
数据预处理
#!/usr/bin/env python
# coding=utf-8
from string import punctuation
import re
import codecs
# 英文标点符号+中文标点符号
# 未去除空格、换行符等(正则表达式以"/s"表示)
punc = punctuation + u'.,;《》?!“”‘’@#¥%…&×()——+【】{};;●,。&~、|::'
fr = codecs.open("……\YWP_EventExtraction_CRF_Elephant\\01 Preprocessing\\20220107 test data.txt", "r", encoding='utf-8')
fw = codecs.open("……\YWP_EventExtraction_CRF_Elephant\\01 Preprocessing\\20220107 test data_result.txt", "w", encoding='utf-8')
# 利用正则表达式替换为一个空格
for line in fr:
line = re.sub(r"[{}]+".format(punc)," ",line)
fw.write(line+' ')
fr.close()
fw.close()

预处理后的数据示例
LTP:分词+词性标注+命名实体识别
- 输入:即形如上述的预处理后的数据
# -*- coding: utf-8 -*-
import os
from pyltp import NamedEntityRecognizer
from pyltp import Postagger
from pyltp import Segmentor
LTP_DATA_DIR = 'D:/Software/Anaconda3/ltp_data_v3.4.0/' # ltp模型目录的路径,根据实际情况修改
cws_model_path = os.path.join(LTP_DATA_DIR,
'cws.model') # 分词模型路径,模型名称为`cws.model`
pos_model_path = os.path.join(LTP_DATA_DIR,
'pos.model') # 词性标注模型路径,模型名称为`pos.model`
ner_model_path = os.path.join(LTP_DATA_DIR,
'ner.model') # 命名实体识别模型路径,模型名称为`ner.model`
with open("D:\Desktop\北移象群\代码\YWP_EventExtraction_CRF_Elephant\\01 Preprocessing\\20220107 test data_result.txt", "r", encoding='utf-8') as f1:
content = f1.read()
# 分词
segmentor = Segmentor() # 初始化分词实例
segmentor.load_with_lexicon(cws_model_path, 'dict') # 加载分词模型,以及自定义词典
seg_list = segmentor.segment(content) # 分词
seg_list = list(seg_list) # 返回值并不是list类型,因此需要转换为list
# LTP不能很好地处理回车,因此需要去除回车给分词带来的干扰。
# LTP也不能很好地处理数字,可能把一串数字分成好几个单词,因此需要连接可能拆开的数字
i = 0
while i < len(seg_list):
# 如果单词里包含回车,则需要分三种情况处理
if '\n' in seg_list[i] and len(seg_list[i]) > 1:
idx = seg_list[i].find('\n')
# 回车在单词的开头,如\n被告人
if idx == 0:
remains = seg_list[i][1:]
seg_list[i] = '\n'
seg_list.insert(i + 1, remains)
# 回车在单词末尾,如被告人\n
elif idx == len(seg_list[i]) - 1:
remains = seg_list[i][:-1]
seg_list[i] = remains
seg_list.insert(i + 1, '\n')
# 回车在单词中间,如被告人\n张某某
else:
remains1 = seg_list[i].split('\n')[0]
remains2 = seg_list[i].split('\n')[-1]
seg_list[i] = remains1
seg_list.insert(i + 1, '\n')
seg_list.insert(i + 2, remains2)
# 将拆开的数字连接起来
if seg_list[i].isdigit() and seg_list[i + 1].isdigit():
seg_list[i] = seg_list[i] + seg_list[i + 1]
del seg_list[i + 1]
i += 1
# 词性标注
postagger = Postagger() # 初始化词性标注实例
postagger.load(pos_model_path) # 加载模型
postags = postagger.postag(seg_list) # 词性标注
# 命名实体识别
recognizer = NamedEntityRecognizer() # 初始化命名实体识别实例
recognizer.load(ner_model_path) # 加载模型
netags = recognizer.recognize(seg_list, postags) # 命名实体识别
# 写入结果
f2 = open("……\YWP_EventExtraction_CRF_Elephant\\02 LTP (Seg, POS, NER)\\05LTP分词\\20220107 test data_LTPresult.txt", "w", encoding='utf-8')
for word, postag, netag in zip(seg_list, postags, netags):
if word == '\n':
f2.write('\n')
else:
f2.write(word + " " + postag + " " + netag + "\n")
f2.close()
# 释放模型
segmentor.release()
postagger.release()
recognizer.release()
- 输出

LTP处理后的数据示例
CRF++:事件抽取
标注数据
- train.data与test.data数据格式

train.data示例(BMES标注)
训练模型
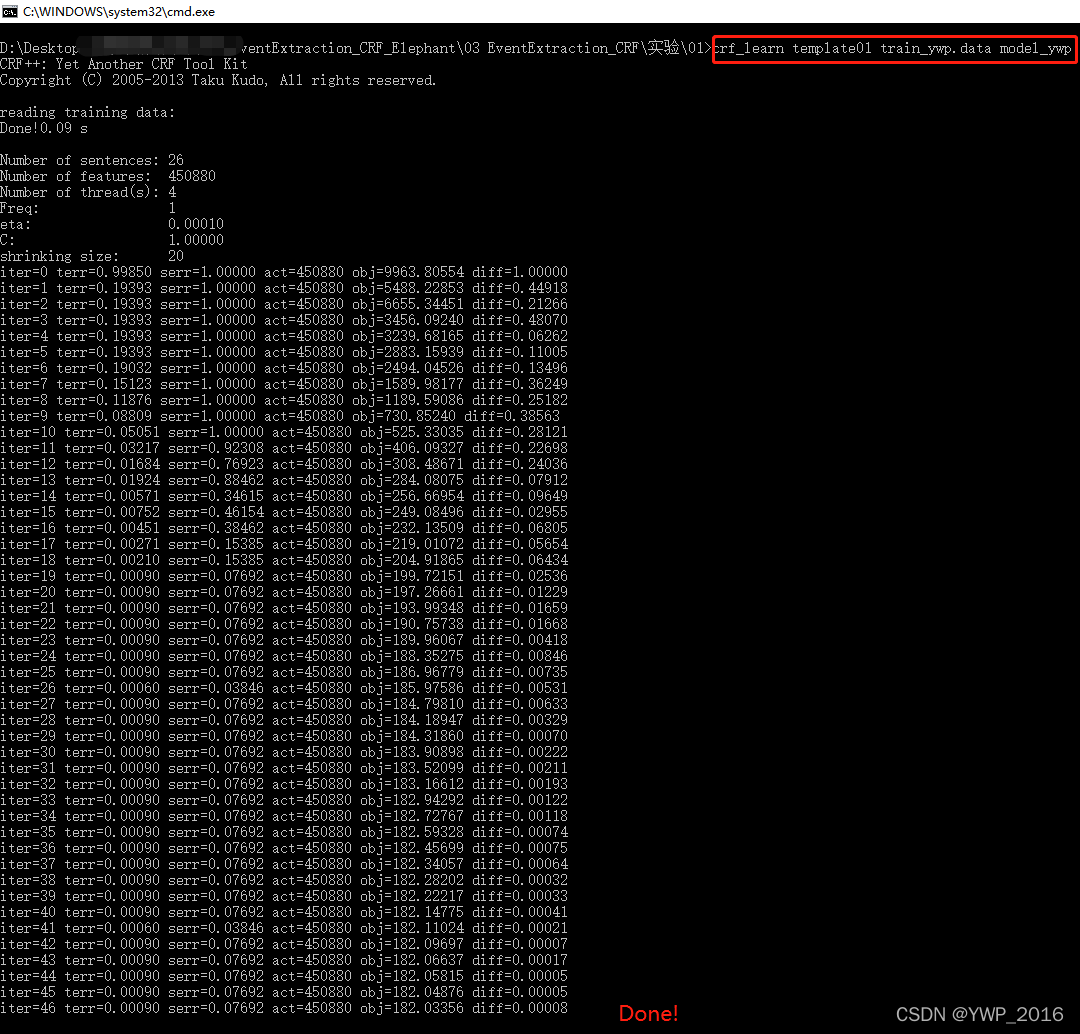
命令行下训练CRF模型
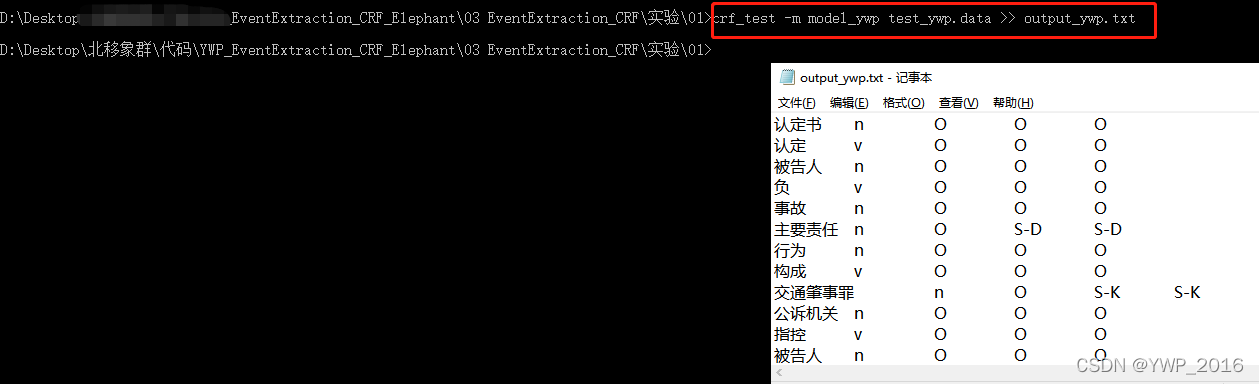
命令行下测试CRF模型
- 输出output.txt→用于后续事件抽取模型评估
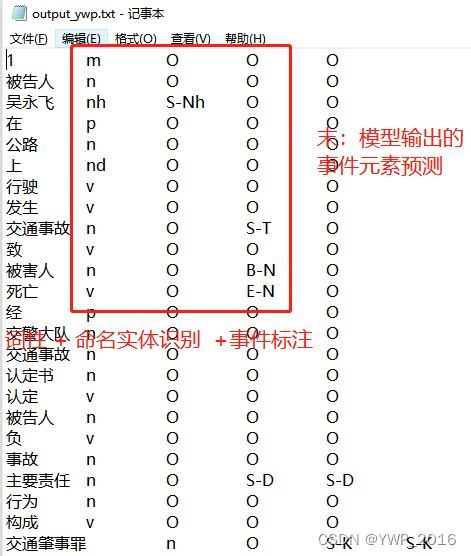
output数据格式
展示事件元素
- (输入:分词+词性+命名实体+事件标注)
#!/usr/bin/env python
# _*_coding:utf-8 _*_
# @Author:Zhang Shiwei + YWP
# @Date :2019-07-21 + 2021-01-07
#通过CRF++模型,得到事件标注(类似命名实体识别)后,运行该程序
# 去除列表中重复元素,同时保持相对顺序不变
def remove_duplicate_elements(l):
new_list = []
for i in l:
if i not in new_list:
new_list.append(i)
return new_list
# 将属于同一事件要素的词语合并
def func(file_name):
words = []
element_type = []
with open(file_name, "r", encoding='utf-8') as f1:
contents = f1.readlines()
new_contents = []
# 将文本转换成list,方便后续处理
for content in contents:
new_contents.append(content.strip("\n").split(" "))
for index, content in enumerate(new_contents):
if "S" in content[-1]:
# 处理由一个单词组成的事件要素
words.append(content[0])
element_type.append(content[-1])
elif "B" in content[-1]:
# 处理由多个单词组成的事件要素
words.append(content[0])
element_type.append(content[-1])
j = index + 1
while "I" in new_contents[j][-1] or "E" in new_contents[j][-1]:
words[-1] = words[-1] + new_contents[j][0]
j += 1
if j == len(new_contents):
break
T = []
K = []
D = []
P = []
N = []
R = []
for i in range(len(element_type)):
if element_type[i][-1] == "T":
T.append(words[i])
elif element_type[i][-1] == "K":
K.append(words[i])
elif element_type[i][-1] == "D":
D.append(words[i])
elif element_type[i][-1] == "P":
P.append(words[i])
elif element_type[i][-1] == "N":
N.append(words[i])
elif element_type[i][-1] == "R":
R.append(words[i])
# 整理抽取结果
result = dict()
result["时间"] = remove_duplicate_elements(T)
result["头数"] = remove_duplicate_elements(K)
result["名称"] = remove_duplicate_elements(D)
result["地点"] = remove_duplicate_elements(P)
result["肇事"] = remove_duplicate_elements(N)
result["原因"] = remove_duplicate_elements(R)
# 打印出完整的事件要素
for key, value in result.items():
print(key, value)
return result
func("…….txt")
#func("…….txt")
精度评价
- 输入数据五列,分别为:分词 + 词性 + 命名实体识别 + 事件元素真实标注 + 事件元素实际标注,后两列用于评价事件抽取模型的精度
# -*- coding:utf-8 -*-
# @Author:Zhang Shiwei + YWP
# @Date :2019-06-10 + 2021-01-07
with open("…….txt", "r", encoding="utf-8") as f1:
contents = f1.read().splitlines()
count = 0
real_count = 0
tp = 0
fp = 0
fn = 0
tn = 0
for i in range(len(contents)):
if len(contents[i]) > 1:
real_count += 1
if contents[i].split(" ")[-2] != "O":
if contents[i].split(" ")[-1] == contents[i].split(" ")[-2]:
tp += 1
else:
fn += 1
else:
if contents[i].split(" ")[-1] != "O":
fp += 1
else:
tn += 1
P = tp / (tp + fp)
R = tp / (tp + fn)
F1 = 2 * P * R / (P + R)
print("P=" + str(P))
print("R=" + str(R))
print("F1=" + str(F1))
重要参考
https://github.com/zhang17173/Event-Extractionhttps://github.com/zhang17173/Event-Extraction
本文转载自: https://blog.csdn.net/YWP_2016/article/details/122364463
版权归原作者 YWP_2016 所有, 如有侵权,请联系我们删除。
版权归原作者 YWP_2016 所有, 如有侵权,请联系我们删除。