
重采样是时间序列分析中处理时序数据的一项基本技术。它是关于将时间序列数据从一个频率转换到另一个频率,它可以更改数据的时间间隔,通过上采样增加粒度,或通过下采样减少粒度。在本文中,我们将深入研究Pandas中重新采样的关键问题。
为什么重采样很重要?
时间序列数据到达时通常带有可能与所需的分析间隔不匹配的时间戳。例如以不规则的间隔收集数据,但需要以一致的频率进行建模或分析。
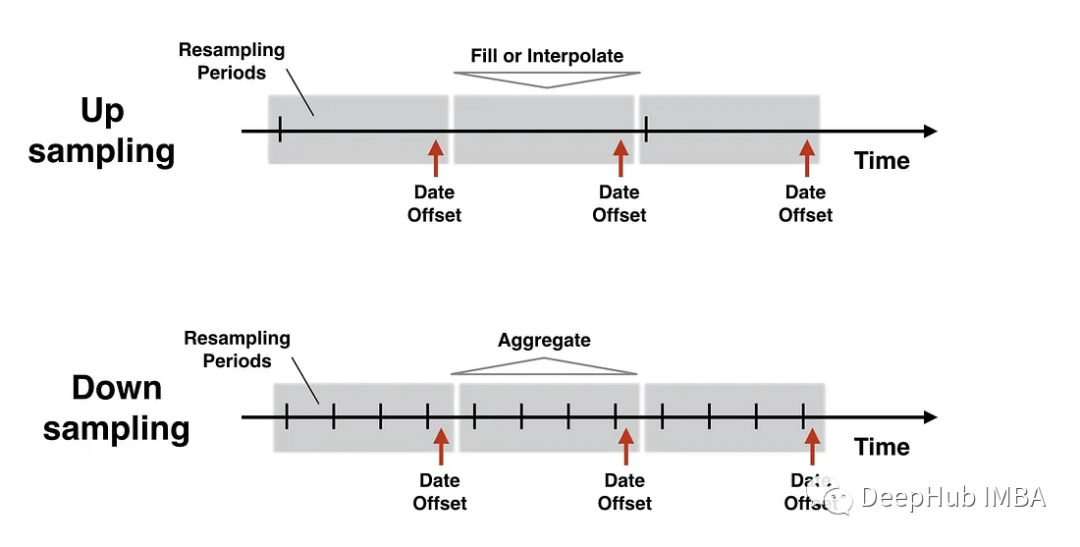
重采样分类
重采样主要有两种类型:
1、Upsampling
上采样可以增加数据的频率或粒度。这意味着将数据转换成更小的时间间隔。
2、Downsampling
下采样包括减少数据的频率或粒度。将数据转换为更大的时间间隔。
重采样的应用
重采样的应用十分广泛:
在财务分析中,股票价格或其他财务指标可能以不规则的间隔记录。重新可以将这些数据与交易策略的时间框架(如每日或每周)保持一致。
物联网(IoT)设备通常以不同的频率生成数据。重新采样可以标准化分析数据,确保一致的时间间隔。
在创建时间序列可视化时,通常需要以不同的频率显示数据。重新采样够调整绘图中的细节水平。
许多机器学习模型都需要具有一致时间间隔的数据。在为模型训练准备时间序列数据时,重采样是必不可少的。
重采样过程
重采样过程通常包括以下步骤:
首先选择要重新采样的时间序列数据。该数据可以采用各种格式,包括数值、文本或分类数据。
确定您希望重新采样数据的频率。这可以是增加粒度(上采样)或减少粒度(下采样)。
选择重新采样方法。常用的方法包括平均、求和或使用插值技术来填补数据中的空白。
在上采样时,可能会遇到原始时间戳之间缺少数据点的情况。插值方法,如线性或三次样条插值,可以用来估计这些值。
对于下采样,通常会在每个目标区间内聚合数据点。常见的聚合函数包括sum、mean或median。
评估重采样的数据,以确保它符合分析目标。检查数据的一致性、完整性和准确性。
Pandas中的resample()方法
resample可以同时操作Pandas Series和DataFrame对象。它用于执行聚合、转换或时间序列数据的下采样和上采样等操作。
下面是
resample()
方法的基本用法和一些常见的参数:
import pandas as pd
# 创建一个示例时间序列数据框
data = {'date': pd.date_range(start='2023-01-01', end='2023-12-31', freq='D'),
'value': range(365)}
df = pd.DataFrame(data)
# 将日期列设置为索引
df.set_index('date', inplace=True)
# 使用resample()方法进行重新采样
# 将每日数据转换为每月数据并计算每月的总和
monthly_data = df['value'].resample('M').sum()
# 将每月数据转换为每季度数据并计算每季度的平均值
quarterly_data = monthly_data.resample('Q').mean()
# 将每季度数据转换为每年数据并计算每年的最大值
annual_data = quarterly_data.resample('Y').max()
print(monthly_data)
print(quarterly_data)
print(annual_data)
在上述示例中,我们首先创建了一个示例的时间序列数据框,并使用
resample()
方法将其转换为不同的时间频率(每月、每季度、每年)并应用不同的聚合函数(总和、平均值、最大值)。
resample()
方法的参数:
- 第一个参数是时间频率字符串,用于指定重新采样的目标频率。常见的选项包括
'D'(每日)、'M'(每月)、'Q'(每季度)、'Y'(每年)等。 - 你可以通过第二个参数
how来指定聚合函数,例如'sum'、'mean'、'max'等,默认是'mean'。 - 你还可以使用
closed参数来指定每个区间的闭合端点,可选的值包括'right'、'left'、'both'、'neither',默认是'right'。 - 使用
label参数来指定重新采样后的标签使用哪个时间戳,可选的值包括'right'、'left'、'both'、'neither',默认是'right'。 - 可以使用
loffset参数来调整重新采样后的时间标签的偏移量。 - 最后,你可以使用聚合函数的特定参数,例如
'sum'函数的min_count参数来指定非NA值的最小数量。
1、指定列名
默认情况下,Pandas的resample()方法使用Dataframe或Series的索引,这些索引应该是时间类型。但是,如果希望基于特定列重新采样,则可以使用on参数。这允许您选择一个特定的列进行重新采样,即使它不是索引。
df.reset_index(drop=False, inplace=True)
df.resample('W', on='index')['C_0'].sum().head()
在这段代码中,使用resample()方法对'index'列执行每周重采样,计算每周'C_0'列的和。
2、指定开始和结束的时间间隔
closed参数允许重采样期间控制打开和关闭间隔。默认情况下,一些频率,如'M', 'A', 'Q', 'BM', 'BA', 'BQ'和'W'是右闭的,这意味着包括右边界,而其他频率是左闭的,其中包括左边界。在转换数据频率时,可以根据需要手动设置关闭间隔。
df = generate_sample_data_datetime()
pd.concat([df.resample('W', closed='left')['C_0'].sum().to_frame(name='left_closed'),
df.resample('W', closed='right')['C_0'].sum().to_frame(name='right_closed')],
axis=1).head(5)
在这段代码中,我们演示了将日频率转换为周频率时左闭间隔和右闭间隔的区别。
3、输出结果控制
label参数可以在重采样期间控制输出结果的标签。默认情况下,一些频率使用组内的右边界作为输出标签,而其他频率使用左边界。在转换数据频率时,可以指定是要使用左边界还是右边界作为输出标签。
df = generate_sample_data_datetime()
df.resample('W', label='left')['C_0'].sum().to_frame(name='left_boundary').head(5)
df.resample('W', label='right')['C_0'].sum().to_frame(name='right_boundary').head(5)
在这段代码中,输出标签是根据在label参数中指定“left”还是“right”而变化的,建议在实际应用时显式指定,这样可以减少混淆。
4、汇总统计数据
重采样可以执行聚合统计,类似于使用groupby。使用sum、mean、min、max等聚合方法来汇总重新采样间隔内的数据。这些聚合方法类似于groupby操作可用的聚合方法。
df.resample('D').sum()
df.resample('W').mean()
df.resample('M').min()
df.resample('Q').max()
df.resample('Y').count()
df.resample('W').std()
df.resample('M').var()
df.resample('D').median()
df.resample('M').quantile([0.25, 0.5, 0.75])
custom_agg = lambda x: x.max() - x.min()
df.resample('W').apply(custom_agg)
上采样和填充
在时间序列数据分析中,上采样和下采样是用来操纵数据观测频率的技术。这些技术对于调整时间序列数据的粒度以匹配分析需求非常有价值。
我们先生成一些数据
import pandas as pd
import numpy as np
def generate_sample_data_datetime():
np.random.seed(123)
number_of_rows = 365 * 2
num_cols = 5
start_date = '2023-09-15' # You can change the start date if needed
cols = ["C_0", "C_1", "C_2", "C_3", "C_4"]
df = pd.DataFrame(np.random.randint(1, 100, size=(number_of_rows, num_cols)), columns=cols)
df.index = pd.date_range(start=start_date, periods=number_of_rows)
return df
df = generate_sample_data_datetime()
上采样包括增加数据的粒度,这意味着将数据从较低的频率转换为较高的频率。
假设您有上面生成的每日数据,并希望将其转换为12小时的频率,并在每个间隔内计算“C_0”的总和:
df.resample('12H')['C_0'].sum().head(10)
代码将数据重采样为12小时的间隔,并在每个间隔内对' C_0 '应用总和聚合。这个.head(10)用于显示结果的前10行。
在上采样过程中,特别是从较低频率转换到较高频率时,由于新频率引入了间隙,会遇到丢失数据点的情况。所以需要对间隙的数据进行填充,填充一般使用以下几个方法:
向前填充-前一个可用的值填充缺失的值。可以使用limit参数限制正向填充的数量。
df.resample('8H')['C_0'].ffill(limit=1)
反向填充 -用下一个可用的值填充缺失的值。
df.resample('8H')['C_0'].bfill(limit=1)
最近填充 -用最近的可用值填充缺失的数据,该值可以是向前的,也可以是向后的。
df.resample('8H')['C_0'].nearest(limit=1)
Fillna —结合了前面三个方法的功能。可以指定方法(例如,'pad'/' fill', 'bfill', 'nearest'),并使用limit参数进行数量控制。
df.resample('8H')['C_0'].fillna(method='pad', limit=1)
Asfreq-指定一个固定的值来填充所有缺失的部分一次。例如,可以使用-999填充缺失的值。
df.resample('8H')['C_0'].asfreq(-999)
插值方法-可以应用各种插值算法。
df.resample('8H').interpolate(method='linear').applymap(lambda x: round(x, 2))
一些常用的函数
1、使用agg进行聚合
result = df.resample('W').agg(
{
'C_0': ['sum', 'mean'],
'C_1': lambda x: np.std(x, ddof=1)
}
).head()
使用agg方法将每日时间序列数据重新采样到每周频率。并为不同的列指定不同的聚合函数。对于“C_0”,计算总和和平均值,而对于“C_1”,计算标准差。
2、使用 apply 聚合
def custom_agg(x):
agg_result = {
'C_0_mean': round(x['C_0'].mean(), 2),
'C_1_sum': x['C_1'].sum(),
'C_2_max': x['C_2'].max(),
'C_3_mean_plus1': round(x['C_3'].mean() + 1, 2)
}
return pd.Series(agg_result)
result = df.resample('W').apply(custom_agg).head()
定义了一个名为custom_agg的自定义聚合函数,它将DataFrame x作为输入,并在不同列上计算各种聚合。使用apply方法将数据重新采样到每周的频率,并应用自定义聚合函数。
3、使用transform进行变换
df['C_0_cumsum'] = df.resample('W')['C_0'].transform('cumsum')
df['C_0_rank'] = df.resample('W')['C_0'].transform('rank')
result = df.head(10)
使用transform 方法来计算每周组中'C_0'变量的累积和排名。DF的原始索引结构保持不变。
4、使用pipe 进行管道操作
result = df.resample('W')['C_0', 'C_1'] \
.pipe(lambda x: x.cumsum()) \
.pipe(lambda x: x['C_1'] - x['C_0'])
result = result.head(10)
使用管道方法对下采样的'C_0'和'C_1'变量进行链式操作。cumsum函数计算累积和,第二个管道操作计算每个组的'C_1'和'C_0'之间的差值。像管道一样执行顺序操作。
总结
时间序列的重采样是将时间序列数据从一个时间频率(例如每日)转换为另一个时间频率(例如每月或每年),并且通常伴随着对数据进行聚合操作。重采样是时间序列数据处理中的一个关键操作,通过进行重采样可以更好地理解数据的趋势和模式。
在Python中,可以使用Pandas库的
resample()
方法来执行时间序列的重采样。
作者:JIN