
大数据项目实战
第三章 数据采集
文章目录
学习目标
掌握 HDFS API 的基本使用
熟悉 HttpClent 爬虫的使用方法
一、分析与准备
本篇主要对要采集的数据结构进行分析以及创建编写数据采集程序的环境,为最终编写数据采集程序做准备。
1、分析网页结构
在爬取网站数据前要先通过分析网站的源码结构制定爬虫程序的编写方式,以便能获取准确的数据。
使用 Google 浏览器进入开发者模式,切换到 Network 这一项,在浏览器的地址栏中输入要爬取数据网站的 URL,在职位搜索栏中输入想要分析的值为进行检索,这时候可以看到服务器返回的内容,因为内容较多,不太容易找到职位信息数据,所以通过设置过滤,过滤掉不需要的信息。
因为该网站的值为信息并不在 HTML 源代码里,而是保存在 JSON 文件例,因此在过滤后的一栏中选择 XHR(XML Http Request) 过滤规则,这样就可以只看到 Ajax 请求中的 JSON 文件了,我们将要获取的值为信息数据也在这个 JSON 文件中。如图所示。
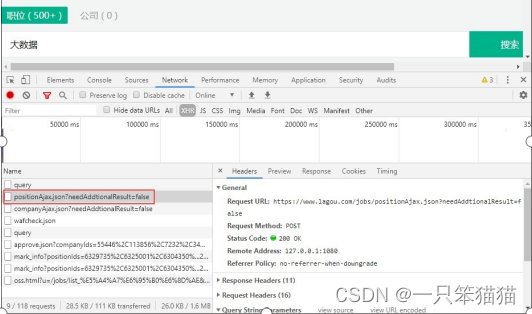
单击 positionAjax.json 这一条信息,在弹出的窗口选择 Preview 选项,通过逐级展开 JSON 文件中的数据,在 content --》positionResult --》result 下查看大数据相关的值为信息。如图所示。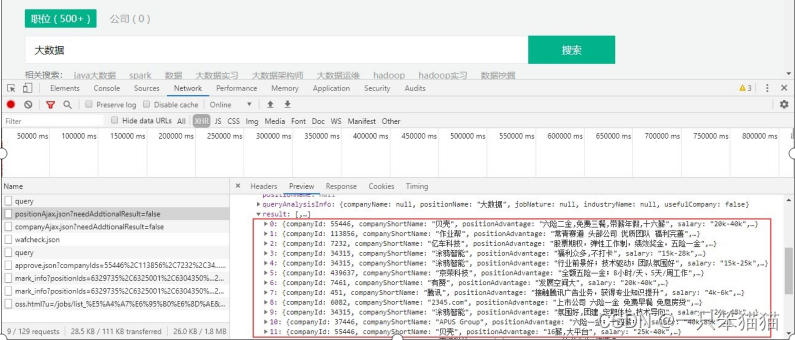
2、数据采集环境准备
本篇编写数据采集程序祝以后啊通过 Eclipse 开发工具完成(当然笨猫猫觉得使用 IDEA 开发工具完成也是可以的哦),实现网络数据的采集。
1)打开 Eclipse 工具,单击 File->new->Other,进入 Select a wizard 界面,选择要创建工程的类别,这里选择的是 Maven Project,即创建一个Maven工程。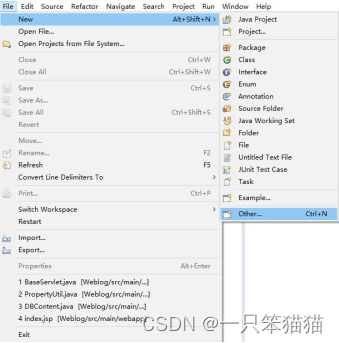
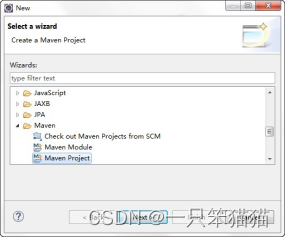
2)创建 Maven Project,单击 Next 按钮,进入新建项目类别的选择界面,勾选 Create a simple project 复选框,创建 一个简单的 Maven 工程。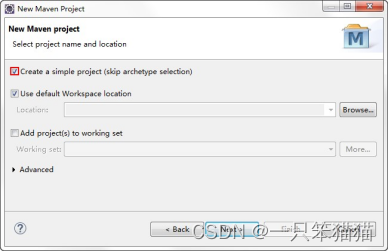
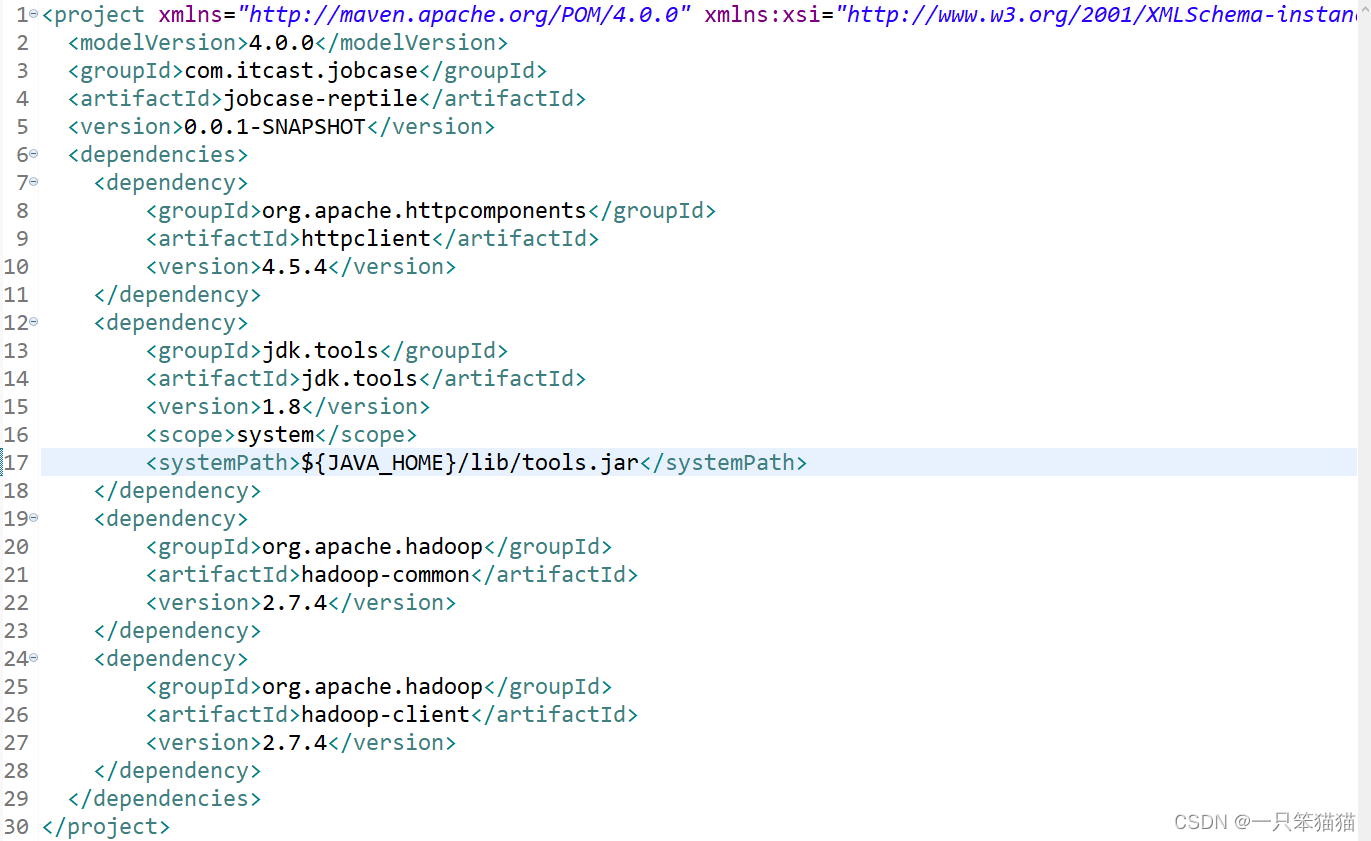
3)单击 Next 按钮,进入 Maven 工程的配置界面,即指定 Group Id 为 com.itcast.jobcase,指定 Artifact Id 为 jobcase-reptile,并在 Packaging 下拉选择框中选择打包方式为 jar 。如图所示。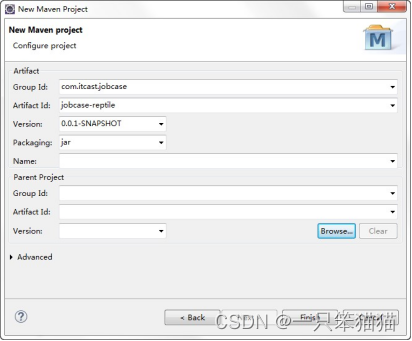
4)单击 Finish 按钮,完成 Maven 工程的配置,创建好的 Maven 工程 jobcase-reptile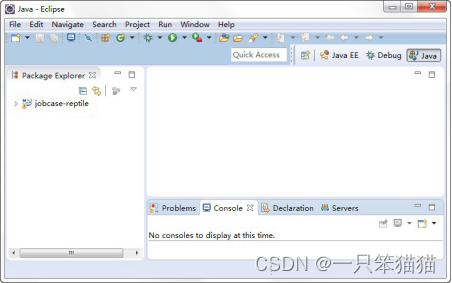
5)双击 jobcase-reptile 工程,选中 src/main/java 文件夹,右键单击 New->Package 创建 Package 包,并命名包为 com.position.reptile。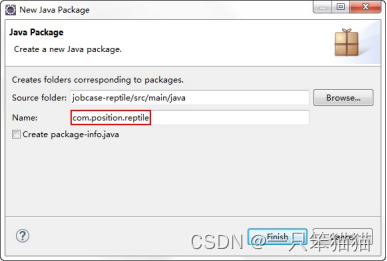
6)单击 Finish 按钮,完成 Package 包的创建,创建好的 Package 包如图所示。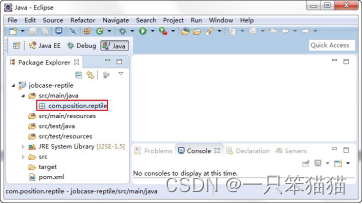
7)在上图,双击 pom.xml 文件,添加编写爬虫程序所需要的 HttpClient 和 JDK 1.8 依赖。pom.xml 文件添加的内容,具体如下。
<dependencies><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.4</version></dependency><dependency><groupId>jdk.tools</groupId><artifactId>jdk.tools</artifactId><version>1.8</version><scope>system</scope><systemPath>${JAVA_HOME}/lib/tools.jar</systemPath></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.4</version></dependency></dependencies>
8)选中 jobcase-reptile 工程,右键单击选择 Maven->Update Project 更新工程。至此,就完成了 Maven 工程的搭建。
二、采集网页数据
1.创建响应结果 JavaBean 类
本项目才采集的网页数据为 HTTP 请求过程中的响应结果数据,通过创建的 HttpClient 响应结果对象作为数据存储的载体,对响应结果中的状态码和数据内容进行封装。
在 com.position.reptile 包下,创建名为 HttpClientResp.java 文件的 JavaBean 类。
packagecom.position.reptile;importjava.io.Serializable;publicclassHttpClientRespimplementsSerializable{privatestaticfinallong serialVersionUID =-8664139869153319066L;//相应状态码privateint code;privateString content;//定义无参的构造方法publicHttpClientResp(){}//定义有参的构造方法publicHttpClientResp(String content){this.content = content;}publicHttpClientResp(int code){this.code = code;}publicHttpClientResp(int code,String content){this.code = code;this.content = content;}//定义属性的get/set方法publicintgetCode(){return code;}publicvoidsetCode(int code){this.code = code;}publicStringgetContent(){return content;}publicvoidsetContent(String content){this.content = content;}//重写toString方法@OverridepublicStringtoString(){return"HttpClientResp [code="+ code +", content="+ content +"]";}}
2.封装 HTTP 请求的工具类
在 com.position.reptile 包下,创建一个命名为 HttpClientUtils.java 文件的工具类,用于实现 HTTP 请求的方法。
1)定义三个全局变量
在类中定义三个全局变量,便于在类中的方法统一访问,下面是这三个常量的概述。
ENCODING:表示定义发送请求的编码格式
CONNECT_TIMEOUT:表示设置建立连接超时时间
SOCKET_TIMEOUT:表示设置请求获取数据的超时时间
为了有效地防止程序阻塞,可以在程序中设置 CONNECT_TIMEOUT 和 SOCKET_TIMEOUT 两项参数,通过在类中定义常量的方式定义参数的内容。
文件HttpClientUtils.java
//编码格式,发送编码格式统一用UTF-8privatestaticfinalString ENCODING ="UTF-8";//设置连接超时时间,单位毫秒privatestaticfinalint CONNECT_TIMEOUT =100000;//请求获取数据的超时时间(即响应时间),单位毫秒privatestaticfinalint SOCKET_TIMEOUT =100000;
2)编写 packageHeader() 方法
在工具类中定义 packageHeader() 方法用于封装 HTTP 请求头的参数,如 Cookie、User-Agent 等信息,该方法中包含两个参数,分别为 params 和 httpMethod。
文件HttpClientUtils.java
publicstaticvoidpackageHeader(Map<String,String>params,HttpRequestBase httpMethod){//封装请求头if(params !=null){/*
* 通过entrySet()方法从params中返回所有键值对的集合,并保存在entrySet中
* 通过foreach()方法每次取出一个键值对保存在一个entry中
* */Set<Entry<String,String>>entrySet = params.entrySet();for(Entry<String,String>entry : entrySet){//通过entry分别获取键-值,将键-值参数设置到请求头HttpRequestBase对象中
httpMethod.setHeader(entry.getKey(),entry.getValue());}}}
params 参数的数据类型为 Map<String,String>,主要用于封装请求头中的参数,其中, Map 的 Key 表示请求头参数的名称,Value 代表请求头参数的内容。例如,在请求头中参加 Cookie,那么 Map 的 Key 则为 Cookie,Value则为 Cookie 的具体内容。
httpMethod 参数为 HttpRequstBase 类型,HttpRequestBase 是一个抽象类,用于调用子类 HttpPost 实现类。
3)编写 packageParam() 方法
设置 HTTP 请求头向服务器发送请求,通过设置请求参数来指定获取哪些类型的数据内容,具体需要哪些参数以及这些参数的作用,会在后续的代码中进行讲解。在工具类中定义 packageParam() 方法用于封装 HTTP 请求参数,该方法中包含两个参数,分别为 params 和 httpMethod 。
文件HttpClientUtils.java
publicstaticvoidpackageParam(Map<String,String>params,HttpEntityEnclosingRequestBase httpMethod)throwsUnsupportedEncodingException{//封装请求对象if(params !=null){/*
* NameValuePair是简单名称值对节点类型 多用于Java想url发送Post请求。在发送post请求时用该list来存放参数
*/List<NameValuePair>nvps =newArrayList<NameValuePair>();/*
* 通过entrySet()方法从params中返回所有键值对的集合,
* 并保存在entrySet中,通过foreach方法每次取出一个键值对保存在一个entry中
*/Set<Entry<String,String>>entrySet = params.entrySet();for(Entry<String,String>entry : entrySet){//分别提取entry中的key和value放入nvps数组中。
nvps.add(newBasicNameValuePair(entry.getKey(),
entry.getValue()));}//设置到请求的http对象中,这里的ENCODING为之前创建的编码常量
httpMethod.setEntity(newUrlEncodedFormEntity(nvps,ENCODING));}}
上述代码中,params 参数为 Map<String,String> 类型,用于封装请求中的参数名称及参数值, httpMethod 参数为 HttpEntityRequestBase 类型,是一个抽象类,其实现类包括 HttpPost、HttpPatch、HttpPut,是 HttpRequesBase 的子类,将设置的请求持仓数封装在 HttpEntityEnclosingRequestBase 对象。
4)编写 HttpClient() 方法
前两步已经创建了封装请求头和请求参数的方法,按照 HTTP 请求的流程在服务器收到 HTTP 响应内容,该方法中包含三个参数,分别为 httpResponse、httpClient 和 httpMethod,该方法包含返回值,返回值类型为之前定义的实体类 HttpClientResp,其中内容包括响应代码和响应内容。
publicstaticHttpClientRespgetHttpClientResult(CloseableHttpResponse httpResponse,CloseableHttpClient httpClient,HttpRequestBase httpMethod)throwsException{//通过请求参数httpMethod执行Http请求
httpResponse = httpClient.execute(httpMethod);//获取HTTP的响应结果if(httpResponse !=null&& httpResponse.getStatusLine()!=null){String content ="";if(httpResponse.getEntity()!=null){//将响应结果转为String类型,并设置编码格式
content =EntityUtils.toString(httpResponse.getEntity(),ENCODING);}/*
* 返回HTTPClientResp实体类的对象,这两个参数
* 分别 代表实体类中的code属性和content属性,
* 分别代表响应代码和响应内容
*/returnnewHttpClientResp(httpResponse.getStatusLine().getStatusCode(),content);}//如果没有接收到响应内容则返回响应的错误信息returnnewHttpClientResp(HttpStatus.SC_INTERNAL_SERVER_ERROR);}
在上述代码中,创建的 getHttpClientResult() 方法包含三个参数: httpResponse 参数为 CloseableHttpResponse 类型,用于在服务器接收并解释请求消息之后以 HTTP 响应消息进行响应,我们将要获取的响应内容就是通过该参数获取:httpClient 参数为 CloseableHttpClient 类型,用于表示 HTTP 请求执行的基础对象:httpMethod 参数为 HttpRequestBase 类型,用于实现 HttpPost。
5)编写 doPost() 方法
在前面创建了请求头、请求参数以及获取响应内容的方法。接下来将讲解荣国 HttpClient Post 方式提交请求头和请求参数,从服务端返回状态码和 JSON 数据内容。
注意:选取请求方法要与爬取网站规定的请求方法一致。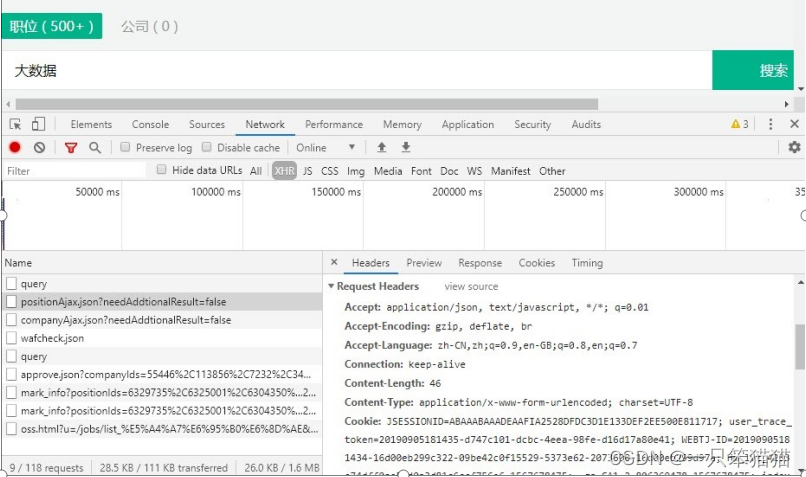
publicstaticHttpClientRespdoPost(String url,Map<String,String>headers,Map<String,String>params)throwsException{//创建httpClient对象CloseableHttpClient httpClient =HttpClients.createDefault();//创建httpPost对象HttpPost httpPost =newHttpPost(url);/*
* setConnectTimeout:设置连接超时时间,单位毫秒。 setConnectionRequestTimeout:设置从connect
* Manager(连接池) 获取Connection 超时时间,单位毫秒。这个属性是新加的属性,因为目前版本是可以共享连接池的。
* setSocketTimeout:请求获取数据的超时时间(即响应时间),单位毫秒。 如果访问一个接口,多少时间内无法返回数据,就直接放弃次调用。
*///封装请求配置项RequestConfig requestConfig =RequestConfig.custom().setConnectTimeout(CONNECT_TIMEOUT).setSocketTimeout(CONNECT_TIMEOUT).build();//设置post请求配置项
httpPost.setConfig(requestConfig);//通过创建的packageHeader()方法设置请求头packageHeader(headers,httpPost);//通过创建的packageParam()方法设置请求参数packageParam(params,httpPost);//创建httpResponse对象获取响应内容CloseableHttpResponse httpResponse =null;try{//执行请求并响应结果returngetHttpClientResult(httpResponse,httpClient,httpPost);}finally{//释放资源release(httpResponse,httpClient);}}
上述代码中的 doPost() 方法,定义的返回值类型为实体类 HttpClientResp 对象,方法中包含三个参数。三个参数如下。
url:进行数据采集的网站链接
headers:请求头数据
params:请求参数数据
在 doPost() 方法中调用已创建的 getHttpClientResult() 方法获取响应结果数据并作为方法的返回值。
在释放资源一行代码会报错,因为释放资源方法需要通过自行创建后去调用,下面梁编写释放资源代码。
6)编写 release() 方法
HttpClient 在使用过程中要注意资源释放和超时处理的问题,如果线程资源无法释放,会导致线程一直在等待,最终可导致内存或线程被大量占用。这里创建了一个释放资源的方法 release() 主要用于释放 httpclient(HTTP 请求)对象资源和 httpResponse(HTTP 响应)对象资源。
privatestaticvoidrelease(CloseableHttpResponse httpResponse,CloseableHttpClient httpClient)throwsIOException{// TODO Auto-generated method stub// 释放资源if(httpResponse !=null){
httpResponse.close();}if(httpClient !=null){
httpClient.close();}}
至此, HttpClient 的所有工具类准备完毕,后续直接在实现网页数据采集的主类中调用这些方法即可,通过编写存储数据的工具类,实现瓯江采集的网页数据存储到 HDFS 上。
3.封装存储在 HDFS 的工具类
通过前两节的操作可以成功采集招聘网站的数据,为了便于后续对数据预处理和分析,需要将数据采集程序获取的数据存储到本地或者集群中的 HDFS 上,下面演示如何将爬取的数据存放到 HDFS 上。
1)添加 Hadoop 的依赖
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.4</version></dependency>
之前添加过了,可以不用再次添加。
2)编写 createFileBySysTime() 方法。
在 com.position.reptile 包下,创建名为 HttpClientHdfsUtils.java 文件工具类,实现将数据写入 HDFS 的方法 createFileBySysTime() ,该方法包括三个参数:url (表示 Hadoop 地址)、fileName(表示存储数据的文件名称)和 data(表示数据内容)。
文件HttpClientHdfsUtils.java
publicclassHttpClientHdfsUtils{publicstaticvoidcreateFileBySysTime(String url,String fileName,String data){//指定操作HDFS的用户
System.setProperty("HADOOP_USER_NAME","root");
Path path =null;//读取系统时间
Calendar calendar = Calendar.getInstance();
Date time = calendar.getTime();//格式化系统时间为年月日的形式
SimpleDateFormat format =newSimpleDateFormat("yyyyMMdd");//获取系统当前时间并将其转换为string类型,fileName即存储数据的文件夹名称
String filePath = format.format(time);//构造Configuration对相关,配置Hadoop参数
Configuration conf =newConfiguration();//实例化URI引入uriURI uri =URI.create(url);//实例化FileSystem对象,处理文件和目录相关的事务
FileSystem fileSystem;try{//获取文件系统对象
fileSystem = FileSystem.get(uri,conf);//定义文件路径
path =newPath("/JobData/"+filePath);//判断路径是否为空if(!fileSystem.exists(path)){//创建目录
fileSystem.mkdirs(path);}//在指定目录下创建文件
FSDataOutputStream fsDataOutputStream = fileSystem.create(newPath(path.toString()+"/"+fileName));//向文件中写入数据
IOUtils.copyBytes(newByteArrayInputStream(data.getBytes()),
fsDataOutputStream, conf,true);//关闭连接释放资源
fileSystem.close();}catch(IOException e){
e.printStackTrace();}}}
上述代码中,指定在 Hadoop 集群的 HDFS 上创建 /JobData 目录,用于存储当天爬取的数据,数据将文件的形式存储在由当前系统日期的“年月日”组成目录下。
4.实现网页数据采集
1)获取网站的请求头内容
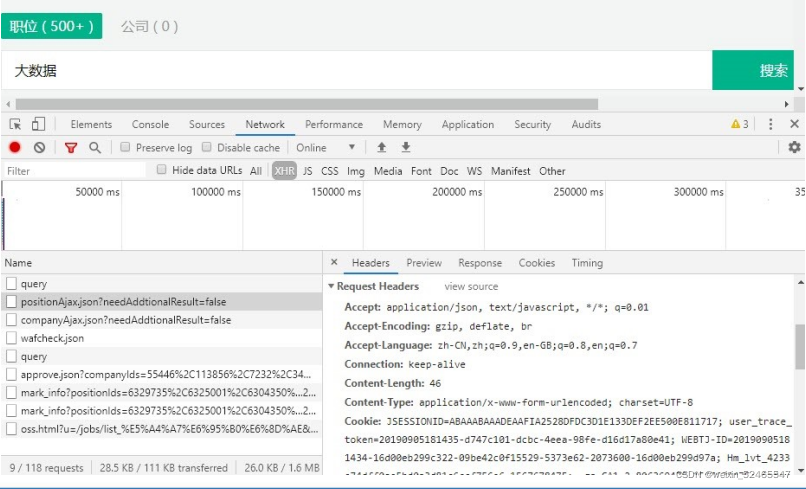
上图中,将 Request Headers 一项中的参数以<Key,Value>形式写入到 Map 集合中作为数据采集程序的请求头,目的是模拟浏览器登录,防止爬虫失败。
2)创建 Map 集合 headers
在 com.position.reptile 包下,创建名为 HttpClientData.java 文件的主类,用于实现数据采集功能,在该类中创建 main() 方法,在 main() 方法中创建 Map 集合 headers ,将请求头参数放入集合中。
文件 HttpClientData.java
//设置请求头Map<String,String> headers =newHashMap<String,String>();
headers.put("Cookie","");
headers.put("Connection","keep-alive");
headers.put("Accept-Language","zh-CN,zh;q=0.9");
headers.put("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36");
headers.put("content-type","application/x-www-form-urlencoded; charset=UTF-8");
headers.put("Referer","https://www.lagou.com/jobs/list_%E5%A4%A7%E6%95%B0%E6%8D%AE/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=");
headers.put("Origin","https://www.lagou.com");
headers.put("x-requested-with","XMLHttpRequest");
headers.put("x-anit-forge-token","None");
headers.put("Cache-Control","no-cache");
headers.put("x-anit-forge-code","0");
headers.put("Host","www.lagou.com");
注意:Cookie 后面要有参数,这里因为太长了我设置了空字符,在开发者工具找到 Cookie参数后,其后面的参数要写进去。
3)创建 Map 集合 params
在 HttpClientData 类的 main() 方法中再创建一个 Map 集合 params,将请求参数放入集合中,本项目主要使用三个参数类指定获取获得数据类型,这三个参数包括: kd(职位类型),city (城市)和 pn(页数)。其中,pn 参数需要在每次 HTTP 请求中发生递增变化,用于爬取不同页面中的数据,因此向集合 params 中添加 pn 参数的操作应放在循环中进行。请求头和请求参数设置完毕后,通过 HttpClient 的 post 请求实现数据的获取,因为需要获取不同页面的数据,每个页面的 pn 参数都会发生变化(请求参数发生变化),因此获取数据的方法要放在实现的 for 循环中,通过变化的参数获取数据,将数据保存到 HDFS 上。
文件 HttpClientData.java
Map<String,String>params =newHashMap<String,String>();
params.put("kd","大数据");
params.put("city","全国");for(int i =1; i <31; i++){
params.put("pn",String.valueOf(i));HttpClientResp result =HttpClientUtils.doPost("https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false&first=true&px=default", headers, params);HttpClientHdfsUtils.createFileBySysTime("hdfs://hadoop001:8020","page"+i, result.toString());Thread.sleep(1*500);}
5.运行结果
在虚拟机上执行以下命令,有图中结果。
hdfs dfs -ls /JobData/。。。。。。
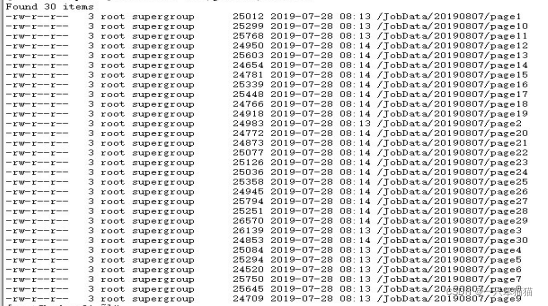
点击其中一个page,下载查看内容。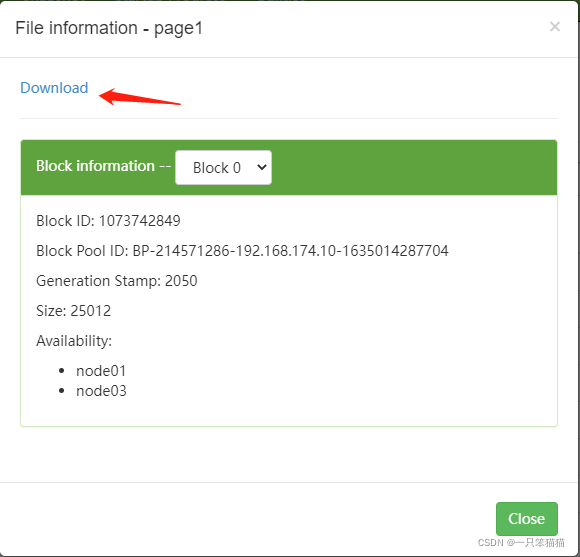
有如下内容即为爬取成功。
总结
本篇主要简介网络数据采集程序的变下。通过本篇的学习,读者可以掌握通过 HttpClient 框架进行爬虫的技巧,熟悉编写爬虫程序的操作流程。
版权归原作者 一只笨猫猫 所有, 如有侵权,请联系我们删除。