
一些博弈论困境,如著名的布雷斯悖论,对多智能体强化学习有着深刻的影响。

纵观历史,人类已经建立了许多既需要自主行动又需要参与者之间协调互动的系统。交通网络、智能电网或股票市场就是这些系统的例子,它们已经成为我们社会的基本支柱。这些系统的基本特征是,它们要求参与者执行自治任务,这些任务的影响是在与其他参与者共享的环境中看到的。在人工智能(AI)代理中重现这种动态是极具挑战性的。其中一个挑战便是如何平衡AI代理的个人利益与整个群体的利益。人工智能解决方案公司SecondMind最近的一篇论文详细介绍了实施多智能体人工智能系统的激励模型。
Prowler的研究集中于一种深度学习学科,称为多智能体强化学习(MARL),它已成为实现自主、多智能体、自学习系统的最先进技术。
分散的MARL
在深度学习生态系统中,多智能体强化学习(MARL)是专注于实现具有多个智能体的自主、自学习系统的领域。从概念上讲,多智能体强化学习(MARL)是一种深度学习学科,专注于包括多个智能体的模型,这些智能体通过与环境动态交互进行学习。在单代理强化学习场景中,环境状态的改变仅仅是由于一个代理的行为,而在MARL场景中,环境受到所有代理的行为的影响。从这个角度来看,我们认为MARL环境是一个元组{X1-A1,X2-A2....Xn-An},其中Xm是任意给定的代理,Am是任意给定的动作,那么环境的新状态是由A1xA2x....An定义的连接动作集的结果。换句话说,MARL场景的复杂性随着环境中代理的数量的增加而增加。
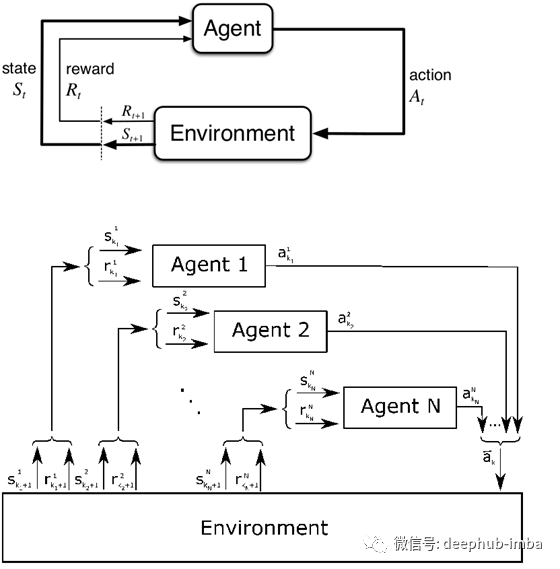
虽然MARL系统本质上是分布式的,但我们仍然可以确定两种主要的架构类型:集中式和分散式。集中式MARL模型依赖于一个控制权威来管理每个代理的奖励。这种类型的体系结构实现起来更简单,在跨不同代理协调目标方面也相对简单,但它会导致大规模操作的计算代价很高,最重要的是,它阻碍了自治。最后,如果一个代理人的报酬是由一个中央集权机构控制的我们不能说代理人是自治的,对吧?😉集中式MARL模型的局限性与激励代理自主行动的系统产生了直接的矛盾。想想股票市场,交易员受到个人收益的驱动,但仍然需要注意交易对手风险。这种类型的体系结构更适合分散的MARL模型,在这种模型中,代理可以自主地行动,协调是基于激励发生的。
在过去的几个月里,随着OpenAI等人工智能巨头创造了能够打败Dota2的系统,DeepMind也在《雷神之锤3》中创造了同样的系统,MARL场景也获得了成功。然而,在这两种场景中,MARL环境只涉及少量代理。到目前为止,MARL方法在应用于涉及大量代理的场景时一直很困难。随着MARL系统中代理数量的增加,它们之间协调的复杂性也随之增加。从这个角度来看,为大规模MARL系统建立一个激励模型仍然是实现这些新架构的最大挑战之一。
布雷斯悖论与纳什均衡
德国数学家Dietrich Braes在1968年提出的一个悖论可以解释MARL系统激励建模的挑战。作为拥堵交通网络的一个例子,Braes解释说,与直觉相反,在道路网络中增加一条路可能会阻碍它的流动(例如每个司机的行驶时间);同样地,封闭道路可能会改善通行时间。官方对这一悖论的解释如下:
“对于路网的每个点,给定从它出发的汽车数量和汽车的目的地的情况下,人们希望估计交通流的分布。一条街道是否比另一条街道更好,不仅取决于道路的质量,还取决于人流的密度。如果每个驾驶者都选择了对它们最有利的路径,那么最终的运行时间肯定不是最小的。此外,通过一个例子表明,道路网络的扩展可能导致交通的重新分配,从而导致更长的个人通行时间。”
布雷斯悖论似乎在挑战多主体系统的黄金标准:纳什均衡。还记得2001年的电影《美丽心灵》(A Beautiful Mind)吗?在这部电影中,罗素·克劳(Russell Crowe)用一个生动的例子解释了纳什均衡的基础。

如果我们都去追金发女郎,互相影响并且没人能追到她。然后我们去找她的朋友,但他们都不理我们,因为没人愿意当第二选择。但如果我们都不喜欢金发女郎呢?我们不会妨碍彼此也不会侮辱其他女孩。这是获胜的唯一途径。——《美丽心灵》
如果我们再加上一个漂亮的金发女郎会怎么样。理论上,这应该是一个优化,因为现在小组有更多的选择。然而,如果第二个金发女郎比第一个更有吸引力,这可能会导致所有参与者更加激烈地相互竞争,导致进一步的延迟(无论在这个场景中这意味着什么😉)。这是教科书上关于Braes悖论的一个例子因为纳什均衡发生在各主体对彼此作出最佳反应的时候而在现实世界的多主体系统中并不总是这样。
Braes悖论与MARL架构非常相关,因为神经网络的任何优化都会影响智能代理对其作出反应的方式。从这个角度来看,MARL系统应该依赖于那些激励的微小变化可以转化为不成比例的积极结果的州。
智能的激励
Prowler用一种将问题分成两部分的新方法解决了MARL体系结构中激励优化的问题。其中一部分是根据一组给定的奖励函数计算个体的最佳响应策略。另一部分是在代理的联合反应下找到对奖励函数(或激励)的最佳修改集。这种方法以分散计算的方式分解问题,因为代理自己计算它们的最佳响应策略。在模拟环境中,多智能体强化学习计算纳什均衡,贝叶斯优化计算最优激励。
在Prowler架构中,在非常聪明的集成中使用MARL和贝叶斯优化来优化代理网络中的激励机制。
MARL用来模拟代理的行为,并通过元代理对给定参数的选择产生代理的纳什均衡行为。
贝叶斯优化是用来选择能得到更理想结果的博弈参数。贝叶斯优化基于随机性找到与系统动态匹配的最佳模型。
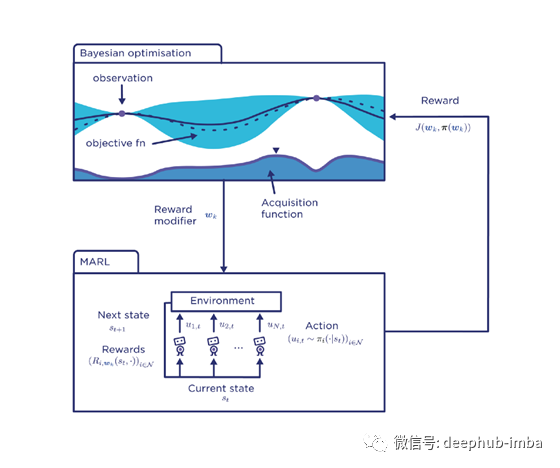
Prowler的聪明激励模型依赖于激励设计师在模拟游戏中选择奖励功能,即由代理扮演,模拟代理的联合行为。激励设计者的目标是修改代理奖励函数的集合,用于诱导使系统性能最大化的行为的子博弈。利用模拟子博弈的反馈来响应代理报酬函数的变化,激励设计者可以精确地计算出对代理报酬的修改,从而在现实世界的博弈中自利代理之间产生理想的均衡。模拟环境避免了从现实环境中获取反馈数据的昂贵需求,同时确保生成的代理行为与现实结果一致。
智能的激励措施
Prowler将其智能激励技术应用于几个迷人的MARL问题。在一个场景中,MARL模型试图分布2000个自利益代理,每个代理都试图在某个时间范围内将自己定位于空间中的理想点。一个区域的可取性随时间而变化,并随着位于该区域内的代理的数量而减少。例如,考虑这样一个场景:代理是车队中的出租车司机,然后每个司机(及其同事)可能会聚集在足球场周围,因为他们知道比赛即将结束,球迷需要搭便车回家。虽然这种行为可能有利于个别司机,但它有利于交通拥堵,并将离开城市的其他点没有准确的交通覆盖。
采用智能激励模型,激励设计者引入奖励修正器,激励代理商采用期望分布。结果是,2000名司机以最优方式分配自己,最大限度地扩大了领土覆盖范围。
MARL系统是深度学习空间中最吸引人的研究领域之一。随着这些架构朝着去中心化的方向发展,健壮的激励模型的需求将变得更加相关。像《Prowler》的聪明激励机制便是朝着正确方向迈出的一步。
论文地址:arxiv:1901.10923
原文作者:Jesus Rodriguez