
继前文Unet和Unet++之后,本文将介绍Attention Unet。
Attention Unet地址,《Attention U-Net: Learning Where to Look for the Pancreas》。
AttentionUnet
Attention Unet发布于2018年,主要应用于医学领域的图像分割,全文中主要以肝脏的分割论证。
论文中心
Attention Unet主要的中心思想就是提出来Attention gate模块,使用soft-attention替代hard-attention,将attention集成到Unet的跳跃连接和上采样模块中,实现空间上的注意力机制。通过attention机制来抑制图像中的无关信息,突出局部的重要特征。
网络架构
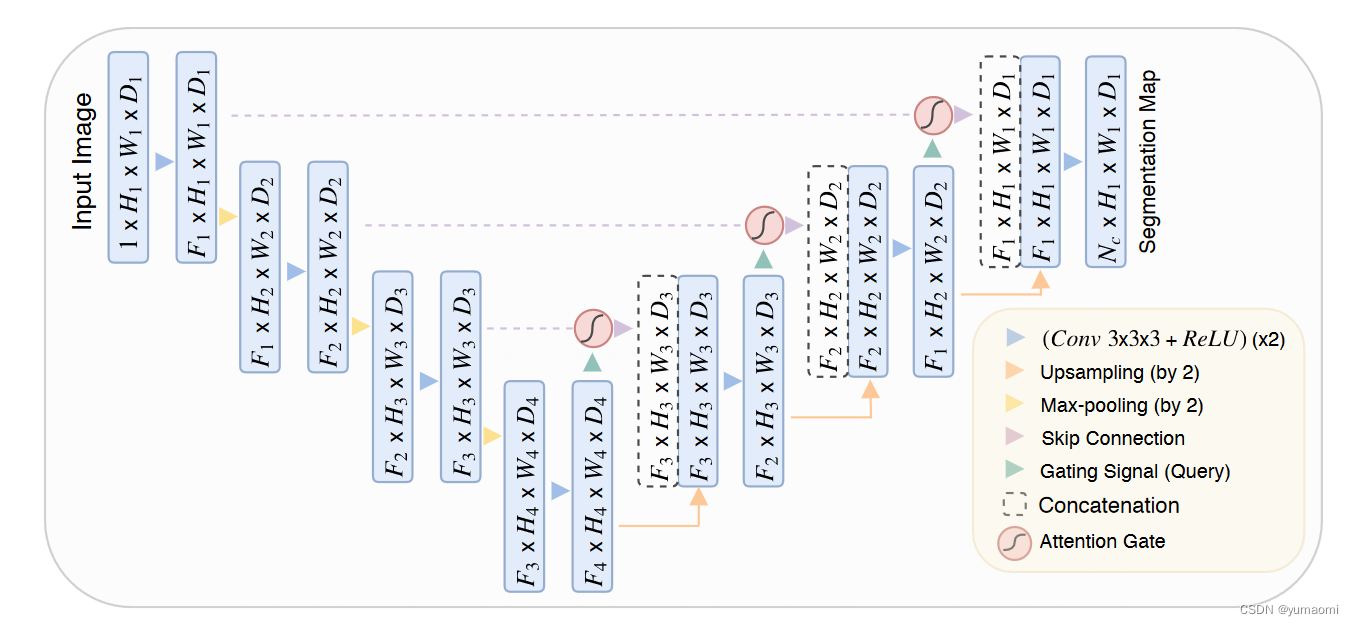
图1 AttentionUnet模型
Attention Unet的模型结构和Unet十分相像,只是增加了Attention Gate模块来对skip connection和upsampling层做attention机制(图2)。
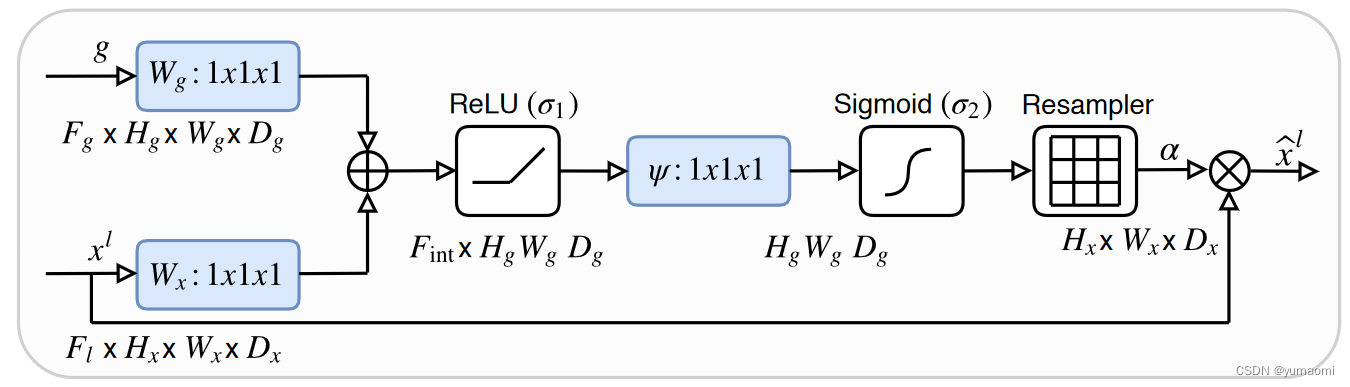
图2 Attention Gate模块
在Attention Gate模块中,g和xl分别为skip connection的输出和下一层的输出,如图3。
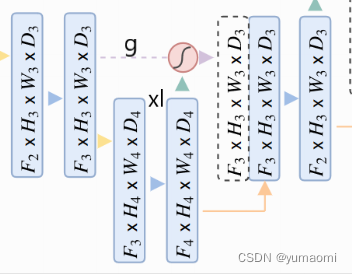
图3 Attention Gate的输入
需要注意的是,在计算Wg和Wx后,对两者进行相加。但是,此时g的维度和xl的维度并不相等,则需要对g做下采样或对xl做上采样。(我倾向于对xl做上采样,因为在原本的Unet中,在Decoder就需要对下一层做上采样,所以,直接使用这个上采样结果可以减少网络计算)。
Wg和Wx经过相加,ReLU激活,1x1x1卷积,Sigmoid激活,生成一个权重信息,将这个权重与原始输入xl相乘,得到了对xl的attention激活。这就是Attenton Gate的思想。
Attenton Gate还有一个比较重要的特点是:这个权重可以经由网络学习!因为soft-attention是可微的,可以微分的attention就可以通过神经网络算出梯度并且前向传播和后向反馈来学习得到attention的权重。以此来学习更重要的特征。
模型复现
Attention Unet代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import init
def init_weights(net, init_type='normal', gain=0.02):
def init_func(m):
classname = m.__class__.__name__
if hasattr(m, 'weight') and (classname.find('Conv') != -1
or classname.find('Linear') != -1):
if init_type == 'normal':
init.normal_(m.weight.data, 0.0, gain)
elif init_type == 'xavier':
init.xavier_normal_(m.weight.data, gain=gain)
elif init_type == 'kaiming':
init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
elif init_type == 'orthogonal':
init.orthogonal_(m.weight.data, gain=gain)
else:
raise NotImplementedError(
'initialization method [%s] is not implemented' %
init_type)
if hasattr(m, 'bias') and m.bias is not None:
init.constant_(m.bias.data, 0.0)
elif classname.find('BatchNorm2d') != -1:
init.normal_(m.weight.data, 1.0, gain)
init.constant_(m.bias.data, 0.0)
print('initialize network with %s' % init_type)
net.apply(init_func)
class conv_block(nn.Module):
def __init__(self, ch_in, ch_out):
super(conv_block, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(ch_in,
ch_out,
kernel_size=3,
stride=1,
padding=1,
bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True),
nn.Conv2d(ch_out,
ch_out,
kernel_size=3,
stride=1,
padding=1,
bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True))
def forward(self, x):
x = self.conv(x)
return x
class up_conv(nn.Module):
def __init__(self, ch_in, ch_out, convTranspose=True):
super(up_conv, self).__init__()
if convTranspose:
self.up = nn.ConvTranspose2d(in_channels=ch_in, out_channels=ch_in,kernel_size=4,stride=2, padding=1)
else:
self.up = nn.Upsample(scale_factor=2)
self.Conv = nn.Sequential(
nn.Conv2d(ch_in,
ch_out,
kernel_size=3,
stride=1,
padding=1,
bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True))
def forward(self, x):
x = self.up(x)
x = self.Conv(x)
return x
class single_conv(nn.Module):
def __init__(self, ch_in, ch_out):
super(single_conv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(ch_in,
ch_out,
kernel_size=3,
stride=1,
padding=1,
bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True))
def forward(self, x):
x = self.conv(x)
return x
class Attention_block(nn.Module):
def __init__(self, F_g, F_l, F_int):
super(Attention_block, self).__init__()
self.W_g = nn.Sequential(
nn.Conv2d(F_g,
F_int,
kernel_size=1,
stride=1,
padding=0,
bias=True),
nn.BatchNorm2d(F_int))
self.W_x = nn.Sequential(
nn.Conv2d(F_l,
F_int,
kernel_size=1,
stride=1,
padding=0,
bias=True),
nn.BatchNorm2d(F_int))
self.psi = nn.Sequential(
nn.Conv2d(F_int, 1, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(1), nn.Sigmoid())
self.relu = nn.ReLU(inplace=True)
def forward(self, g, x):
g1 = self.W_g(g)
x1 = self.W_x(x)
psi = self.relu(g1 + x1)
psi = self.psi(psi)
return x * psi
class AttU_Net(nn.Module):
"""
in_channel: input image channels
num_classes: output class number
channel_list: a channel list for adjust the model size
checkpoint: 是否有checkpoint if False: call normal init
convTranspose: 是否使用反卷积上采样。True: use nn.convTranspose Flase: use nn.Upsample
"""
def __init__(self,
in_channel=3,
num_classes=1,
channel_list=[64, 128, 256, 512, 1024],
checkpoint=False,
convTranspose=True):
super(AttU_Net, self).__init__()
self.Maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.Conv1 = conv_block(ch_in=in_channel, ch_out=channel_list[0])
self.Conv2 = conv_block(ch_in=channel_list[0], ch_out=channel_list[1])
self.Conv3 = conv_block(ch_in=channel_list[1], ch_out=channel_list[2])
self.Conv4 = conv_block(ch_in=channel_list[2], ch_out=channel_list[3])
self.Conv5 = conv_block(ch_in=channel_list[3], ch_out=channel_list[4])
self.Up5 = up_conv(ch_in=channel_list[4], ch_out=channel_list[3], convTranspose=convTranspose)
self.Att5 = Attention_block(F_g=channel_list[3],
F_l=channel_list[3],
F_int=channel_list[2])
self.Up_conv5 = conv_block(ch_in=channel_list[4],
ch_out=channel_list[3])
self.Up4 = up_conv(ch_in=channel_list[3], ch_out=channel_list[2], convTranspose=convTranspose)
self.Att4 = Attention_block(F_g=channel_list[2],
F_l=channel_list[2],
F_int=channel_list[1])
self.Up_conv4 = conv_block(ch_in=channel_list[3],
ch_out=channel_list[2])
self.Up3 = up_conv(ch_in=channel_list[2], ch_out=channel_list[1], convTranspose=convTranspose)
self.Att3 = Attention_block(F_g=channel_list[1],
F_l=channel_list[1],
F_int=64)
self.Up_conv3 = conv_block(ch_in=channel_list[2],
ch_out=channel_list[1])
self.Up2 = up_conv(ch_in=channel_list[1], ch_out=channel_list[0], convTranspose=convTranspose)
self.Att2 = Attention_block(F_g=channel_list[0],
F_l=channel_list[0],
F_int=channel_list[0] // 2)
self.Up_conv2 = conv_block(ch_in=channel_list[1],
ch_out=channel_list[0])
self.Conv_1x1 = nn.Conv2d(channel_list[0],
num_classes,
kernel_size=1,
stride=1,
padding=0)
if not checkpoint:
init_weights(self)
def forward(self, x):
# encoder
x1 = self.Conv1(x)
x2 = self.Maxpool(x1)
x2 = self.Conv2(x2)
x3 = self.Maxpool(x2)
x3 = self.Conv3(x3)
x4 = self.Maxpool(x3)
x4 = self.Conv4(x4)
x5 = self.Maxpool(x4)
x5 = self.Conv5(x5)
# decoder
d5 = self.Up5(x5)
x4 = self.Att5(g=d5, x=x4)
d5 = torch.cat((x4, d5), dim=1)
d5 = self.Up_conv5(d5)
d4 = self.Up4(d5)
x3 = self.Att4(g=d4, x=x3)
d4 = torch.cat((x3, d4), dim=1)
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
x2 = self.Att3(g=d3, x=x2)
d3 = torch.cat((x2, d3), dim=1)
d3 = self.Up_conv3(d3)
d2 = self.Up2(d3)
x1 = self.Att2(g=d2, x=x1)
d2 = torch.cat((x1, d2), dim=1)
d2 = self.Up_conv2(d2)
d1 = self.Conv_1x1(d2)
return d1
数据集
数据集依旧使用Camvid数据集,见Camvid数据集的构建和使用。
# 导入库
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch import optim
from torch.utils.data import Dataset, DataLoader, random_split
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
import os.path as osp
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
torch.manual_seed(17)
# 自定义数据集CamVidDataset
class CamVidDataset(torch.utils.data.Dataset):
"""CamVid Dataset. Read images, apply augmentation and preprocessing transformations.
Args:
images_dir (str): path to images folder
masks_dir (str): path to segmentation masks folder
class_values (list): values of classes to extract from segmentation mask
augmentation (albumentations.Compose): data transfromation pipeline
(e.g. flip, scale, etc.)
preprocessing (albumentations.Compose): data preprocessing
(e.g. noralization, shape manipulation, etc.)
"""
def __init__(self, images_dir, masks_dir):
self.transform = A.Compose([
A.Resize(224, 224),
A.HorizontalFlip(),
A.VerticalFlip(),
A.Normalize(),
ToTensorV2(),
])
self.ids = os.listdir(images_dir)
self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]
self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]
def __getitem__(self, i):
# read data
image = np.array(Image.open(self.images_fps[i]).convert('RGB'))
mask = np.array( Image.open(self.masks_fps[i]).convert('RGB'))
image = self.transform(image=image,mask=mask)
return image['image'], image['mask'][:,:,0]
def __len__(self):
return len(self.ids)
# 设置数据集路径
DATA_DIR = r'dataset\camvid' # 根据自己的路径来设置
x_train_dir = os.path.join(DATA_DIR, 'train_images')
y_train_dir = os.path.join(DATA_DIR, 'train_labels')
x_valid_dir = os.path.join(DATA_DIR, 'valid_images')
y_valid_dir = os.path.join(DATA_DIR, 'valid_labels')
train_dataset = CamVidDataset(
x_train_dir,
y_train_dir,
)
val_dataset = CamVidDataset(
x_valid_dir,
y_valid_dir,
)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True,drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=True,drop_last=True)
模型训练
model = AttentionUnet(num_classes=33).cuda()
#model.load_state_dict(torch.load(r"checkpoints/Unet_100.pth"),strict=False)
from d2l import torch as d2l
from tqdm import tqdm
import pandas as pd
#损失函数选用多分类交叉熵损失函数
lossf = nn.CrossEntropyLoss(ignore_index=255)
#选用adam优化器来训练
optimizer = optim.SGD(model.parameters(),lr=0.1)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1, last_epoch=-1)
#训练50轮
epochs_num = 50
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,scheduler,
devices=d2l.try_all_gpus()):
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
loss_list = []
train_acc_list = []
test_acc_list = []
epochs_list = []
time_list = []
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples,
# no. of predictions
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = d2l.train_batch_ch13(
net, features, labels.long(), loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
scheduler.step()
# print(f'loss {metric[0] / metric[2]:.3f}, train acc '
# f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
# print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
# f'{str(devices)}')
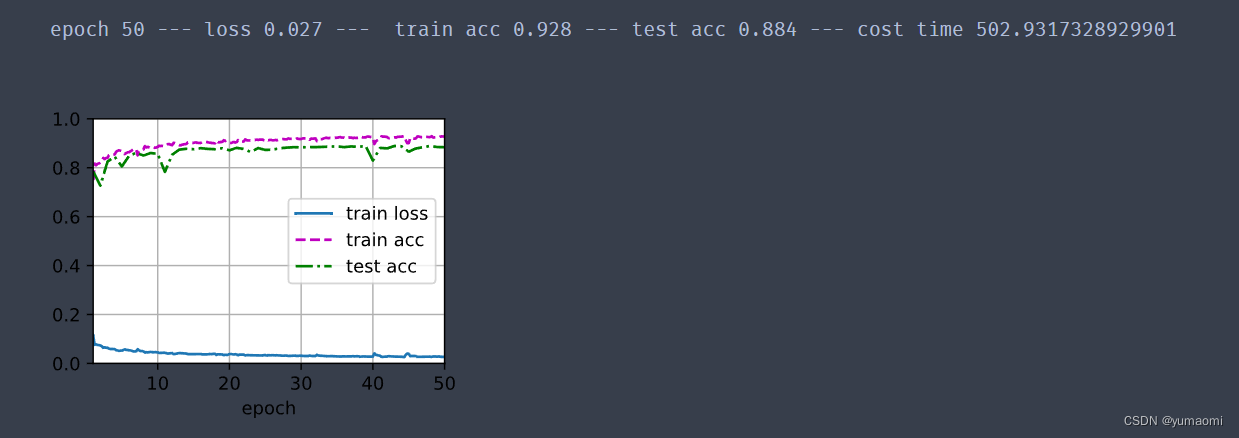
print(f"epoch {epoch+1} --- loss {metric[0] / metric[2]:.3f} --- train acc {metric[1] / metric[3]:.3f} --- test acc {test_acc:.3f} --- cost time {timer.sum()}")
#---------保存训练数据---------------
df = pd.DataFrame()
loss_list.append(metric[0] / metric[2])
train_acc_list.append(metric[1] / metric[3])
test_acc_list.append(test_acc)
epochs_list.append(epoch+1)
time_list.append(timer.sum())
df['epoch'] = epochs_list
df['loss'] = loss_list
df['train_acc'] = train_acc_list
df['test_acc'] = test_acc_list
df['time'] = time_list
df.to_excel("savefile/AttentionUnet_camvid1.xlsx")
#----------------保存模型-------------------
if np.mod(epoch+1, 5) == 0:
torch.save(model.state_dict(), f'checkpoints/AttentionUnet_{epoch+1}.pth')
开始训练
train_ch13(model, train_loader, val_loader, lossf, optimizer, epochs_num,scheduler)
训练结果
版权归原作者 yumaomi 所有, 如有侵权,请联系我们删除。