
📢📢📢📣📣📣
作者:IT邦德
中国DBA联盟(ACDU)成员,10余年DBA工作经验,
Oracle、PostgreSQL ACE
CSDN博客专家及B站知名UP主,全网粉丝10万+
擅长主流Oracle、MySQL、PG、高斯及Greenplum备份恢复,
安装迁移,性能优化、故障应急处理
文章目录
📣 前言
本文介绍了Mycat数据库中间件实现的MySQL读写分离分库分表的高可用架构
📣 1.分库分表
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
① 分库:垂直分库、水平分库
② 分表:垂直分表、水平分表
分库是指把一个数据库拆分为多个数据库,一般分为垂直分库和水平分库。
分表指的是通过一定规则,将一张表分解成多张不同的表,一般分为垂直分表和水平分表。
✨ 1.1 垂直分库
1 、概念:垂直分库以表为依据,按照业务归属不同,将不同的表拆分到不同的业务库中。
每个库可以放在不同的服务器上,核心理念是专库专用。
2 、结果:垂直分库的结果是
①每个库的表结构都不一样;
②每个库的数据也不一样,没有交集;
③所有库的并集是全量数据。

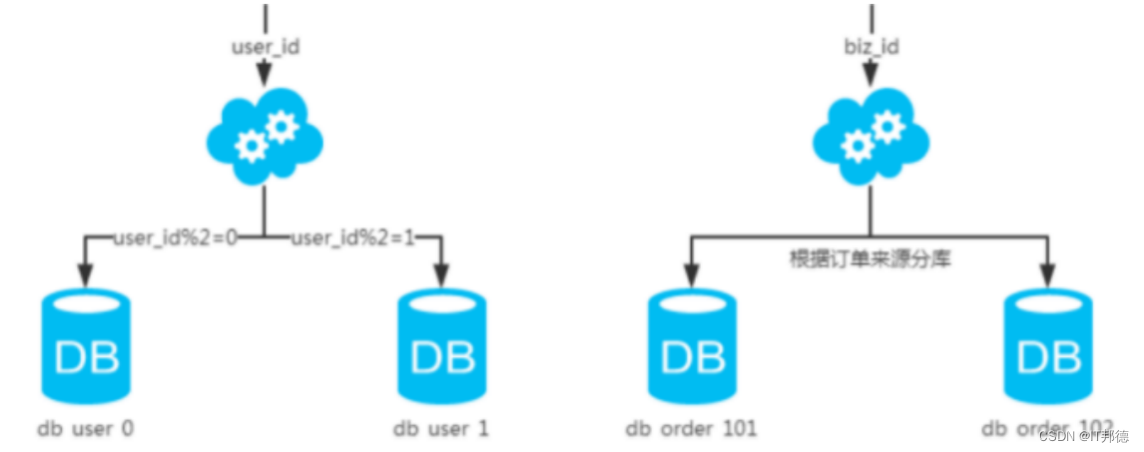
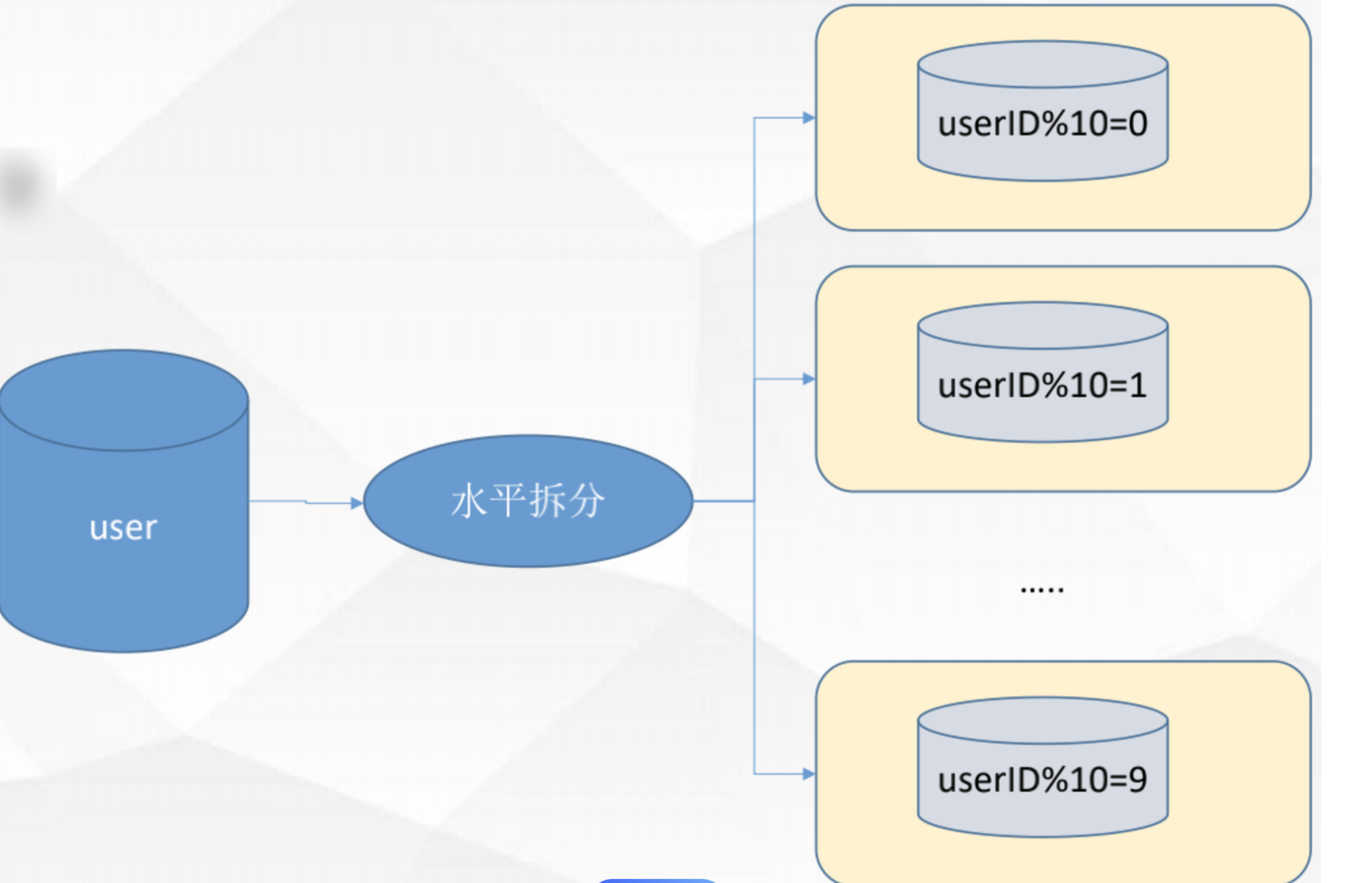
✨ 1.2 水平分库
1 、概念:水平分库是以字段为依据,按照一定策略(hash、range 等),
将一个库中的数据拆分到多个库中。
2 、结果:水平分库的结果是
①每个库的结构都一样;
②每个库的数据都不一样,没有交集;
③所有库的并集是全量数据。
✨ 1.3 垂直分表
1 、概念:垂直分表即“宽表拆窄表”,以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。垂直分表一般是表中的字段较多,将冗余字段,不常用字段,数据较大,长度较长(例如 text 类型字段)的拆分到“扩展表“。一般是针对那种几百列的宽表,也可以避免在查询时,数据量太大造成的“跨页”问题。
2 、结果:垂直分表的结果是
①每个表的结构都不一样;
②每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,
一般是主键,用于关联数据;
③所有表的并集是全量数据。

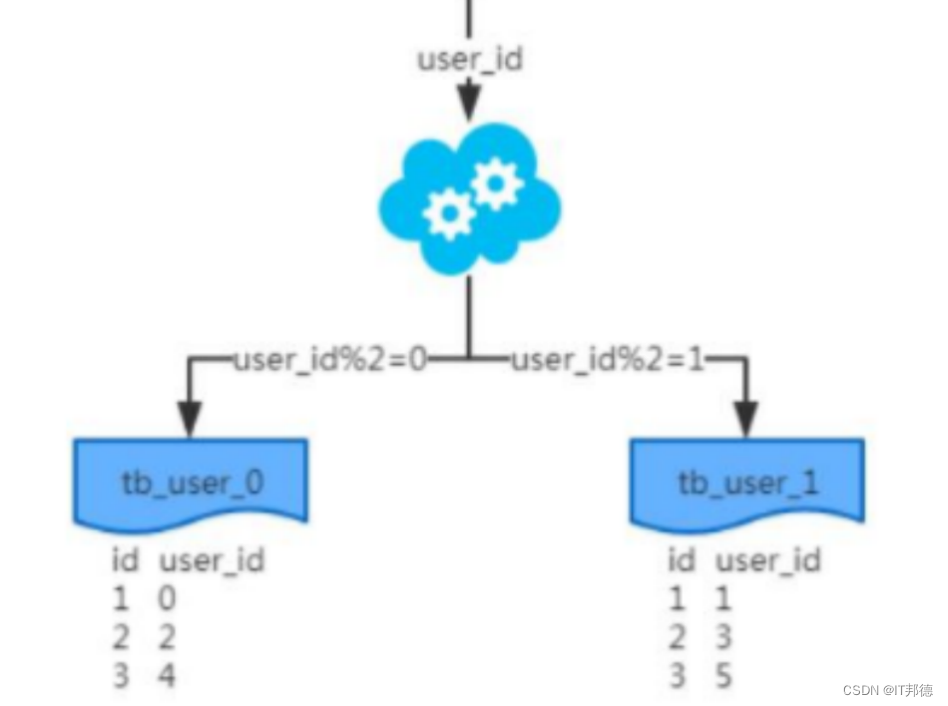
✨ 1.4 水平分表(库内分表)
概念:水平分表是以字段为依据,按照一定策略(hash、range 等),
将一个表中的数据拆分到多个表中,也称为库内分表。
结果:水平分表的结果是
①每个表的结构都一样;
②每个表的数据都不一样,没有交集;
③所有表的并集是全量数据。
📣 2.Mycat中间件
Mycat适用的场景很丰富,以下是几个典型的应用场景单纯的读写分离,此时配置最为简单,支持读写分离,主从切换分表分库,对于超过1000万的表进行分片,最大支持1000亿的单表分片多租户应用,每个应用一个库,但应用程序只连接Mycat,从而不改造程序本身,实现多租户化报表系统,借助于Mycat的分表能力,处理大规模报表的统计替代Hbase,分析大数据作为海量数据实时查询的一种简单有效方案.
📣 3.Mycat安装
2.JDK安装
Mycat 是由 Java 编写的,运行环境需要有 Java 支持。
Mycat 1.6.7.3 最低需要 JDK 1.8
yum install -y java-1.8.0-openjdk*
java -version
3.解压安装
tar -zxvf Mycat-server-1.6.7.6-release-20201126013625-linux.tar.gz
cp -r mycat /usr/local/
chmod +x /usr/local/mycat/bin/mycat
ln -s /usr/local/mycat/bin/mycat /usr/local/bin/mycat
mycat --help
#启动Mycat
mycat start
mycat status

📣 4.架构设计
✨ 4.1 server.xml配置
server.xml:定义用户以及系统相关变量,如端口等

✨ 4.2 schema.xml配置
schema.xml:是逻辑库定义和表以及分片定义的配置文件
<?xml version="1.0"?><!DOCTYPE mycat:schema SYSTEM "schema.dtd"><mycat:schema xmlns:mycat="http://io.mycat/"><schema name="TESTDB"checkSQLschema="false"sqlMaxLimit="100"><table name="t1"primaryKey="id"dataNode="dn1,dn2"rule="mod-long"></table></schema><dataNode name="dn1"dataHost="host1"database="testdb01" /><dataNode name="dn2"dataHost="host2"database="testdb02" /><dataHost name="host1"maxCon="1000"minCon="10"balance="3"writeType="0"dbType="mysql"dbDriver="native"switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="hostM1"url="172.72.0.2:3306"user="root"password="root"><readHost host="hostS1"url="172.72.0.3:3306"user="root"password="root" /><readHost host="hostS2"url="172.72.0.4:3306"user="root"password="root" /></writeHost></dataHost><dataHost name="host2"maxCon="1000"minCon="10"balance="3"writeType="0"dbType="mysql"dbDriver="native"switchType="1"slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="hostM1"url="172.72.0.2:3306"user="root"password="root"><readHost host="hostS1"url="172.72.0.3:3306"user="root"password="root" /><readHost host="hostS2"url="172.72.0.4:3306"user="root"password="root" /></writeHost></dataHost></mycat:schema>
✨ 4.3 rule.xml配置
rule.xml:定义分片规则,
按照mod-long方式,字段id分片
此处是进行了垂直分库,分到了2个库


📣 5.验证架构
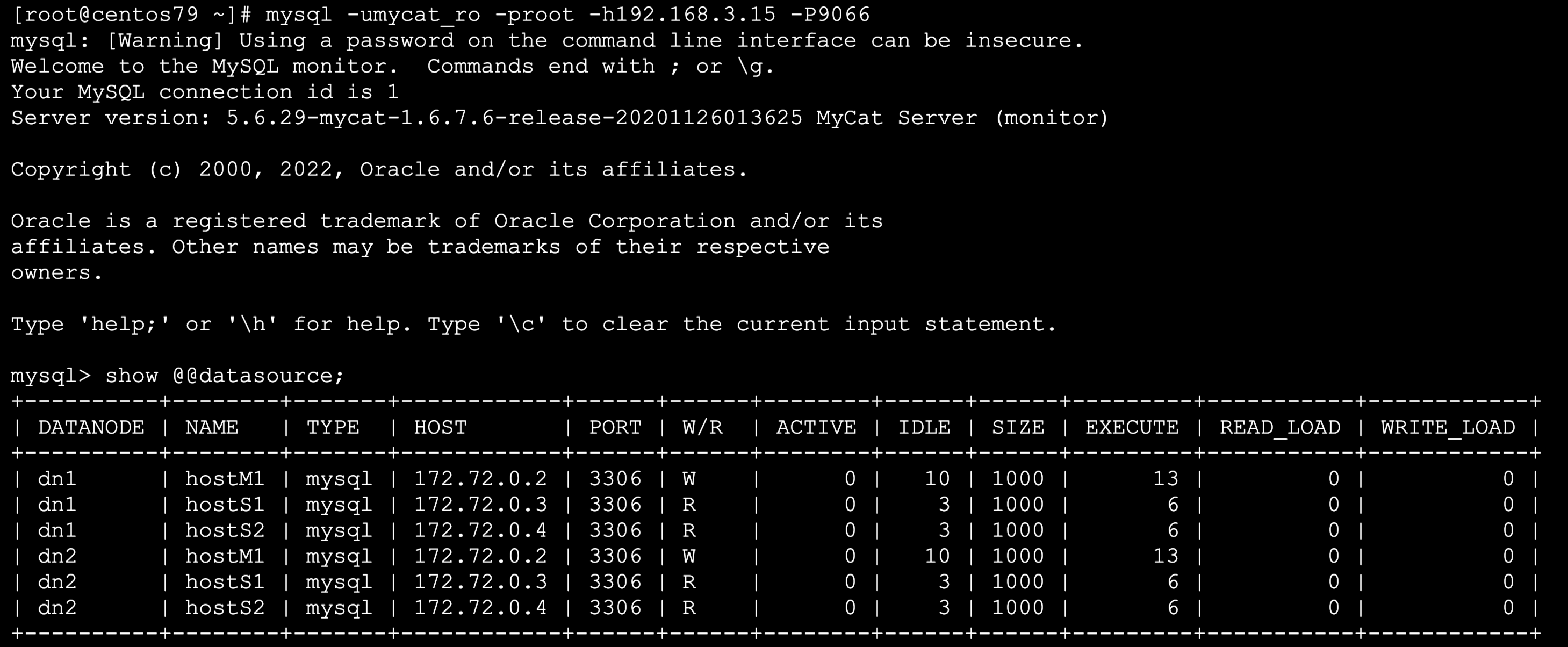
✨ 5.1 读写分离验证

测试读负载均衡
注意:root的用户和密码是配置文件里配置好的
for i in $(seq 1 10);
do mysql -uroot -proot
-h192.168.3.15 -P8066 -e
‘select @@hostname;’;
done | egrep ‘[0-9]’

✨ 5.2 分库分表验证
1.testdb01、testdb02这2套库分别创建表
create table testdb01.t1
(id int not null primary key auto_increment,
name varchar(20) not null
);
create table testdb02.t1
(id int not null primary key auto_increment,
name varchar(20) not null
);
2.Mycat登陆插入数据
mysql -uroot-proot-h192.168.3.15-P8066
use TESTDB
insert into t1(id,name) values(1,'a');
insert into t1(id,name) values(2,'b');
insert into t1(id,name) values(3,'c');
insert into t1(id,name) values(4,'d');
insert into t1(id,name) values(5,'c');
insert into t1(id,name) values(6,'d');
mysql>select * from t1;
+----+------+
|id| name |
+----+------+
|2| b ||4| d ||6| d ||1| a ||3| c ||5| c |
+----+------+
6 rows inset(0.05 sec)
3.主从库分库分表
我们已经看到数据已经分别写入2套库表了
root@master:/# mysql -uroot -proot
mysql>select * from testdb01.t1;
+----+------+
|id| name |
+----+------+
|2| b ||4| d ||6| d |
+----+------+
3 rows inset(0.00 sec)
mysql>select * from testdb02.t1;
+----+------+
|id| name |
+----+------+
|1| a ||3| c ||5| c |
+----+------+
3 rows inset(0.00 sec)
📣 6.总结
Mycat首先对 SQL 语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此 SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。这种方式把数据库的分布式从代码中解耦出来,程序员察觉不出来后台使用 Mycat 还是 MySQL
版权归原作者 IT邦德 所有, 如有侵权,请联系我们删除。