
本文以YOLOv5-6.1版本为例
一、Add
1.在common.py后加入如下代码
# 结合BiFPN 设置可学习参数 学习不同分支的权重
# 两个分支add操作
class BiFPN_Add2(nn.Module):
def __init__(self, c1, c2):
super(BiFPN_Add2, self).__init__()
# 设置可学习参数 nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter
# 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter
# 从而在参数优化的时候可以自动一起优化
self.w = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
self.conv = nn.Conv2d(c1, c2, kernel_size=1, stride=1, padding=0)
self.silu = nn.SiLU()
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon)
return self.conv(self.silu(weight[0] * x[0] + weight[1] * x[1]))
# 三个分支add操作
class BiFPN_Add3(nn.Module):
def __init__(self, c1, c2):
super(BiFPN_Add3, self).__init__()
self.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
self.conv = nn.Conv2d(c1, c2, kernel_size=1, stride=1, padding=0)
self.silu = nn.SiLU()
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
# Fast normalized fusion
return self.conv(self.silu(weight[0] * x[0] + weight[1] * x[1] + weight[2] * x[2]))
2.yolov5s.yaml进行修改
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 BiFPN head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, BiFPN_Add2, [256, 256]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, BiFPN_Add2, [128, 128]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [512, 3, 2]], # 为了BiFPN正确add,调整channel数
[[-1, 13, 6], 1, BiFPN_Add3, [256, 256]], # cat P4 <--- BiFPN change 注意v5s通道数是默认参数的一半
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, BiFPN_Add2, [256, 256]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
3.修改yolo.py,在
parse_model
函数中找到
elif m is Concat:
语句,在其后面加上
BiFPN_Add
相关语句:
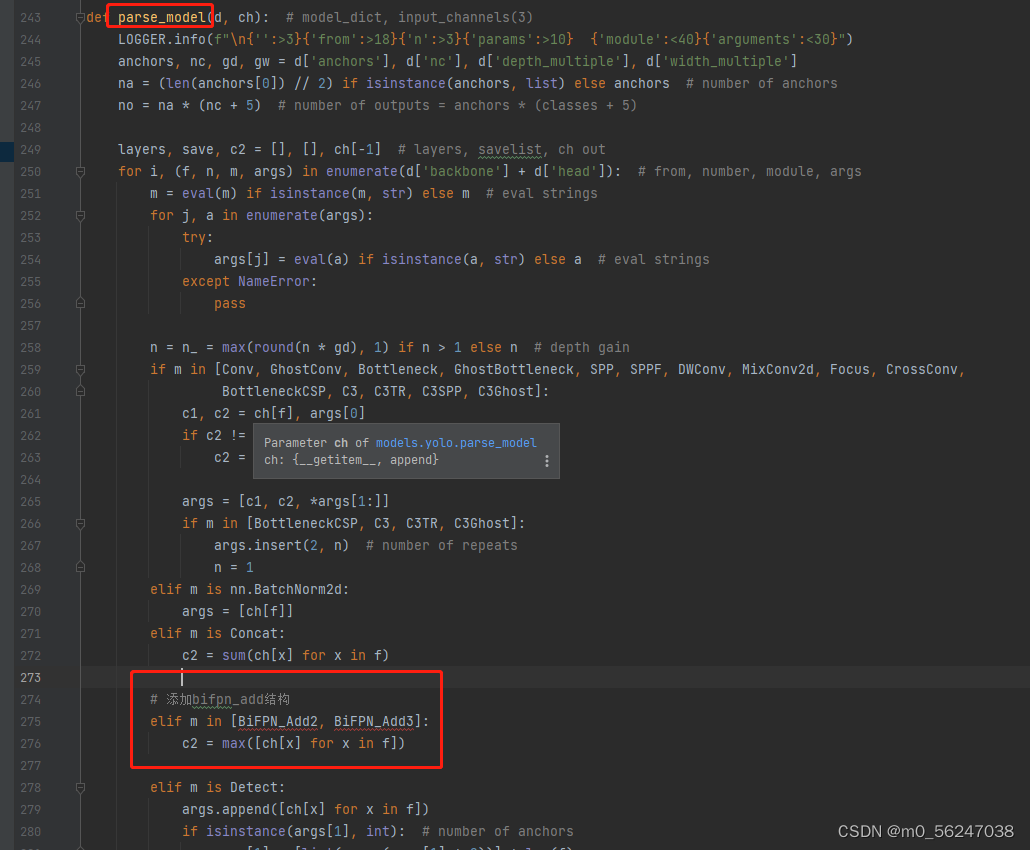
# 添加bifpn_add结构
elif m in [BiFPN_Add2, BiFPN_Add3]:
c2 = max([ch[x] for x in f])
4.修改train.py,向优化器中添加BiFPN的权重参数
将
BiFPN_Add2
和
BiFPN_Add3
函数中定义的
w
参数,加入g1
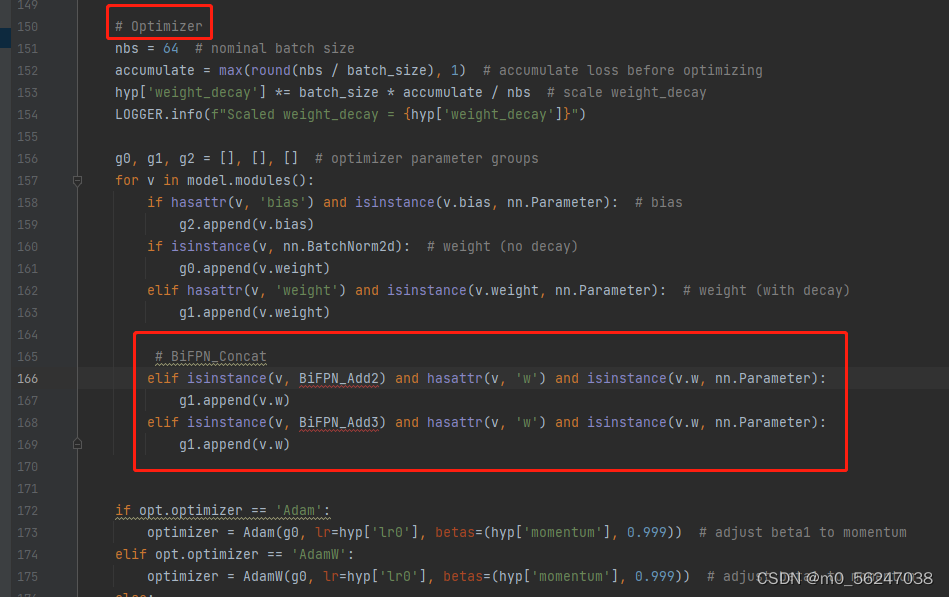
# BiFPN_Concat
elif isinstance(v, BiFPN_Add2) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g1.append(v.w)
elif isinstance(v, BiFPN_Add3) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g1.append(v.w)
然后导入一下这两个包
一、Concat
1.在common.py后加入如下代码
# 结合BiFPN 设置可学习参数 学习不同分支的权重
# 两个分支concat操作
class BiFPN_Concat2(nn.Module):
def __init__(self, dimension=1):
super(BiFPN_Concat2, self).__init__()
self.d = dimension
self.w = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
# Fast normalized fusion
x = [weight[0] * x[0], weight[1] * x[1]]
return torch.cat(x, self.d)
# 三个分支concat操作
class BiFPN_Concat3(nn.Module):
def __init__(self, dimension=1):
super(BiFPN_Concat3, self).__init__()
self.d = dimension
# 设置可学习参数 nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter
# 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter
# 从而在参数优化的时候可以自动一起优化
self.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
# Fast normalized fusion
x = [weight[0] * x[0], weight[1] * x[1], weight[2] * x[2]]
return torch.cat(x, self.d)
2.yolov5s.yaml进行修改
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 BiFPN head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, BiFPN_Concat2, [1]], # cat backbone P4 <--- BiFPN change
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, BiFPN_Concat2, [1]], # cat backbone P3 <--- BiFPN change
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14, 6], 1, BiFPN_Concat3, [1]], # cat P4 <--- BiFPN change
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, BiFPN_Concat2, [1]], # cat head P5 <--- BiFPN change
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
3.修改yolo.py,在
parse_model
函数中找到
elif m is Concat:
语句,在其后面加上
BiFPN_
Concat相关语句:
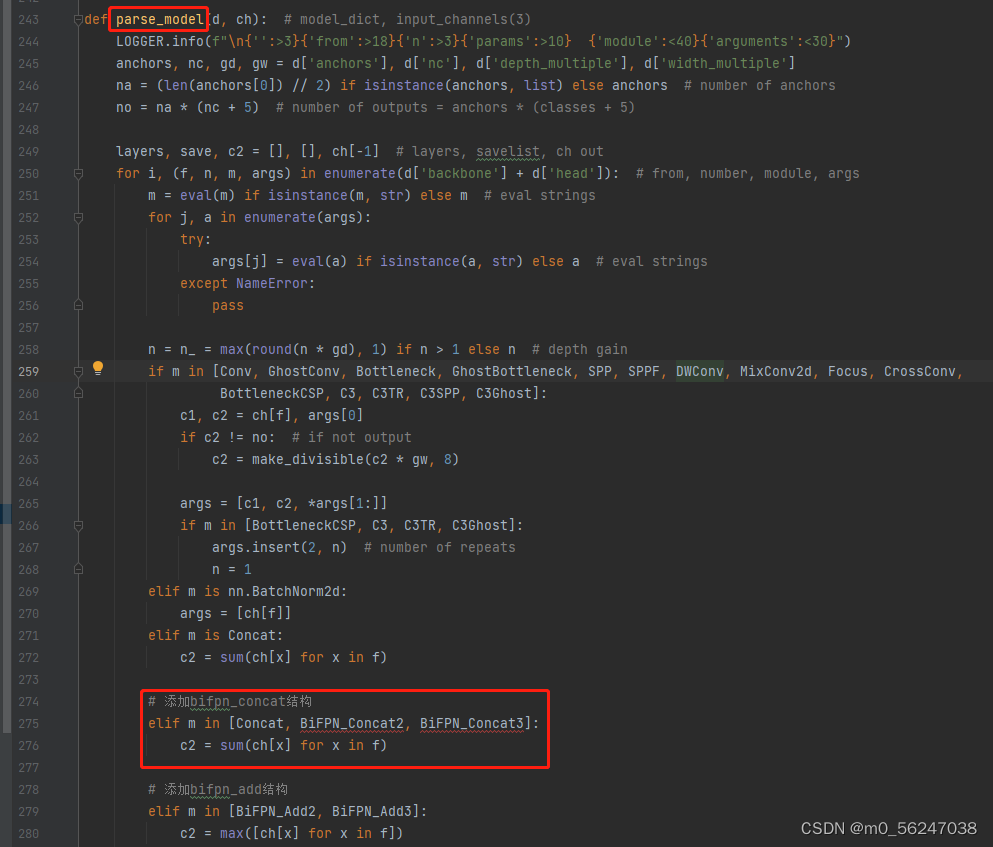
# 添加bifpn_concat结构
elif m in [Concat, BiFPN_Concat2, BiFPN_Concat3]:
c2 = sum(ch[x] for x in f)
4.修改train.py,向优化器中添加BiFPN的权重参数
添加复方式同上(Add)
# BiFPN_Concat
elif isinstance(v, BiFPN_Concat2) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g1.append(v.w)
elif isinstance(v, BiFPN_Concat3) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g1.append(v.w)
至此,大功告成~~~
reference:【YOLOv5-6.x】设置可学习权重结合BiFPN(Add操作)_嗜睡的篠龙的博客-CSDN博客
【YOLOv5-6.x】设置可学习权重结合BiFPN(Concat操作)_嗜睡的篠龙的博客-CSDN博客_bifpn代码
本文转载自: https://blog.csdn.net/m0_56247038/article/details/124891449
版权归原作者 有温度的AI 所有, 如有侵权,请联系我们删除。
版权归原作者 有温度的AI 所有, 如有侵权,请联系我们删除。