
在CPU上进行完整版yolov5项目跟练记录
一、yolov5原理解析
本节内容参考来源:1、2、3
1. 目标检测任务说明
目标检测指的是:输入图像或视频,要从图像中获取需要的物体类型以及位置等信息。
主要的检测性能指标如下图所示:
1.1 基础检测精度指标:
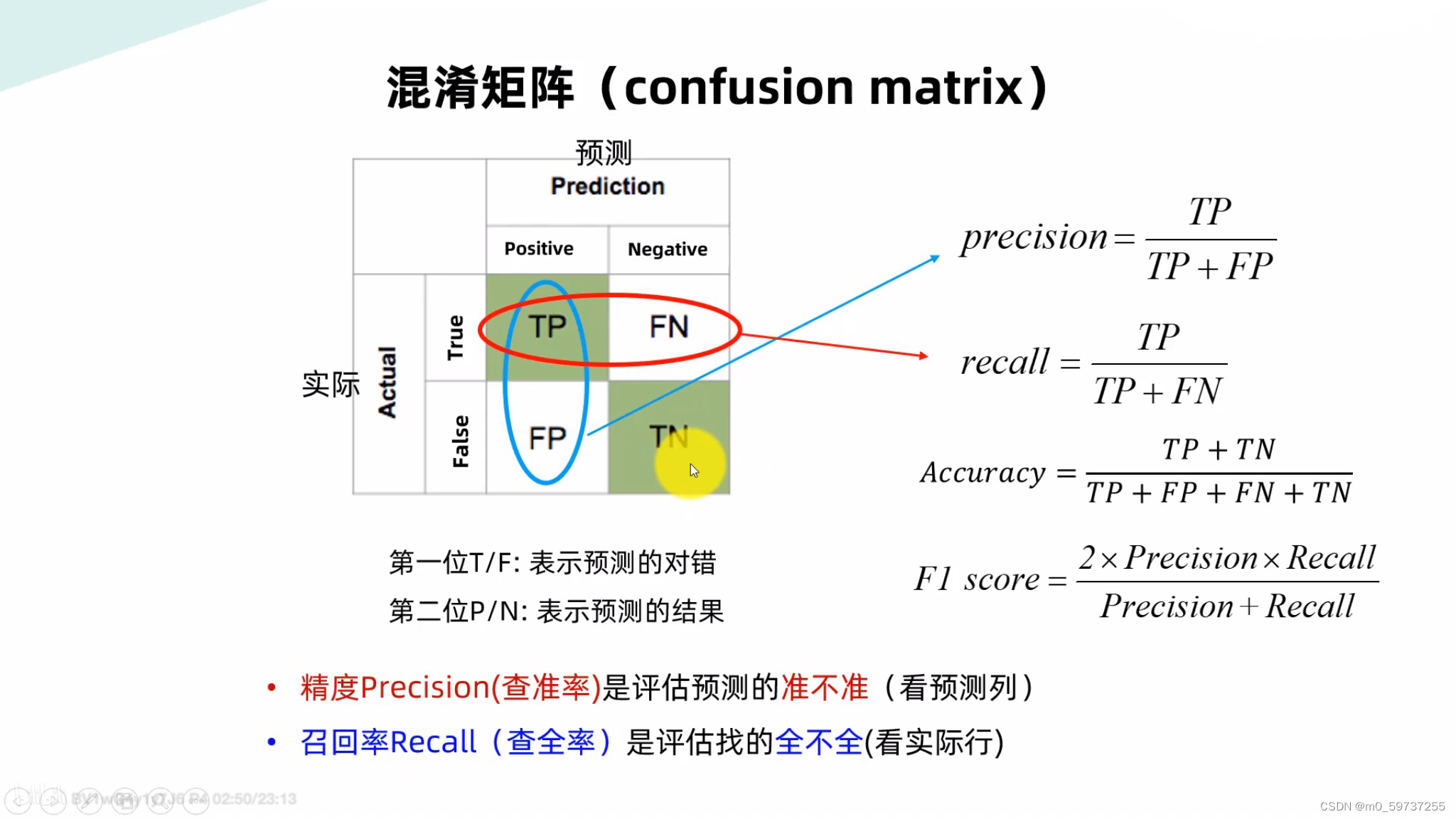
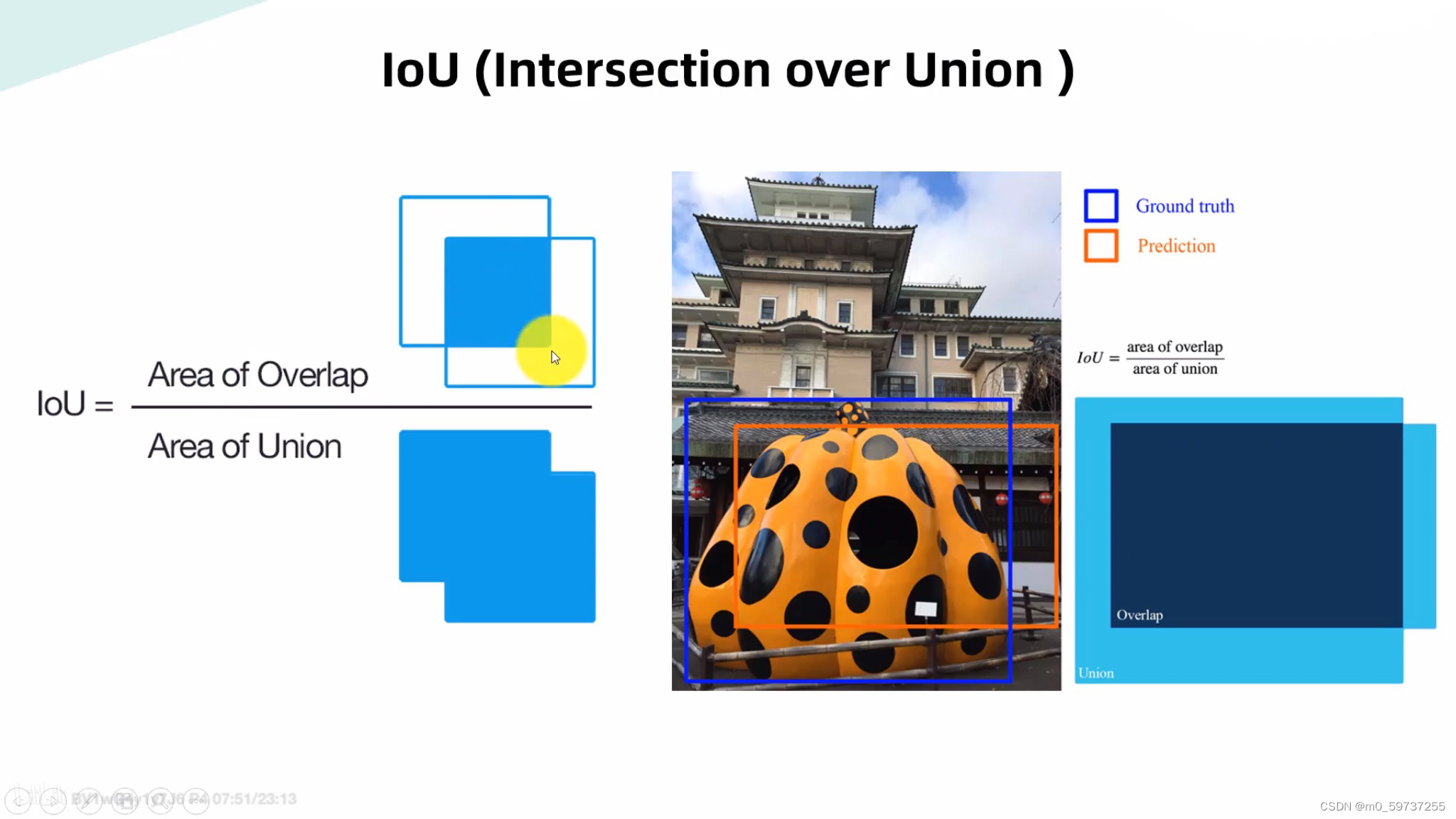
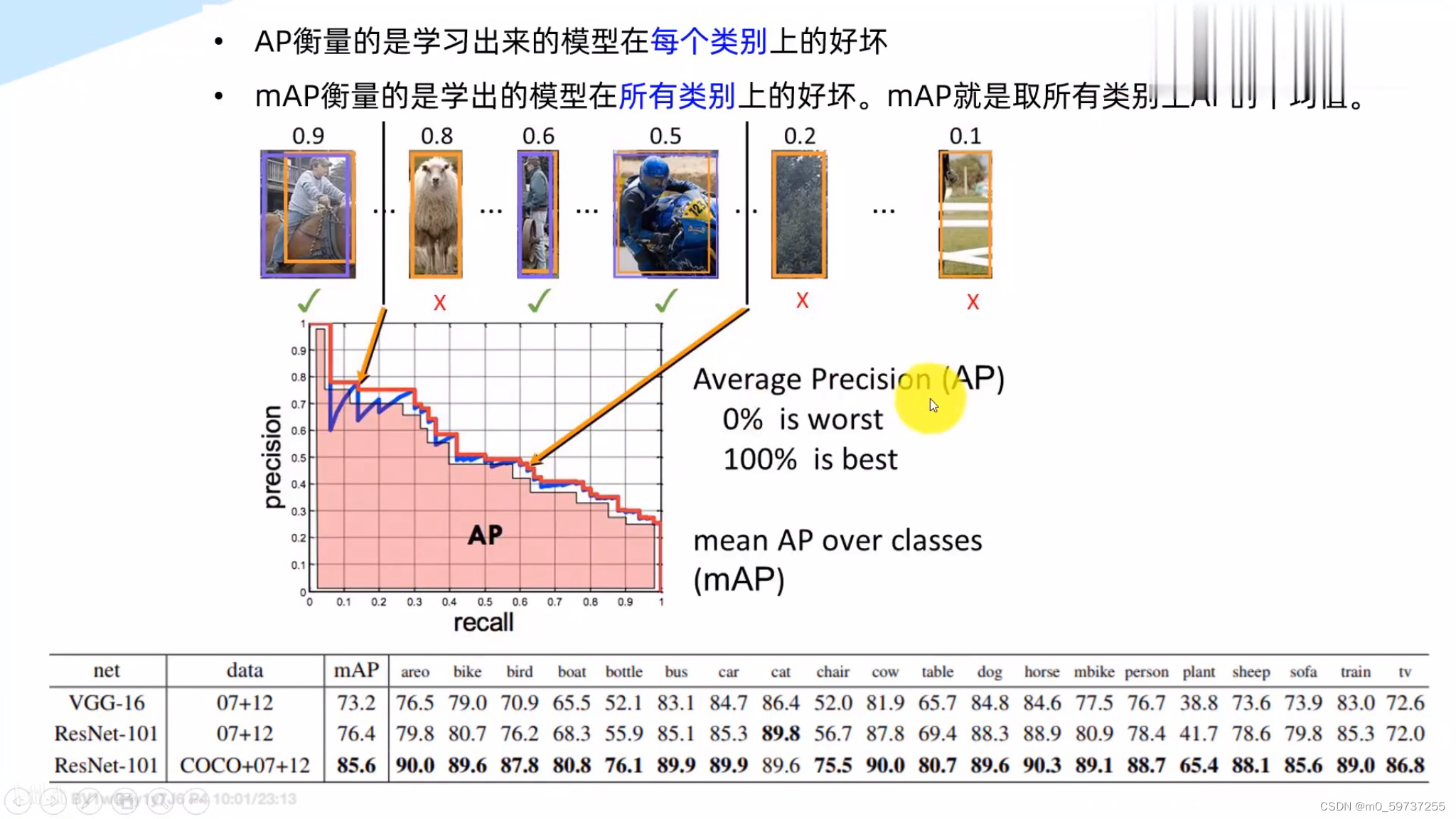
1.2 基础检测速度指标:

2. 目标检测与yolov5发展历程
2.1目标检测发展史

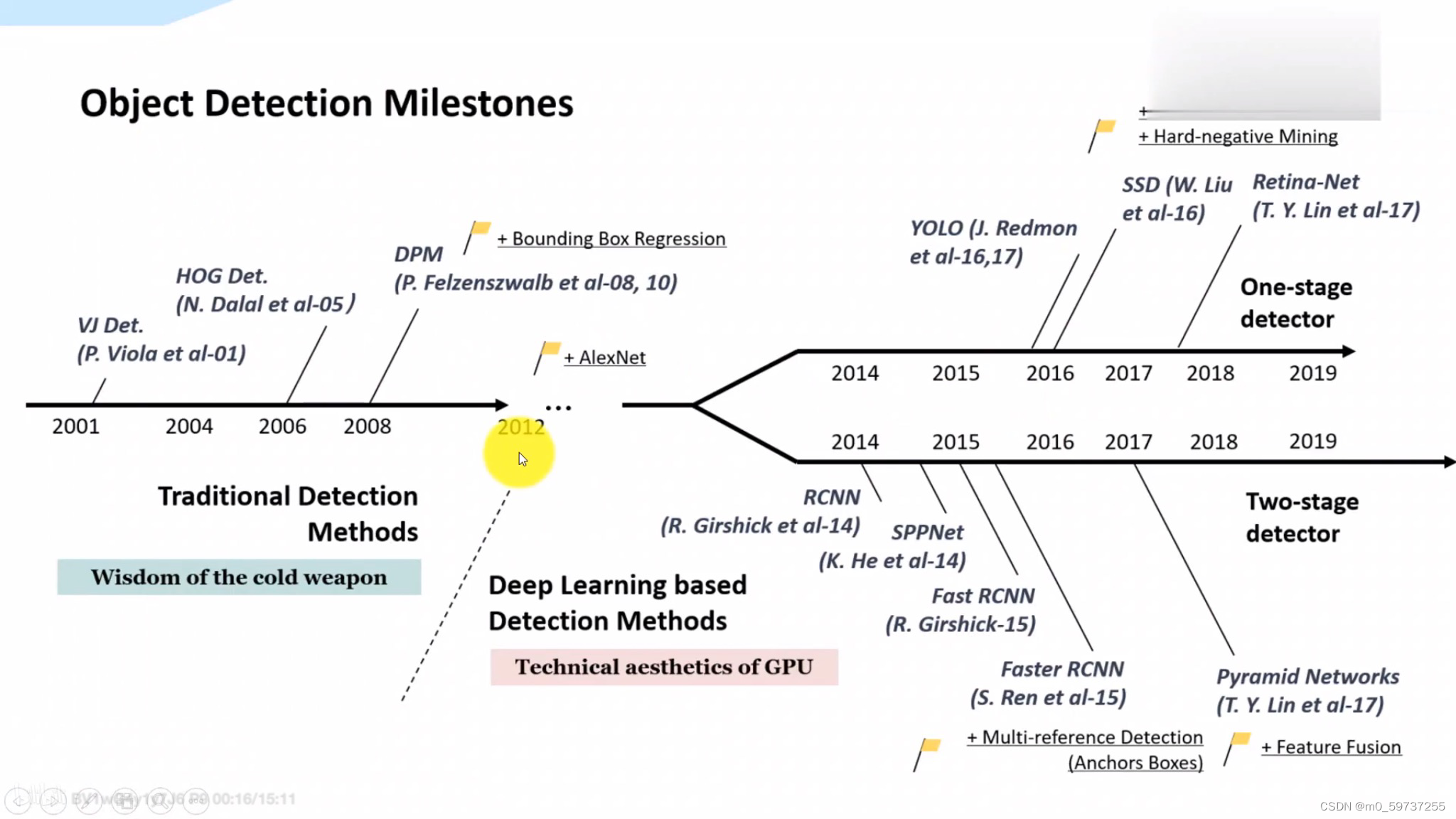
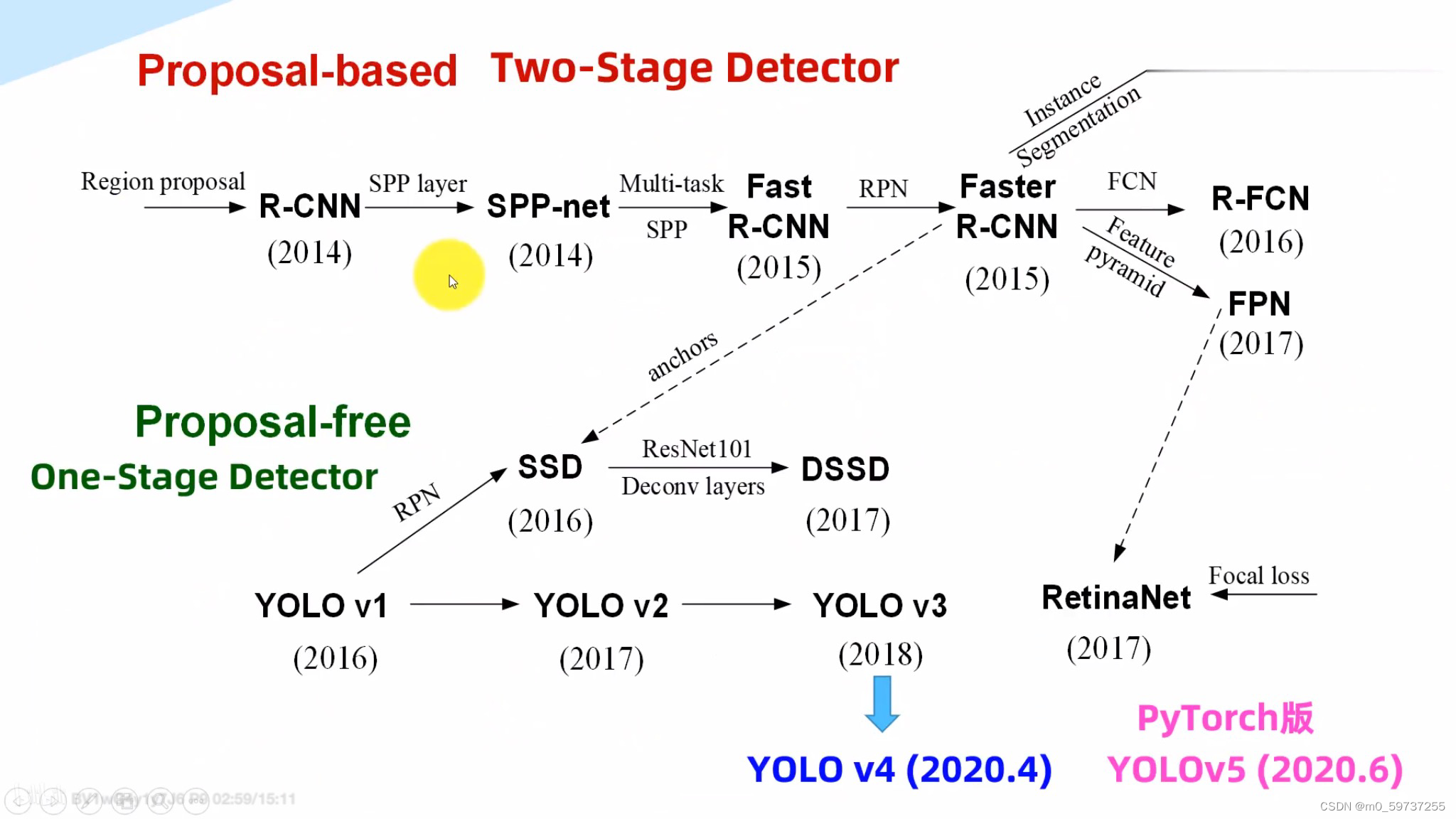
2.2 yolo原理及发展史
yolo简介:
yolov1:

yolov2:

yolov3: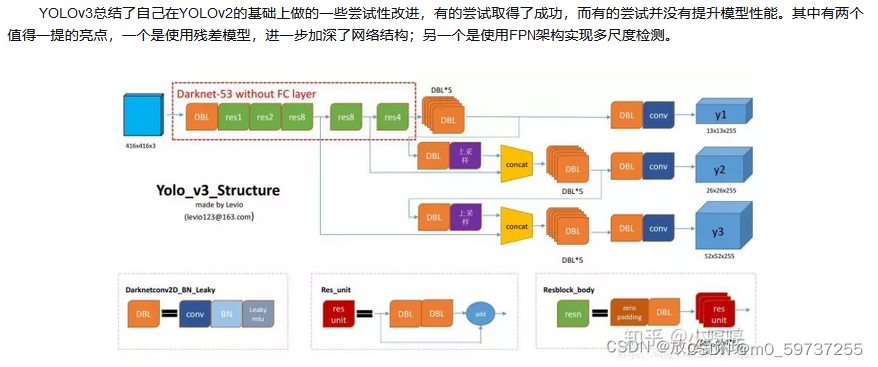

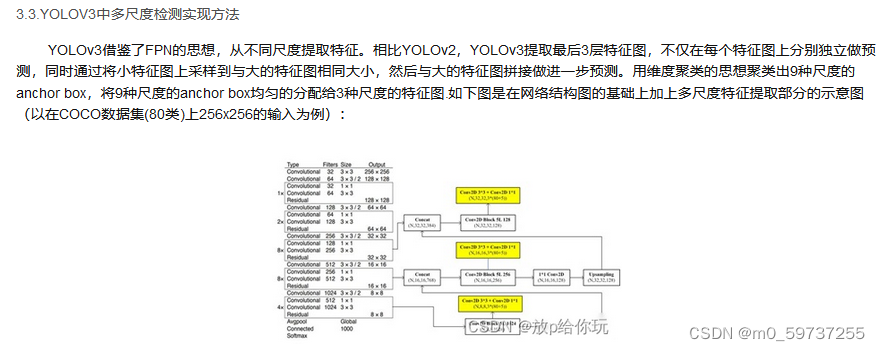
yolov4: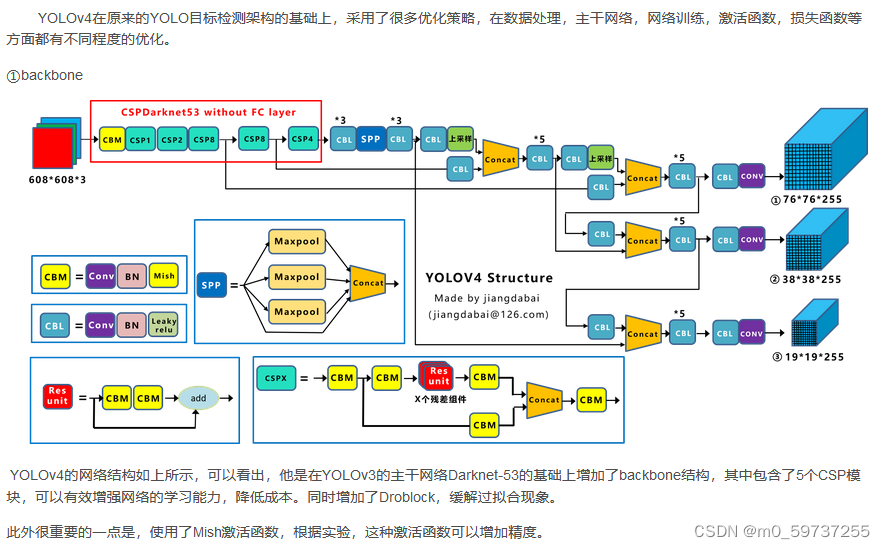

yolov5: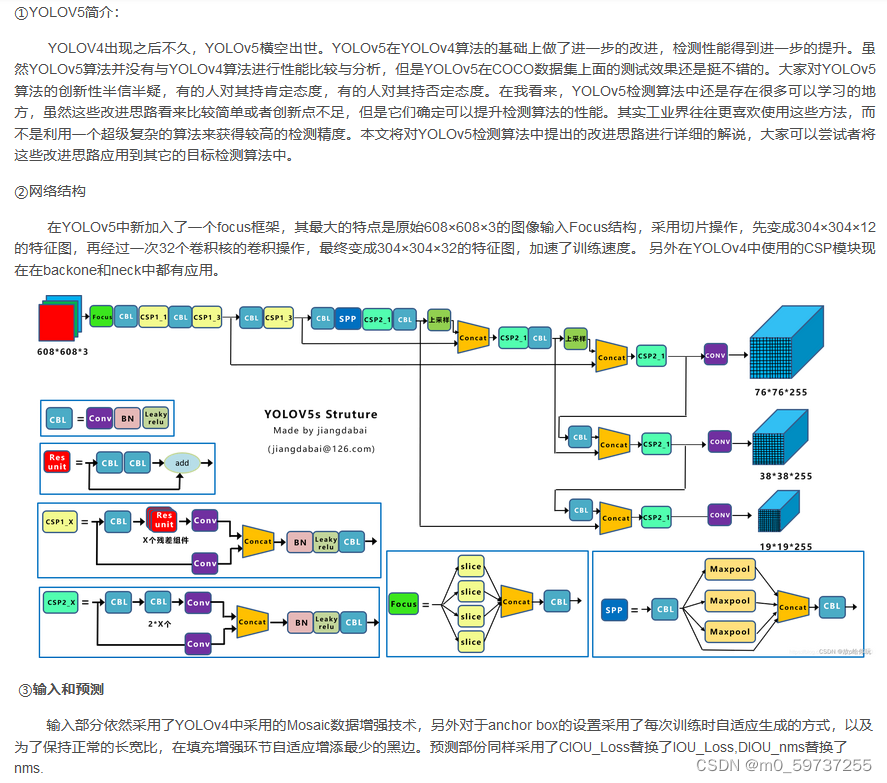

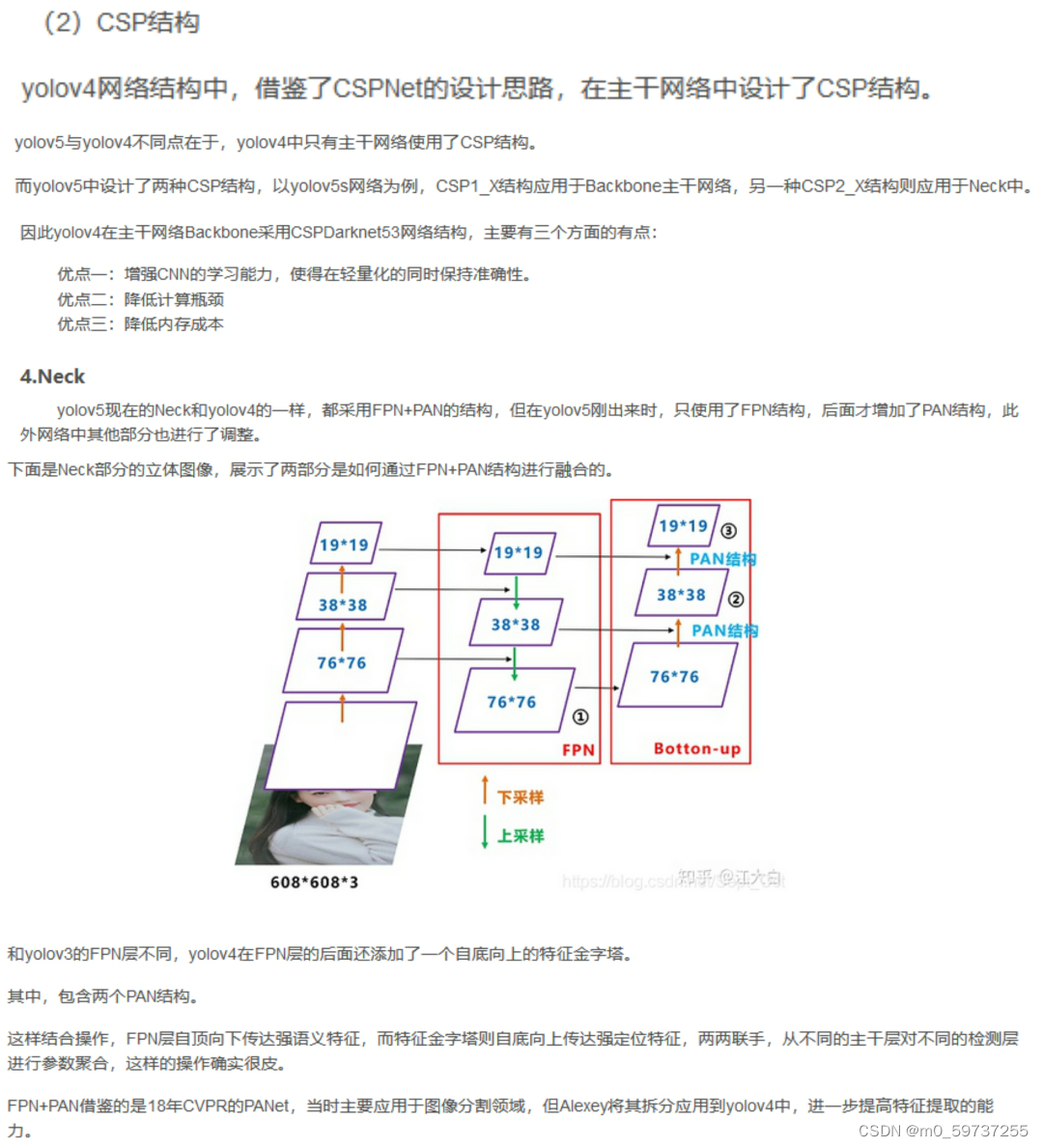
二、在CPU上部署yolov5
剩下章节内容主要参考来源:1、2、3
显卡匹配:我的设备是核显,没有独显,所以也用不了CUDA,因此选择在CPU上跑yolov5
1. Win10环境配置
1.1 下载并安装anaconda和pycharm
(注意不用单独安python 容易与anaconda版本不匹配而报错,anaconda会自带安装对应的python)
用cmd创建python3.7版本的yolov5环境并激活
1.2 导入Pytorch库
平台选择CPU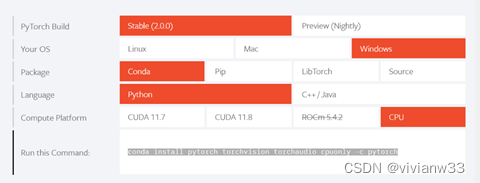 安装opencv,在anaconda prompt输入pip install python-opencv 即可
安装opencv,在anaconda prompt输入pip install python-opencv 即可
2. 下载yolov5源码并测试
将github上的yolov5代码下载后 用pycharm打开,并添加之前激活的yolov5环境,源码地址: https://github.com/ultralytics/yolov5
以下为源码包的简要介绍: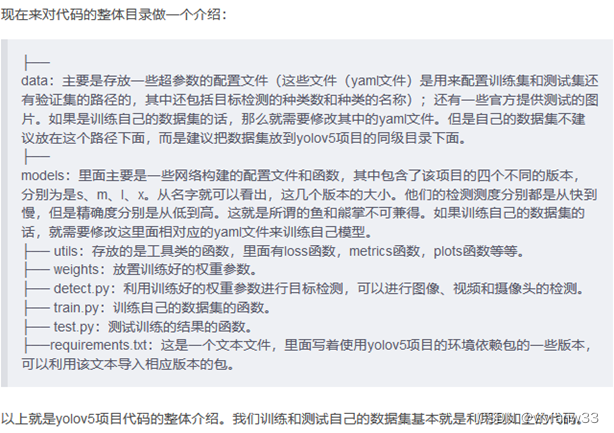
接下来安装依赖库,在pycharm打开yolov5源码文件中的requirements.txt,将第一行命令 pip install -r requirements.txt 输入终端等待包安装导入。安装完成后运行源码中的detect.py文件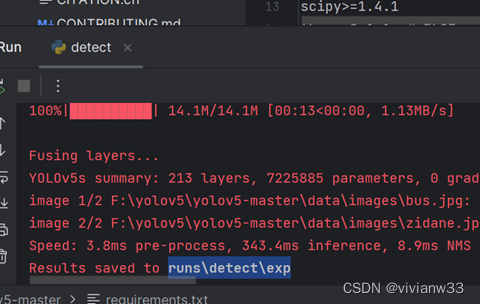 完成后进入图中runs\detect\exp路径
完成后进入图中runs\detect\exp路径
发现以下两张被处理的图片: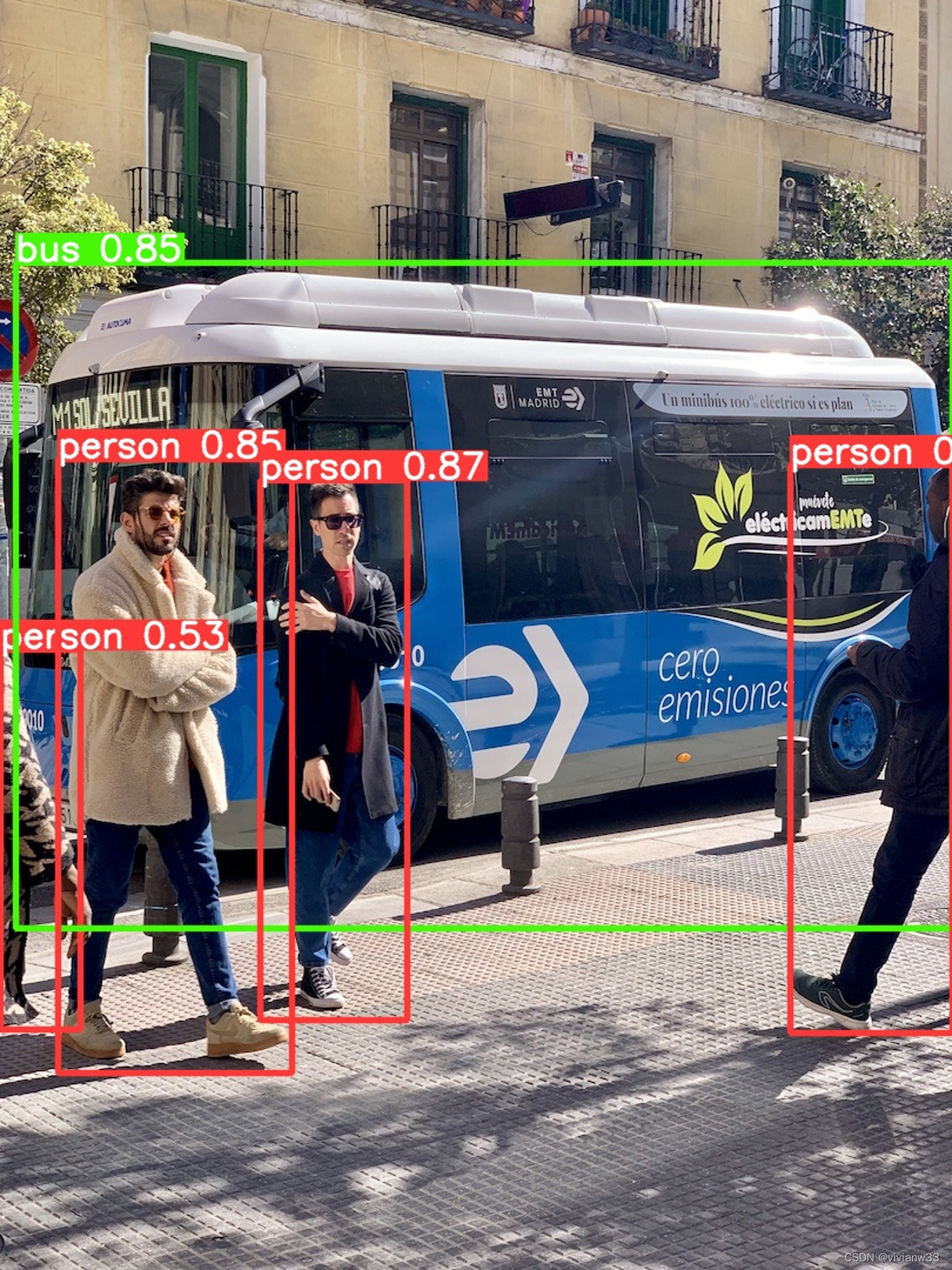
 测试运行成功,准备工作已完成
测试运行成功,准备工作已完成
三、用yolov5训练coco128数据集
由于电脑配置原因跑不动coco2017,所以采用coco128数据集进行训练。
首先需要修改yolov5文件中的train.py中parse_opt部分参数: weight为训练参数保存名称
weight为训练参数保存名称
cfg设置模型配置文件,选择yolov5s.yaml
data中配置训练数据配置文件为coco128.yaml
由于电脑配置低,epoch改为10轮迭代
batchsize选择比较小2的幂次即可,这里选择16
接下来运行train.py文件
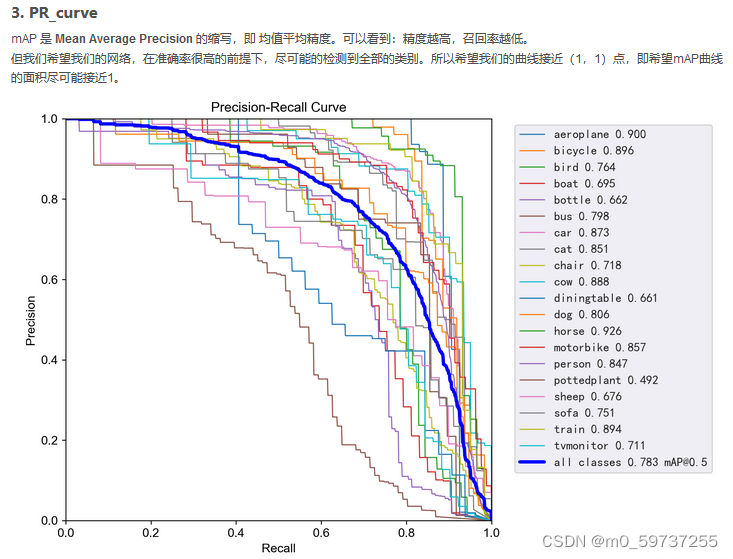
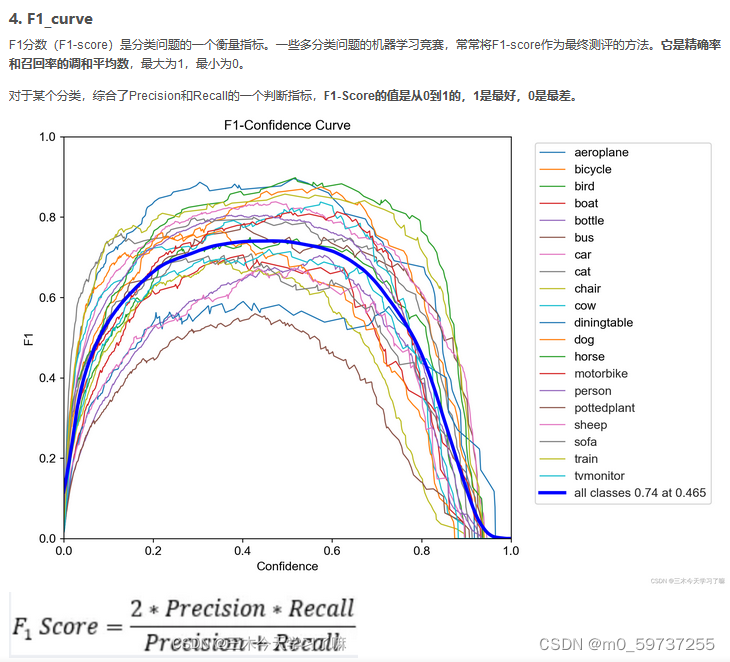
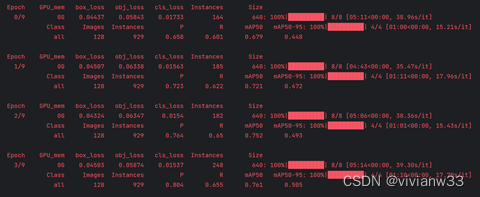
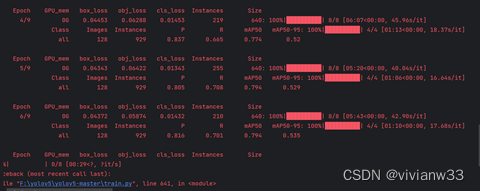
每轮训练后更新模型验证精度(观察指标:精度’P’,召回率’R’,[email protected]和[email protected]:.95)
报错:bad git executable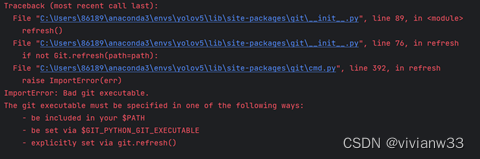 #出错原因:git环境变量设置问题
#出错原因:git环境变量设置问题
#简便解决办法:在导入包的上方增加以下代码
import os
os.environ[“GIT_PYTHON_REFRESH”] = “quiet”
参考链接:在这
开始运行,运行结果保存在exp2中
报错:内存不足,测试停止,计划的十次迭代只进行了7次
四、制作自己的数据集
1. 制作个人数据集
下载猫狗数据集 参考链接: https://zhuanlan.zhihu.com/p/116826786
文件路径结构参考如下(本文将own_datas命名为catndog):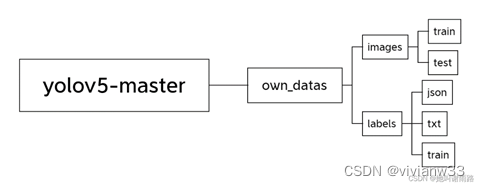 接下来开始制作猫猫的单项数据集
接下来开始制作猫猫的单项数据集
选择猫猫图片34张图片,复制进以下路径
yolov5-master\catndog\images\train
安装依赖库来给数据集打标签:
在Anaconda Prompt里pip install pyqt5和pip install labelme
完成后在终端输入labelme 在新窗口对训练集进行标注
Open dir 中选中images\train,出现训练集图片之后,右键选择create rectangle 框选对象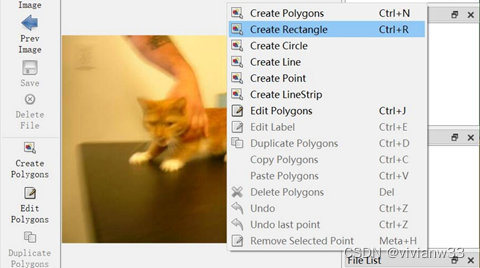 写入对象类的标签名后,存入labels\json路径中,点击next image进行下一张框选,直至34张框选完成
写入对象类的标签名后,存入labels\json路径中,点击next image进行下一张框选,直至34张框选完成
附:labelme使用指南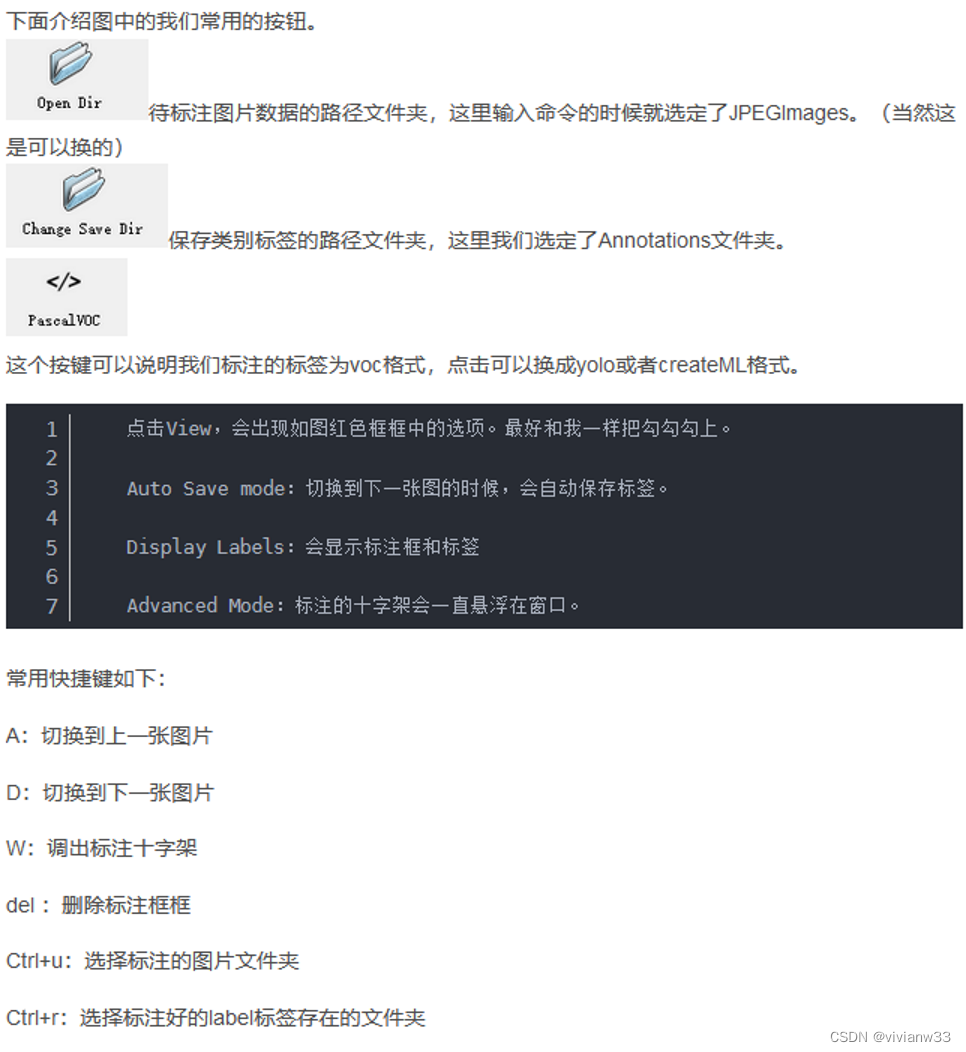 由于yolov5只能识别.txt格式,所以接下来要将.json格式的文件转换成.txt文件
由于yolov5只能识别.txt格式,所以接下来要将.json格式的文件转换成.txt文件
在yolov5-master文件中新建json2txt.py文件,并拷贝如下代码:
import json
import os
name2id ={'cat':0}# 标签名称defconvert(img_size, box):
dw =1./(img_size[0])
dh =1./(img_size[1])
x =(box[0]+ box[2])/2.0-1
y =(box[1]+ box[3])/2.0-1
w = box[2]- box[0]
h = box[3]- box[1]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return(x, y, w, h)defdecode_json(json_floder_path, json_name):
txt_name ='F:\yolov5\catndog/labels/txt/'+ json_name[0:-5]+'.txt'# txt文件夹的绝对路径
txt_file =open(txt_name,'w')
json_path = os.path.join(json_floder_path, json_name)
data = json.load(open(json_path,'r', encoding='gb2312', errors='ignore'))
img_w = data['imageWidth']
img_h = data['imageHeight']for i in data['shapes']:
label_name = i['label']if(i['shape_type']=='rectangle'):
x1 =int(i['points'][0][0])
y1 =int(i['points'][0][1])
x2 =int(i['points'][1][0])
y2 =int(i['points'][1][1])
bb =(x1, y1, x2, y2)
bbox = convert((img_w, img_h), bb)
txt_file.write(str(name2id[label_name])+" "+" ".join([str(a)for a in bbox])+'\n')if __name__ =="__main__":
json_floder_path =''F:/yolov5/catndog/labels/json/'
# json文件夹的绝对路径
json_names = os.listdir(json_floder_path)for json_name in json_names:
decode_json(json_floder_path, json_name)
运行json2txt.py,结束后可以在txt文件中看到对应的34个文件。将txt文件全部复制进labels\train文件中
将yolov5-master\data路径下找到128.yaml文件,复制到yolov5-master\catndog目录下,为方便理解,将其重命名为cat.yaml
接下来选择模型,由于数据集样本较少,所以选择精度更高的yolov5l,将yolov5-master\models路径下的yolov5l也复制进yolov5-master\catndog目录下,并重命名为yolov5l_cat.yaml
2. 设定训练参数:
打开cat.yaml文件,修改参数,将path注释掉,train 和 val 都使用刚制作好的个人数据集即可:
修改结果如下: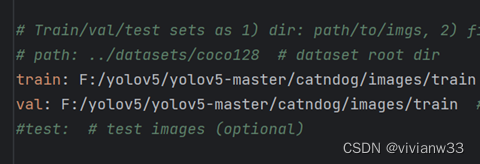
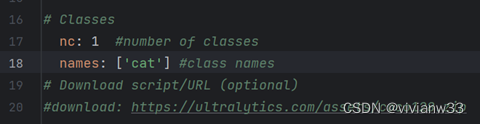 再打开yolov5l_cat.yaml文件,修改下面这行即可:
再打开yolov5l_cat.yaml文件,修改下面这行即可:
nc: 1 # number of classes
打开train.py文件,修改参数
parser.add_argument('--weights',type=str, default='weights/yolov5s.pt',help='initial weights path')#初始化权重文件的路径地址
parser.add_argument('--cfg',type=str, default='models/yolov5s_hat.yaml',help='model.yaml path')#模型yaml文件的路径地址
parser.add_argument('--data',type=str, default='data/hat.yaml',help='data.yaml path')#数据yaml文件的路径地址
因为电脑配置较差,所以初步将epochs设为 5
workers 设为 2 ,workers是最大工作核心数,我的电脑为双核四线程。修改后运行即可
报错: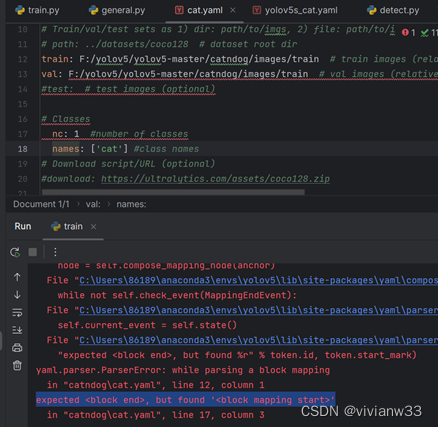 参考链接: https://blog.csdn.net/enthan809882/article/details/103970203
参考链接: https://blog.csdn.net/enthan809882/article/details/103970203
由于yaml对空格数要求很严格,没有对齐就会报这个错,对齐后运行成功
运行到一半报告内存不够: 清理后继续运行train.py 依然失败,遂改为使用yolov5s模型
清理后继续运行train.py 依然失败,遂改为使用yolov5s模型 运行成功后,可在 runs\train\exp22 路径下查看运行结果
运行成功后,可在 runs\train\exp22 路径下查看运行结果

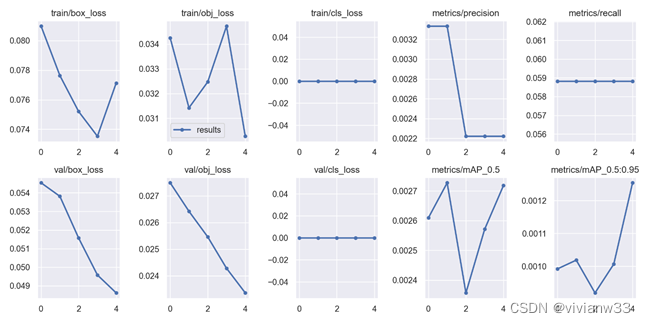 结果分析参考链接: https://blog.csdn.net/weixin_45751396/article/details/126726120
结果分析参考链接: https://blog.csdn.net/weixin_45751396/article/details/126726120
五、用yolov5训练自己的数据集并用视频进行测试
在b站上选择几段猫猫视频进行录屏,作为此次监测的测试集,将视频存入yolov5-master/catnddog/images/test
打开detect.py文件,修改以下两行代码:
parser.add_argument('--weights', nargs='+',type=str, default='runs/train/exp22/weights/best.pt',help='model path(s)')
parser.add_argument('--source',type=str, default='catndog/images/test',help='file/dir/URL/glob, 0 for webcam')
一个是模型的相对路径,另一个是存放测试文件的路径
运行detece.py后,在runs/detect/exp3中查看结果
结果未识别出猫猫,分析可能是迭代次数太少所以模型性能较差,将迭代改为30后重新测试后,
训练结果如下: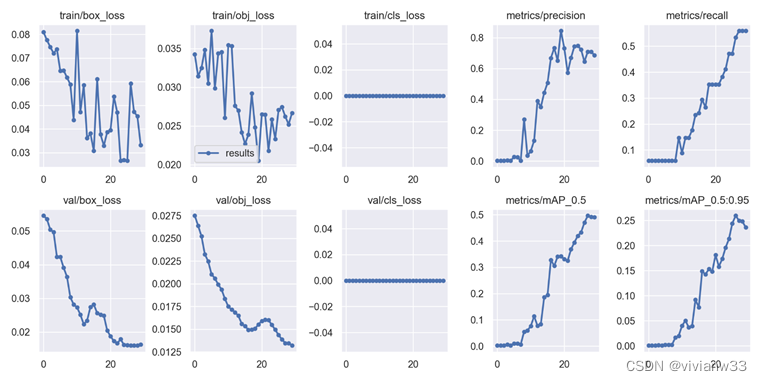


测试后视频截图如下:


版权归原作者 vivianw33 所有, 如有侵权,请联系我们删除。