
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
“神经网络是具有相互连接的节点的计算系统,其工作原理与人类大脑中的神经元非常相似。”——SAS
神经元是一个密集的系统中的节点,它接收输入的数字并输出更多的数字。如果我们仔细观察一个密集的神经网络,就会发现神经元是相互连接的,如下图所示。
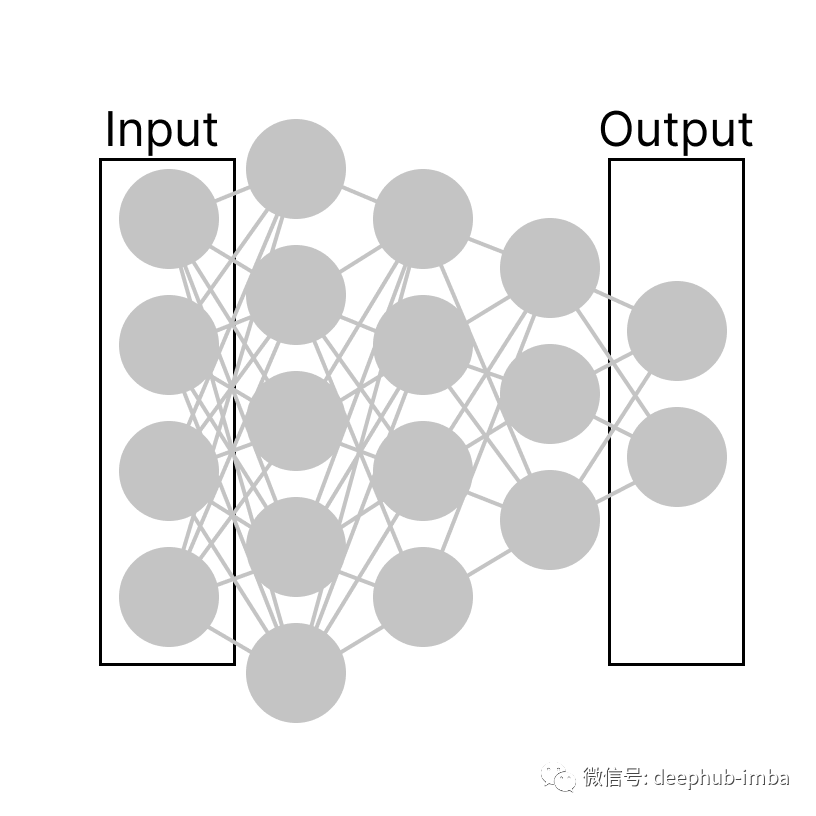
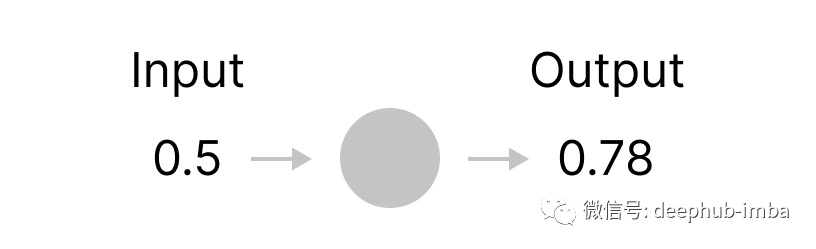
如果进一步放大,我们可以准确地看到每个神经元的作用。例如,一个神经元可以被看作是一个盒子,它吃掉一个数字并抛出另一个计算机数字作为输出。
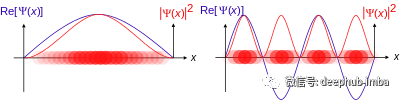
这种神经网络的限制是神经元只能输出一个具体的数字。并且每个数字都有一定的置信度。在物理学中可以找到一个很好的类比。当前的神经网络架构可以被视为具有特定结果的机械物理过程,但我们希望查看多个结果。例如,在量子力学中,概率波函数表示在特定点找到粒子的概率。这个概念可以在下图中看到。
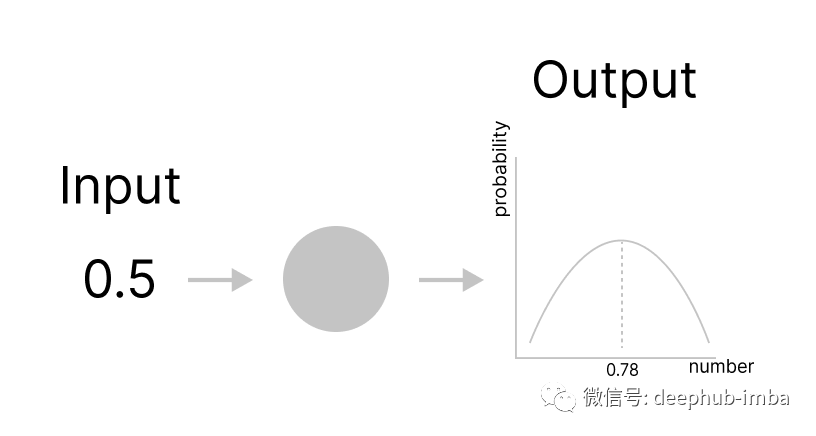
我将尝试在下面构建的神经网络中模仿这个概念,允许神经元输出一个概率函数,该函数将输出神经元最置信度最高的值。
Tensorflow 是用于构建自定义神经网络层的库,我们将在本项目中使用它并通过 Keras API 创建一个自定义层,该层可以轻松集成到我们选择的神经网络架构中。我将这一层称为 probability distribution function neural network(概率分布函数神经网络)。
我们可以使用以下结构在 TensorFlow 中构建神经网络:
class PDNN(tf.keras.layers.Layer):
def __init__(self, num_outputs):
...
def build(self, input_shape):
...
def call(self, inputs):
...
该python类具有三个主要函数:
init ,进行所有与输入无关的初始
build,处理输入张量的形状并完成其余的初始化工
call,在那里进行前向传播
波函数是复值的。为了找到概率密度,我们需要找到波函数的平方模数,这就是我们要在自定义层中模拟的行为。首先创建一个复数值部分,然后找到它的平方模数。
class PDNN(layers.Layer):
def __init__(self, num_outputs, PDFS):
super(PDNN, self).__init__()
self.num_outputs = num_outputs
self.PDFS = PDFS
def build(self, input_shape):
self.w = self.add_weight(
shape=[self.PDFS,self.num_outputs,1],
name="w",
trainable=True,
)
self.b = self.add_weight(
shape=[self.PDFS,self.num_outputs,1],
name="b",
trainable=True,
)
self.m = self.add_weight(
shape=[1,self.PDFS,self.num_outputs,1],
name="m",
trainable=True,
)
def call(self, input_tensor):
pi = tf.constant(math.pi)
e = tf.constant(math.e)
space = tf.constant([value/10 for value in range(1,1000 )], dtype=tf.float32)
space = tf.reshape(space, [1,999])
space = tf.tile(space, [self.num_outputs,1])
space = tf.reshape(space, [1,self.num_outputs,999])
space = tf.tile(space, [self.PDFS,1,1])
input_tensor = tf.reshape(input_tensor, [1,self.num_outputs])
input_tensor = tf.tile(input_tensor, [self.PDFS,1])
input_tensor = tf.reshape(input_tensor, [self.PDFS,self.num_outputs,1])
input_tensor = self.w*input_tensor+self.b
pdf = tf.complex(tf.math.cos(input_tensor*space), tf.math.sin(input_tensor*space))pdf = tf.reshape(pdf, [1,self.PDFS,self.num_outputs,999])
pdf = pdf*tf.complex(self.m, self.m)
pdf = tf.math.reduce_sum(pdf, axis=1, keepdims=True)
pdf = tf.reshape(pdf, [1,self.num_outputs,999])
pdf = tf.abs(pdf)
return pdf
我们可以用上面新创建的自定义层来构建网络。
inp = L.Input(shape=(7,))
x = PDNN(7, n_pdfs)(inp)
x = L.Lambda(lambda x: tf.math.pow(x,2))(x)
x = L.Lambda(lambda x: tf.math.top_k(x,k=5)[1]/10)(x)
x = L.Flatten()(x)
x = L.Dense(32, activation='relu')(x)
y = PDNN(7, n_pdfs)(inp)
y = L.Lambda(lambda x: tf.math.pow(x,2))(y)
y = L.Lambda(lambda x: tf.math.top_k(x,k=5)[1]/10)(y)
y = L.Flatten()(y)
y = L.Dense(64, activation='relu')(y)
z = PDNN(7, n_pdfs)(inp)
z = L.Lambda(lambda x: tf.math.pow(x,2))(z)
z = L.Lambda(lambda x: tf.math.top_k(x,k=5)[1]/10)(z)
z = L.Flatten()(z)
z = L.Dense(64, activation='relu')(z)
w = PDNN(7, n_pdfs)(inp)
w = L.Lambda(lambda x: tf.math.pow(x,2))(w)
w = L.Lambda(lambda x: tf.math.top_k(x,k=5)[1]/10)(w)
w = L.Flatten()(w)
w = L.Dense(64, activation='relu')(w)
m = PDNN(7, n_pdfs)(inp)
m = L.Lambda(lambda x: tf.math.pow(x,2))(m)
m = L.Lambda(lambda x: tf.math.top_k(x,k=5)[1]/10)(m)
m = L.Flatten()(m)
m = L.Dense(64, activation='relu')(m)
n = PDNN(7, n_pdfs)(inp)
n = L.Lambda(lambda x: tf.math.pow(x,2))(n)
n = L.Lambda(lambda x: tf.math.top_k(x,k=5)[1]/10)(n)
n = L.Flatten()(n)
n = L.Dense(64, activation='relu')(n)
x = L.concatenate([x,y,z,w, m, n])
x = L.Dense(64, activation='relu')(x)
x = L.Dense(32, activation='relu')(x)
out = L.Dense(1)(x)
model = Model(inp, out)
model.compile(optimizer=Adam(learning_rate=0.001), loss='mae')
我们的模型可视化如下
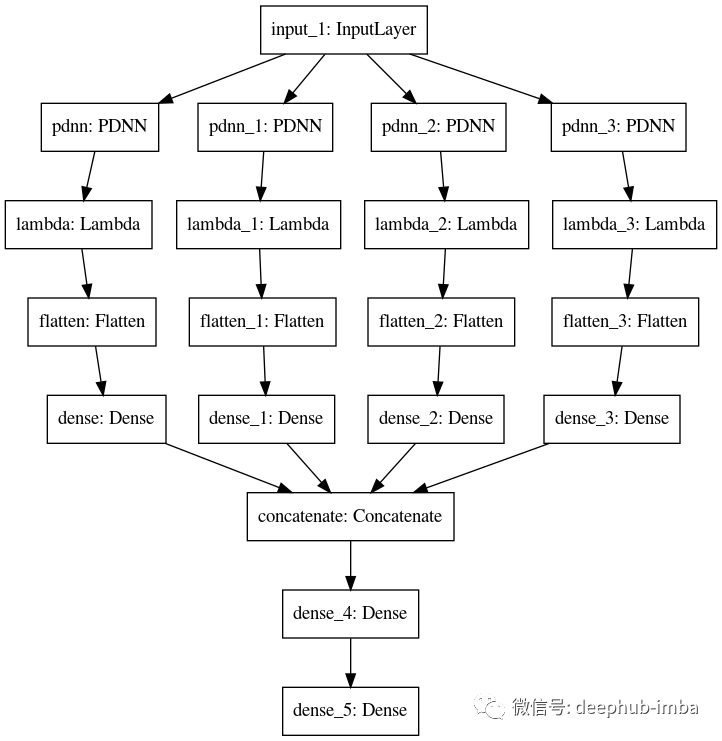
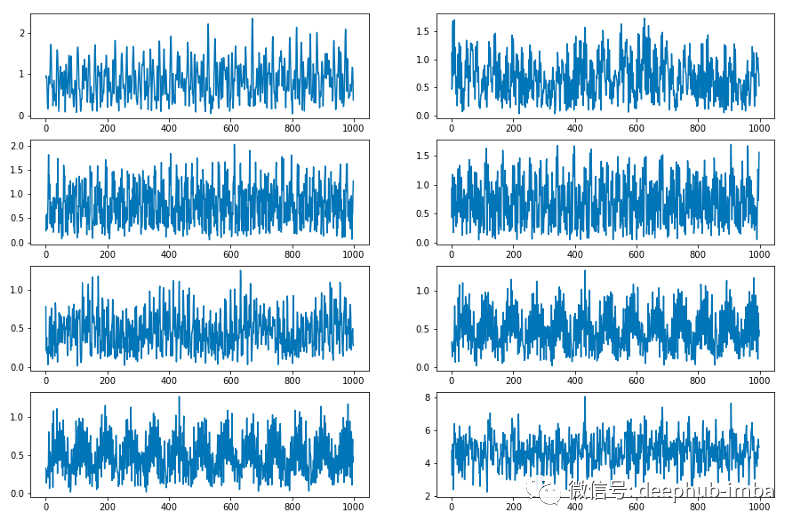
现在,让我们尝试在一个基本的时间序列数据集上训练我们的模型,并看看它与ARIMA等经典统计模型的比较情况。训练的完整代码在文章的最后部分提供。在测试结果之前,我们可以先看啊可能由PDNN层生成的波函数的峰值。
看起来不错!在100轮训练之后,该模型获得了12.07的RMSE得分。让我们来看看预测。
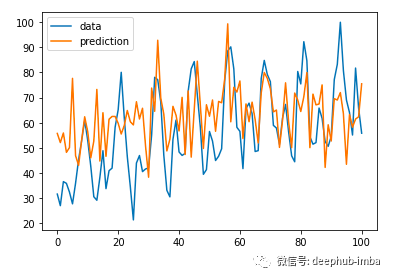
在使用ARIMA模型的RMSE为14.96!这意味着我们的模型在很大程度上优于经典模型。
PDNN层在提高神经网络性能方面似乎具有相当大的潜力,因为它可以同时考虑多种可能的结果,而不必选择一个特定的结果。与时间序列预测示例中的ARIMA模型相比,这个想法的实际结果要好很多。
PDNN代码:https://github.com/DavidIstrati/PDNN
本文训练代码:https://www.kaggle.com/davidistrati/pdnn-demo/notebook
作者:Istrati David
喜欢就关注一下吧:
点个 在看 你最好看!********** **********