
在前面的文章中已经详细介绍了在本机上安装YOLOv5的教程,安装YOLOv5可参考前面的文章YOLOv5训练自己的数据集(超详细)https://blog.csdn.net/qq_40716944/article/details/118188085
1 SENet
论文名称:Squeeze-and-Excitation Networks
论文链接:https://arxiv.org/pdf/1709.01507.pdf
论文代码: GitHub - hujie-frank/SENet: Squeeze-and-Excitation Networks
1.1 SENet原理
对于卷积操作,很大一部分工作是提高感受野,即空间上融合更多特征融合,或者是提取多尺度空间信息,如Inception网络的多分支结构。对于channel维度的特征融合,卷积操作基本上默认对输入特征图的所有channel进行融合。而MobileNet网络中的组卷积(Group Convolution)和深度可分离卷积(Depthwise Separable Convolution)对channel进行分组也主要是为了使模型更加轻量级,减少计算量。而SENet网络的创新点在于关注channel之间的关系,希望模型可以自动学习到不同channel特征的重要程度。为此,SENet提出了Squeeze-and-Excitation (SE)模块,如图1所示。
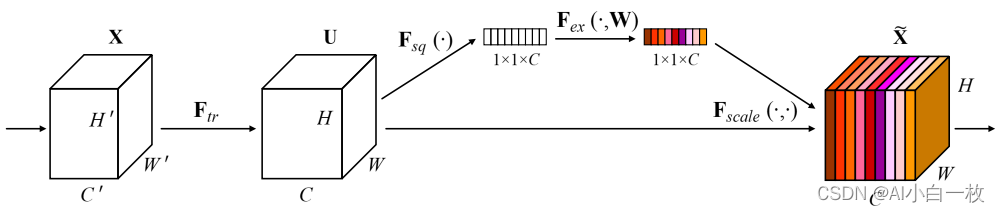
图1 SEBlock结构图
SE模块首先对卷积得到的特征图进行Squeeze操作,得到channel级的全局特征,然后对全局特征进行Excitation操作,学习各个channel间的关系,也得到不同channel的权重,最后乘以原来的特征图得到最终特征。本质上,SE模块是在channel维度上做attention或者gating操作,这种注意力机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。另外一点是SE模块是通用的,这意味着其可以嵌入到现有的网络架构中。
为了更好的对SENet的核心原理进行放分析,可以将SENet分成4个步骤进行理解,如图2所示。
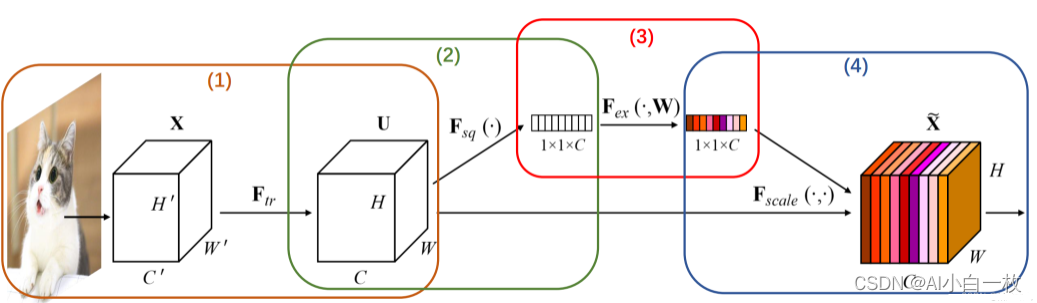
图2 SEBlock模块分析图
- 从单张图像开始,提取图像特征,当前特征层U的特征图维度为[C,H,W]。
- 对特征图的[ H , W ]维度进行平均池化或最大池化,池化过后的特征图大小从[ C , H , W ] ->[ C , 1 , 1 ]。[ C , 1 , 1 ] 可理解为对于每一个通道C,都有一个数字和其一一对应。图3对应了步骤(2)的具体操作。
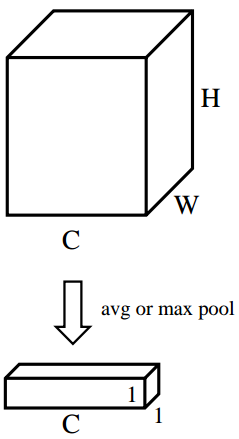
图3 平均池化(最大池化)操作,得到每个通道的权重,得到每个通道的权重
- 对[ C , 1 , 1 ]的特征可以理解为,从每个通道本身提取出来的权重,权重表示了每个通道对特征提取的影响力,全局池化后的向量通过MLP网络后,其意义为得到了每个通道的权重。图4对应了步骤(3)的具体操作。

图4 通道权重生成
- 上述步骤,得到了每个通道C的权重[ C , 1 , 1 ],将权重作用于特征图U[ C , H , W ],即每个通道各自乘以各自的权重。可以理解为,当权重大时,该通道特征图的数值相应的增大,对最终输出的影响也会变大;当权重小时,该通道特征图的数值就会更小,对最终输出的影响也会变小。图5对应了步骤(4)的具体操作。
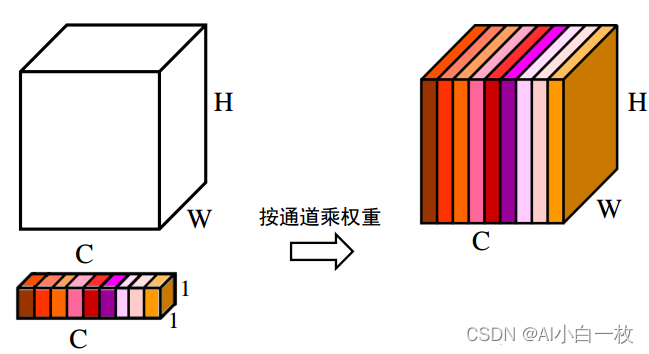
图5 通道注意力——各通道乘以各自不同权重
1.2 SENet代码(Pytorch)
class SEAttention(nn.Module):
def __init__(self, channel=512, reduction=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
1.3 YOLOv5中加入SE模块
1.3.1 common.py配置
在yolov5-6.1/models/common.py文件中增加以下模块,直接复制即可。
class SEAttention(nn.Module):
def __init__(self, channel=512, reduction=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
1.3.2 yolo.py配置
然后找到yolov5-6.1/models//yolo.py文件下里的parse_model函数,将类名加入进去,如下所示。

1.3.3 创建添加RepVGG模块的YOLOv5的yaml配置文件
完成上述两步操作之后,就可以在原有的YOLOv5的yaml配置文件的基础上进行修改,在适当位置添加RepVGG模块或者利用RepVGG模块替换原始yaml配置文件中的一些模块,这里为了能够快速的训练模型,选择YOLOv5s模型进行修改,修改后的yolov5s_se.yaml文件内容如下所示。
# YOLOv5 🚀 by YOLOAir, GPL-3.0 license
# Parameters
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, SEAttention, [256]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, SEAttention, [512]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, SEAttention, [1024]],
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
2 CBAM
论文名称:CBAM: Convolutional Block Attention Module
论文链接:https://arxiv.org/pdf/1807.06521.pdf
论文代码: GitHub - luuuyi/CBAM.PyTorch: Non-official implement of Paper:CBAM: Convolutional Block Attention Module
2.1 CBAM原理
Convolutional Block Attention Module (CBAM) 表示卷积模块的注意力机制模块,是一种结合了空间(spatial)和通道(channel)的注意力机制模块。相比于senet只关注通道(channel)的注意力机制可以取得更好的效果。
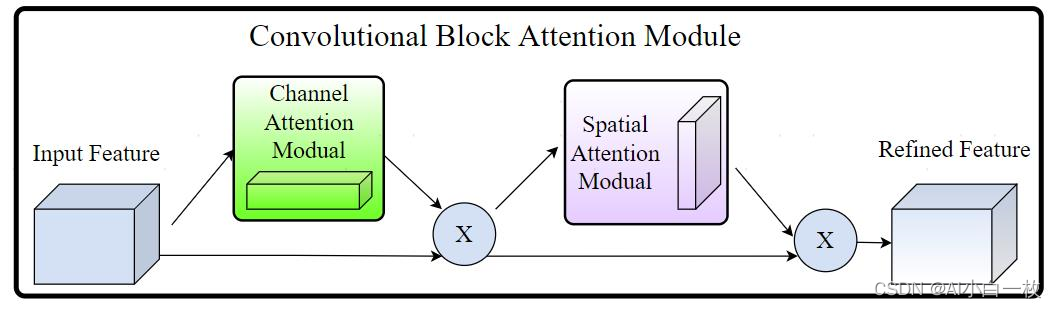
图6 CBAM模块的结构图
上图给出了添加CBAM模块之后的整体结构。可以看到的是,卷积层输出的结果,会先通过一个通道注意力模块,得到加权结果之后,会再经过一个空间注意力模块,最终进行加权得到结果。
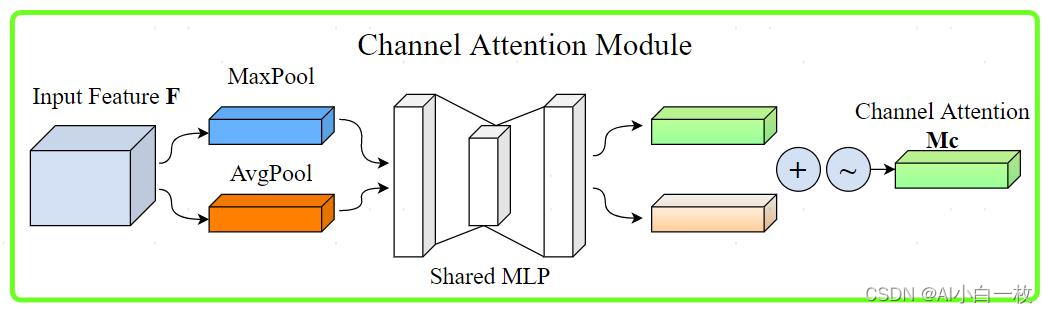
图8 通道注意力模块图
通道注意力模块如图8所示。将输入的特征图,分别经过基于width和height的global max pooling 和global average pooling,然后分别经过MLP。将MLP输出的特征进行基于element-wise的加和操作,再经过sigmoid激活操作,生成最终的channel attention featuremap。将该channel attention featuremap和input featuremap做elementwise乘法操作,生成Spatial attention模块需要的输入特征。以上是通道注意力机制的步骤。
换一个角度考虑,通道注意力机制(Channel Attention Module)是将特征图在空间维度上进行压缩,得到一个一维矢量后再进行操作。在空间维度上进行压缩时,不仅考虑到了平均值池化(Average Pooling)还考虑了最大值池化(Max Pooling)。平均池化和最大池化可用来聚合特征映射的空间信息,送到一个共享网络,压缩输入特征图的空间维数,逐元素求和合并,以产生通道注意力图。单就一张图来说,通道注意力,关注的是这张图上哪些内容是有重要作用的。平均值池化对特征图上的每一个像素点都有反馈,而最大值池化在进行梯度反向传播计算时,只有特征图中响应最大的地方有梯度的反馈。通道注意力机制可以表达为:

空间注意力模块如图9所示。将Channel attention模块输出的特征图作为本模块的输入特征图。首先做一个基于channel的global max pooling 和global average pooling,然后将这2个结果基于channel 做concat操作。然后经过一个卷积操作,降维为1个channel。再经过sigmoid生成spatial attention feature。最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。
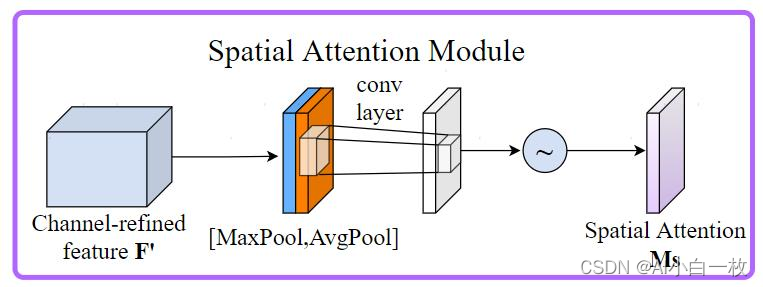
图9 空间注意力模块图
同样,空间注意力机制(Spatial Attention Module)是对通道进行压缩,在通道维度分别进行了平均值池化和最大值池化。MaxPool的操作就是在通道上提取最大值,提取的次数是高乘以宽;AvgPool的操作就是在通道上提取平均值,提取的次数也是是高乘以宽;接着将前面所提取到的特征图(通道数都为1)合并得到一个2通道的特征图。
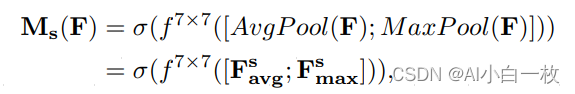
2.2 CBAM代码(Pytorch)
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
class CBAM(nn.Module):
def __init__(self, c1, c2):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttention(c1)
self.spatial_attention = SpatialAttention()
def forward(self, x):
out = self.channel_attention(x) * x
out = self.spatial_attention(out) * out
return out
2.3 YOLOv5中加入CBAM模块
2.3.1 common.py配置
在yolov5-6.1/models/common.py文件中增加以下模块,直接复制即可。
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
class CBAM(nn.Module):
def __init__(self, c1, c2):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttention(c1)
self.spatial_attention = SpatialAttention()
def forward(self, x):
out = self.channel_attention(x) * x
out = self.spatial_attention(out) * out
return out
2.3.2 yolo.py配置
然后找到yolov5-6.1/models//yolo.py文件下里的parse_model函数,将类名加入进去,如下所示。
2.3.3 创建添加CBAM模块的YOLOv5的yaml配置文件
完成上述两步操作之后,就可以在原有的YOLOv5的yaml配置文件的基础上进行修改,在适当位置添加RepVGG模块或者利用RepVGG模块替换原始yaml配置文件中的一些模块,这里为了能够快速的训练模型,选择YOLOv5s模型进行修改,修改后的yolov5s_se.yaml文件内容如下所示。
# YOLOv5 🚀 by YOLOAir, GPL-3.0 license
# Parameters
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, CBAM, [256]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, CBAM, [512]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, CBAM, [1024]],
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
3 CA
论文名称:Coordinate Attention for Efficient Mobile Network Design
论文链接:https://arxiv.org/pdf/2103.02907.pdf
论文代码:CoordAttention/coordatt.py at main · houqb/CoordAttention · GitHub
3.1 CA原理
目前,轻量级网络的注意力机制大都采用SE模块,仅考虑了通道间的信息,忽略了位置信息。尽管后来的BAM和CBAM尝试在降低通道数后通过卷积来提取位置注意力信息,但卷积只能提取局部关系,缺乏长距离关系提取的能力。为此,论文提出了新的高效注意力机制coordinate attention,能够将横向和纵向的位置信息编码到channel attention中,使得移动网络能够关注大范围的位置信息又不会带来过多的计算量。
coordinate attention的优势主要有以下几点:
- 不仅获取了通道间信息,还考虑了方向相关的位置信息,有助于模型更好地定位和识别目标。
- 足够灵活和轻量,能够简单地插入移动网络的核心结构中。
- 可以作为预训练模型用于多种任务中,如检测和分割,均有不错的性能提升。
CA注意力机制的详细原理可以参考我前期写的博客https://blog.csdn.net/qq_40716944/article/details/121787103?spm=1001.2014.3001.5502
3.2 CA代码(Pytorch)
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return
3.3 YOLOv5中加入CA模块
3.3.1 common.py配置
在yolov5-6.1/models/common.py文件中增加以下模块,直接复制即可。
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return
3.3.2 yolo.py配置
然后找到yolov5-6.1/models//yolo.py文件下里的parse_model函数,将类名加入进去,如下所示。

3.3.3 创建添加CA模块的YOLOv5的yaml配置文件
完成上述两步操作之后,就可以在原有的YOLOv5的yaml配置文件的基础上进行修改,在适当位置添加RepVGG模块或者利用RepVGG模块替换原始yaml配置文件中的一些模块,这里为了能够快速的训练模型,选择YOLOv5s模型进行修改,修改后的yolov5s_se.yaml文件内容如下所示。
# YOLOv5 🚀 by YOLOAir, GPL-3.0 license
# Parameters
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, CoordAtt, [256]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, CoordAtt, [512]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, CoordAtt, [1024]],
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
4、实验效果对比
4.1 口罩检测数据集
前期收集了口罩检测识别数据集,主要是未佩戴口罩和佩戴口罩两个类别,图片总数在10000张左右,部分图片如下所示。

4.2 效果对比
为了对比加入SE、CBAM和CA模块后YOLOv5算法的效果,选择同样的数据集和实验参数进行算法模型训练和测试,实验参数设置如下。
在同样的训练参数和训练集的情况,得到训练后的模型,然后在同样的测试集上进行测试验证,测试集上的测试效果如下表所示,可以看出加入CBAM和CA模块后的YOLOv5s的效果比原始的yolov5s有所提升,但是加入SE注意力机制后的效果是下降的,数据集不同,加入SE、CBAM和CA模块后的效果也是存在区别的,需要根据自己的数据集调整SE、CBAM和CA模块的位置以及数量。
faceface_maskallyolov5s0.8850.9320.908yolov5s_se0.8750.9170.896yolov5s_cbam0.8760.9420.909yolov5s_ca0.8930.9320.913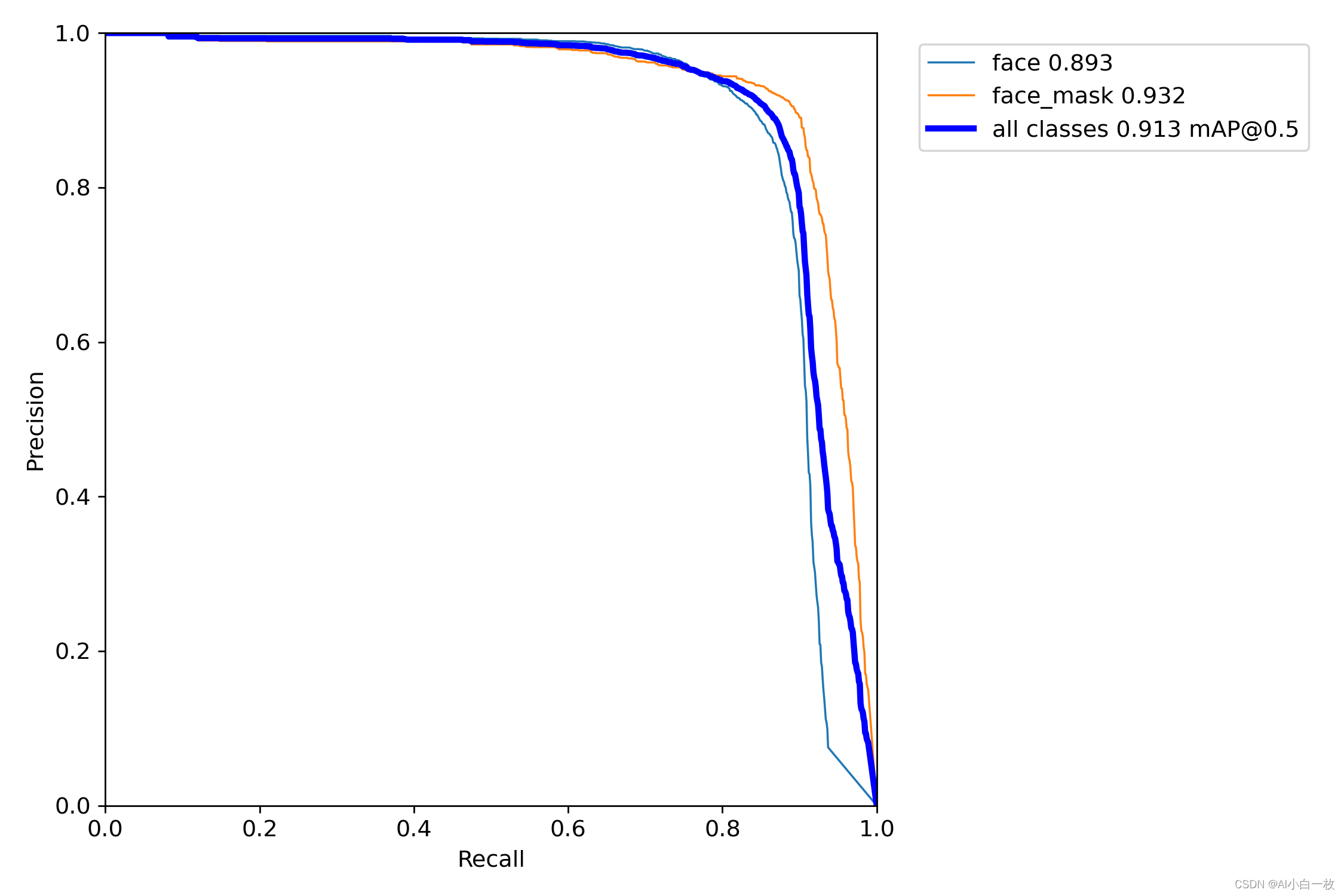
参考文章
1 https://github.com/ultralytics/yolov5
2 CBAM——即插即用的注意力模块(附代码)_Billie使劲学的博客-CSDN博客_cbam
3 注意力机制——CAM、SAM、CBAM、SE_Billie使劲学的博客-CSDN博客_cam注意力机制
版权归原作者 AI追随者 所有, 如有侵权,请联系我们删除。