
主要目的是为了学习Scrapy与Sklearn而不是写论文,结论是瞎扯的,轻喷求求了
目录
摘要
在我们的日常生活中,电影已经成为了我们娱乐放松活动所不可缺少的元素。然而,自电影诞生以来,人们每天都在生产着电影,却又生产着质量良莠不齐的电影。在这些几乎是无穷无尽的电影洪流中,如何挑选一部高质量电影,成为了电影爱好者乃至平民百姓的首要问题。与此同时,作为电影拍摄团队,如何从高质量电影中找到共性,从而把握大体方向,是拍摄出传世经典的重要保证。
鉴于此,一份高质量电影的分析报告是有必要的。本文以豆瓣评分为标准,用Scrapy爬虫框架爬取豆瓣TOP250网页,再用Pandas,Numpy三方库进行数据处理,提取出时长、评分、电影分类等数据并进行相关性分析,再采用Scikit-learn方法进行K-means聚类分析,最后用Matplotlib三方库进行可视化呈现。
最后,本文得出了关于高质量电影共性的相关结论,并从电影拍摄团队角度,在拍摄高质量电影方面给出了一些建议。
关键词:Scrapy框架;相关性分析;K-means聚类分析
数据爬虫程序设计和实现
Scrapy框架
Scrapy框架简介
Scrapy是基于Python的一个非常流行的网络爬虫框架,可以用来抓取Web站点并从页面中提取结构化的数据。下图展示了Scrapy的基本架构,其中包含了主要组件和系统的数据处理流程。
Scrapy的组件
1.Scrapy 引擎(Engine) :用来控制整个系统的数据处理流程。
2.调度器(Scheduler)︰调度器从引擎接受请求并排序列入队列,并在引擎发出请求后返还给它们。
3.下载器(Downloader)︰下载器的主要职责是抓取网页并将网页内容返还给蜘蛛(Spiders)。
4.蜘蛛程序(Spiders)︰蜘蛛是用户自定义的用来解析网页并抓取特定URL的类,每个蜘蛛都能处理一个域名或一组域名,简单的说就是用来定义特定网站的抓取和解析规则的模块。
5.数据管道(ltem Pipeline)︰管道的主要责任是负责处理有蜘蛛从网页中抽取的数据条目,它的主要任务是清理、验证和存储数据。当页面被蜘蛛解析后,将被发送到数据管道,并经过几个特定的次序处理数据。每个数据管道组件都是一个Python类,它们获取了数据条目并执行对数据条目进行处理的方法,同时还需要确定是否需要在数据管道中继续执行下一步或是直接丢弃掉不处理。数据管道通常执行的任务有︰清理HTML数据、验证解析到的数据(检查条目是否包含必要的字段)、检查是不是重复数据〈如果重复就丢弃)﹑将解析到的数据存储到数据库(关系型数据库或 NoSQL数据库)中。
6.中间件(Middlewares)︰中间件是介于引擎和其他组件之间的一个钩子框架,主要是为了提供自定义的代码来拓展Scrapy的功能,包括下载器中间件和蜘蛛中间件。
Scrapy的工作过程
1.引擎询问蜘蛛需要处理哪个网站,并让蜘蛛将第一个需要处理的URL交给它。
2.引擎让调度器将需要处理的URL放在队列中。
3.引擎从调度那获取接下来进行爬取的页面。
4.调度将下一个爬取的URL返回给引擎,引擎将它通过下载中间件发送到下载器。
5.当网页被下载器下载完成以后,响应内容通过下载中间件被发送到引擎;如果下载失败了,引擎会通知调度器
记录这个URL,待会再重新下载。
6.引擎收到下载器的响应并将它通过蜘蛛中间件发送到蜘蛛进行处理。
7.蜘蛛处理响应并返回爬取到的数据条目,此外还要将需要跟进的新的URL发送给引擎。
8.引擎将抓取到的数据条目送入数据管道,把新的URL发送给调度器放入队列中。
上述操作中的第2步到第8步会一直重复直到调度器中没有需要请求的URL,爬虫就停止工作。
爬取豆瓣TOP250网页
新建爬虫项目
在任意项目的终端上输入
pip install scrapy
以下载安装Scrapy,然后输入
scrapy startproject spider
来新建spider项目。
编写爬虫程序
在spider项目的终端调用
scrapy genspider douban movie.douban.com
来生成针对豆瓣网站的爬虫,取名为douban。
douban.py的代码如下:
import scrapy
from scrapy import Selector, Request
from scrapy.http import HtmlResponse
from spider.items import MovieItem
classDoubanSpider(scrapy.Spider):
name ='douban'
allowed_domains =['movie.douban.com']defstart_requests(self):for page inrange(10):yield Request(url=f'https://movie.douban.com/top250?start={page *25}&filter=')defparse(self, response: HtmlResponse,**kwargs):
sel = Selector(response)
list_items = sel.css('#content > div > div.article > ol > li')for list_item in list_items:
detail_url = list_item.css('div > div.info > div.hd > a::attr(href)').get()
movie_item = MovieItem()
movie_item['title']= list_item.css('span.title::text').get()or''
movie_item['rating_num']= list_item.css('span.rating_num::text').get()or''yield Request(url=detail_url, callback=self.detail_parse, cb_kwargs={'item': movie_item})defdetail_parse(self, response,**kwargs):
movie_item = kwargs['item']
sel = Selector(response)
movie_item['mold']= sel.css('span[property="v:genre"]::text').getall()or''
movie_item['duration']= sel.css('span[property="v:runtime"]::attr(content)').get()or''yield movie_item
其中,
allowed_domains =['movie.douban.com']
用于锁定豆瓣网站;
defstart_requests(self):for page inrange(10):yield Request(url=f'https://movie.douban.com/top250?start={page *25}&filter=')
用于实现第1页到第10页的切换,因为一个页面有25条电影数据,每次点击下一页后更新的网址中start便增加了25;
defparse(self, response: HtmlResponse,**kwargs):
与
defdetail_parse(self, response,**kwargs):
用于爬取所需的电影信息,并采用yield方式传给Request方法,从而做到连续爬取。
items.py代码如下:
import scrapy
classMovieItem(scrapy.Item):
title = scrapy.Field()
rating_num = scrapy.Field()
mold = scrapy.Field()
duration = scrapy.Field()
用于给获取的信息命名。
middlewares.py无需改动,因为本次不需要特殊的中间件。
pipelines.py需改动的地方如下:
USER_AGENT ='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
用于把自己伪装成浏览器,防止反爬;
DOWNLOAD_DELAY =10
RANDOMIZE_DOWNLOAD_DELAY =True
CONCURRENT_REQUESTS =32
为了补偿时延降低的效率,将并发请求增加一倍(默认为16)。
获得csv文件
在终端输入
scrapy crawl douban -o data.csv
用csv接收数据,得到data.csv文件见附录。
数据分析与挖掘算法的设计和实现
NumPy&Pandas&Scikit-learn简介
NumPy
NumPy是一个用python实现的科学计算,包括:1、一个强大的N维数组对象Array;2、比较成熟的(广播)函数库;3、用于整合C/C++和Fortran代码的工具包;4、实用的线性代数、傅里叶变换和随机数生成函数。numpy和稀疏矩阵运算包scipy配合使用更加方便。
NumPy(Numeric Python)提供了许多高级的数值编程工具,如:矩阵数据类型、矢量处理,以及精密的运算库。专为进行严格的数字处理而产生。
NumPy 的前身为 Numeric ,最早由 Jim Hugunin 与其它协作者共同开发,2005 年,Travis Oliphant 在 Numeric 中结合了另一个同性质的程序库 Numarray 的特色,并加入了其它扩展而开发了 NumPy。NumPy 为开放源代码并且由许多协作者共同维护开发。
Pandas
Pandas 是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
Scikit-learn
Scikit-learn(以前称为scikits.learn,也称为sklearn)是针对python 编程语言的免费软件机器学习库。它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度提升,k均值和DBSCAN,并且旨在与ython数值科学库NumPy和SciPy联合使用。
Scikit-learn项目始于scikits.learn,这是David Cournapeau的Google Summer of Code项目。它的名称源于它是“ SciKit”(SciPy工具包)的概念,它是SciPy的独立开发和分布式第三方扩展。原始代码库后来被其他开发人员重写。2010年费边Pedregosa,盖尔Varoquaux,亚历山大Gramfort和Vincent米歇尔,全部由法国国家信息与自动化研究所的罗屈昂库尔,法国,把该项目的领导和做出的首次公开发行在二月一日2010在各种scikits中,scikit-learn以及scikit-image在2012年11月被描述为“维护良好且受欢迎” 。Scikit-learn是GitHub上最受欢迎的机器学习库之一。
用三方库处理爬虫文件
读取文件
代码如下:
data = pd.read_csv('data.csv')
mold = data.iloc[:,1]
avg_rating_num = np.mean(data.iloc[:,[2]], axis=0)
X = data.iloc[:,[0,2]]
X = X.values.astype('float32')
通过调用pd.read_csv读入文件,并获得类型mold、均分avg_rating_num、时长与评分是数据集X。
处理数据
代码如下:
label ={}deffetch(s):if s in label:
label[s]+=1else:
label[s]=1for i in mold:print(i)iflen(i)==2:
fetch(i[0:2])eliflen(i)==3:
fetch(i[0:3])eliflen(i)==5:
fetch(i[0:2])
fetch(i[3:5])eliflen(i)==8:
fetch(i[0:2])
fetch(i[3:5])
fetch(i[6:8])eliflen(i)==11:
fetch(i[0:2])
fetch(i[3:5])
fetch(i[6:8])
fetch(i[9:11])eliflen(i)==14:
fetch(i[0:2])
fetch(i[3:5])
fetch(i[6:8])
fetch(i[9:11])
fetch(i[12:14])del label["剧情"]
其中,
label ={}
用于新建一个空字典label来统计mold中出现的关键词与出现次数;
deffetch(s):if s in label:
label[s]+=1else:
label[s]=1
用于记录关键词出现次数,如果它没有出现,就把次数记为1,否则+1;
CONCURRENT_REQUESTS = 32for i in mold:print(i)iflen(i)==2:
fetch(i[0:2])eliflen(i)==3:
fetch(i[0:3])eliflen(i)==5:
fetch(i[0:2])
fetch(i[3:5])eliflen(i)==8:
fetch(i[0:2])
fetch(i[3:5])
fetch(i[6:8])eliflen(i)==11:
fetch(i[0:2])
fetch(i[3:5])
fetch(i[6:8])
fetch(i[9:11])eliflen(i)==14:
fetch(i[0:2])
fetch(i[3:5])
fetch(i[6:8])
fetch(i[9:11])
fetch(i[12:14])
观察数据可以发现,大部分关键词都是两个字,且中间带有逗号,因此只要找到逗号的位置就可以将其周围的关键词分隔开,并依据字符串的长度判断该字符串中有几个关键词。
del label["剧情"]
最后,因为发现“剧情”这一关键词出现频次过高,且对于高质量电影分析没有意义(电影一定都会有剧情),所以把“剧情”删去。
算法实现
相关性分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度。相关性的元素之间需要存在一定的联系或者概率才可以进行相关性分析。
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是,预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
代码如下:
print(np.corrcoef(X[:,0], X[:,1]))
clf = KMeans(n_clusters=4)
y_pred = clf.fit_predict(X)
调用np.corrcoef计算时长与评分的相关性,调用sklearn.cluster中的KMeans方法,把数据分成4簇。
数据可视化设计和实现
Matplotlib简介
Matplotlib 是 Python 的绘图库,它能让使用者很轻松地将数据图形化,并且提供多样化的输出格式,可以用来绘制各种静态,动态,交互式的图表,是一个非常强大的 Python 画图工具,可以绘制线图、散点图、等高线图、条形图、柱状图、3D 图形、甚至是图形动画等等。
Matplotlib 通常与 NumPy 和 SciPy(Scientific Python)一起使用, 这种组合广泛用于替代 MatLab,是一个强大的科学计算环境,有助于我们通过 Python 学习数据科学或者机器学习。
可视化设计
对于类型,生成饼状图;对于聚类,生成散点图。
代码如下:
patches, text = plt.pie(label.values(), labels=label.keys(), radius=1)
text[-1].set_text('')
text[-2].set_text('')
text[-3].set_text('')
text[-5].set_text('')
text[-6].set_text('')
text[-7].set_text('')
text[-8].set_text('')
text[-9].set_text('')
text[13].set_text('')for t in text:
t.set_size(10)
plt.title("高质量电影类型成分分析")
x =[n[0]for n in X]
y =[n[1]for n in X]
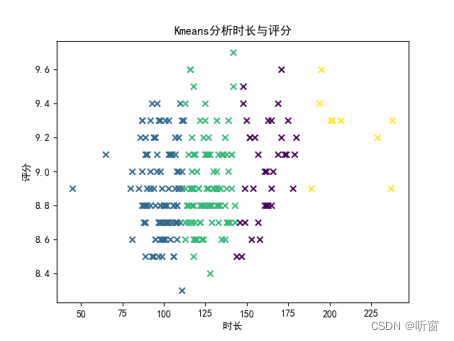
plt.scatter(x, y, c=y_pred, marker='x')
plt.title("Kmeans分析时长与评分")
plt.xlabel("时长")
plt.ylabel("评分")
plt.show()
其中,
text[-1].set_text('')
text[-2].set_text('')
text[-3].set_text('')
text[-5].set_text('')
text[-6].set_text('')
text[-7].set_text('')
text[-8].set_text('')
text[-9].set_text('')
text[13].set_text('')
用于将较小的类型置空,以使饼状图美观;
x =[n[0]for n in X]
y =[n[1]for n in X]
用于提取数据集X的数据,做单个散点图。
最终结果如下图: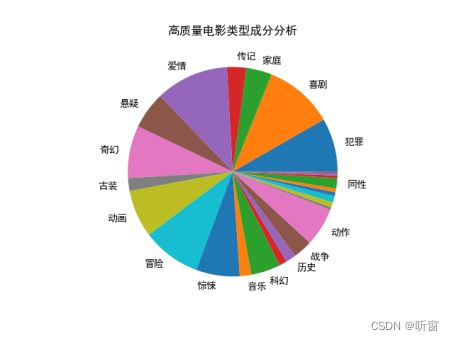
结论
最终,由分析可得:
高质量电影中,类型占比最高的前八个类型为:爱情、喜剧、奇幻、动画、冒险、惊悚、犯罪、动作。
时长与评分的总体相关性为0.267,相关性不高,但经过聚类后,时长较高的那一类的时长与评分的相关性为0.733,呈现出较好的相关性,且经过计算发现,时长较高的那一类的总体评分较高。
因此,本文对于电影拍摄团队,给出如下建议:
1.拍摄题材应更多地考虑爱情、喜剧、奇幻、动画、冒险、惊悚、犯罪、动作八个类型。
2.考虑长一点的拍摄时长,以不低于150min为宜。
附录
data.csv:
duration,mold,rating_num,title
142,“剧情,犯罪”,9.7,肖申克的救赎
112,“剧情,喜剧”,9.3,触不可及
117,“剧情,家庭,传记”,9.2,当幸福来敲门
90,“剧情,喜剧,爱情”,9.1,怦然心动
175,“剧情,犯罪”,9.3,教父
116,“剧情,悬疑,犯罪”,9.6,控方证人
125,剧情,9.3,熔炉
95,“喜剧,爱情,奇幻,古装”,9.2,大话西游之大圣娶亲
109,“喜剧,动画,冒险”,9.2,疯狂动物城
101,“剧情,惊悚,犯罪”,9.3,无间道
97,“剧情,喜剧,音乐”,9.3,放牛班的春天
98,“科幻,动画,冒险”,9.3,机器人总动员
171,“剧情,喜剧,爱情,歌舞”,9.2,三傻大闹宝莱坞
103,“剧情,科幻”,9.3,楚门的世界
93,剧情,9.4,忠犬八公的故事
169,“剧情,科幻,冒险”,9.4,星际穿越
165,“剧情,音乐”,9.3,海上钢琴师
148,“剧情,科幻,悬疑,冒险”,9.4,盗梦空间
195,“剧情,历史,战争”,9.6,辛德勒的名单
125,“剧情,动画,奇幻”,9.4,千与千寻
116,“剧情,喜剧,爱情,战争”,9.6,美丽人生
110,“剧情,动作,犯罪”,9.4,这个杀手不太冷
194,“剧情,爱情,灾难”,9.4,泰坦尼克号
142,“剧情,爱情”,9.5,阿甘正传
155,“剧情,爱情”,9.2,天堂电影院
162,“动作,科幻,冒险”,8.8,阿凡达
127,“剧情,喜剧,家庭”,8.9,7号房的礼物
98,“爱情,奇幻,武侠,古装”,8.8,倩女幽魂
139,“剧情,传记,历史,战争”,8.7,血战钢锯岭
113,“剧情,悬疑,惊悚,犯罪”,8.7,记忆碎片
237,“剧情,犯罪”,8.9,牯岭街少年杀人事件
106,“剧情,科幻,惊悚”,8.8,千钧一发
107,“剧情,惊悚”,8.7,浪潮
128,“剧情,传记”,8.8,聚焦
111,“剧情,喜剧”,8.3,驴得水
97,“剧情,喜剧”,8.5,完美陌生人
118,“剧情,爱情”,9.1,我爱你
165,“剧情,家庭,儿童”,8.9,地球上的星星
87,“剧情,爱情,动画”,8.8,千年女优
147,“剧情,犯罪,奇幻”,8.5,香水
124,“剧情,爱情”,8.6,朗读者
98,“剧情,爱情,科幻,动画”,8.6,穿越时空的少女
119,“动作,悬疑,惊悚”,8.6,谍影重重
104,“喜剧,爱情,音乐”,8.6,再次出发之纽约遇见你
104,纪录片,9.1,海洋
144,“剧情,科幻,冒险”,8.5,火星救援
94,“剧情,爱情,犯罪”,8.5,阿飞正传
130,“剧情,惊悚,犯罪”,8.9,末路狂花
133,“剧情,爱情,战争,西部”,8.8,燃情岁月
108,“动作,悬疑,惊悚”,8.7,谍影重重2
128,“剧情,爱情,歌舞”,8.4,爱乐之城
122,“剧情,犯罪”,8.7,战争之王
101,“动画,奇幻,冒险”,8.6,崖上的波妞
89,“科幻,悬疑,惊悚”,8.5,彗星来的那一夜
138,“动作,科幻”,8.7,黑客帝国2:重装上阵
108,“剧情,爱情,战争”,8.8,魂断蓝桥
115,“剧情,家庭”,8.8,步履不停
143,“剧情,惊悚,冒险”,8.7,血钻
101,“动画,音乐,奇幻”,8.7,心灵奇旅
153,“剧情,犯罪”,8.6,无耻混蛋
118,“剧情,家庭”,8.8,房间
88,“动作,爱情,武侠,古装”,8.7,新龙门客栈
120,“动作,科幻,冒险”,8.6,疯狂的麦克斯4:狂暴之路
99,纪录片,8.7,二十二
113,“剧情,家庭,儿童”,8.6,奇迹男孩
135,“剧情,同性,音乐,传记”,8.6,波西米亚狂想曲
99,“剧情,爱情,奇幻,古装”,8.6,青蛇
137,“动作,科幻”,8.8,终结者2:审判日
88,“剧情,悬疑,犯罪”,8.8,罗生门
137,“剧情,家庭”,8.6,海边的曼彻斯特
118,“剧情,喜剧,爱情”,8.5,初恋这件小事
92,“剧情,喜剧,动画”,9.0,东京教父
146,“剧情,科幻”,8.7,人工智能
132,“喜剧,战争”,8.9,虎口脱险
122,“剧情,惊悚,犯罪”,8.7,小丑
93,“科幻,悬疑,惊悚”,8.5,源代码
148,剧情,9.5,背靠背,脸对脸
89,“剧情,动画,战争”,8.7,萤火虫之墓
119,“剧情,惊悚,犯罪”,8.7,无间道2
102,“剧情,喜剧”,8.7,大佛普拉斯
85,“剧情,犯罪”,8.9,可可西里
87,“剧情,喜剧,爱情”,9.3,城市之光
97,“剧情,喜剧,冒险”,8.7,遗愿清单
133,剧情,8.7,雨人
123,“剧情,爱情”,8.6,恋恋笔记本
103,“动画,奇幻,冒险”,8.7,魔女宅急便
149,“科幻,惊悚,冒险”,8.9,2001太空漫游
99,“剧情,悬疑,惊悚”,8.5,恐怖游轮
108,“剧情,惊悚”,8.6,黑天鹅
90,“剧情,动画,儿童”,8.9,你看起来好像很好吃
103,“喜剧,爱情,歌舞”,9.1,雨中曲
81,“喜剧,动画,冒险”,8.6,冰川时代
118,“剧情,历史”,9.5,茶馆
106,“喜剧,犯罪”,8.5,疯狂的石头
100,“剧情,动作,爱情,武侠,古装”,8.6,东邪西毒
135,“剧情,喜剧,爱情”,8.6,真爱至上
101,“喜剧,动画,奇幻,冒险”,8.7,无敌破坏王
120,“剧情,爱情”,8.6,贫民窟的百万富翁
117,“剧情,家庭,犯罪”,8.7,小偷家族
107,“剧情,音乐”,8.7,爆裂鼓手
158,“剧情,爱情,情色”,8.6,色,戒
189,“剧情,悬疑,犯罪,奇幻”,8.9,绿里奇迹
109,“剧情,爱情”,8.9,爱在午夜降临前
122,“剧情,喜剧,犯罪”,8.8,荒蛮故事
107,剧情,9.2,忠犬八公物语
117,“剧情,家庭”,8.7,岁月神偷
127,“剧情,家庭”,8.8,海街日记
108,“剧情,喜剧,动作,犯罪”,8.8,纵横四海
110,“剧情,悬疑,犯罪”,8.7,心迷宫
117,“动画,奇幻,冒险”,8.9,风之谷
95,“剧情,动作,犯罪”,8.6,英雄本色
109,“悬疑,惊悚,恐怖”,9.0,惊魂记
108,“剧情,喜剧,古装”,8.7,九品芝麻官
115,“动作,悬疑,惊悚”,8.8,谍影重重3
130,“剧情,犯罪”,9.0,上帝之城
98,“喜剧,动画,冒险”,8.7,疯狂原始人
117,“剧情,同性,传记”,8.8,达拉斯买家俱乐部
121,“剧情,传记,历史,战争”,8.9,卢旺达饭店
106,“剧情,爱情,动画”,8.5,你的名字。
115,“剧情,犯罪”,8.7,三块广告牌
103,“悬疑,惊悚,恐怖”,8.7,电锯惊魂
95,“喜剧,动画,冒险”,8.8,头脑特工队
129,“动作,科幻”,8.8,黑客帝国3:矩阵革命
98,“剧情,爱情”,8.7,花样年华
207,“剧情,动作,冒险”,9.3,七武士
108,“剧情,喜剧,爱情,同性,家庭”,9.0,喜宴
114,“剧情,同性,传记,战争”,8.8,模仿游戏
134,“剧情,犯罪”,8.9,新世界
140,“动作,科幻,冒险”,8.7,头号玩家
132,“剧情,家庭”,9.0,我是山姆
157,“悬疑,奇幻,冒险”,8.7,哈利·波特与火焰杯
97,“剧情,悬疑,犯罪”,8.7,恐怖直播
65,“动画,奇幻,冒险”,9.1,哪吒闹海
163,“剧情,动作,西部,冒险”,8.8,被解救的姜戈
113,“喜剧,奇幻,武侠,古装”,8.7,射雕英雄传之东成西就
124,“剧情,喜剧”,8.8,阳光姐妹淘
118,“动作,惊悚,灾难”,8.6,釜山行
81,“动画,惊悚,奇幻”,9.0,未麻的部屋
95,“喜剧,动画,冒险”,8.6,神偷奶爸
106,“剧情,悬疑”,8.8,告白
129,“剧情,爱情”,8.7,傲慢与偏见
125,“剧情,家庭,奇幻,冒险”,8.8,大鱼
103,“喜剧,动画,奇幻,冒险”,8.9,玩具总动员3
132,剧情,8.8,寄生虫
116,剧情,8.9,一个叫欧维的男人决定去死
162,“剧情,犯罪”,9.0,教父3
92,“喜剧,动画,儿童,奇幻,冒险”,8.8,怪兽电力公司
45,“剧情,爱情,动画,奇幻”,8.9,萤火之森
92,“剧情,喜剧,动画”,8.9,玛丽和马克思
98,“动画,奇幻,冒险”,8.8,驯龙高手
128,“剧情,喜剧,爱情”,8.8,幸福终点站
123,“喜剧,爱情,奇幻”,8.8,时空恋旅人
111,“剧情,爱情,动画”,8.9,侧耳倾听
120,剧情,9.0,小森林 冬春篇
118,“剧情,爱情”,8.9,甜蜜蜜
94,“动画,奇幻,冒险”,8.9,借东西的小人阿莉埃蒂
80,“剧情,爱情”,8.9,爱在日落黄昏时
149,“剧情,悬疑,惊悚,犯罪”,8.7,消失的爱人
141,剧情,9.1,无人知晓
138,“剧情,犯罪”,9.1,完美的世界
102,“喜剧,动作,科幻,动画,冒险”,8.7,超能陆战队
134,“剧情,爱情”,8.9,阳光灿烂的日子
121,“剧情,喜剧”,8.9,菊次郎的夏天
111,剧情,9.0,小森林 夏秋篇
165,“剧情,动作,科幻,惊悚,犯罪”,8.8,蝙蝠侠:黑暗骑士崛起
134,“动画,奇幻,冒险”,8.9,幽灵公主
102,“剧情,爱情”,8.8,重庆森林
101,“剧情,爱情”,8.8,爱在黎明破晓前
122,“剧情,喜剧,爱情”,8.7,天使爱美丽
107,“剧情,悬疑,惊悚”,8.9,第六感
161,“奇幻,冒险”,8.8,哈利·波特与密室
173,“剧情,爱情,家庭”,9.1,一一
130,剧情,8.9,入殓师
102,“喜剧,爱情,古装”,8.7,唐伯虎点秋香
178,“剧情,动作,传记,历史,战争”,8.9,勇敢的心
134,“剧情,爱情,同性,家庭”,8.8,断背山
105,“剧情,爱情,奇幻”,8.7,剪刀手爱德华
132,“剧情,爱情,同性”,8.9,请以你的名字呼唤我
115,剧情,9.1,狩猎
130,“剧情,歌舞”,8.9,被嫌弃的松子的一生
90,“科幻,动画,悬疑,惊悚”,9.1,红辣椒
143,“动作,奇幻,冒险”,8.8,加勒比海盗
141,“奇幻,冒险”,8.9,哈利·波特与阿兹卡班的囚徒
98,剧情,9.0,超脱
132,“剧情,动作,悬疑,惊悚,犯罪”,8.9,杀人回忆
100,“喜剧,动作,犯罪,奇幻”,8.8,功夫
90,“剧情,悬疑,惊悚”,8.8,致命ID
89,“剧情,喜剧,爱情”,8.8,喜剧之王
127,“剧情,悬疑,惊悚,犯罪”,8.8,七宗罪
87,“剧情,喜剧,爱情”,9.3,摩登时代
96,“剧情,爱情,同性”,9.0,春光乍泄
154,“剧情,喜剧,犯罪”,8.9,低俗小说
126,剧情,8.9,心灵捕手
229,“剧情,犯罪”,9.2,美国往事
113,“剧情,科幻,悬疑,惊悚”,8.9,蝴蝶效应
99,“剧情,喜剧,冒险”,8.9,布达佩斯大饭店
138,“剧情,悬疑,惊悚”,8.9,禁闭岛
130,“剧情,悬疑,惊悚”,8.9,致命魔术
92,纪录片,9.3,海豚湾
118,“剧情,惊悚,犯罪”,8.9,沉默的羔羊
130,“奇幻,冒险”,8.9,哈利·波特与死亡圣器(下)
89,“剧情,家庭,儿童”,9.2,小鞋子
133,剧情,9.1,飞越疯人院
169,“剧情,战争”,9.1,拯救大兵瑞恩
174,“剧情,爱情,歌舞,传记”,9.1,音乐之声
106,“剧情,悬疑,惊悚,犯罪”,8.8,看不见的客人
109,“剧情,情色,战争”,8.9,西西里的美丽传说
107,“剧情,喜剧,犯罪”,9.1,两杆大烟枪
117,“剧情,爱情”,8.9,情书
94,“剧情,战争”,9.2,穿条纹睡衣的男孩
166,“剧情,爱情,奇幻”,9.0,本杰明·巴顿奇事
137,“剧情,悬疑”,9.2,窃听风暴
135,“剧情,传记”,9.1,美丽心灵
124,“剧情,家庭”,9.2,饮食男女
139,“剧情,动作,悬疑,惊悚”,9.0,搏击俱乐部
89,“动画,歌舞,冒险”,9.1,狮子王
127,剧情,9.2,辩护人
130,“剧情,喜剧,音乐,传记”,8.9,绿皮书
202,“剧情,犯罪”,9.3,教父2
128,剧情,9.1,死亡诗社
113,“剧情,动画,奇幻,古装”,9.4,大闹天宫
136,“动作,科幻”,9.1,黑客帝国
179,“剧情,动作,奇幻,冒险”,9.1,指环王1:护戒使者
118,“剧情,喜剧,爱情”,9.1,罗马假日
111,“剧情,家庭,冒险”,9.3,海蒂和爷爷
180,“剧情,动作,奇幻,冒险”,9.2,指环王2:双塔奇兵
157,剧情,9.1,闻香识女人
132,“剧情,喜剧,动作,西部”,8.9,让子弹飞
150,“剧情,音乐,传记,战争”,9.3,钢琴家
125,“动画,奇幻,冒险”,9.1,天空之城
87,“喜剧,爱情,奇幻,古装”,9.0,大话西游之月光宝盒
141,“剧情,传记,犯罪”,9.1,猫鼠游戏
139,“剧情,喜剧”,9.3,鬼子来了
119,“动画,奇幻,冒险”,9.1,哈尔的移动城堡
127,“剧情,奇幻,冒险”,9.1,少年派的奇幻漂流
96,剧情,9.4,十二怒汉
126,剧情,9.1,何以为家
117,“剧情,喜剧”,9.0,我不是药神
161,“剧情,家庭,传记,运动”,9.0,摔跤吧!爸爸
96,“剧情,喜剧,动画,冒险”,9.1,飞屋环游记
122,剧情,9.3,素媛
238,“剧情,爱情,历史,战争”,9.3,乱世佳人
201,“剧情,动作,奇幻,冒险”,9.3,指环王3:王者无敌
152,“奇幻,冒险”,9.2,哈利·波特与魔法石
132,“剧情,家庭,历史”,9.3,活着
152,“剧情,动作,科幻,惊悚,犯罪”,9.2,蝙蝠侠:黑暗骑士
105,“喜剧,动画,音乐,奇幻”,9.1,寻梦环游记
86,“动画,奇幻,冒险”,9.2,龙猫
163,“剧情,传记,历史”,9.3,末代皇帝
171,“剧情,爱情,同性”,9.6,霸王别姬
版权归原作者 听窗 所有, 如有侵权,请联系我们删除。