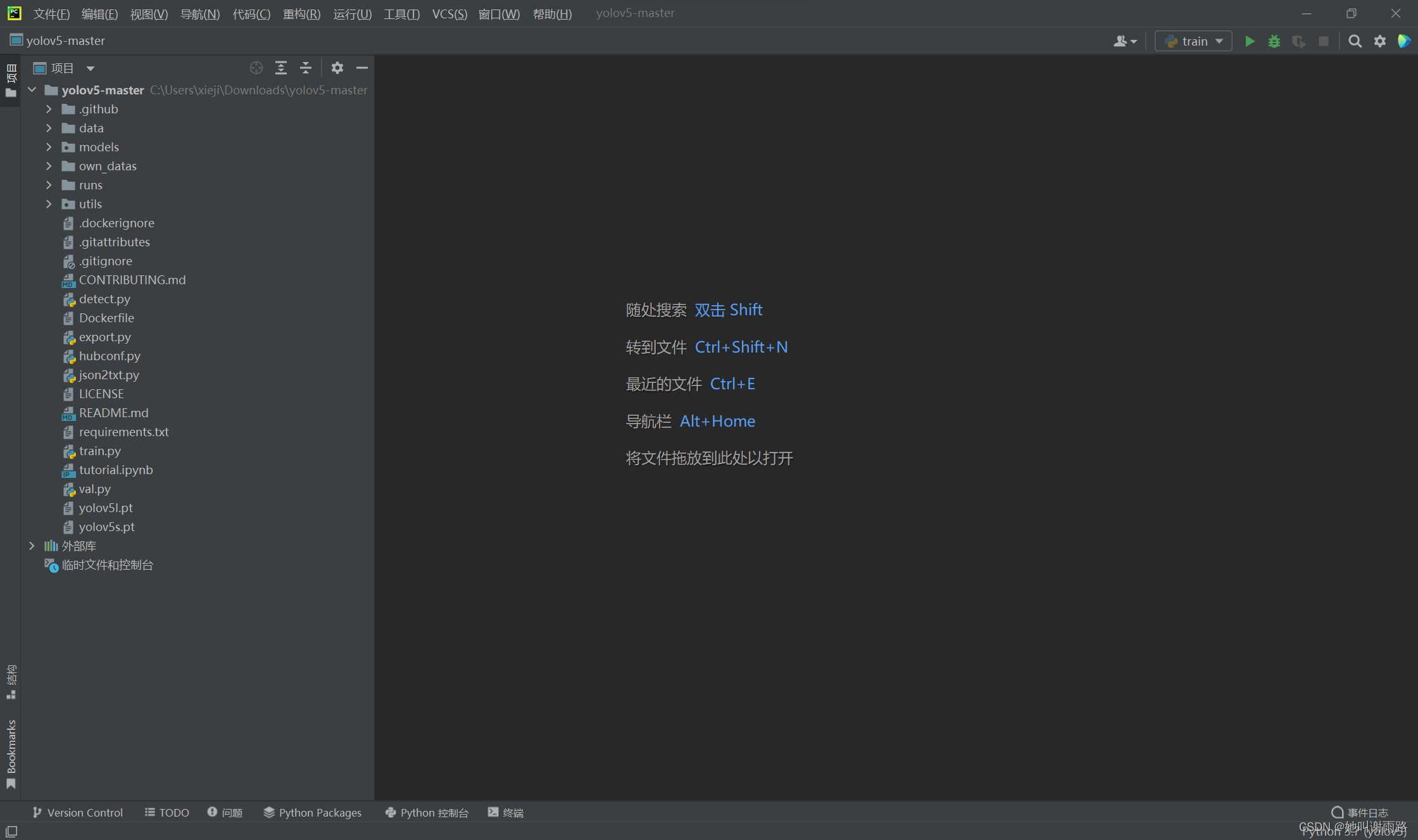
可以看到此时Pycharm界面右下角已经变成Python3.7(yolov5)
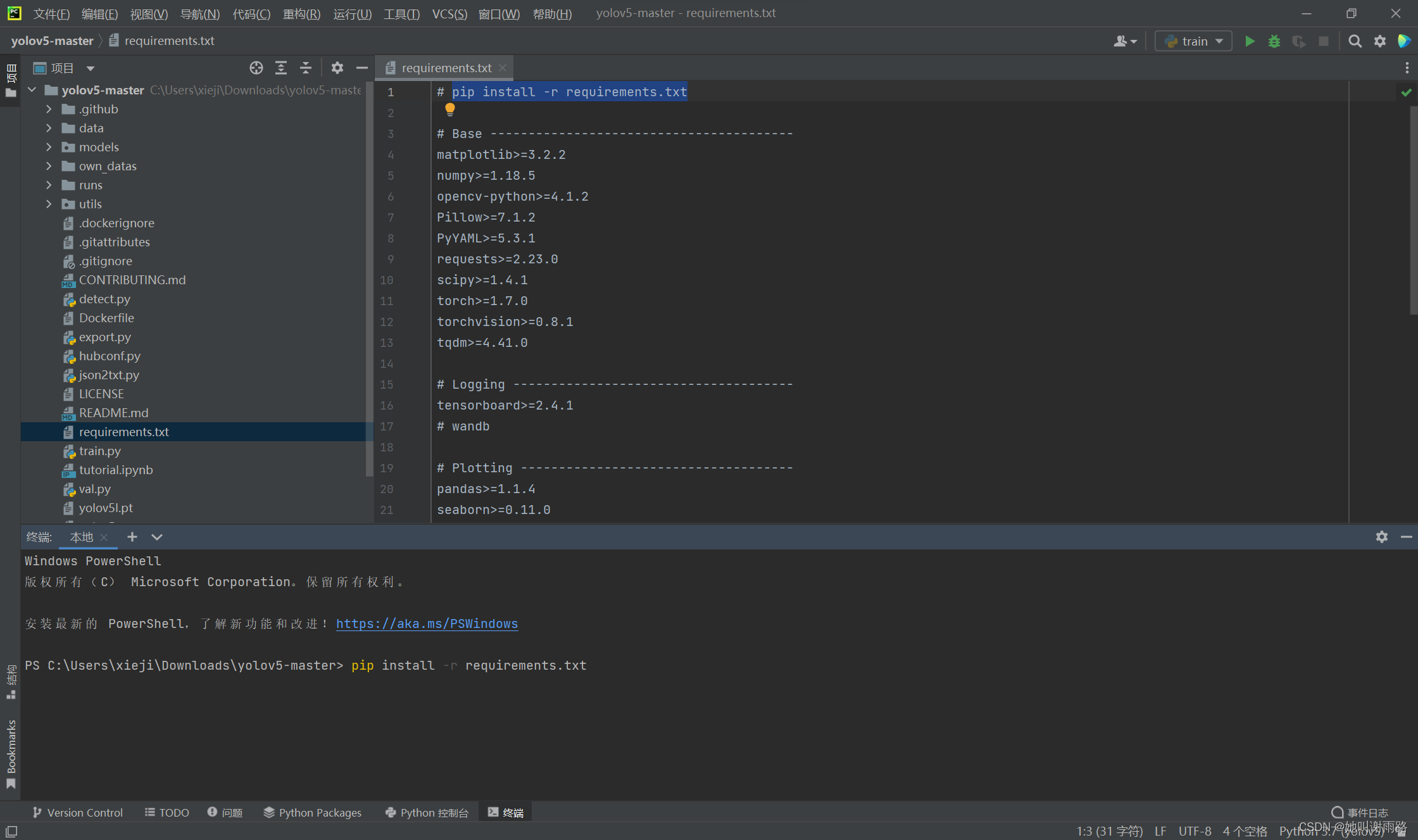
四、测试
打开requirements.txt文件,里面写有yolov5运行所需要的各种包。复制第一行的命令到终端中运行
这个过程可快可慢,看网速,静静地等待吧~有几个包的安装可能会出问题,没关系,把报错信息在CSDN上搜一搜都能找到解决办法!
全部安装好之后就运行左侧的detect.py文件
如果运行结束后没有报错,而且在左侧的runs\detect\exp目录下出现了下面这两张被处理过的图片,就说明前面的操作都木有问题,恭喜!准备工作结束


五、准备数据集
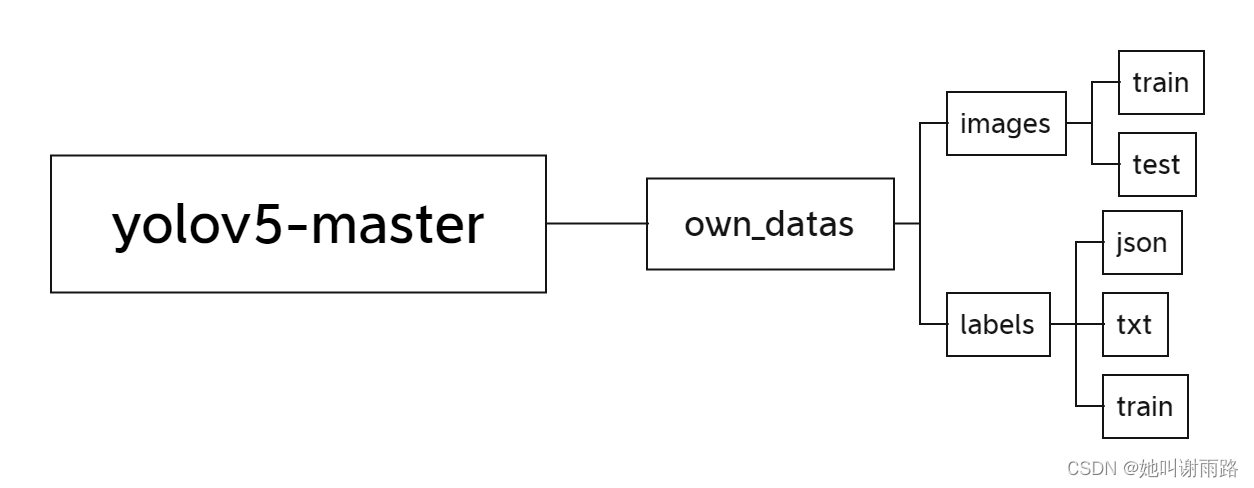
大家先按照我这种方式在yolov5-master路径下新建下列空文件夹,方便后续管理
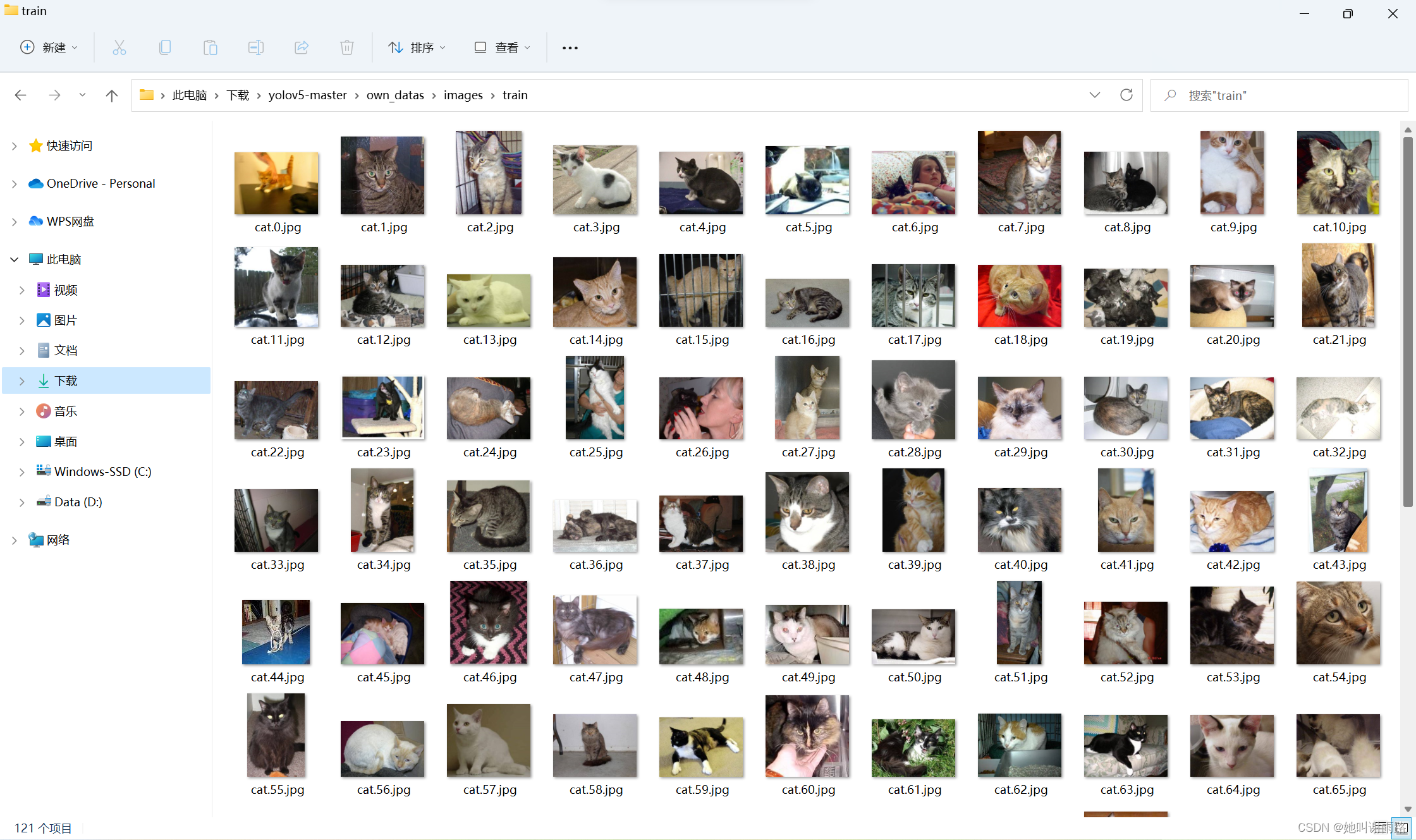
我是在知乎的这篇文章中下载了博主提供的训练数据猫狗识别之准备数据集 - 知乎,解压之后有25000张图片,显然是不可能全部使用的。我选择了猫猫图片的前121张,复制到yolov5-master\own_datas\images\train文件夹下作为训练集
然后在Pycharm终端中输入pip install pyqt5 labelme,回车。这两个库是用来给数据集打标签的
安装完成后,在终端输入labelme,回车
会弹出一个窗口,就在这个窗口里进行训练集的标注
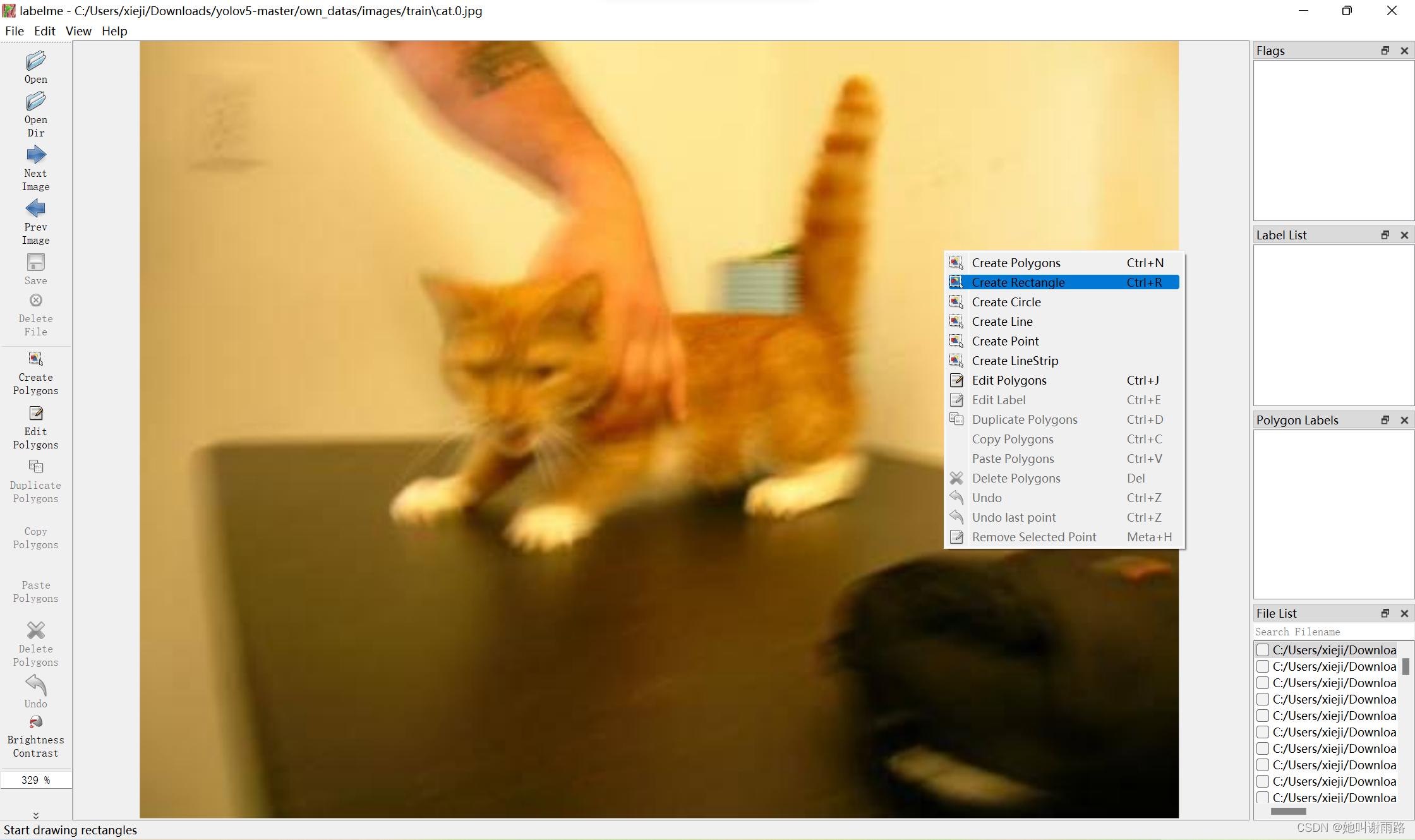
点击左上角的Open Dir,选择yolov5-master\own_datas\images\train文件夹,就会出现训练集里的图片。右键选择Create Rectangle,框出图片里的猫猫
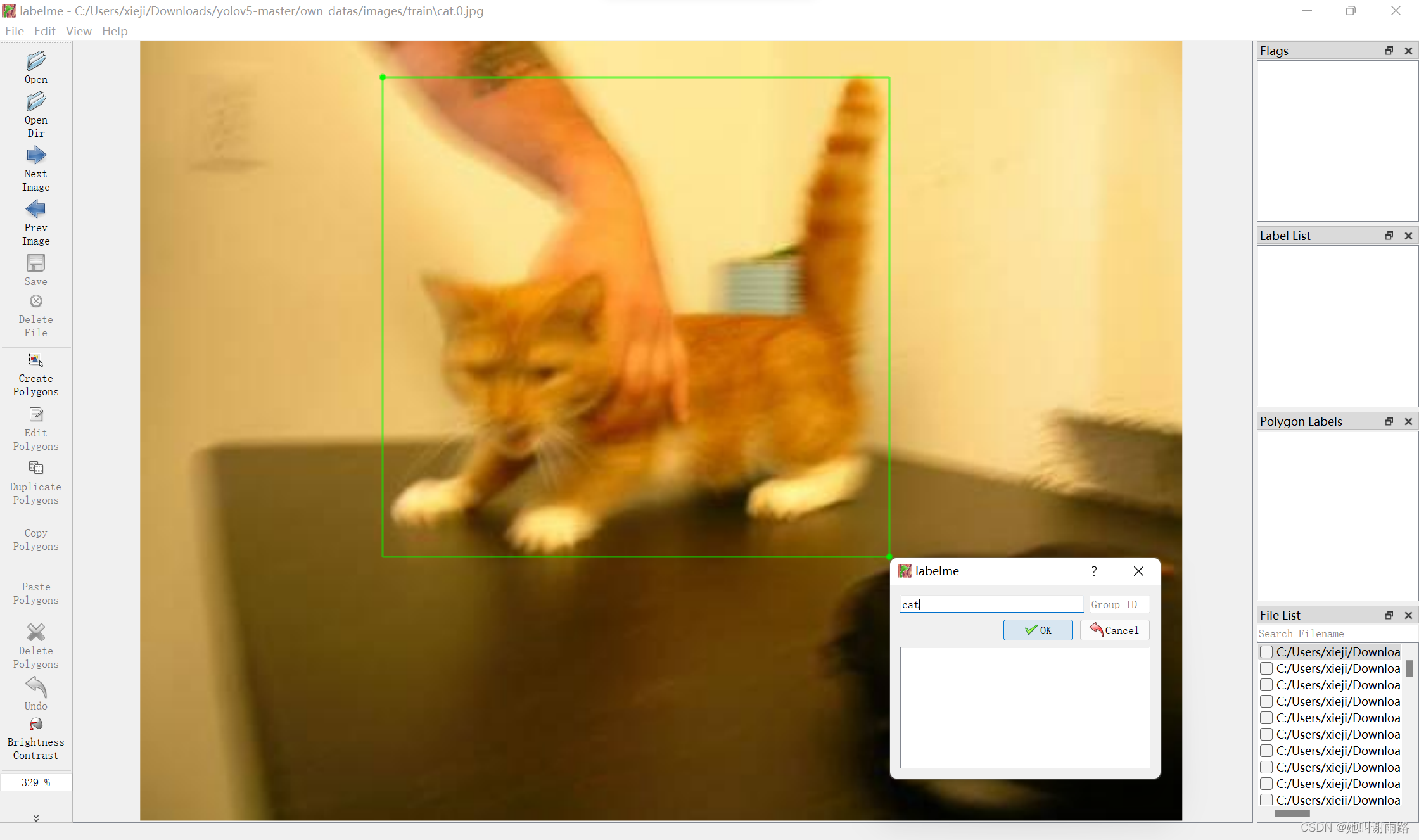
框选结束后,输入标签名cat,点击ok,这个标签就保存下来了。如果有多只猫猫,就继续框选
整张图片框选完毕后,点击左侧的Next Image,根据提示把标注文件保存到路径yolov5-master\own_datas\labels\json中,文件的格式是.json
大概半小时后...
所有图片标注完毕,可以在yolov5-master\own_datas\labels\json文件夹中看到与训练集图片数量相同且对应的121个.json文件
还没完,因为yolov5只能识别.txt格式的标签,还需要把.json文件转换成.txt文件
在yolov5-master文件夹中新建json2txt.py文件
把如下代码拷贝进去:
import json
import os
name2id = {'cat': 0} # 标签名称
def convert(img_size, box):
dw = 1. / (img_size[0])
dh = 1. / (img_size[1])
x = (box[0] + box[2]) / 2.0 - 1
y = (box[1] + box[3]) / 2.0 - 1
w = box[2] - box[0]
h = box[3] - box[1]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def decode_json(json_floder_path, json_name):
txt_name = 'C:/Users/xieji/Downloads/yolov5-master/own_datas/labels/txt/' + json_name[0:-5] + '.txt'
# txt文件夹的绝对路径
txt_file = open(txt_name, 'w')
json_path = os.path.join(json_floder_path, json_name)
data = json.load(open(json_path, 'r', encoding='gb2312', errors='ignore'))
img_w = data['imageWidth']
img_h = data['imageHeight']
for i in data['shapes']:
label_name = i['label']
if (i['shape_type'] == 'rectangle'):
x1 = int(i['points'][0][0])
y1 = int(i['points'][0][1])
x2 = int(i['points'][1][0])
y2 = int(i['points'][1][1])
bb = (x1, y1, x2, y2)
bbox = convert((img_w, img_h), bb)
txt_file.write(str(name2id[label_name]) + " " + " ".join([str(a) for a in bbox]) + '\n')
if __name__ == "__main__":
json_floder_path = 'C:/Users/xieji/Downloads/yolov5-master/own_datas/labels/json/'
# json文件夹的绝对路径
json_names = os.listdir(json_floder_path)
for json_name in json_names:
decode_json(json_floder_path, json_name)
三个有注释的地方是可能需要做出调整的地方。如果大家是一模一样跟着我做下来的,就只用把C:/Users/xieji/Downloads/换成自己的路径就可以了
运行json2txt.py,结束后可以在yolov5-master\own_datas\labels\txt文件夹中看到对应的121个.txt文件
最后一步,把txt文件夹中的文件全部复制到yolov5-master\own_datas\labels\train文件夹中。这一步别忘啦!不然等会在训练的时候会报错找不到标签
六、修改配置文件
首先先复制两个文件
在yolov5-master\data路径下找到coco128.yaml文件,复制到yolov5-master\own_datas路径下,改名为cat.yaml
因为我们用的不是coco128数据集,而是我们自己的猫猫数据集。其实不改也可以,只是改了更便于理解
在yolov5-master\models路径下找到yolov5s.yaml文件,同样复制到yolov5-master\own_datas路径下。选择yolov5s是因为,虽然它效果不太好,但是速度比较快,我之前用过yolov5l,得跑一晚上...
打开cat.yaml文件,首先需要修改的是这三行:
# path: ../datasets/coco128 # dataset root dir
train: own_datas/images/train # train images (relative to 'path') 128 images
val: own_datas/images/train # val images (relative to 'path') 128 images
第一行要注释掉
第二行和第三行的相对路径,如果是一模一样跟着我做下来的,按我这个来就可以了
然后修改这两行:
nc: 1 # number of classes
names: ['cat'] # class names
nc是类别数,names是类别名称。如果是一模一样跟着我做下来的,按我这个来就可以了
最后把这一行给注释掉,因为我们不使用coco128数据集。不注释也行,没什么影响,只是我强迫症犯了
# download: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip
打开yolov5s.yaml文件,需要修改的是这一行:
nc: 1 # number of classes
七、训练
打开train.py文件
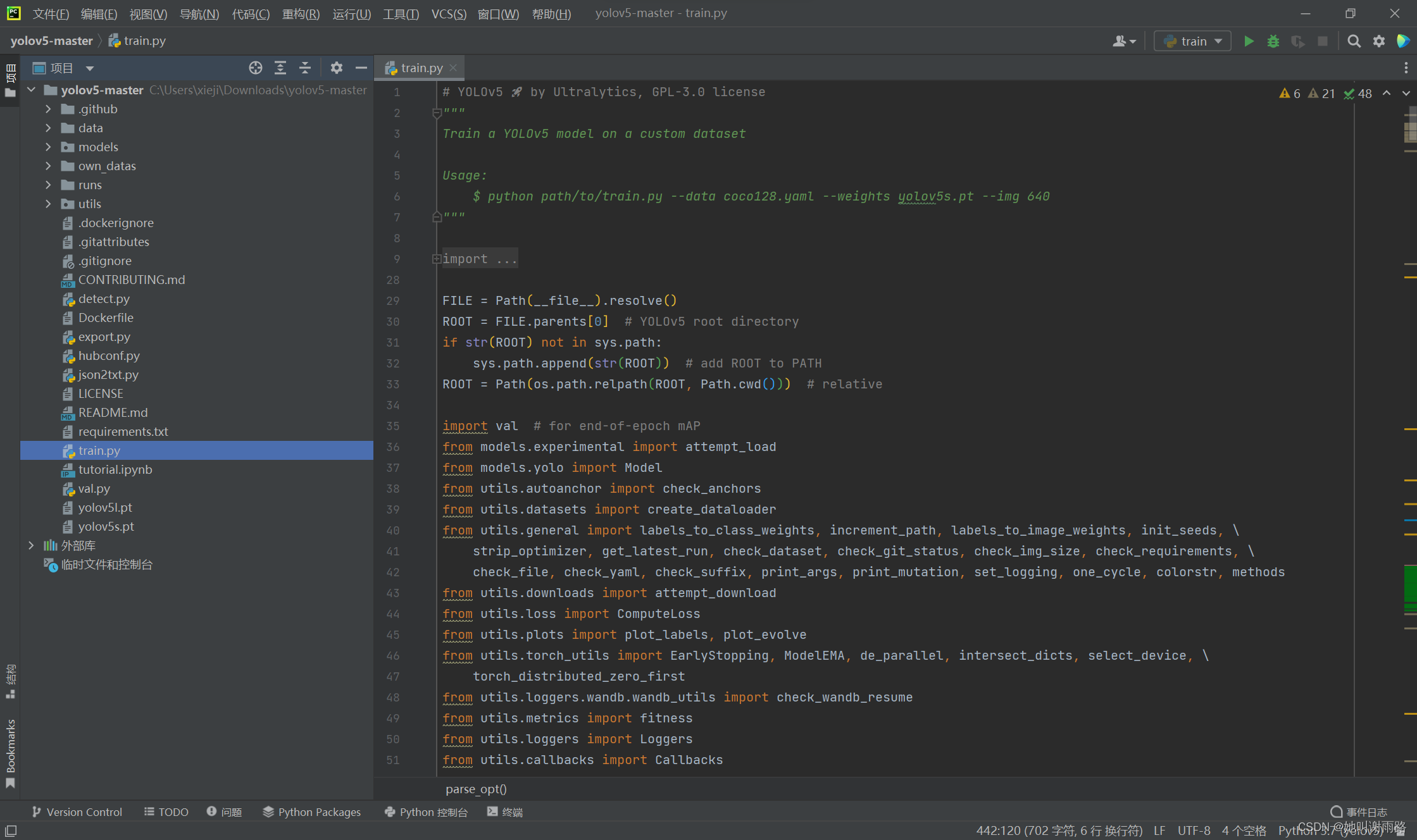
首先修改这几行的default:
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='own_datas/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='own_datas/cat.yaml', help='dataset.yaml path')
如果是一模一样跟着我做下来的,按我这个来就可以了
然后修改这一行的default:
parser.add_argument('--epochs', type=int, default=150)
默认值是300,但是训练时间会比较长,我这里改成了150
最后一个要修改的是这一行的default:
parser.add_argument('--workers', type=int, default=0, help='maximum number of dataloader workers')
我一开始使用的是默认值8,因为我的CPU是8核心16线程的,我看别的地方说这个值设置成自己电脑的CPU核心数的话训练速度最快,结果训练的时候报错了,大概意思是说内存爆了,然后我就改成了0
OK,开始训练!
运行train.py,然后静静等待吧...风扇会呼呼呼地转个不停...
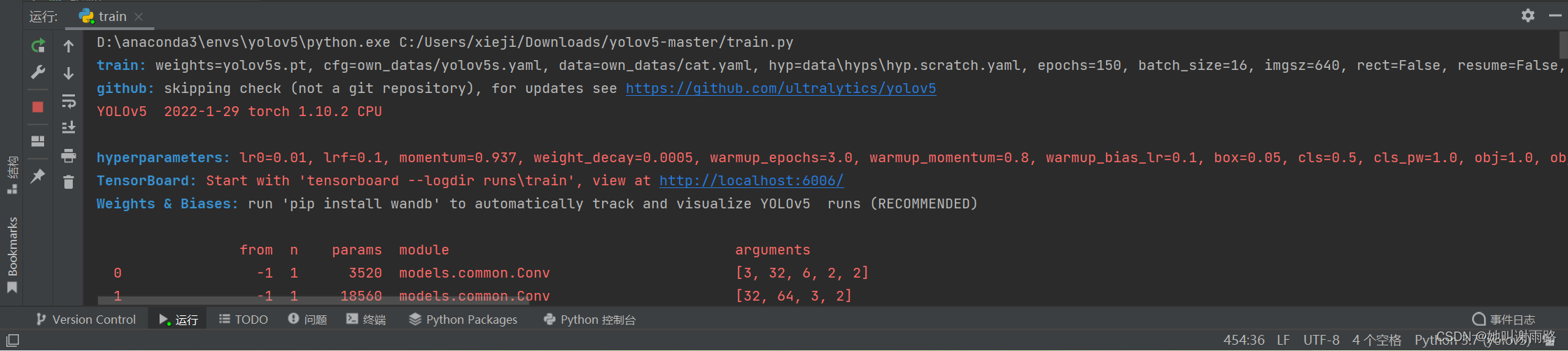
我训练了三个小时...**用CPU是真的慢啊...**最后一个epoch结束后,mAP@0.5停在了0.995,mAP@0.5:0.95停在了0.904,挺好
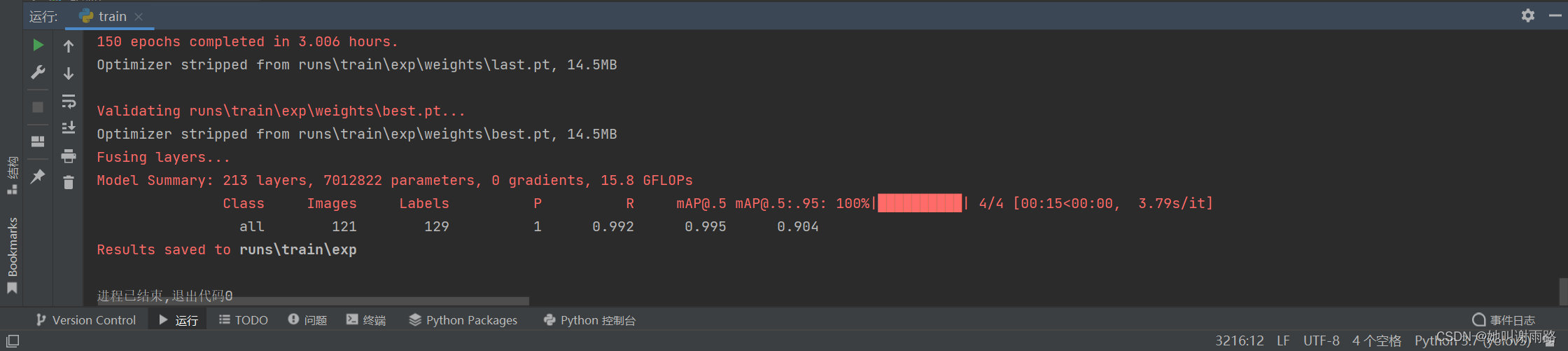
可以在yolov5-master\runs\train\exp文件夹中查看训练相关的信息
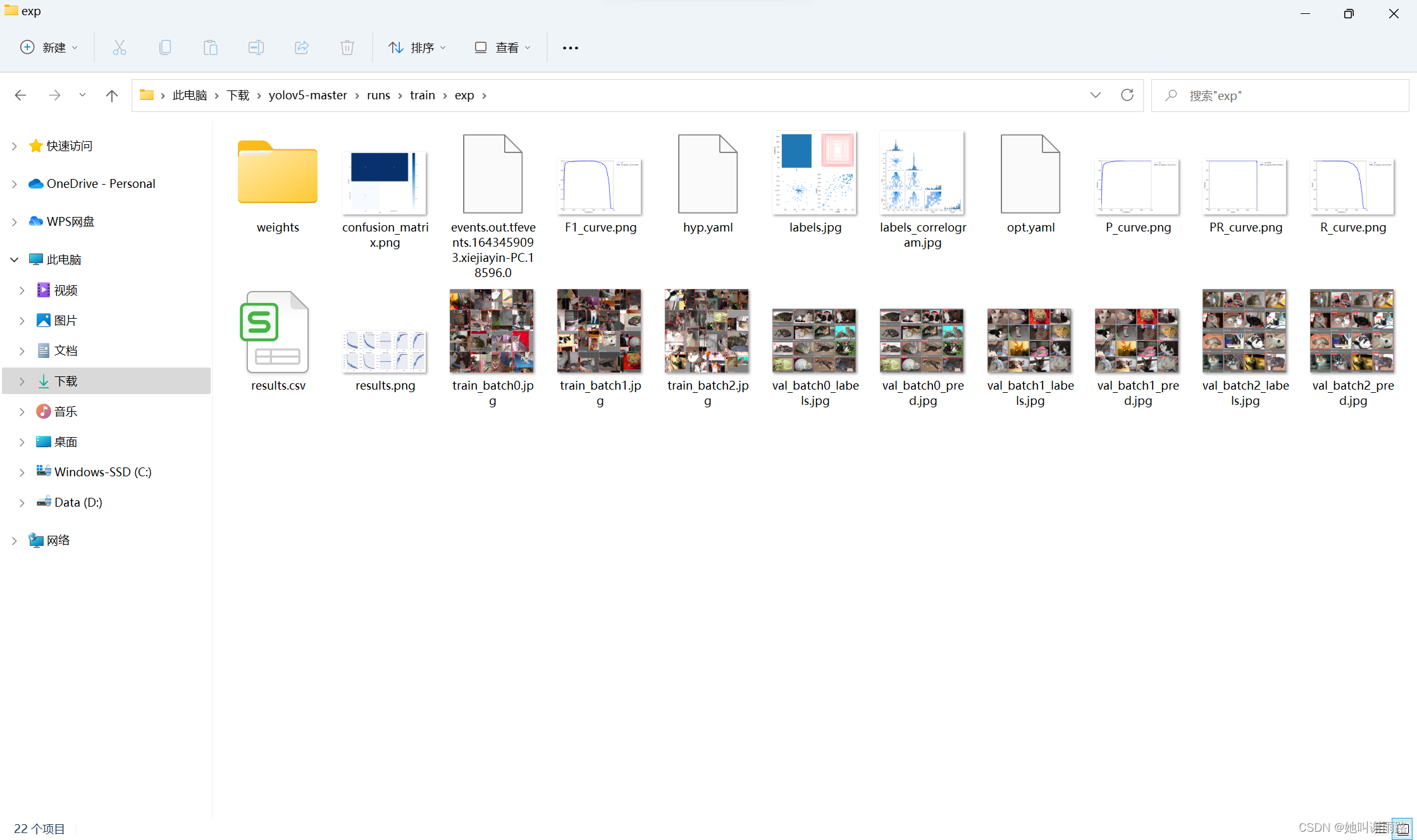
weights文件夹里面的best.pt文件是训练好的模型,等会测试的时候会用到
八、实例测试
花了三小时训练出来的模型,接下来就看看它的效果吧!
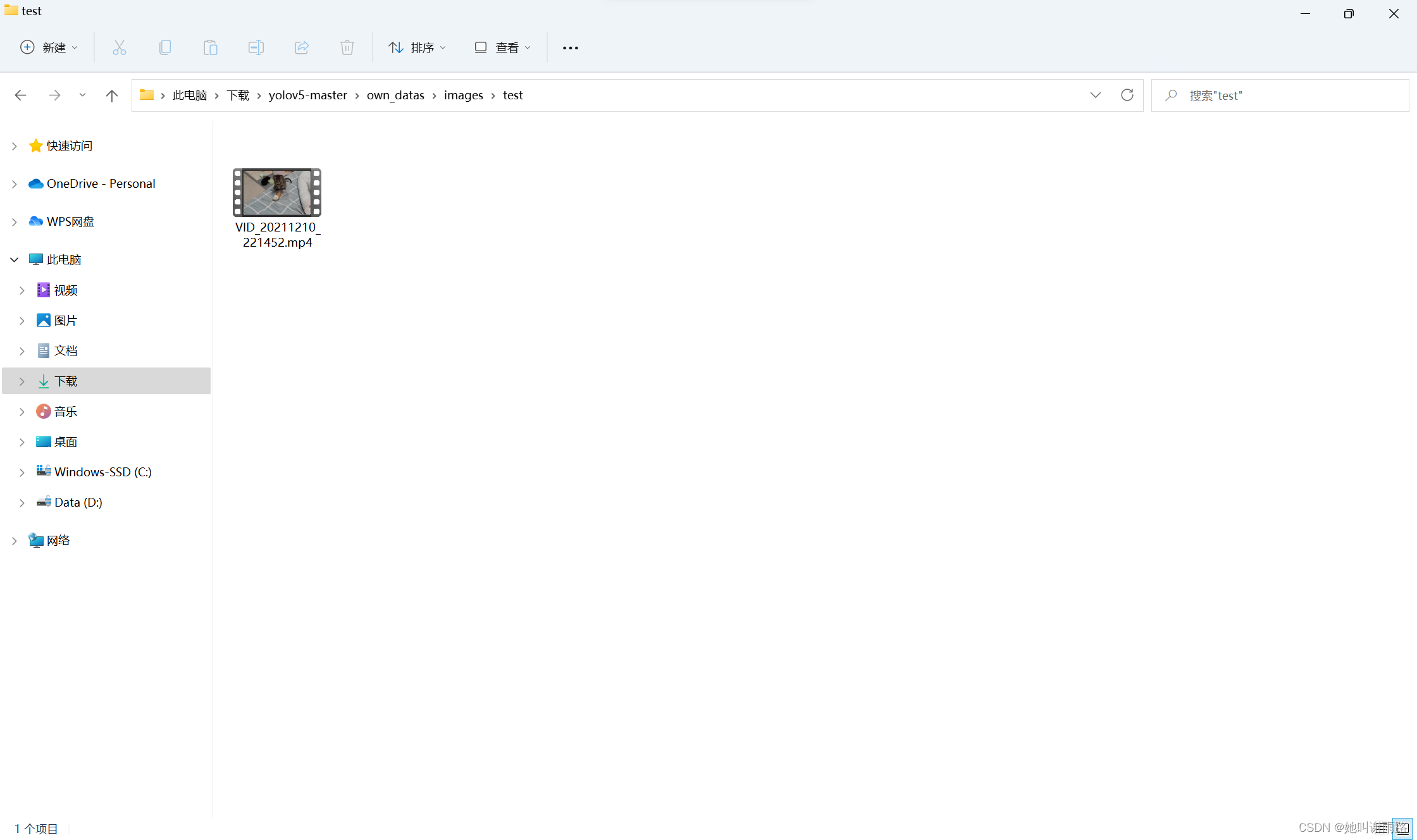
我是用的自己拍的猫猫视频进行测试的,大家可以用自己拍的,照片也可以(其实可以直接用之前下载的数据集里的,两万多张随便用)
把测试文件放在yolov5-master\own_datas\images\test文件夹下
打开detect.py文件
修改下面这两行的default:
parser.add_argument('--weights', nargs='+', type=str, default='runs/train/exp/weights/best.pt', help='model path(s)')
parser.add_argument('--source', type=str, default='own_datas/images/test', help='file/dir/URL/glob, 0 for webcam')
第一个default就是之前说过的训练出来的模型文件的相对路径
第二个default就是存放测试文件的文件夹的相对路径
如果是一模一样跟着我做下来的,按我这个来就可以了
运行detect.py,等待一会...
结束后可以在yolov5-master\runs\detect\exp2文件夹里查看结果
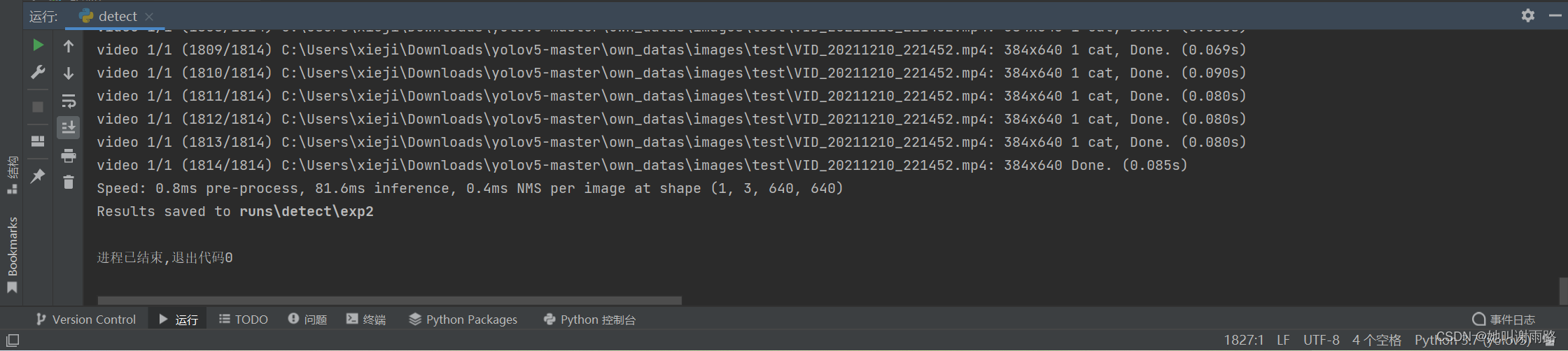
不能直接上传视频,我从视频里截几张图给大家看一下:

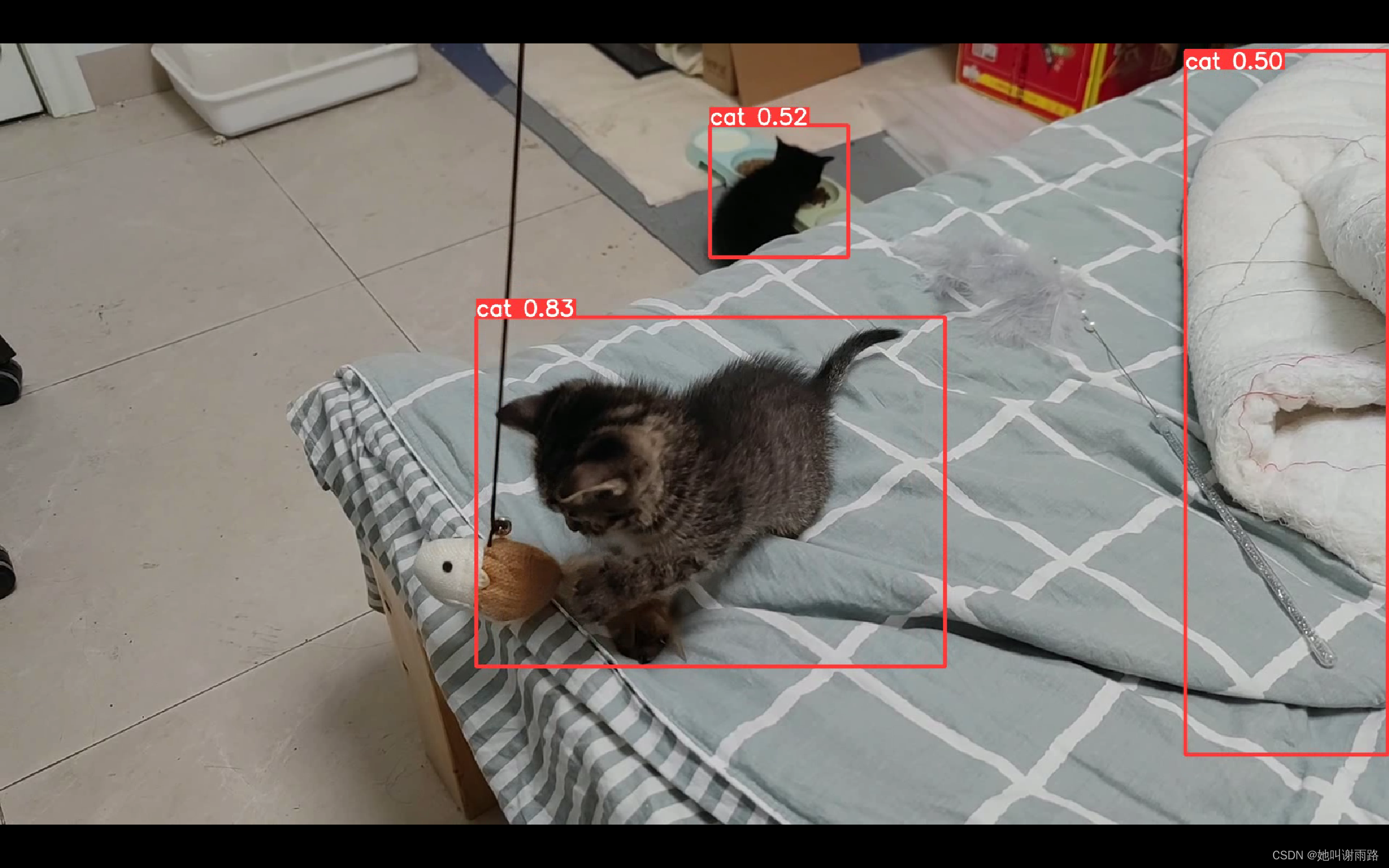

效果还行,差强人意,毕竟只训练了100多张图片,还用了比较差的yolov5s网络
九、结束语
我自己也是个新手,刚接触深度学习,这个项目前后做了好几天,恶补了不少知识
写完草稿之后,我就把自己之前做的都删除了,然后按照自己写的步骤重新跑了一遍,很顺利,没有问题!
大家按我这个流程,不要一天就可以完成(如果有比较好的独显,用GPU来跑就更快了)
遇到问题就在CSDN上搜一搜,再结合自己的智慧,相信都能解决!
主要是参考了这篇博客,感谢!
【Yolov5】1.认真总结6000字Yolov5保姆级教程,80岁老奶奶都看得懂_若丶尘的博客-CSDN博客_coco128.yaml
版权归原作者 她叫谢雨路 所有, 如有侵权,请联系我们删除。