
0.简介
I3D是除了双流网络视频领域里的另一力作,本文主要的工作有2个方面,一方面就是这个标题名称,inflated,本文提供了一种方法将2D网络膨胀为3D网络,使得视频理解不需要再耗费心神去设计一个专门的网络了,而是可以直接使用图片预训练好的模型甚至是预训练的参数,另一方面是提出了一个Kinetics400数据集(后续还有扩充),大家可以在这个数据集做视频理解的预训练,然后迁移到其他数据集上,也能获得比较好的结果
1.视频理解数据集的对比
数据集yutube 8Msport 1Mucf101hmdb51数据量800万100万1.3万0.7万局限性数据量太大纯运动类,迁移性不好数据量少数据量少
在图像的领域,研究者可以在ImageNet上做预训练,然后在具体任务上做fine tune,一般都可以获得很好的结果,但是在视频领域,缺少这样的一个数据集,本文提出的Kinetics就可以解决这样的问题。Kinetics一共有400个类别,每一个类目有超过400个样本,每个样本均来自于不同的yutube视频,所以视频的多样性是很好的。而在Kinetics上预训练好的模型,在ucf101和hmdb51上都能取得非常好的结果(98%和80%)
2.视频领域里3种方式的对比
在本文发表时,视频理解领域有3种主流的方式:
a)卷积神经网络+LSTM
用卷积神经网络来对视频的每一帧抽特征,然后再过lstm,非常符合直觉,但是效果并不好
b)3D卷积神经网络
将视频切分成一个个的视频段,然后再丢给模型进行学习。3D建模导致参数量变得很大,而由于前面提到的数据集的数据量比较少,训练出来的结果也并不理想
c)双流网络
在时间和空间上分别用卷积神经网络,时间上是先抽取光流,然后用卷积神经网络来学习光流到最后动作的一个映射关系,最后再融合(late fusion,做加权平均)起来。

d)3d-fused双流神经网络
其实是b)和c)结合在一起的结果,前半部分和双流网络的结构相同,只是在最后并不是用later fusion将2个网络的结果做加权平均,而是在最后用一个小的3d卷积神经神经网络替代,做early fusion。后续也有结果证明,前面用2d cnn,后面用3d cnn的结果比较好(相比于先3d cnn+2d cnn),也比较好训练。
e) 双流I3D网络
和c)相比就是用3d cnn替代了2d cnn
3.实现细节
3.1 inflate如何实现
2d网络里2d的卷积kernel直接变成3d的卷积kernel,2d的池化层直接变成3d的池化层就好了,剩下的网络结构统统都不变,这样我们就可以选择在图像领域里用过比较好的2d网络结构(vgg,res50 etc.),得到在视频理解领域下可以使用的3d的网络结构。
3.2 bootstrap,如何使用2d预训练的模型参数初始化3d模型参数
将同一张图片反复地复制粘贴得到一个视频,假设视频的长度是N,每一帧的输入为x,将图片的2d filter在时间维度上也复制N遍,那么就得到了wNx,那么最后再进行缩放,除以N,那么就得到了wx,具体实现见gluon-cv/i3d_resnet.py at ab03ca04c588342be5cd659c3f96011c0146ac4f · dmlc/gluon-cv · GitHub
3.3 具体的实现细节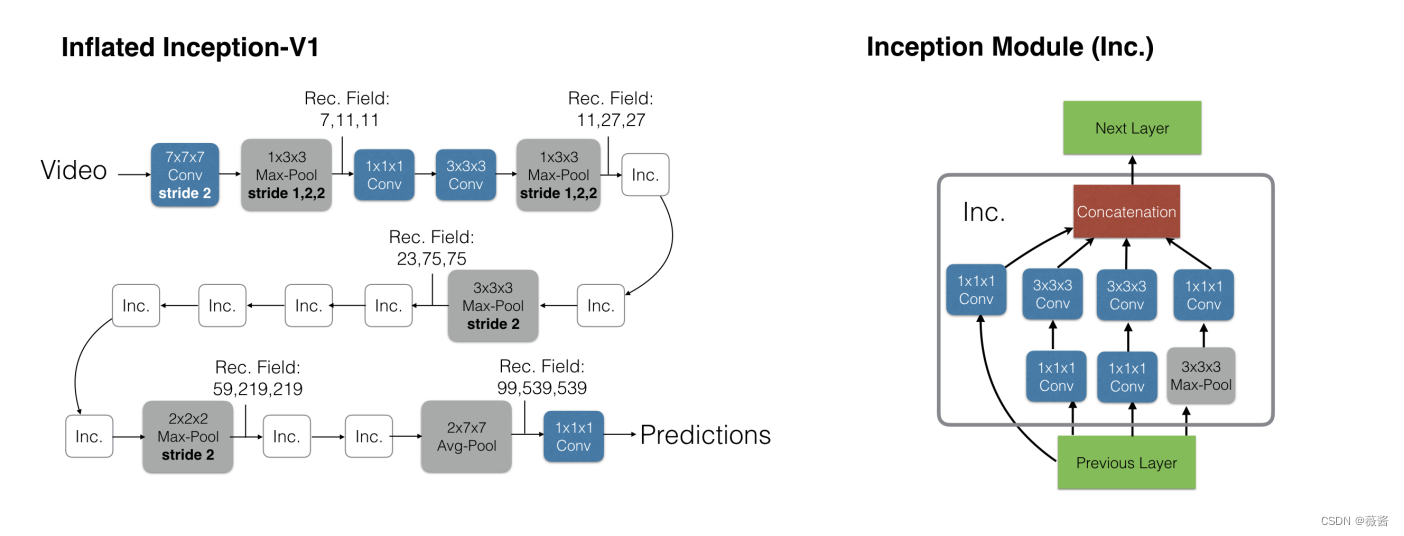
虽然前面所说的,pooling的时候 33对应的转为333,但在实现上,还是稍微有点区别的,时间维度上最好不要做下采样,所以前面2个max pooling层对应的kernel是133,stride是12*2,后续的就kernel和stride就是正常inflate了。
3.4 5种模型结构的参数对比

可以看到,3D卷积的网络参数是最多的,而ConvNet+LSTM和双流网络对应的参数就比较小。
训练:
convNet+LSTM:输入是25帧,一秒是25帧,但是lstm每5帧抽取一帧,所以25帧就需要5秒
双流网络:任选一帧,接下来的10帧去计算光流图,所以是11帧,0.4秒
测试:
为了公平比较,所有模型测试时都覆盖了整个视频10s
4.实验结果
4.1 5种模型结构的结果对比
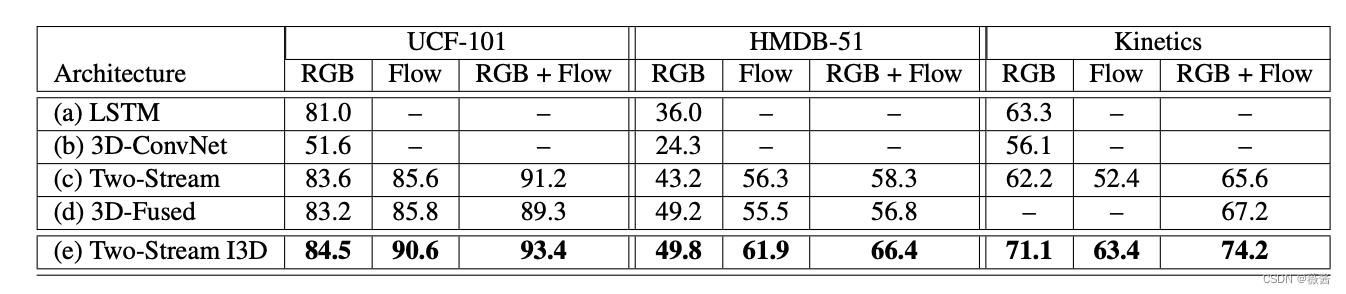
1)I3D在所有数据集上的表现最好
2)LSTM和3D-ConvNet的效果一般
3)无论算法在图像上的表现结果比光流上的好或者坏,2者结合在一起结果都有大幅度的提升
4.2 使用Kinetics数据集迁移学习的效果
original:使用ucf-101的数据预训练和测试
fix:冻住骨干网络在Kinetics数据集上训练
full-ft:整个网络在Kinetics数据集上微调
可以看到整个网络在Kinetics数据集上微调获得的效果最好
更多模型的对比:
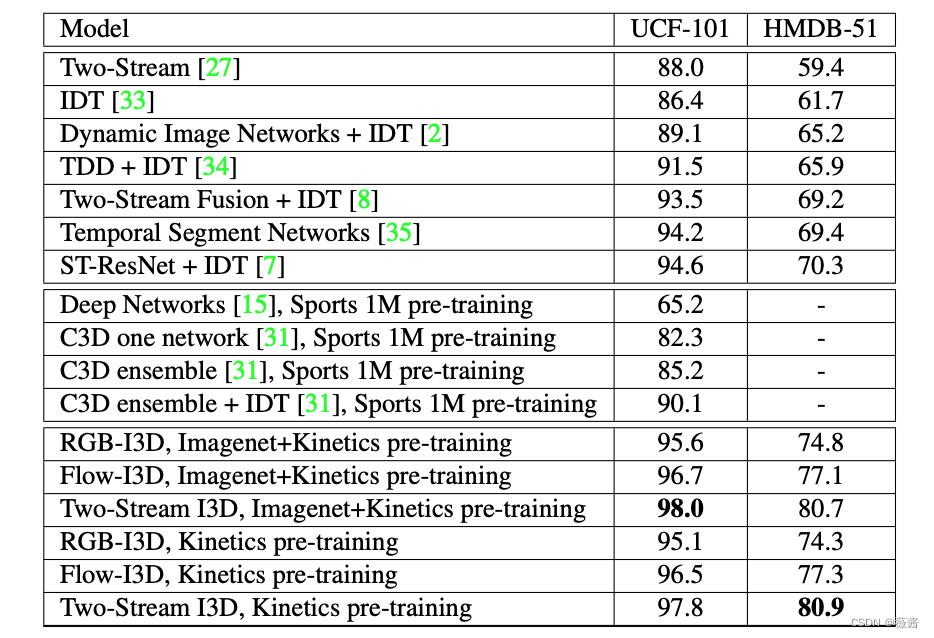
可以看到I3D效果都是非常好的,即便是在只使用Kinetics数据集进行预训练的时候,效果也是相当亮眼的。
后续还诞生了很多基于I3D算法的研究,比如 NonLocal Network,在I3D后面加上了self attention,可以说是开启了3D-conv研究的新潮流。
论文地址:https://arxiv.org/abs/1705.07750
参考:I3D 论文精读【论文精读】_哔哩哔哩_bilibili
版权归原作者 薇酱 所有, 如有侵权,请联系我们删除。