
一 简介
Ollama 官网:https://github.com/ollama/ollama
Ollama是一个开源的人工智能(AI)和机器学习(ML)工具平台,特别设计用于简化大型语言模型(LLM)的部署和使用流程。用户可以通过Ollama在本地环境中便捷地运行各种大型语言模型,比如Llama 2和其他开源模型。该工具的主要优势和特点包括:
- 易用性:提供了类似于OpenAI API的简单接口,用户可以快速上手并调用模型进行内容生成,同时也包含一个类似ChatGPT的聊天界面,可以直接与模型进行交互。
- 跨平台支持:支持macOS、Linux 和 Windows 操作系统,让用户能够在不同平台上本地运行大型语言模型。
- 模型管理和部署:Ollama将模型权重、配置和数据整合在一个名为Modelfile的包中,通过优化的Docker容器化技术,用户只需一条命令就能在本地部署和管理LLM。支持热切换模型,灵活多变。
- 高效性:它显著降低了使用大型语言模型所需的硬件配置和技术门槛,使更多的开发者和研究者能够迅速获得和使用高级AI技术。
- 灵活性:除了支持预训练模型外,Ollama还允许用户自定义和创建自己的模型。 总结来说,Ollama是一个旨在促进AI民主化的工具,通过简化部署和使用流程,让更多人能够在个人计算机上运行复杂的大型语言模型,从而推进AI技术的广泛普及和创新应用。
二 安装
2.1 安装
官方文档:https://github.com/ollama/ollama/blob/main/docs/linux.md
curl-fsSL https://ollama.com/install.sh |sh[root@localhost ~]# curl -fsSL https://ollama.com/install.sh | sh>>> Downloading ollama...
######################################################################## 100.0%>>> Installing ollama to /usr/local/bin...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
WARNING: No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode
[root@localhost ~]# ollama help
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --helphelpfor ollama
-v, --version Show version information
Use "ollama [command] --help"formore information about a command.
在Ollama安装完成后, 一般会自动启动 Ollama 服务,而且会自动设置为开机自启动。安装完成后,可以使用如下命令查看是否Ollama是否正常启动。如下例子中显示“Active: active (running)”表示Ollama已经正常启动。
[root@localhost ~]# systemctl status ollama
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; vendor preset: disabled)
Active: active (running) since 日 2024-04-07 11:26:30 CST;1 day 21h ago
Main PID: 4293(ollama)
CGroup: /system.slice/ollama.service
└─4293 /usr/local/bin/ollama serve
4月 07 11:26:30 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:30.908+08:00 level=INFO source=payload_common.go:113 msg="Extracting dynamic libraries to /tmp/ollama3707241284/runners ..."4月 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.058+08:00 level=INFO source=payload_common.go:140 msg="Dynamic LLM libraries [cpu_avx2 rocm_v60000 cpu_avx cpu cuda_v11]"4月 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.059+08:00 level=INFO source=gpu.go:115 msg="Detecting GPU type"4月 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.059+08:00 level=INFO source=gpu.go:265 msg="Searching for GPU management library libcudart.so*"4月 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.062+08:00 level=INFO source=gpu.go:311 msg="Discovered GPU libraries: [/tmp/ollama3707241284/runners/cuda_v11/libcudart.so.11.0]"4月 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.063+08:00 level=INFO source=gpu.go:340 msg="Unable to load cudart CUDA management library /tmp/ollama3707241284/runners/cuda_v11/libcudar...it failure: 35"4月 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.064+08:00 level=INFO source=gpu.go:265 msg="Searching for GPU management library libnvidia-ml.so"4月 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.066+08:00 level=INFO source=gpu.go:311 msg="Discovered GPU libraries: []"4月 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.066+08:00 level=INFO source=cpu_common.go:15 msg="CPU has AVX"4月 07 11:26:36 localhost.localdomain ollama[4293]: time=2024-04-07T11:26:36.066+08:00 level=INFO source=routes.go:1141 msg="no GPU detected"
Hint: Some lines were ellipsized, use -l to show in full.
在 Linux 上,如果 Ollama 未启动,可以用如下命令启动 Ollama 服务:ollama serve,或者 sudo systemctl start ollama。
通过分析Linux的安装脚本install.sh,就会看到其中已经将ollama serve配置为一个系统服务,所以可以使用systemctl来 start / stop ollama 进程。
[Unit]Description=Ollama Service
After=network-online.target
[Service]ExecStart=$BINDIR/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3Environment="PATH=$PATH"
2.2 启动
sudo systemctl start ollama
2.3 更新
Update ollama by running the install script again:
curl-fsSL https://ollama.com/install.sh |sh
Or by downloading the ollama binary:
sudocurl-L https://ollama.com/download/ollama-linux-amd64 -o /usr/bin/ollama
sudochmod +x /usr/bin/ollama
2.4 查看日志
journalctl -u ollama
三 开启远程访问
Ollama默认绑定127.0.0.1端口11434。通过
OLLAMA_HOST
环境变量更改绑定地址。
3.1 在linux 上设置环境变量
如果Ollama作为systemd服务运行,应该使用
OLLAMA_HOST
设置环境变量:
- 通过调用
systemctl edit ollama.service编辑systemd服务。这将打开一个编辑器。或者创建/etc/systemd/system/ollama.service.d/environment.conf配置文件。 - 对于每个环境变量,在
[Service]部分下添加一行Environment:复制
[Service]Environment="OLLAMA_HOST=0.0.0.0"
- 保存并退出。
- 重载
systemd并重启Ollama:复制
systemctl daemon-reload
systemctl restart ollama
3.2 在 Windows 上设置环境变量
在Windows上,Ollama继承了您的用户和系统环境变量。
- 首先通过任务栏点击Ollama退出程序
- 从控制面板编辑系统环境变量
- 为您的用户账户编辑或新建变量,比如
OLLAMA_HOST、OLLAMA_MODELS等。 - 点击OK/应用保存
- 重启 ollama app.exe 服务
如下图配置所示: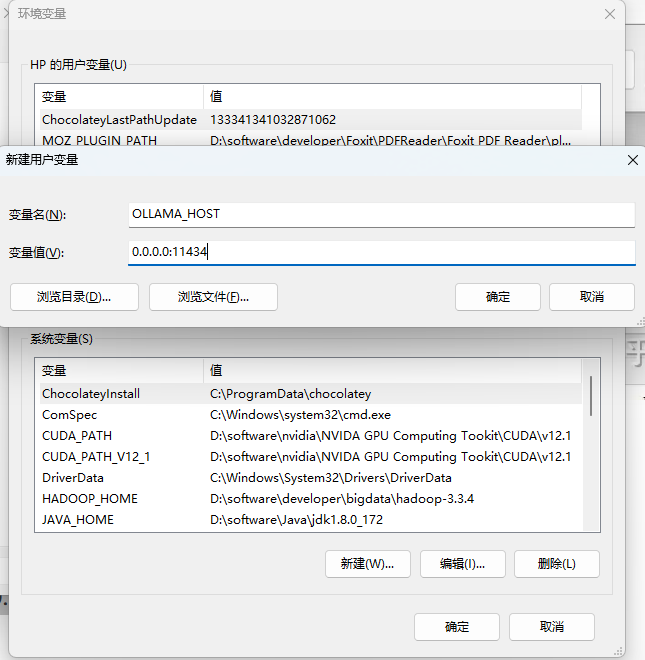
四 部署模型
4.1 模型库
模型仓库地址: https://ollama.com/library
Ollama 是一个基于 Go 语言开发的简单易用的本地大模型运行框架。可以将其类比为 docker , ollama 安装之后,其同时还是一个命令,与模型交互就是通过命令来进行的。
- ollama list:显示模型列表。
- ollama show:显示模型的信息
- ollama pull:拉取模型
- ollama push:推送模型
- ollama cp:拷贝一个模型
- ollama rm:删除一个模型
- ollama run:运行一个模型
同时,官方还提供了类似 GitHub,DockerHub 一般的,可类比理解为 ModelHub,用于存放大模型的仓库(有 llama 2,mistral,qwen 等模型,同时你也可以自定义模型上传到仓库里来给别人使用)。
Here are some example models that can be downloaded:
ModelParametersSizeDownloadLlama 27B3.8GBollama run llama2Mistral7B4.1GBollama run mistralDolphin Phi2.7B1.6GBollama run dolphin-phiPhi-22.7B1.7GBollama run phiNeural Chat7B4.1GBollama run neural-chatStarling7B4.1GBollama run starling-lmCode Llama7B3.8GBollama run codellamaLlama 2 Uncensored7B3.8GBollama run llama2-uncensoredLlama 2 13B13B7.3GBollama run llama2:13bLlama 2 70B70B39GBollama run llama2:70bOrca Mini3B1.9GBollama run orca-miniVicuna7B3.8GBollama run vicunaLLaVA7B4.5GBollama run llavaGemma2B1.4GBollama run gemma:2bGemma7B4.8GBollama run gemma:7b
官方建议:应该至少有 8 GB 可用 RAM 来运行 7B 型号,16 GB 来运行 13B 型号,32 GB 来运行 33 B 型号
你可以去模型库官网搜索你想要运行的模型
4.2 运行模型
在这里我选择下载阿里开源的 Qwen1.5 模型来做演示。模型地址为:https://github.com/QwenLM/Qwen1.5 。
通过模型仓库也可以搜索到,如下图: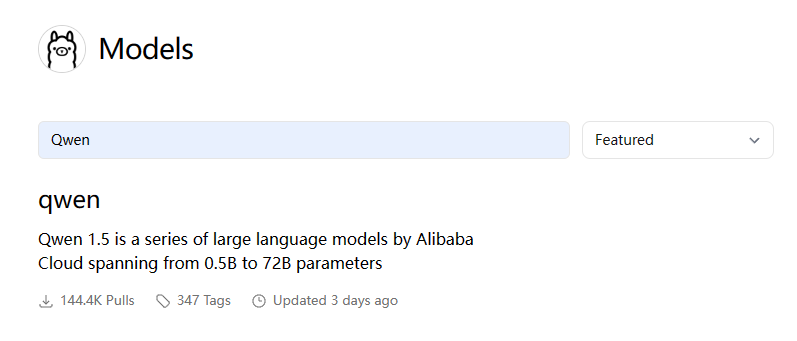
因我的电脑有 32G,所以选择了 14b 的模型来调试。
先查看本地是否存在模型:
[root@localhost ~]# ollama list
NAME ID SIZE MODIFIED
下载并运行模型
[root@localhost ~]# ollama run qwen:14b>>> 你好
你好!很高兴为你服务。有什么可以帮到你的吗?
>>> Send a message (/? forhelp)
等待下载完成后,你就可以直接在终端中与大模型进行对话了。如此简单你就拥有了一个属于你自己私人的chatAI。
如果本地没有该模型,则会先下载模型再运行。首次运行启动可能略慢。
再次查看本地模型库:
[root@localhost ~]# ollama list
NAME ID SIZE MODIFIED
qwen:14b 80362ced6553 8.2 GB 6 minutes ago
4.3 指定 GPU
本地有多张 GPU,如何用指定的 GPU 来运行 Ollama?
在Linux上创建如下配置文件,并配置环境变量
CUDA_VISIBLE_DEVICES
来指定运行 Ollama 的 GPU,再重启 Ollama 服务即可。
$ cat /etc/systemd/system/ollama.service.d/environment.conf
[Service]
Environment=CUDA_VISIBLE_DEVICES=1,2
4.4 修改存储路径
默认情况下,不同操作系统大模型存储的路径如下:
- macOS: ~/.ollama/models
- Linux: /usr/share/ollama/.ollama/models
- Windows: C:\Users.ollama\models
Linux平台安装Ollama时,默认安装时会创建用户ollama,再将模型文件存储到该用户的目录/usr/share/ollama/.ollama/models。但由于大模型文件往往特别大,有时需要将大模型文件存储到专门的数据盘,此时就需要修改大模型文件的存储路径。
官方提供的方法是设置环境变量“OLLAMA_MODELS”。
Linux 下创建如下配置文件,并配置环境变量
OLLAMA_MODELS
来指定存储路径,再重启 Ollama 服务。
$ cat /etc/systemd/system/ollama.service.d/environment.conf
[Service]
Environment=OLLAMA_MODELS=<path>/OLLAMA_MODELS
五 REST API
如果不希望直接在终端中与大型语言模型交互,可以使用命令 ollama serve 启动本地服务器。一旦这个命令成功运行,你就可以通过REST API与本地语言模型进行交互。
Ollama has a REST API for running and managing models.
5.1 Generate a response
curl http://localhost:11434/api/generate -d '{
"model": "qwen:14b",
"prompt":"你好"
}'
输出如下:
[root@localhost ~]# curl http://localhost:11434/api/generate -d '{>"model":"qwen:14b",
>"prompt":"你好">}'
{"model":"qwen:14b","created_at":"2024-04-09T06:02:32.544936379Z","response":"你好","done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:02:33.102577518Z","response":"!","done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:02:33.640148118Z","response":"很高兴","done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:02:34.175936317Z","response":"为你","done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:02:34.767553169Z","response":"服务","done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:02:35.413131616Z","response":"。","done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:02:35.910356234Z","response":"有什么","done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:02:36.52352589Z","response":"可以帮助","done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:02:37.080783596Z","response":"你的","done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:02:37.725254803Z","response":"吗","done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:02:38.229425561Z","response":"?","done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:02:39.355910894Z","response":"\n","done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:02:40.020951528Z","response":"","done":true,
"context":[151644,872,198,108386,151645,198,151644,77091,198,108386,6313,112169,106184,47874,1773,104139,111728,103929,101037,94432],
"total_duration":21400599076,"load_duration":10728843813,"prompt_eval_count":9,"prompt_eval_duration":3192013000,"eval_count":14,"eval_duration":7474825000}
5.2 Chat with a model
curl http://localhost:11434/api/chat -d '{
"model": "qwen:14b",
"messages": [
{ "role": "user", "content": "你好" }
]
}'
输出如下:
[root@localhost ~]# curl http://localhost:11434/api/chat -d '{>"model":"qwen:14b",
>"messages":[>{"role":"user", "content":"你好"}>]>}'
{"model":"qwen:14b","created_at":"2024-04-09T06:05:06.900324407Z","message":{"role":"assistant","content":"你好"},"done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:05:07.470563314Z","message":{"role":"assistant","content":"!"},"done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:05:08.06014135Z","message":{"role":"assistant","content":"很高兴"},"done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:05:08.659460583Z","message":{"role":"assistant","content":"为你"},"done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:05:09.198527345Z","message":{"role":"assistant","content":"提供"},"done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:05:09.86445663Z","message":{"role":"assistant","content":"帮助"},"done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:05:10.373454235Z","message":{"role":"assistant","content":"。"},"done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:05:11.001192023Z","message":{"role":"assistant","content":"有什么"},"done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:05:11.5422106Z","message":{"role":"assistant","content":"可以"},"done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:05:12.135530288Z","message":{"role":"assistant","content":"聊"},"done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:05:12.737720245Z","message":{"role":"assistant","content":"的"},"done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:05:13.236999733Z","message":{"role":"assistant","content":"吗"},"done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:05:13.908050157Z","message":{"role":"assistant","content":"?"},"done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:05:15.073687823Z","message":{"role":"assistant","content":"\n"},"done":false}{"model":"qwen:14b","created_at":"2024-04-09T06:05:15.675686469Z","message":{"role":"assistant","content":""},"done":true,
"total_duration":12067791340,"load_duration":4094567,"prompt_eval_duration":3253826000,"eval_count":16,"eval_duration":8773552000}
See the API Documentation for all endpoints.
六 Web UI
6.1 UI 工具
Web 和 Desktop UI 有如下工具:
这里推荐上面的 Web UI: Open WebUI (以前的Ollama WebUI)。
6.2 Open WebUI
OpenWebUI 是一个可扩展、功能丰富且用户友好的自托管 WebUI,它支持完全离线操作,并兼容 Ollama 和 OpenAI 的 API 。这为用户提供了一个可视化的界面,使得与大型语言模型的交互更加直观和便捷。
6.2.1 安装
官方文档:How To Install
docker run -d--network=host -v open-webui:/app/backend/data -eOLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
然后访问 http://localhost:8080 :
6.2.2 使用
首次登录,输入邮箱密码注册,即可登录。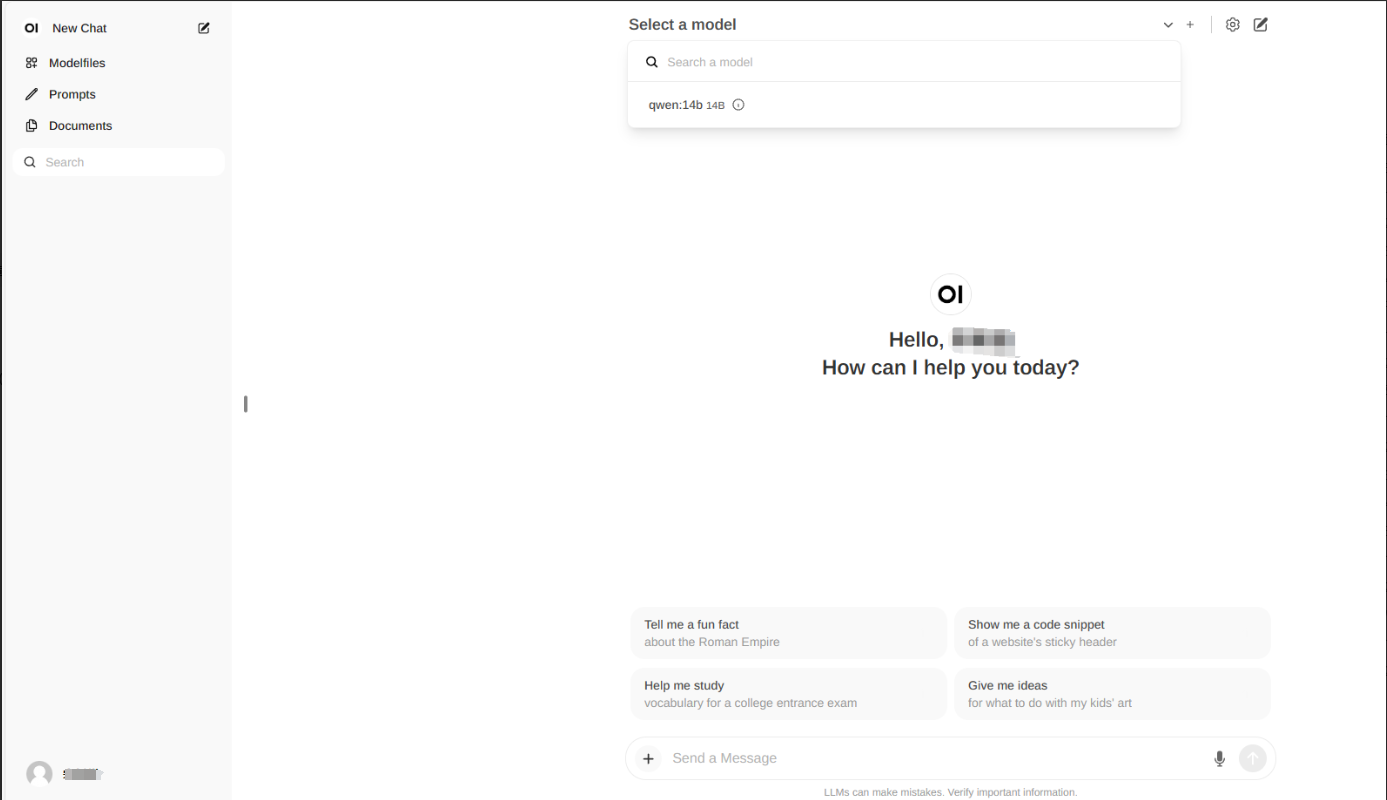
选择模型
qwen:14b
,即可在对话框中输入文字,开始对话。界面是不是很熟悉,很像chatGPT,用着顺手多了。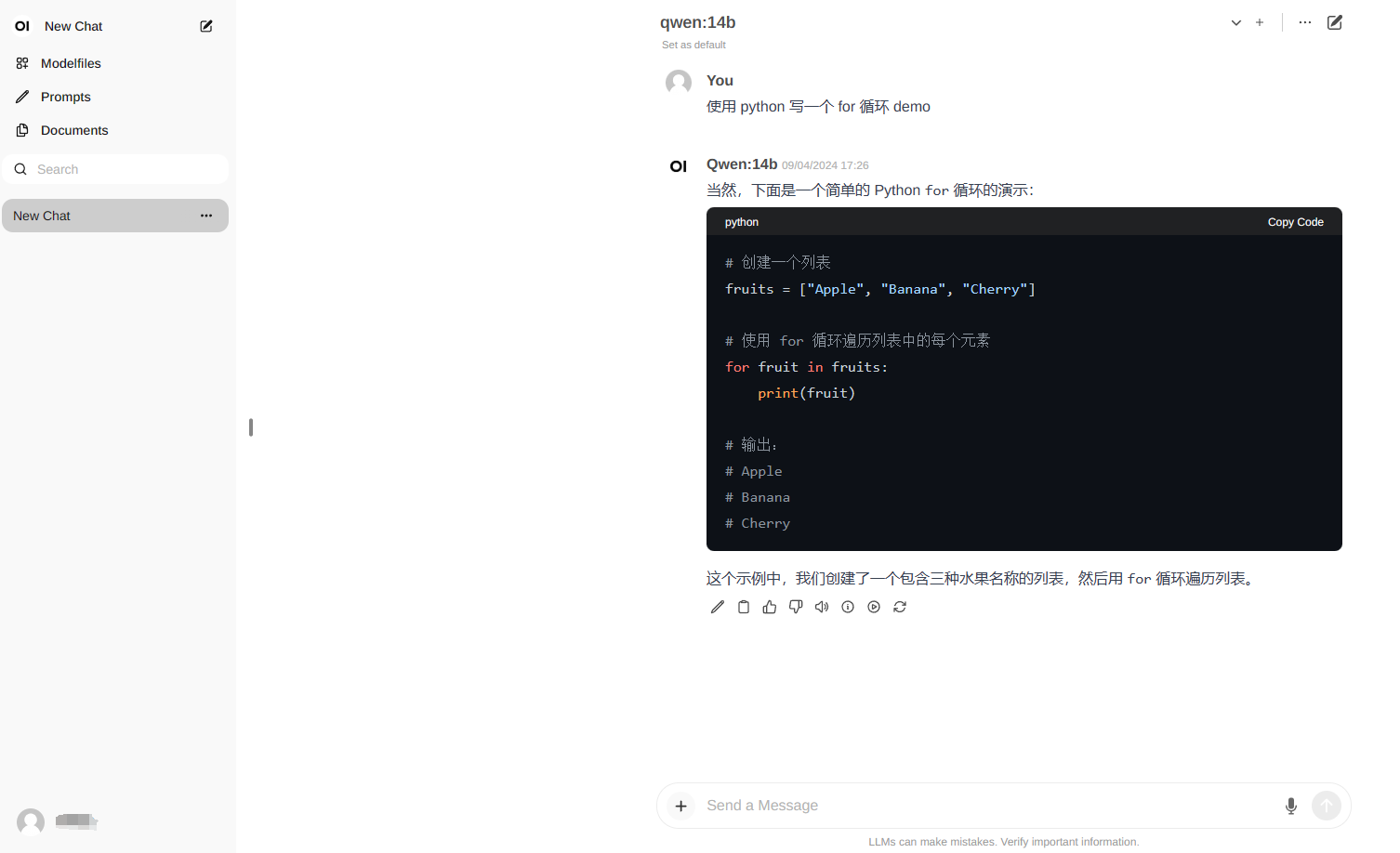
Open WebUI还有很多其它功能,比如它本身自带RAG。可以在对话框中输入“#”,然后跟上网址,即可访问网页的实施信息,并进行内容生成。
还可以上传文档,基于文本进行更深层次的知识交互。如果你对知识库的要求不高,做到这一点以后,基本能满足大多数个人的需求了。

版权归原作者 大数据AI 所有, 如有侵权,请联系我们删除。