
前言
ChatGLM3-6B 是 OpenAI 推出的一款强大的自然语言处理模型,它在前两代模型的基础上进行了优化和改进,具有更高的性能和更广泛的应用场景。本文将从技术角度对 ChatGLM3-6B 进行详细介绍,包括其特点、资源评估、购买云服务器、git拉取GLM、pip安装依赖、运行测试以及本地部署安装等方面的内容。希望通过本文的介绍,能够帮助大家更好地理解和使用 ChatGLM3-6B 模型。
一、ChatGLM3-6B 简介说明
ChatGLM3-6B 是一款基于深度学习的自然语言处理模型,它具有以下特点:
1)更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,* ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能*。
2)更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式 ,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
3)更全面的开源序列: 除了对话模型 ChatGLM3-6B** 外,还开源了**基础模型 ChatGLM3-6B-Base 、长文本对话模型 ChatGLM3-6B-32K 和进一步强化了对于长文本理解能力的 ChatGLM3-6B-128K。
******二、ChatGLM3-6B **资源评估
初步粗略估算:
1)如果精度为FP32, 需要GPU显存大概 24G左右,如果考虑其他因素再加一点32G左右。
2)如果精度为FP16, 需要GPU显存大概 12G左右,如果考虑其他因素再加一点16G左右。
3)如果量化为int8, 需要GPU显存大概 6G左右,如果考虑其他因素再加一点8G左右。
由于默认情况下,ChatGLM3-6B模型以 FP16 精度加载,因此大概需要16G左右;
如果显存不够需要修改源码进行量化处理,源码参考如下:
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
.quantize(8).cuda()
三、购买云服务器
在AutoDL租一个按量收费的服务器;大家可自行选择合适的云平台,购买云服务器
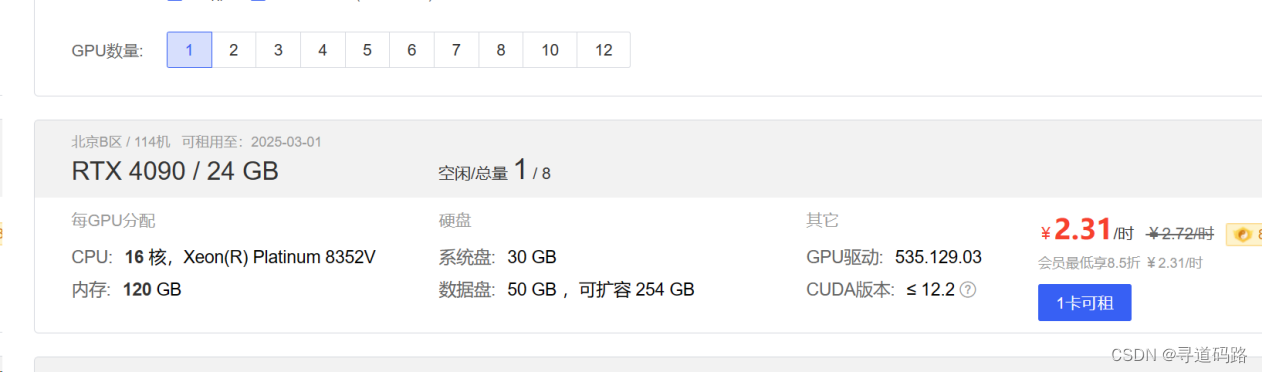
选择最新的Pytorch基础镜像(核心需要pytorch库)

登录云服务器
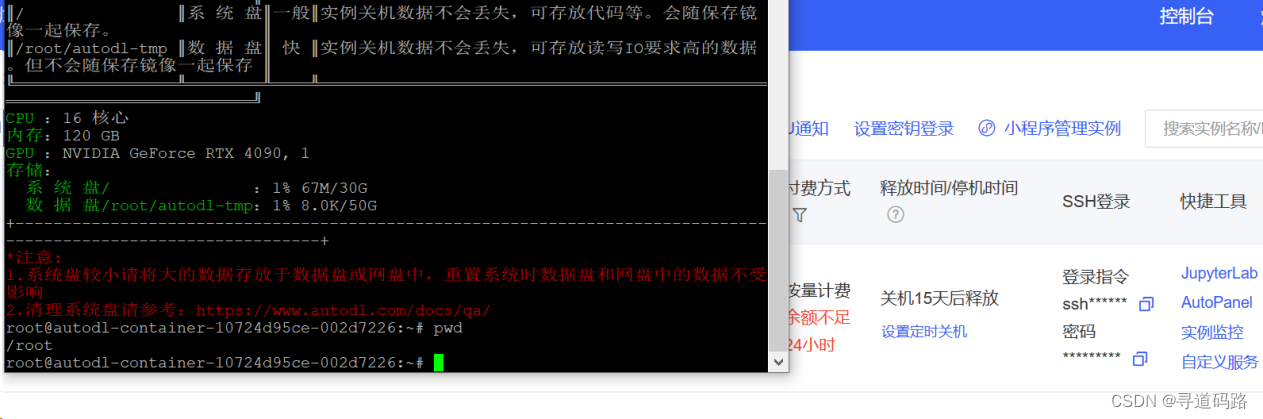
学术加速一波,执行命令:source /etc/network_turbo
四、git拉取GLM
1)下载GLM
git clone https://github.com/THUDM/ChatGLM3

2)下载完成后进入ChatGLM3目录
cd ChatGLM3
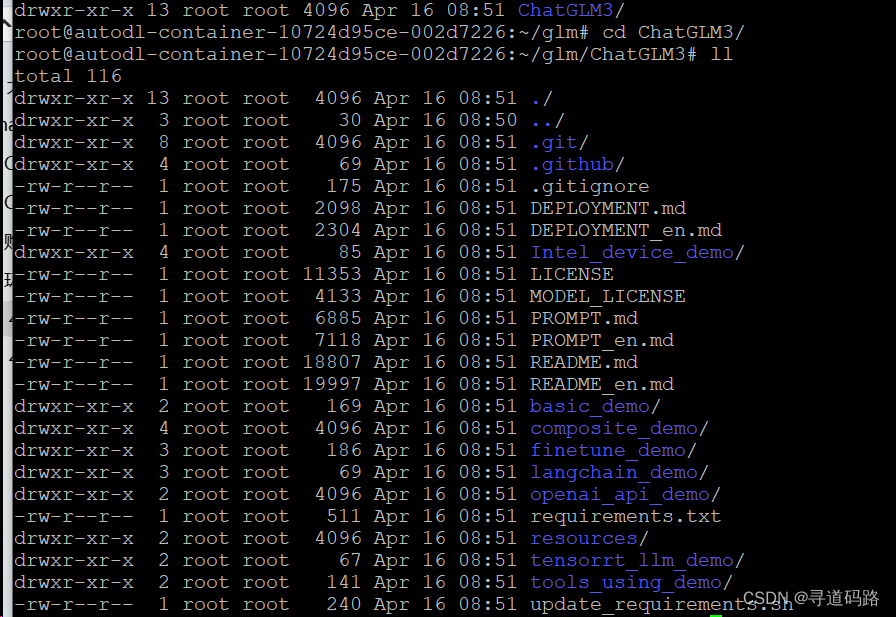
五、pip安装依赖****
执行下面的pip命令,安装依赖(核心需要pytorch库)
pip install -r requirements.txt
安装过程中提示tensorboard依赖的protobuf版比较低,服务器中protobuf版本过高

有两种方案:
1)降低protobuf的版本到满足tensorboard 2.15.1的要求。你可以使用pip命令来卸载当前的protobuf并安装一个兼容的版本。例如:
pip uninstall protobuf
pip install protobuf==4.24
2)升级你的tensorboard版本到一个与当前protobuf版本兼容的版本。你需要查找最新的tensorboard版本,然后使用pip命令来安装。例如:
pip install --upgrade tensorboard
经尝试采用第一种失败后,改用方案二执行成功。
再重新执行:pip install -r requirements.txt,执行成功

六、运行测试
进入basic_demo目录,查看测试的demo
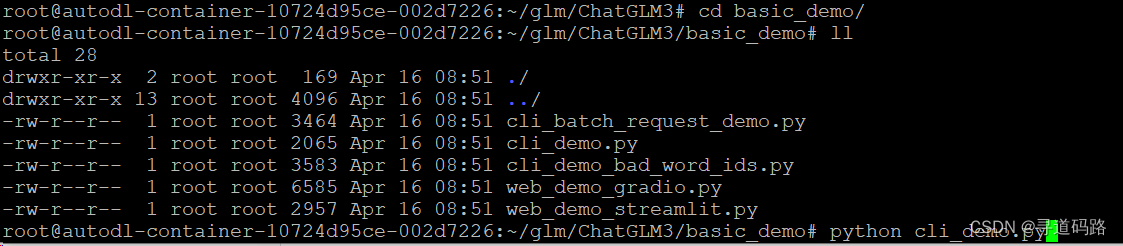
执行测试demo : python cli_demo.py
这个目录放了各种测试用的demo,为了方便使用,本次主要采用命令行客户端的方式测试
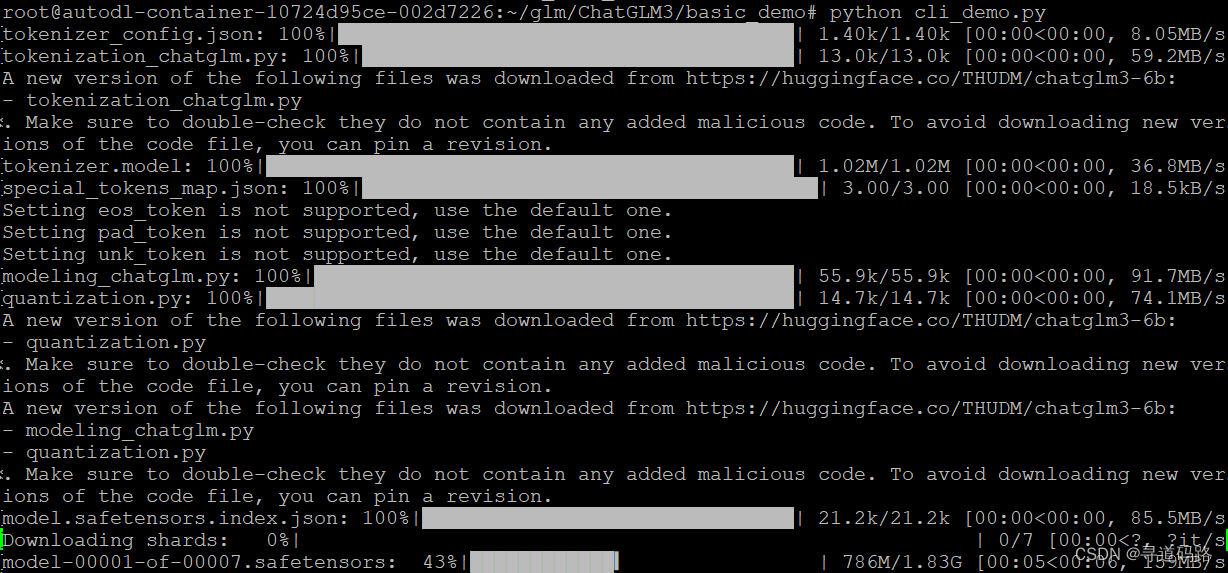
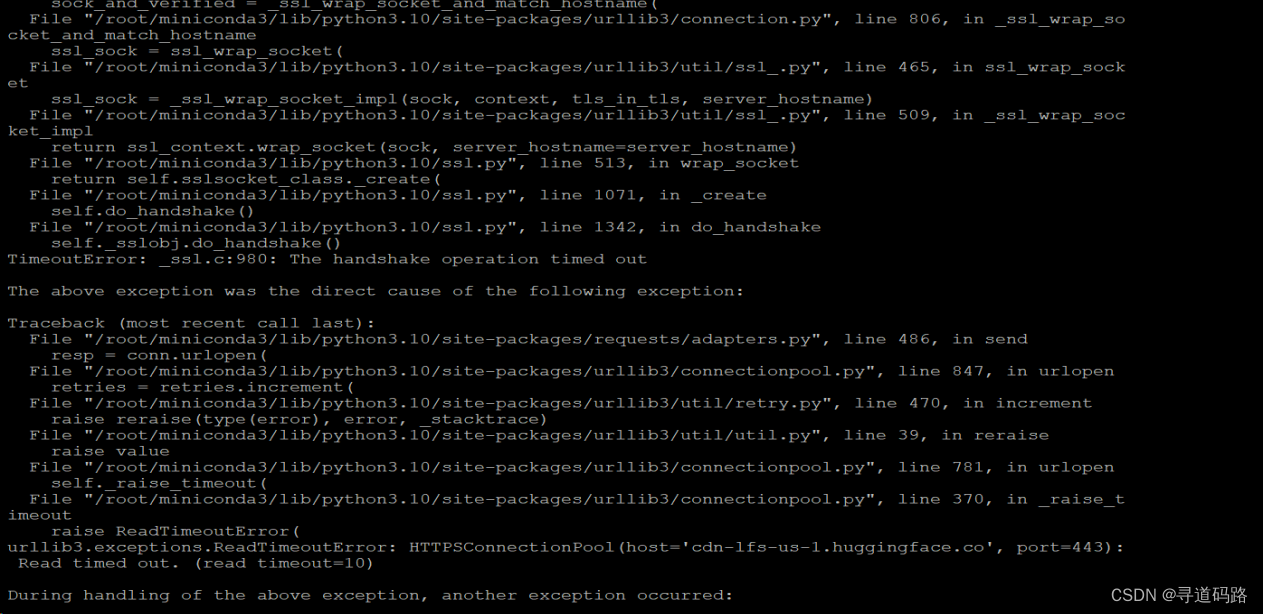
第一次执行时,中途链接huggingface超时失败,惊出一身冷汗
第二次执行后执行成功(终于出现了期待已久的画面)

赶紧测一波 ,
测试效果赶紧很不错,精准度方面也比较高;另外,感受最明显的特点就是,“速度快”,
基本上在我提问完后,ChatGLM秒回结果,和调用OpenAI在线API相比,直接原地起飞。

七、本地部署安装
由于本地电脑GPU资源不足,无法实操;主要以云服务器部署为主;本地安装方式仅做记录备用
****1. Python环境准备
建议安装anaconda(里面集成了很多科学计算的库集成了jupyter等在线编译工具)
网站会自动识别电脑版本匹配工具
****2. GPU版PyTorch安装
PyTorch是一个开源的Python机器学习库,基于Torch;它提供了必要的模型管理和训练工具,以及分布式训练能力、易用性、以及与其他工具的良好集成;用于自然语言处理等应用程序。PyTorch既可以看作加入了GPU支持的numpy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络。
ChatGLM3-6B运行过程需要借助PyTorch来完成相关计算。
需要确认是否已经安装2.0版本及以上的GPU版本的PyTorch;
1)验证是否安装
#导入模块
import torch
#查看Pytorch的版本
torch.__version__
#测试当前的touch版本与当前服务器的CUDA是否兼容
print(torch.cuda.is_available())
2)安装
#卸载当前pytorch版本
pip uninstall torch torchvision torchaudio
#安装新的pytorch版本
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
******3. **验证PyTorch与CUDA是否兼容
CUDA是Compute Unified Device Architecture的缩写,它是由NVIDIA公司推出的一个并行计算平台和应用程序接口(API),允许软件开发者和软件工程师使用NVIDIA的图形处理单元(GPU)进行通用计算。简单来说,CUDA让开发者能够利用NVIDIA GPU强大的计算能力来加速除了图形处理以外的科学和工程计算,从而提供比传统CPU更高效的性能。
1)验证是否兼容
#导入模块
import torch
#测试当前的touch版本与当前服务器的CUDA是否兼容
print(torch.cuda.is_available())
2)重新安装
在CUDA官网下载最新版CUDA toolkit(CUDA安装工具)进行安装或者更新至12.1版,
3)重新验证
4. 拉取ChatGLM3工程
创建一个目录使用GIT拉取工程代码
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
下载完成后,能够在你的文件目录下看到完整的ChatGLM3安装文件
******5. 安装ChatGLM3-6B项目依赖库 ******
pip install -r requirements.txt
安装过程若出现类似typing-extensions或fastapi等非核心库不兼容性报错,并不会影响最终模型运行,不用进行额外处理。完成了相关依赖库的安装之后,即可尝试进行模型调用了。
6. 运行测试
测试方式1:
python cli_demo.py
测试方式2:
streamlit run web_demo2.py
总结
本文从技术角度对 ChatGLM3-6B 进行了深入介绍,包括其特点、资源评估、购买云服务器、git 拉取 GLM、pip 安装依赖、运行测试以及本地部署安装等方面的内容。希望通过本文的介绍,能够帮助大家更好地理解和使用 ChatGLM3-6B 模型。
文章若有瑕疵,恳请不吝赐教;若有所触动或助益,还望各位老铁多多关注并给予支持。
版权归原作者 寻道AI小兵 所有, 如有侵权,请联系我们删除。