
写在前面
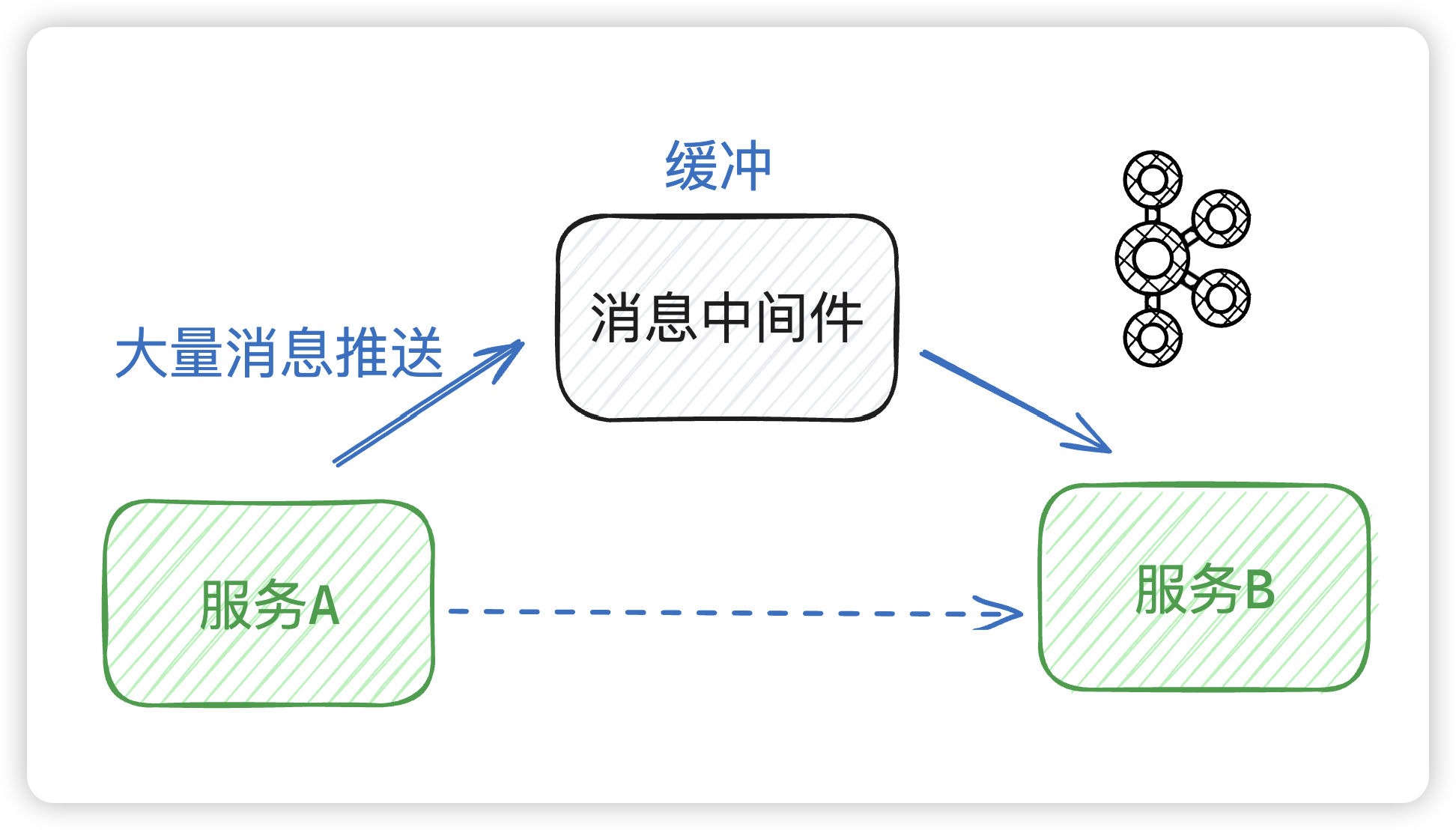
Kafka 是一个可横向扩展,高可靠的实时消息中间件,常用于服务解耦、流量削峰。
好像是 LinkedIn 团队开发的,后面捐赠给apache基金会了。
kafka
总体架构图
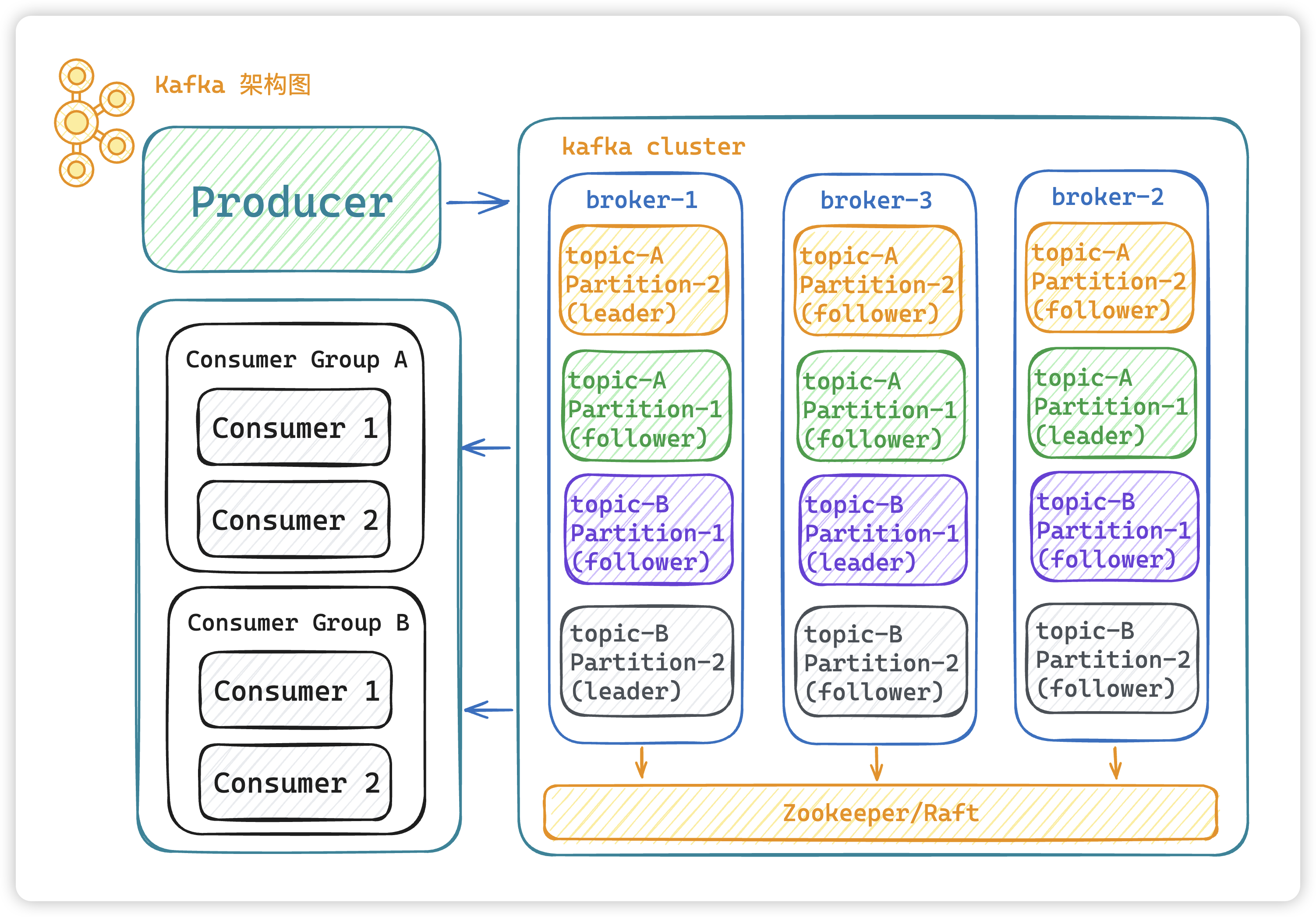
- Producer:生产者,消息的产生者,是消息的入口。
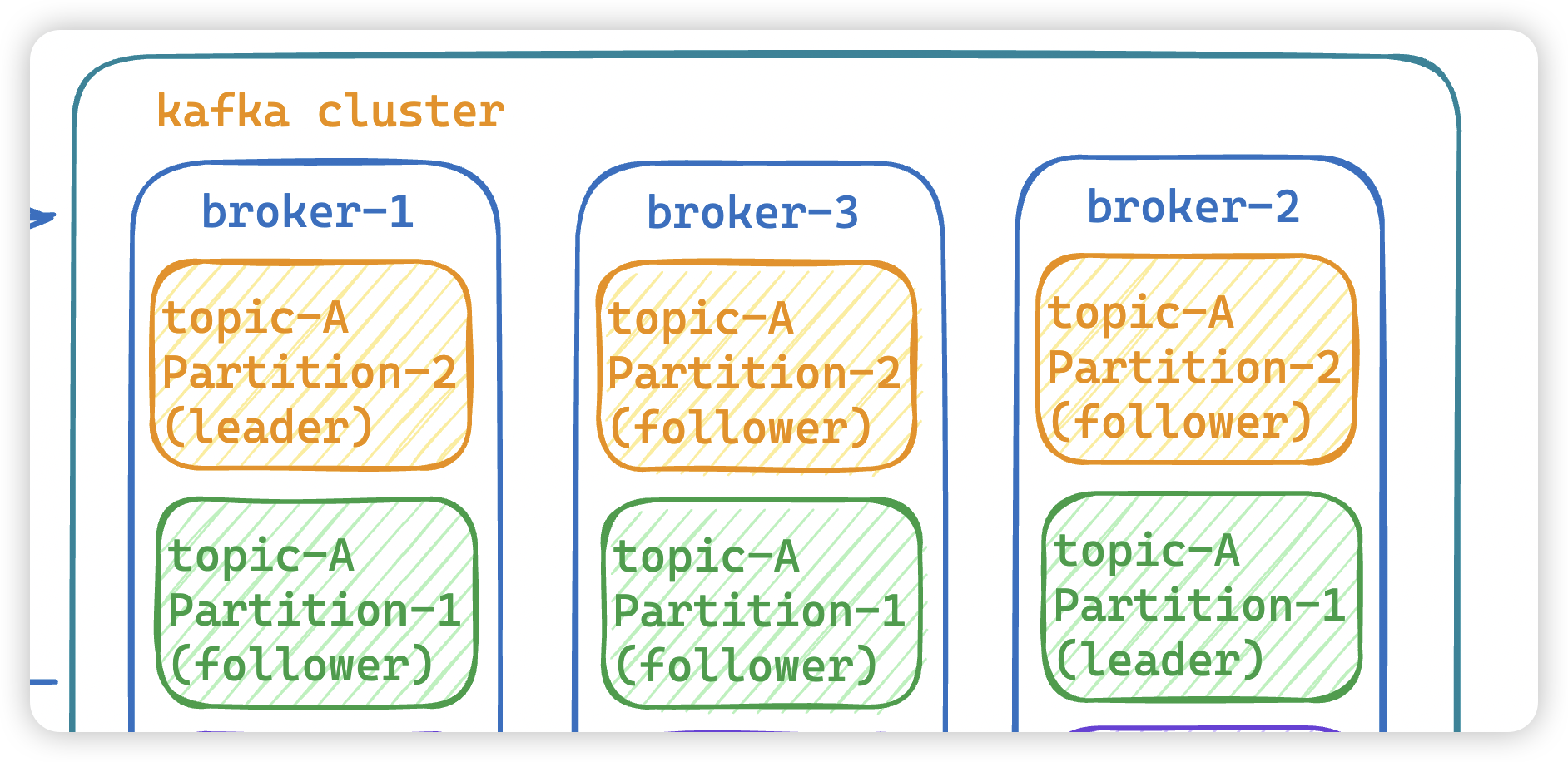
- Broker:Broker 是 kafka 一个实例,每个服务器上有一个或多个 kafka 的实例,简单的理解就是一台 kafka 服务器,kafka cluster 表示集群的意思
- Topic:消息的主题,可以理解为消息队列,kafka的数据就保存在topic。在每个 broker 上都可以创建多个 topic 。
- Partition:
Topic的分区,每个 topic 可以有多个分区,分区的作用是做负载,提高 kafka 的吞吐量。同一个 topic 在不同的分区的数据是不重复的,partition 的表现形式就是一个一个的文件夹。 - Replication:每一个分区都有多个副本,副本的作用是做备胎,leader节点会将数据同步到follow从节点。当leader故障的时候会选择一个follower ,成为 leader,
follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本。
- Consumer:消费者,消息的消费方,是消息的出口。
- Consumer Group:可以将多个消费组构成一个消费者组,同一个 partition 的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量。
- Zookeeper:kafka 2.8 版本之前是依赖 zookeeper 来保存集群的的元信息,来保证系统的可用性。
- Raft:kafka 2.8 版本之后就根据
raft来保证系统的可用性。
为什么同一个 partition 的数据只能被消费者组中的某一个消费者消费?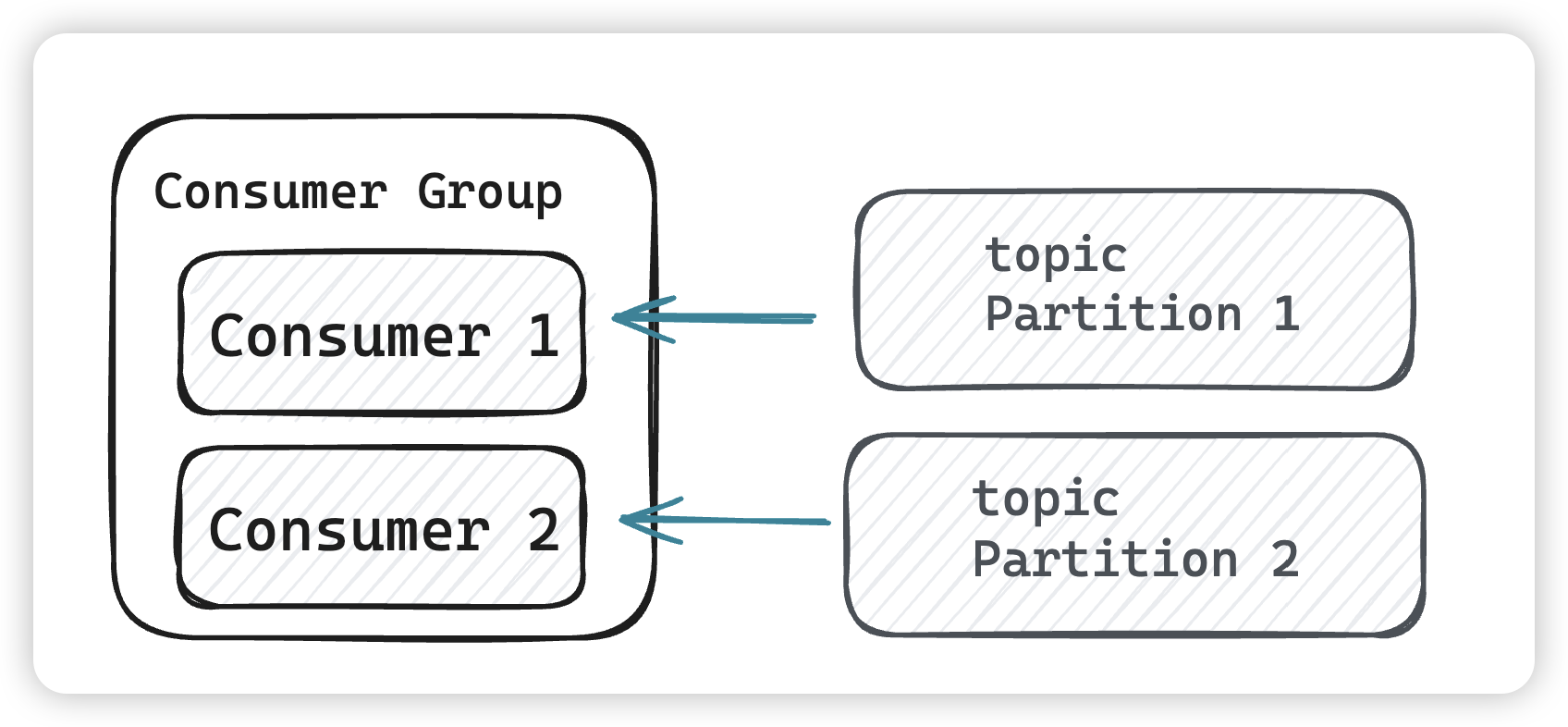
- 顺序性:Kafka 保证了同一个分区内的消息是有序的,如果允许多个消费者并行消费同一个分区的消息,那么消息的
顺序性将无法得到保证。当然由于各个分区的不同,我们顺序性还是不要靠kafka,在自己业务做判定。 - 负载均衡:通过让不同的消费者组内的消费者分摊不同的分区,Kafka 实现了
负载均衡,确保每个消费者都有机会消费消息,同时避免了重复消费。 - Offset 管理:**
每个消费者在消费时都会维护自己的 offset**,如果多个消费者同时消费同一个分区,那么 offset 的管理将变得复杂,可能会导致重复消费或者消息丢失。
发送数据
kafka 会每次发送数据都是向 leader节点发送数据,并顺序写入到磁盘,然后 leader节点会将数据同步到各个从节点follower,即使主节点挂了,也不会影响服务的正常运行。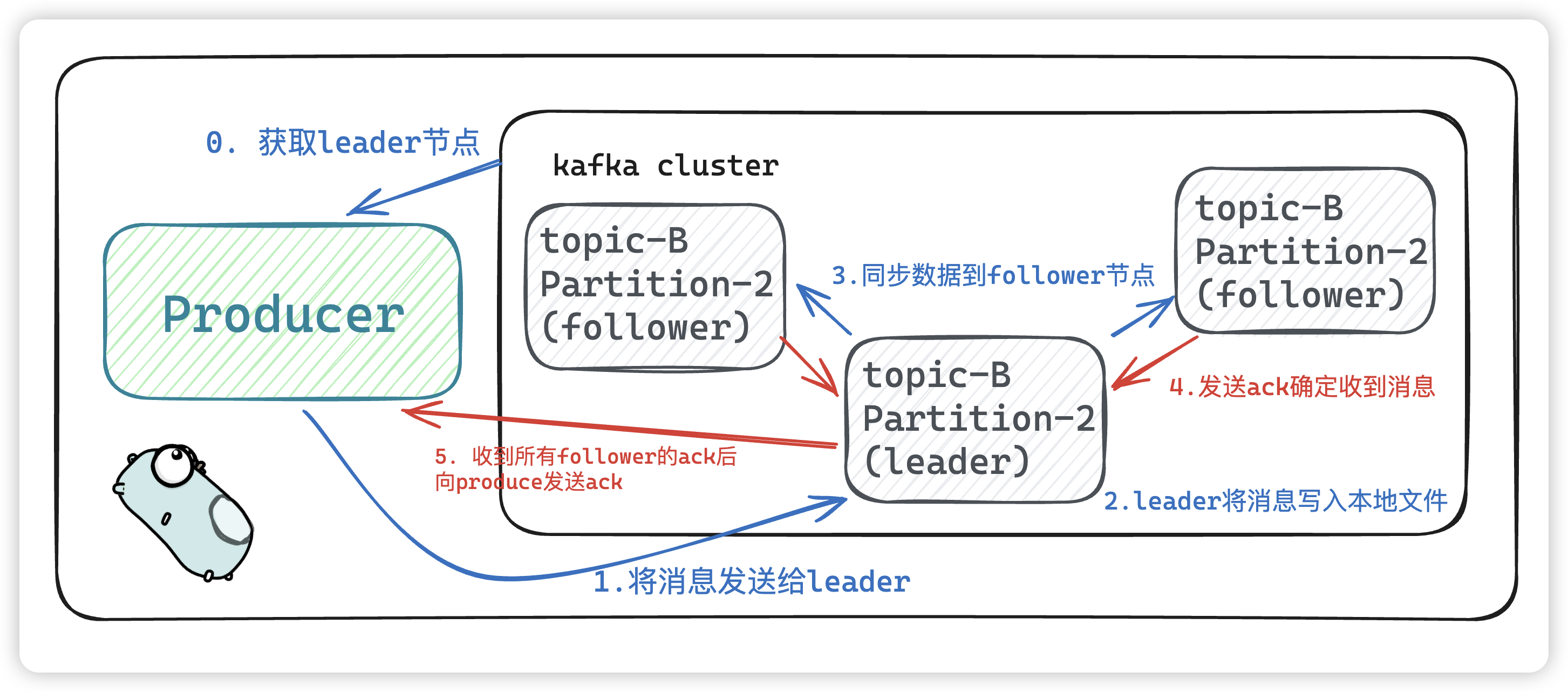
- producer 生产者获取 leader 节点,将消息发送给leader节点。
- leader节点将消息持久化到本地后,将数据同步到各个follower节点。
- leader节点收到各个follower节点的
ack后,发送ack给producer
消费数据
和生产者一样,消费者主动到kafka集群中拉取消息时,
也是从leader节点去拉取数据
。
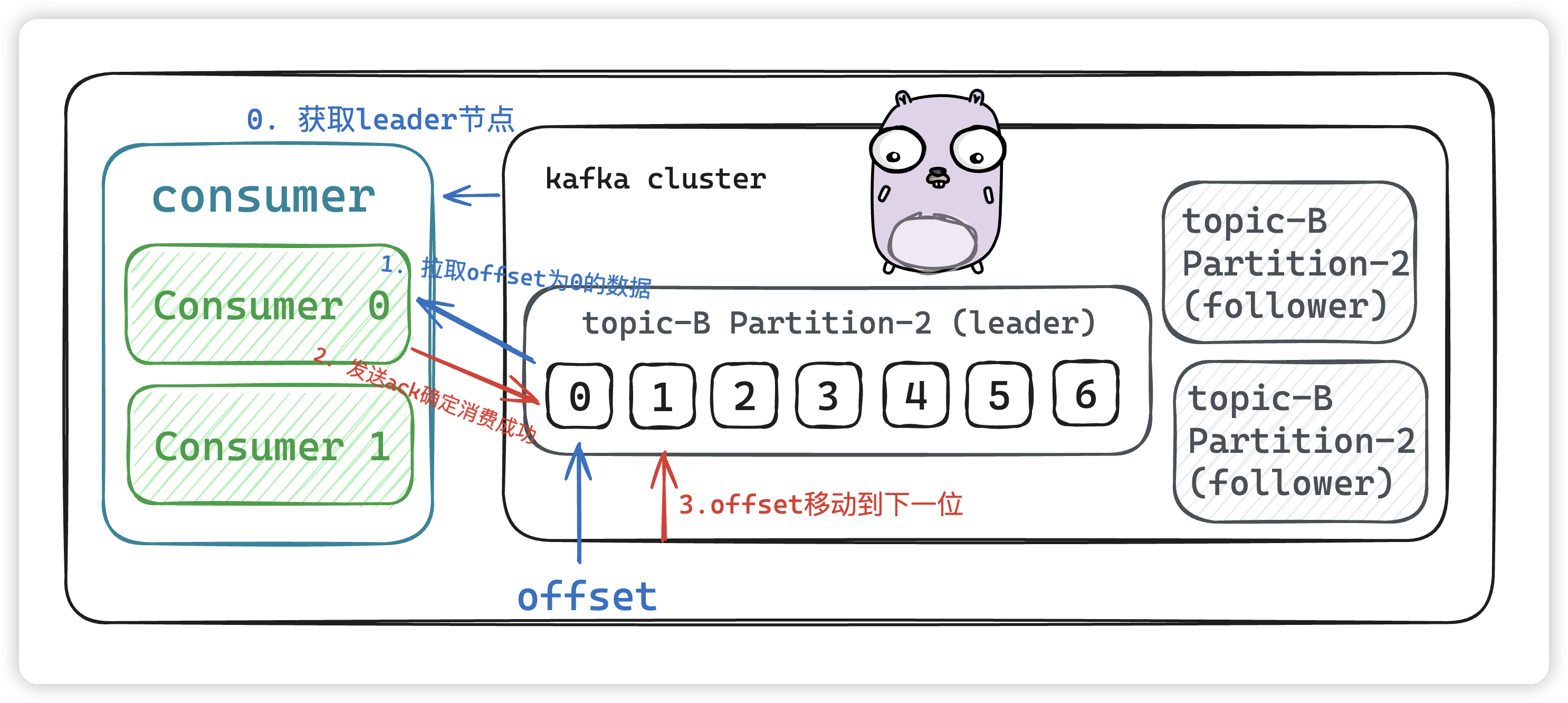
- 获取leader节点
- 拉去offset为0的数据进行消费
- 消费成功后发送
ack,offset将会移动到下一位,待下次消费定位数据
kafka 为什么会那么快?
一共有四个原因
- 磁盘顺序读写
- PageCache 页缓存技术
- 零拷贝技术
- kafka 分区架构
磁盘顺序读写
生产者发送数据到 kafka 集群中,最终会写入到磁盘中,会采用顺序写入的方式。消费者从 kafka 集群中获取数据时,也是采用顺序读的方式。无论是机械磁盘还是固态硬盘 SSD,顺序读写的速度都是远大于随机读写的。
- 机械磁盘顺序读写省去了
磁头频繁寻址和旋转盘片的开销 - 固态硬盘SSD以Page为单位做读写,以Block为单位做垃圾回收。写相同数据量的情况下,顺序写
制造更少的垃圾Block,所以比随机写有更高的性能。
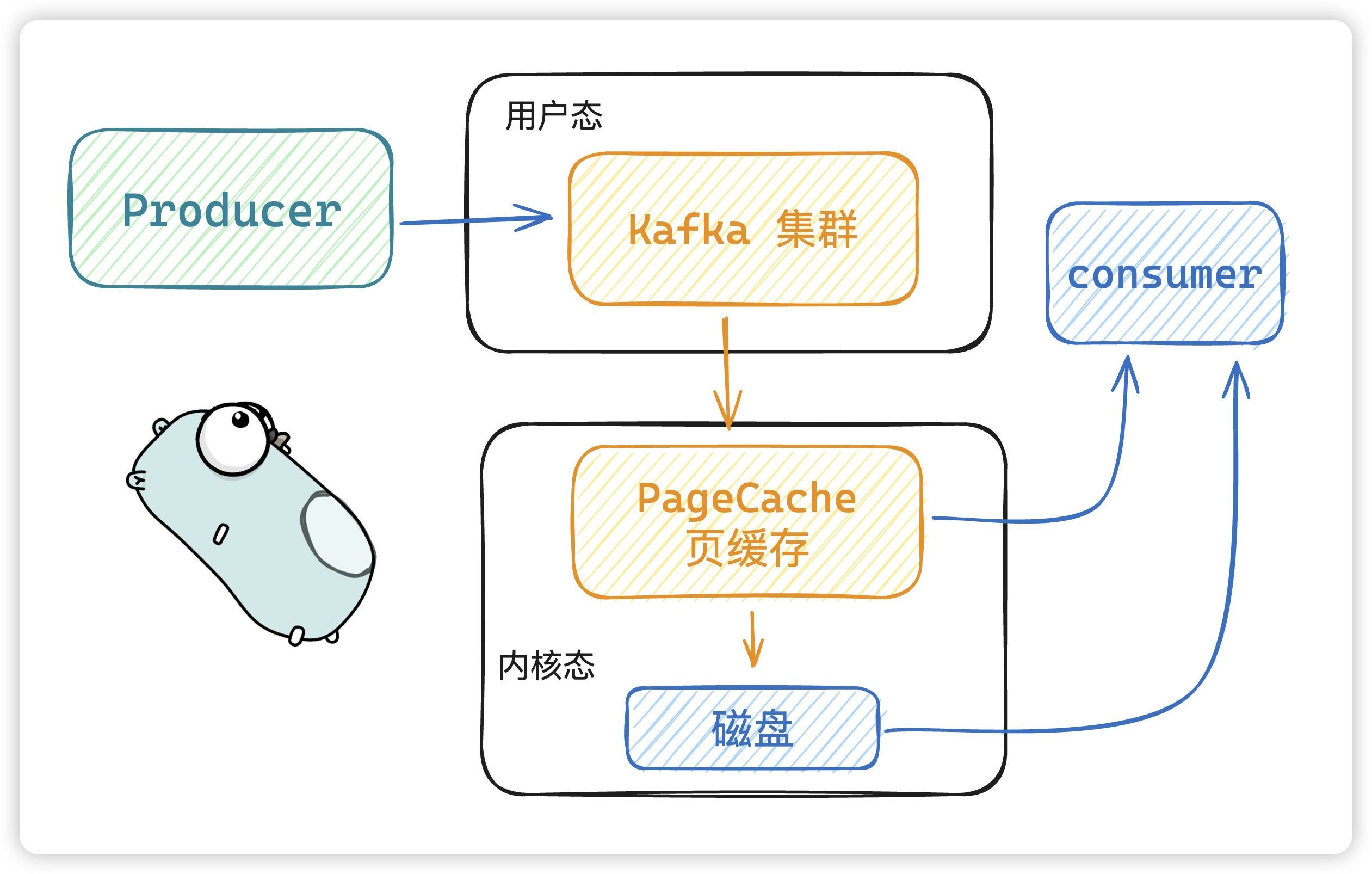
PageCache 页缓存技术
- 当 kafka 有写操作时,先将数据写入
PageCache中,然后在顺序写入到磁盘中。 - 当读操作发生时,先从
PageCache中查找,如果找不到,再去磁盘中读取。
零拷贝技术
一般性能的瓶颈都是网络io、磁盘io。我们来看下从磁盘读取数据到网卡场景下,传统 IO 的整个过程:
DMA方式,Direct Memory Access,也称为成组数据传送方式,有时也称为直接内存操作。DMA方式在数据传送过程中,没有保存现场、恢复现场之类的工作。
传统 IO 模型下,从磁盘读取数据,写到网卡设备中,经历了 4 次用户态和内核态之间的切换和数据的拷贝。
红色箭头为数据拷贝
。
那能不能让拷贝次数发送的少一点呢?但是kafka 采用了 sendfile 的零拷贝技术
所谓的零拷贝技术不是指不发生拷贝,而是在用户态没有进行拷贝。
kafka 分区架构
- 分区架构:kafka 集群架构采用了多分区技术,并行度高。
参考
[1] https://strikefreedom.top/archives/why-kafka-is-so-fast
[2] https://cloud.tencent.com/developer/article/2185290
[3] https://serverfault.com/questions/843628/why-do-sequential-writes-have-better-performance-than-random-writes-on-ssds
[4] https://xie.infoq.cn/article/51b6764c48ff70988e124a868
版权归原作者 小生凡一 所有, 如有侵权,请联系我们删除。