
机器学习之k近邻(KNN算法)工作原理、代码实现详解
文章目录
1、kNN介绍
(1)定义
k近邻简称KNN,(k-Nearest Neighbor)是一种常用的监督学习方法。
(2)工作原理
工作原理为:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息来进行预测。
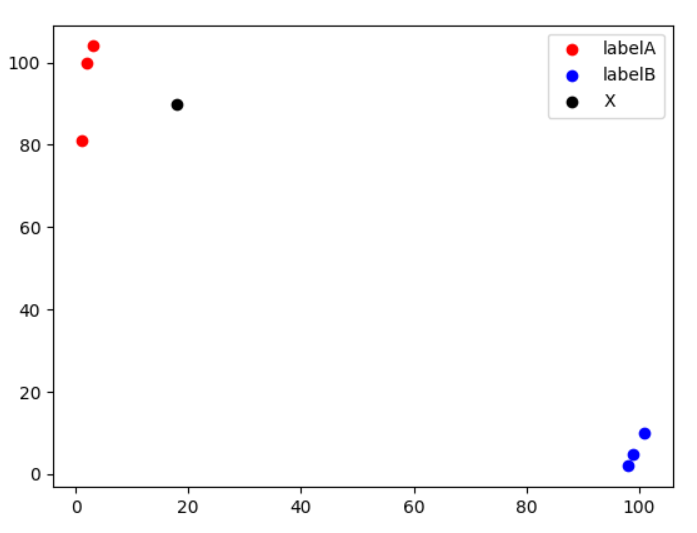
例如下图,其中黑色标记样本靠近红色标记样本,而远离蓝色标记样本,那么根据最靠近的3个训练样本来进行预测黑色样本属于红色样本类别。
(3)学习方式
它是"懒惰学习"的著名代表,在训练阶段仅仅把样本保存,训练时间为0,待收到测试样本后再进行处理,相应的在训练阶段就对样本进行学习处理的方法称为“急切学习”。
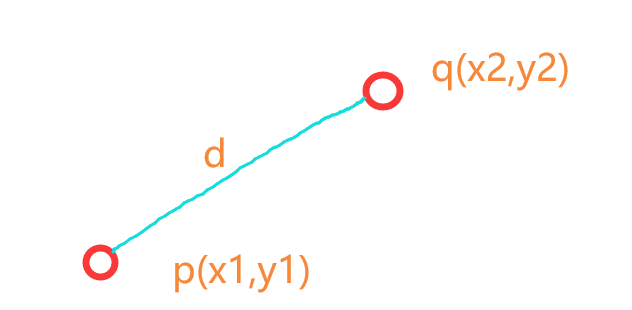
(4)欧氏距离
评估的标准是用欧式距离来进行判定。
公式及图解如下
E
(
x
,
y
)
=
∑
i
=
0
n
(
x
i
−
y
i
)
2
E(x,y)=\sqrt{\sum_{i=0}^n(x_{i}-y_{i})^2}
E(x,y)=i=0∑n(xi−yi)2
2、kNN代码实现简单案例
1、IRIS数据集分类案例——算法实现
(1)、导入所需数据集合算法包
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report,confusion_matrix
import operator
import random
(2)、定义knn函数求欧式距离并排序
defknn(x_test, x_data, y_data, k):# 计算样本数量
x_data_size = x_data.shape[0]# 复制x_test
np.tile(x_test,(x_data_size,1))# 计算x_test与每一个样本的差值
diffMat = np.tile(x_test,(x_data_size,1))- x_data
# 计算差值的平方
sqDiffMat = diffMat**2# 求和
sqDistances = sqDiffMat.sum(axis=1)# 开方
distances = sqDistances**0.5# 从小到大排序
sortedDistances = distances.argsort()
classCount ={}for i inrange(k):# 获取标签
votelabel = y_data[sortedDistances[i]]# 统计标签数量
classCount[votelabel]= classCount.get(votelabel,0)+1# 根据operator.itemgetter(1)-第1个值对classCount排序,然后再取倒序
sortedClassCount =sorted(classCount.items(),key=operator.itemgetter(1), reverse=True)# 获取数量最多的标签return sortedClassCount[0][0]
(3)、数据处理
# 载入数据
iris = datasets.load_iris()#分割数据0.2为测试数据,0.8为训练数据
x_train,x_test,y_train,y_test = train_test_split(iris.data, iris.target, test_size=0.2)
predictions =[]for i inrange(x_test.shape[0]):
predictions.append(knn(x_test[i], x_train, y_train,5))print(classification_report(y_test, predictions))print(confusion_matrix(y_test,predictions))
结果如下:
准确度达到了90%
precision recall f1-score support
0 1.00 1.00 1.00 5
1 1.00 0.77 0.87 13
2 0.80 1.00 0.89 12
accuracy 0.90 30
macro avg 0.93 0.92 0.92 30
weighted avg 0.92 0.90 0.90 30
[[13 0 0]
[ 0 11 1]
[ 0 1 14]]
2、IRIS数据集分类案例——sklearn实现
(1)、导入所需数据集合算法包
# 导入算法包以及数据集from sklearn import neighbors
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import random
(2)、处理数据并调用模型
# 载入数据
iris = datasets.load_iris()print(iris)
x_train,x_test,y_train,y_test = train_test_split(iris.data, iris.target, test_size=0.2)# 构建模型
model = neighbors.KNeighborsClassifier(n_neighbors=3)
model.fit(x_train, y_train)
prediction = model.predict(x_test)print(classification_report(y_test, prediction))
结果如下:
准确率到达了93%
precision recall f1-score support
0 1.00 1.00 1.00 10
1 1.00 0.80 0.89 10
2 0.83 1.00 0.91 10
accuracy 0.93 30
macro avg 0.94 0.93 0.93 30
weighted avg 0.94 0.93 0.93 30
注意:每次训练的结果可能不会相同。
0.93 30
macro avg 0.94 0.93 0.93 30
weighted avg 0.94 0.93 0.93 30
注意:每次训练的结果可能不会相同。
本文转载自: https://blog.csdn.net/tianhai12/article/details/124796617
版权归原作者 天海一直在 所有, 如有侵权,请联系我们删除。
版权归原作者 天海一直在 所有, 如有侵权,请联系我们删除。