
DAY1:
感谢伟大的NV开发社区! 感谢参加本次活动的各位大佬
课程内容
一、L4T Ubuntu基础

1、操作系统篇
① 操作系统的概念

简单来说操作系统就是 翻译官 ,处于用户与计算机硬件之间,能够使用户更加方便的命令计算机硬件做事,为用户提供了 简单的硬件使用接口
功能操作系统的主要功能进程管理其工作主要是进程调度,在单用户单任务的情况下,处理器仅为一个用户的一个任务所独占, 进程管理的工作十分简单。但在多道程序或多用户的情况 下,组织多个作业或任务时,就要解决处理器的调度、 分配和回收等问题 。存储管理存储分配、存储共享、存储保护 、存储扩张。设备管理设备分配、设备传输控制 、设备独立性。文件管理文件存储空间的管理、目录管理 、文件操作管理、文件保护。作业管理负责处理用户提交的任何要求
② Linux操作系统发展历史
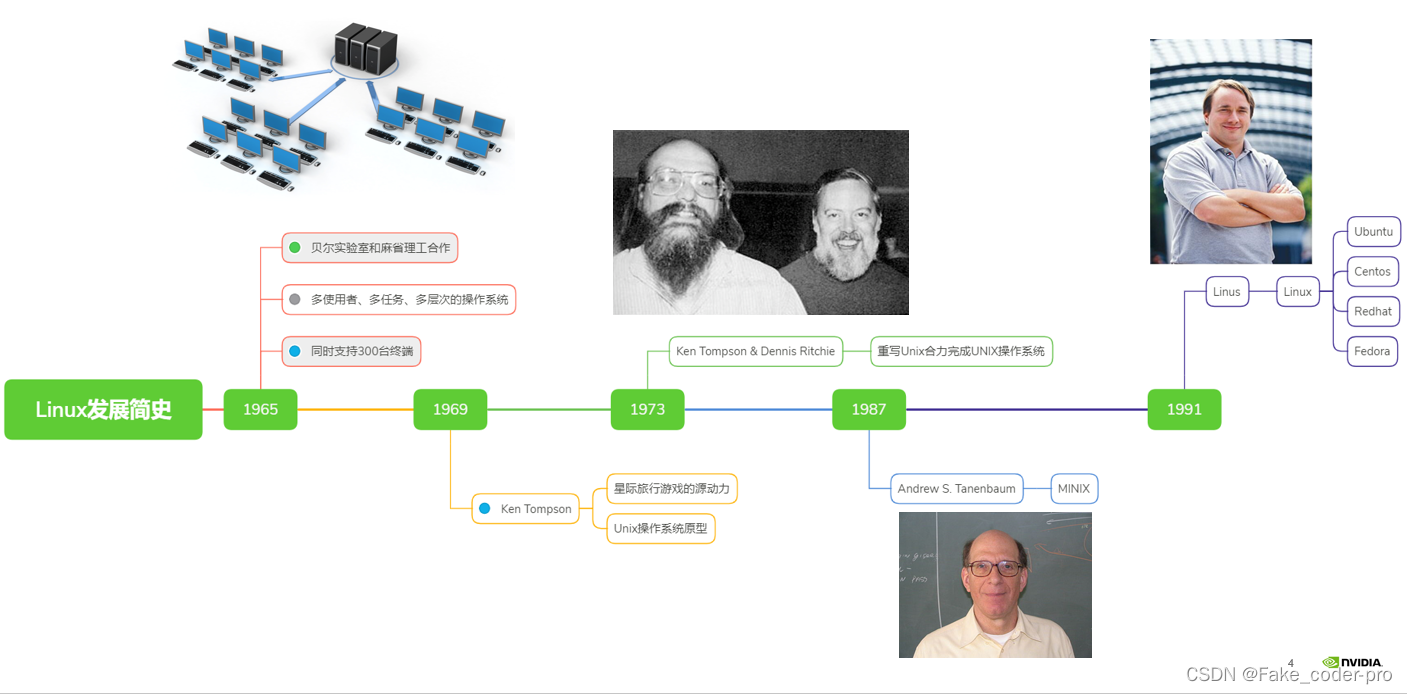
李老师提供的上图已经简单概括了发展历程,想要细细了解的同学可以听 度娘 娓娓道来
③ L4T Ubuntu(Linux for Tegra)
Tegra是集成了ARM架构CPU和NVIDIA的GPU的Soc芯片,L4T Ubuntu是Tegra的特殊定制版本
X86 Ubuntu 与 L4T Ubuntu 的区别应用定位:L4T多应用于Arm处理器的边缘设备,智能设备,开发板 ;x86多用于桌面级和服务器级需求定位:L4T基于的Arm芯片为低功耗高效率设计;x86的设计是为了追求高性能设计架构:Arm是精简指令集(RISC)架构;x86是复杂指令集(CISC)架构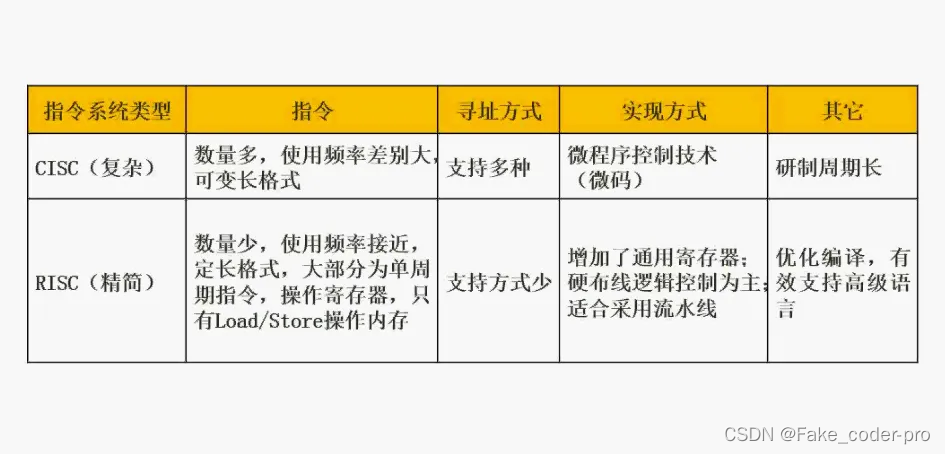
下边进入系统命令的学习
文件权限的查看 (ls -l)


左边为相关的权限 ,右边为使用到该权限的操作

文件权限的修改 (chmod)
数字法:
[root@linuxprobe ~]# ls -l anaconda-ks.cfg
-rw-------. 1 root root 1407 Jul 21 05:09 anaconda-ks.cfg
[root@linuxprobe ~]# chmod 760 anaconda-ks.cfg [root@linuxprobe ~]# ls -l anaconda-ks.cfg
-rwxrw----. 1 root root 1407 Jul 21 05:09 anaconda-ks.cfg
后边的三个数字分别代表为文件所著者,文件所属组,其它用户的权限,rwx权限对应的数字如上图所示,命令后边的数字为各对象三个权限之和
字母法:
[root@linuxcool ~]# chmod a+r anaconda-ks.cfg
为当前目录下的 anaconda-ks.cfg 所有三个对象添加 r(read)权限
Linux中的常用命令 (Linux命令手册)
命令作用cd切换目录ls显示指定工作目录下的文件及属性信息cat在终端设备上显示文件内容more分页显示文本文件内容pwd显示当前工作目录的路径touch创建空文件与修改时间戳mkdir创建目录文件rm删除文件或目录cp复制文件或目录mv移动或改名文件find根据路径和条件搜索指定文件grep强大的文本搜索工具df强大的文本搜索工具du查看文件或目录的大小ps显示进程状态top实时显示系统运行状态kill杀死进程ifconfig显示或设置网络设备参数信息ping测试主机间网络连通性ssh安全的远程连接服务器
上表只做了简单的介绍,详细信息可以查询Linux命令手册
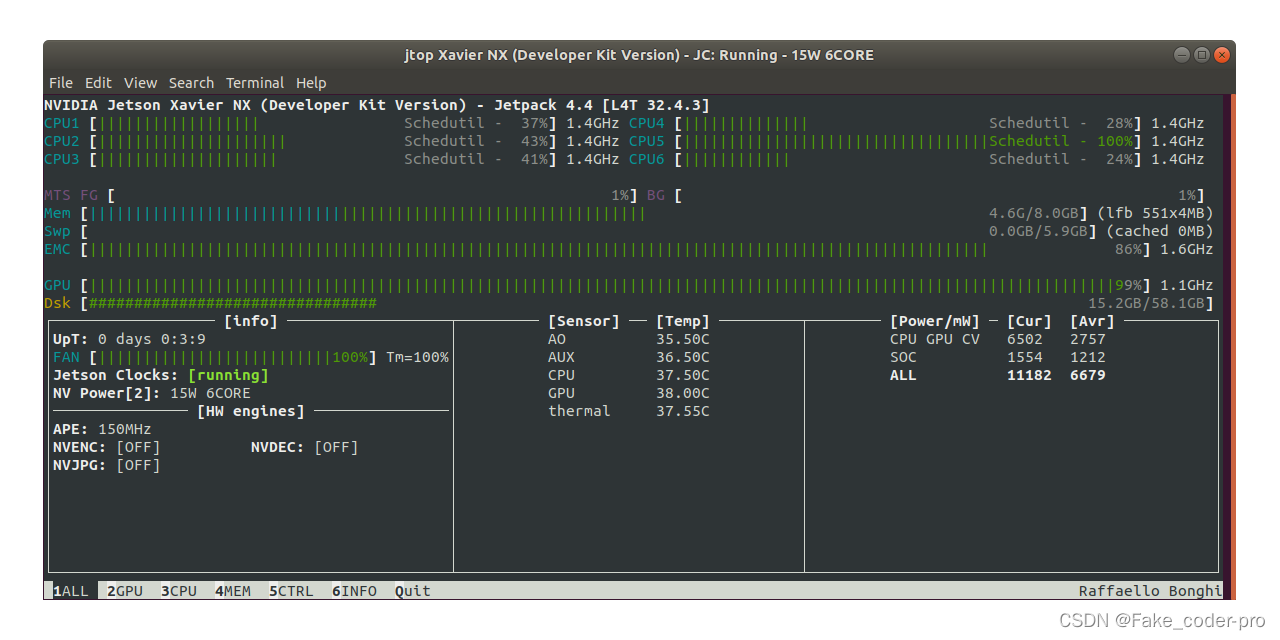
Jtop (L4T 状态查看)
安装:
sudo -H pip install jetson-stats
使用
jtop
2、Makefile编写
一个工程中的源文件不计其数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为 makefile就像一个Shell脚本一样,也可以执行操作系统的命令。

通过make命令执行,make clean可以清除缓存
二、GPU硬件架构
通过对比GPU与CPU的架构了解CUDA并行计算
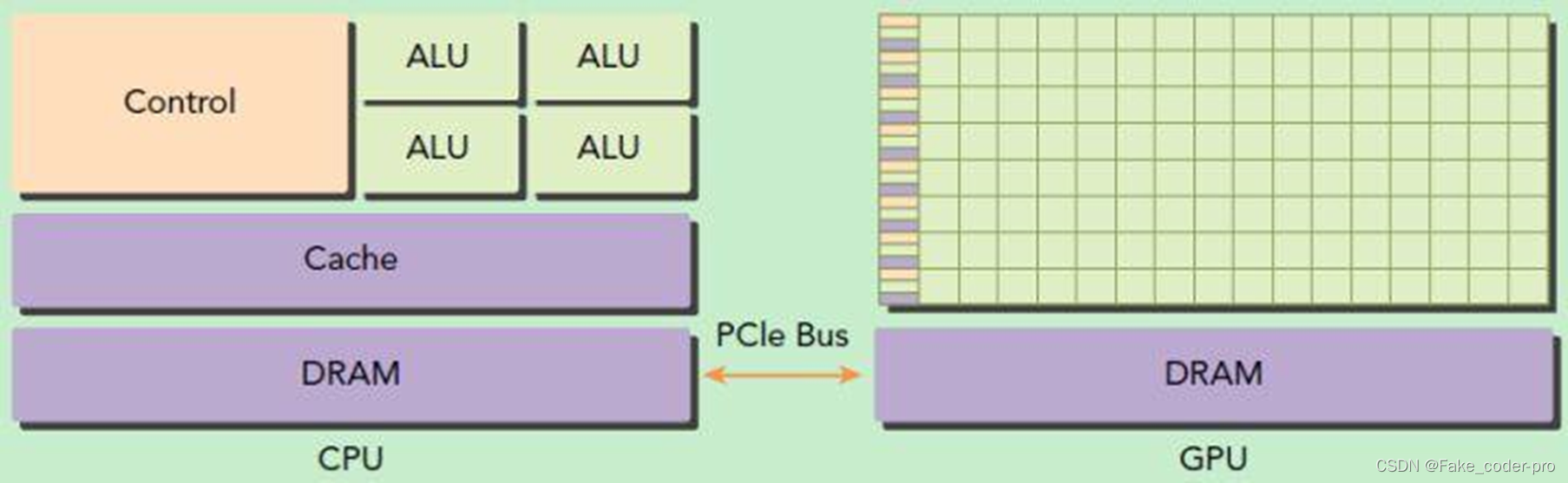
CPU架构
图中为两路CPU的架构图,通过systembus访问系统中的内存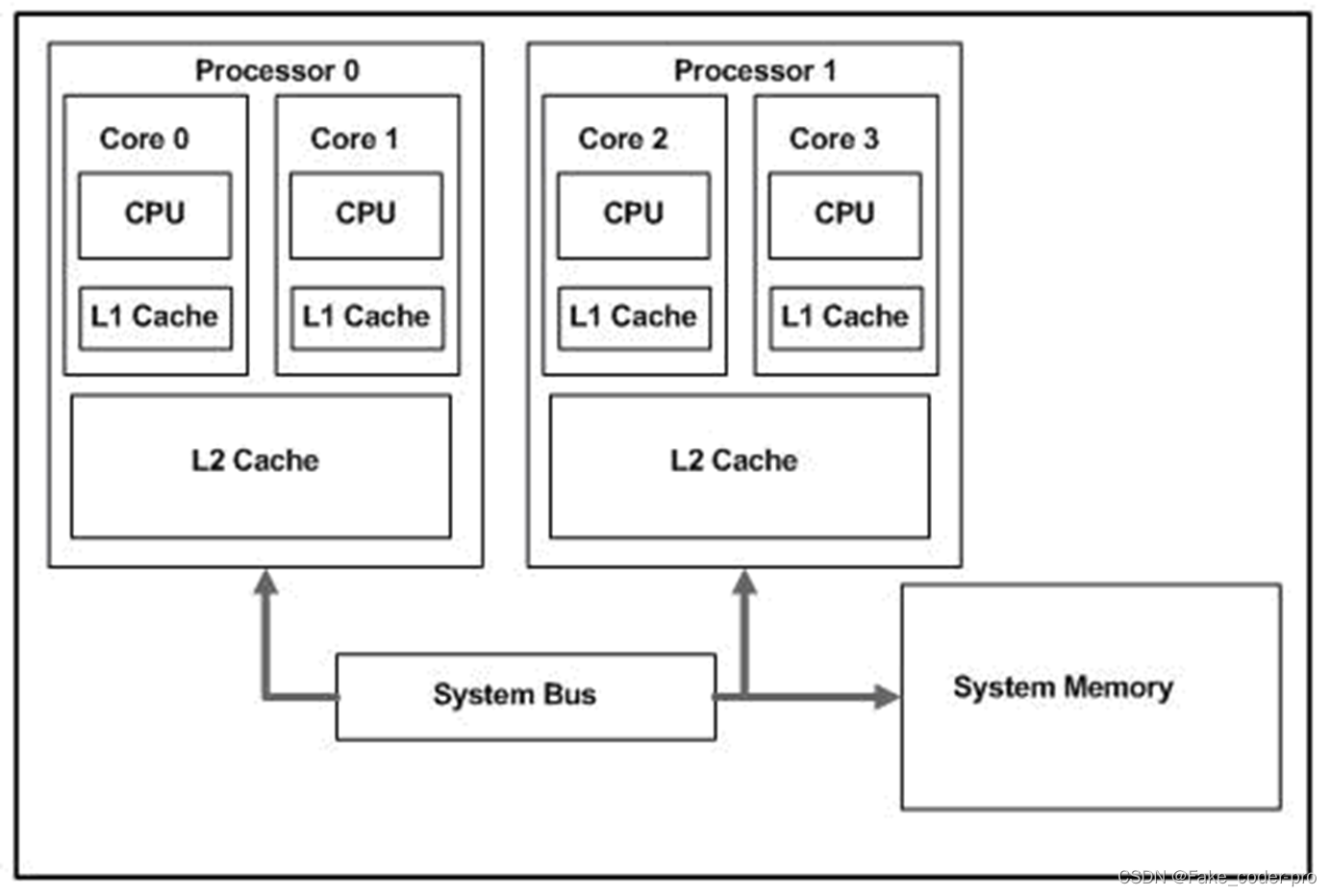
GPU架构(Fermi)

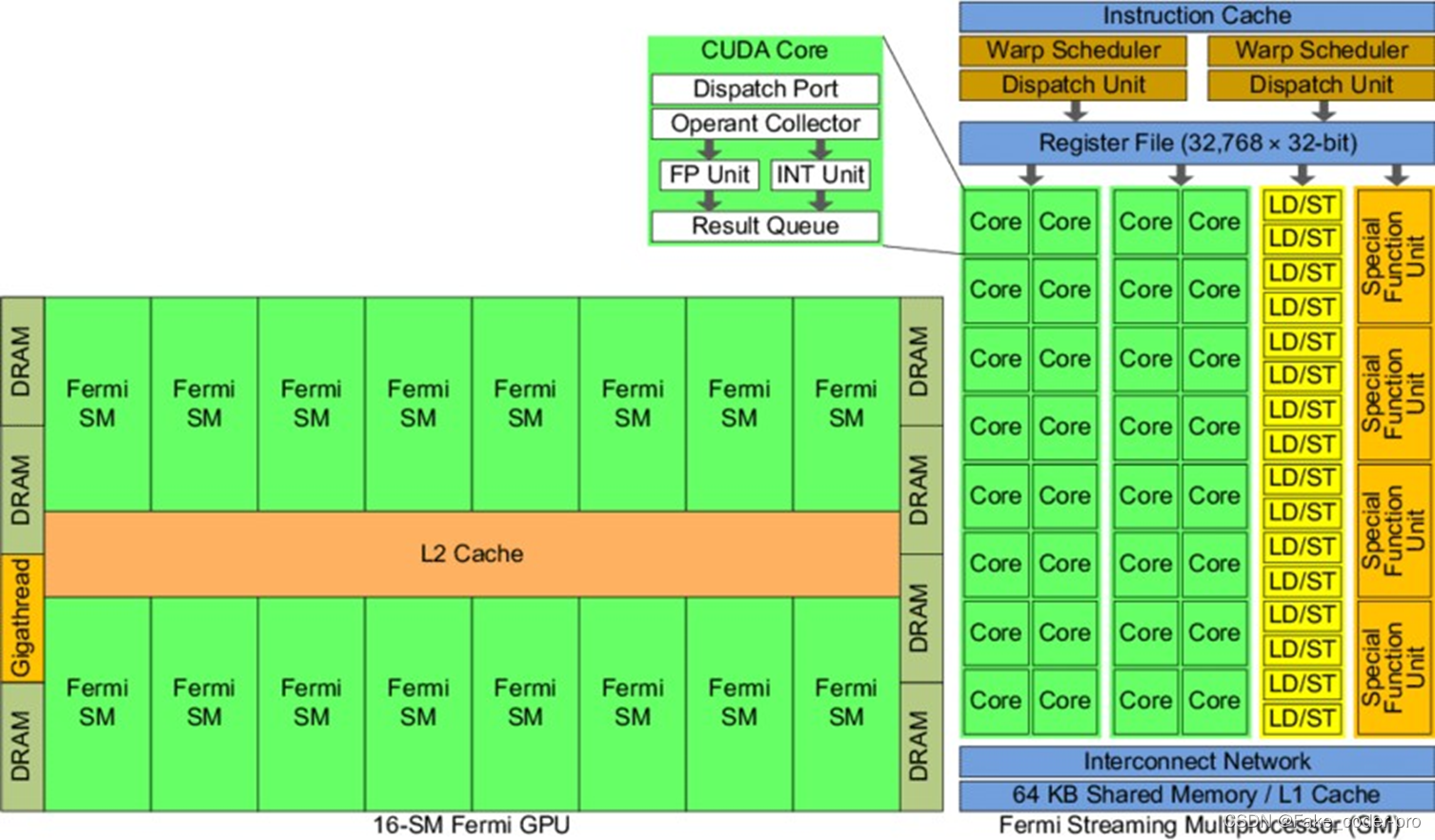
图中为比较老的Fermi架构的GPU方便理解SM
下图为新款GPU的架构图,可见随着GPU的迭代,架构发生了变化,但是都有一个特点:众核设计
,这一点使它非常适用于 高性能并行计算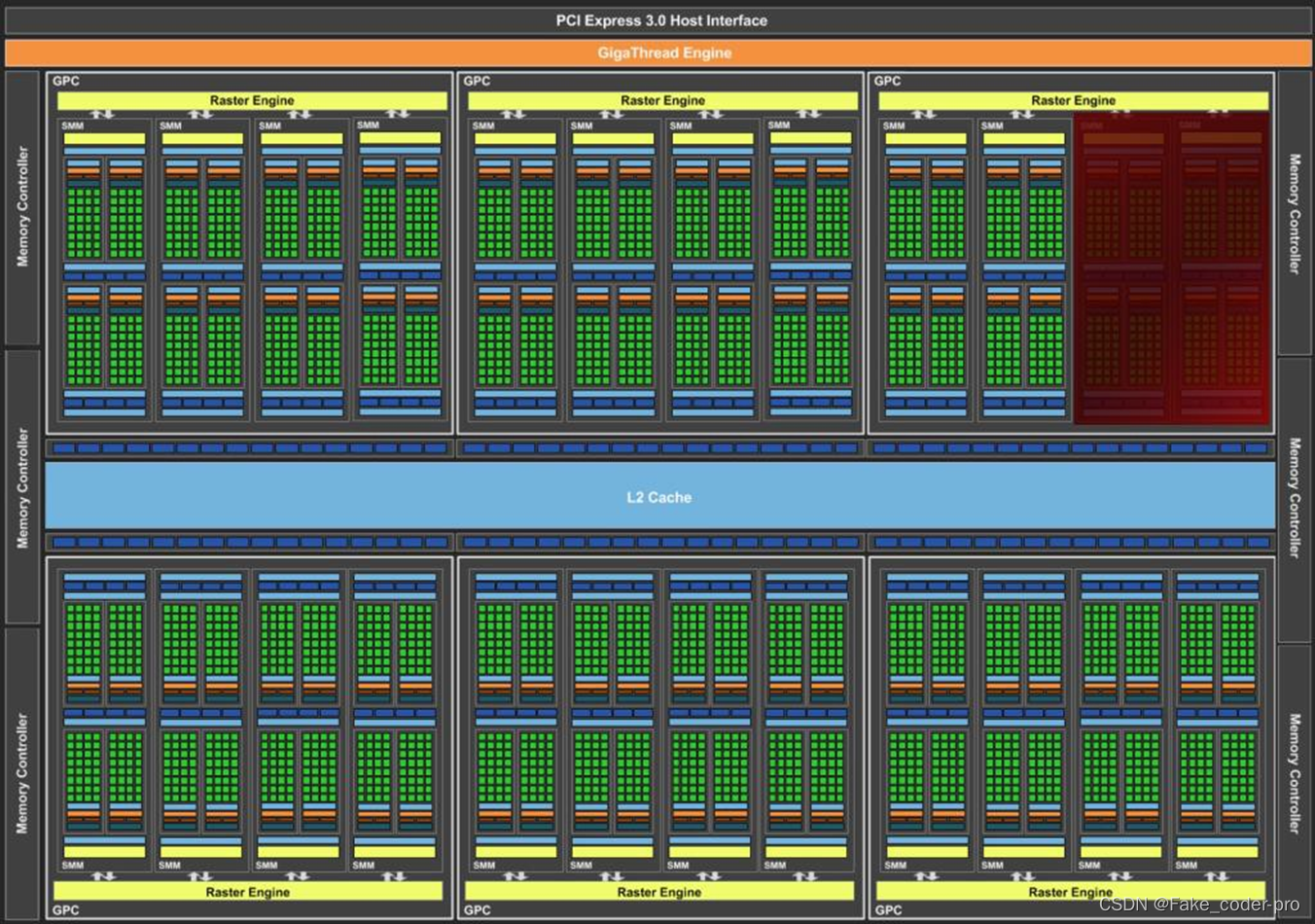
异构计算

三、初识CUDA
1、CUDA安装
扫地的小何尚(本次活动主讲师何老师)
最新CUDA环境配置教程(ubuntu 20.04 + cuda 11.7 + cuDNN 8.4)
最新CUDA环境配置(Win10 + CUDA 11.6 + VS2019)
2、CUDA程序的编写
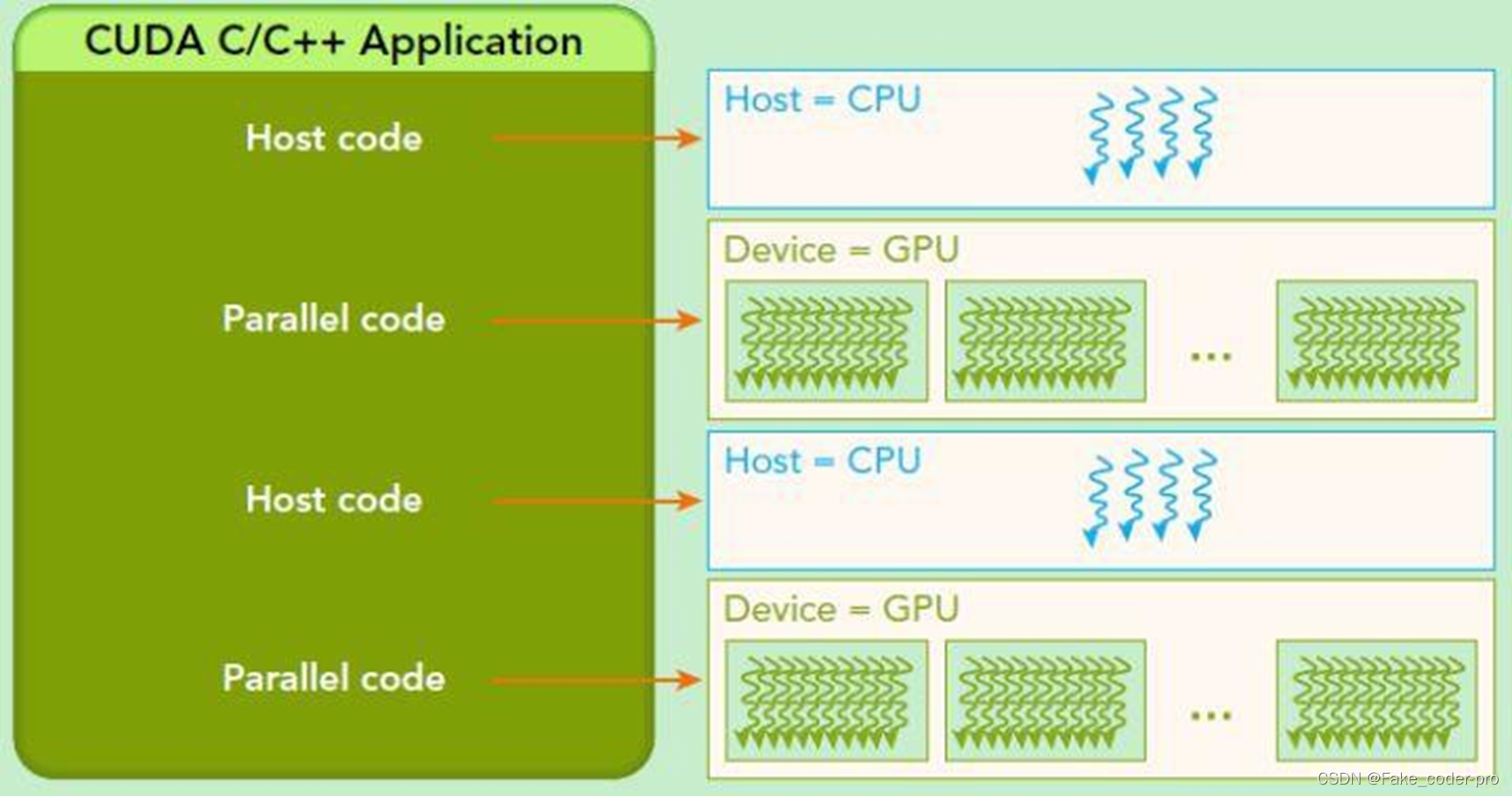
在CPU中执行串行部分,通过调用global命名空间的函数在GPU上执行并行部分
表面上来看与普通C程序最大的不同为 执行空间的说明:_global _ , _host _ , _device _


以下为普通的C代码 我们只需为我们的核函数添加执行空间标识符,并在调用时添加执行设置就可以变为CUDA代码
#include<stdio.h>voidhello_from_gpu()//例如:想要通过GPU端输出我们的hello world{printf("Hello World from the GPU!\n");}intmain(void){hello_from_gpu();cudaDeviceSynchronize();return0;}
下边为修改过后的代码
#include<stdio.h>
__global__ voidhello_from_gpu(){printf("Hello World from the GPU!\n");}intmain(void){
hello_from_gpu<<<1,1>>>();//两个参数分别为griddim和blockdim 代表网格中的线程块数量和线程块中的线程数量cudaDeviceSynchronize();return0;}
3.CUDA程序的编译与调优
①编译(nvcc)
使用方法与gcc相似,需要特别注意的是
-arch
和
-code
的设定,不加的话默认会使用当前CUDA Toolkit的默认参数,如果你的GPU版本较低,Toolkit的版本较高,可能会出现报错
root@7e7ce296e8a6:~# nvcc -arch=compute_72 -code=sm_72 hello_from_gpu.cu -o hello_from_gpu
root@7e7ce296e8a6:~# ./hello_from_gpu
Hello World from the GPU!
②调优(nvprof)
需要使用root权限所以执行时需要添加sudo来提权
nvprof --print-gpu-trace ./hello_from_gpu

End Part
第一天都为入门级别,多为介绍,本博客也简易摘录了课堂内容,想要具体了解的同学可以选择参加
CUDA On Arm
活动喔
再次感谢伟大的开发者社区
版权归原作者 Fake_coder-pro 所有, 如有侵权,请联系我们删除。