
SPD-Conv源于2022年一篇专门针对于小目标和低分辨率图像研究提出来的新技术,可以用于目标检测任务,能够一定程度提升模型的检测效果,今天正好有时间就想基于SPD融合yolov5s模型来开发路面裂痕裂缝检测模型,同时与原生的yolov5s模型进行对比分析,首先看下效果图。
接下来看下数据情况。

标注文件如下:

原生yolov5s模型文件如下:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
融合 SPD-Conv模型文件如下:
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
backbone:
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 1]], # 1
[-1,1,space_to_depth,[1]], # 2 -P2/4
[-1, 3, C3, [128]], # 3
[-1, 1, Conv, [256, 3, 1]], # 4
[-1,1,space_to_depth,[1]], # 5 -P3/8
[-1, 6, C3, [256]], # 6
[-1, 1, Conv, [512, 3, 1]], # 7-P4/16
[-1,1,space_to_depth,[1]], # 8 -P4/16
[-1, 9, C3, [512]], # 9
[-1, 1, Conv, [1024, 3, 1]], # 10-P5/32
[-1,1,space_to_depth,[1]], # 11 -P5/32
[-1, 3, C3, [1024]], # 12
[-1, 1, SPPF, [1024, 5]], # 13
]
head:
[[-1, 1, Conv, [512, 1, 1]], # 14
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 15
[[-1, 9], 1, Concat, [1]], # 16
[-1, 3, C3, [512, False]], # 17
[-1, 1, Conv, [256, 1, 1]], # 18
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 19
[[-1, 6], 1, Concat, [1]], # 20
[-1, 3, C3, [256, False]], # 21
[-1, 1, Conv, [256, 3, 1]], # 22
[-1,1,space_to_depth,[1]], # 23
[[-1, 18], 1, Concat, [1]], # 24
[-1, 3, C3, [512, False]], # 25
[-1, 1, Conv, [512, 3, 1]], # 26
[-1,1,space_to_depth,[1]], # 27
[[-1, 14], 1, Concat, [1]], # 28
[-1, 3, C3, [1024, False]], # 29
[[21, 25, 29], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
默认在相同的数据配置下,均执行100次epoch的迭代计算,接下来看下模型的实际表现。
yolov5s结果输出:

spd结果输出:
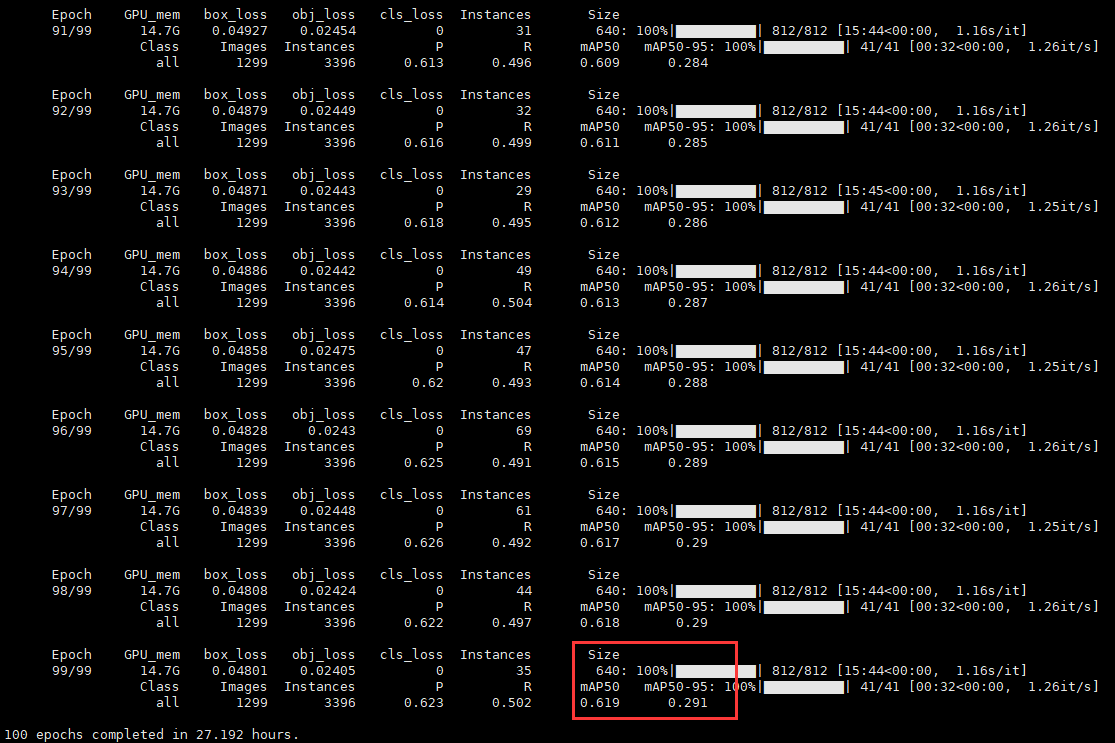
从训练结果输出上面来看:spd的结果要优于原生的YOLOv5s模型的,在训练时间上直观来看spd的训练时长达到了yolov5s的两倍,实际则不然,因为训练原生yolov5s的时候是独占显卡的,但是训练yolov5s-spd模型的时候因为有其他的模型训练在并行进行,所以时长消耗被拉长了。
接下来看下结果详情对比。
混淆矩阵:

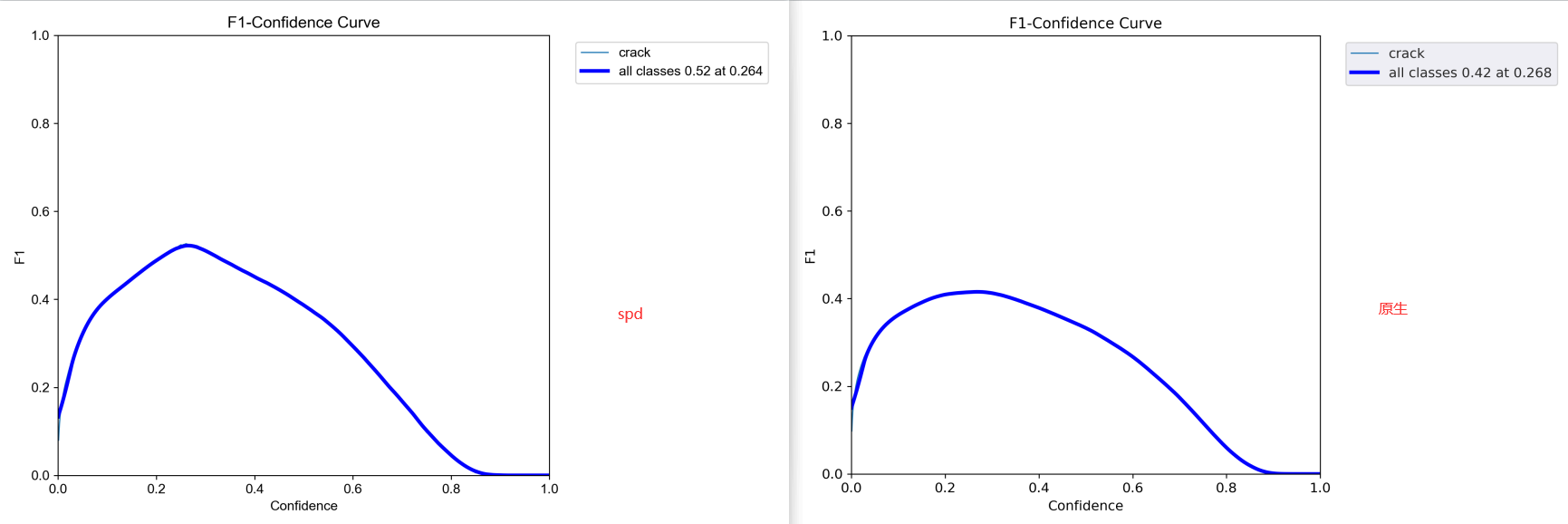
F1值曲线:
PR曲线:
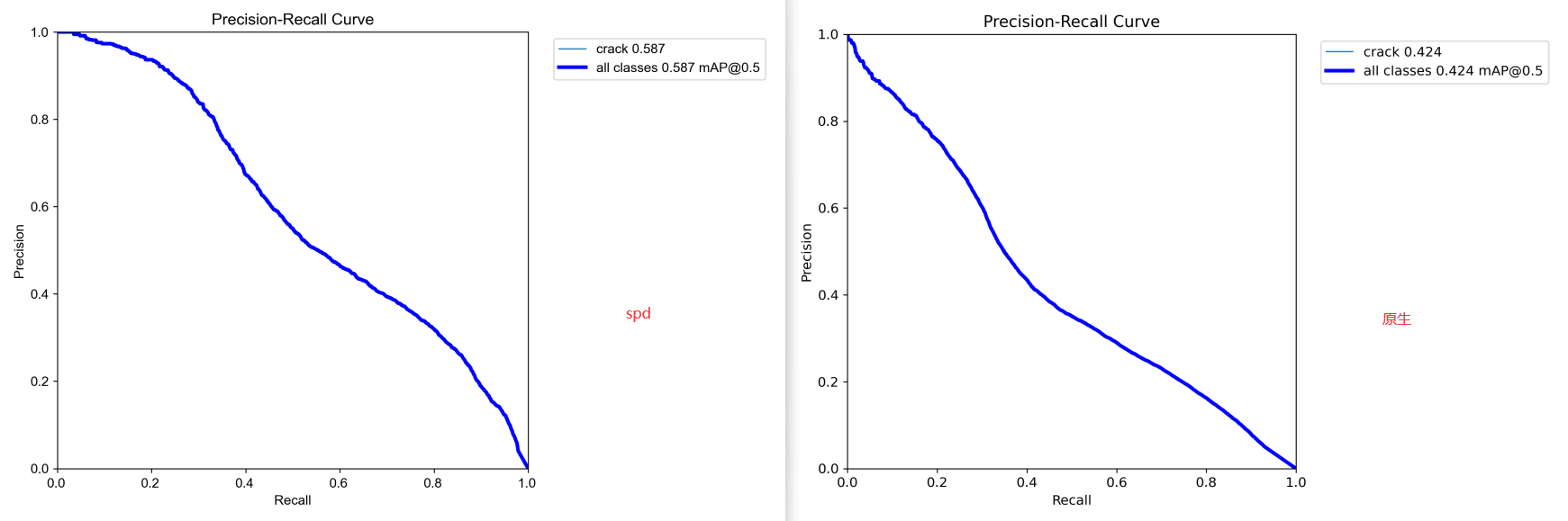
综合对比可以看到:SPD模型都是要优于原生模型的。
LABEL可视化:

batch计算实例如下:

最终基于专门的界面实现可视化推理,样例如下:



简单实践记录一下,关于spd的介绍在我之前的文章中有详细的介绍,本文主要是以应用为主就没有再赘述了。
本文转载自: https://blog.csdn.net/Together_CZ/article/details/128882489
版权归原作者 Together_CZ 所有, 如有侵权,请联系我们删除。
版权归原作者 Together_CZ 所有, 如有侵权,请联系我们删除。