
1. 引言
1.1 背景介绍
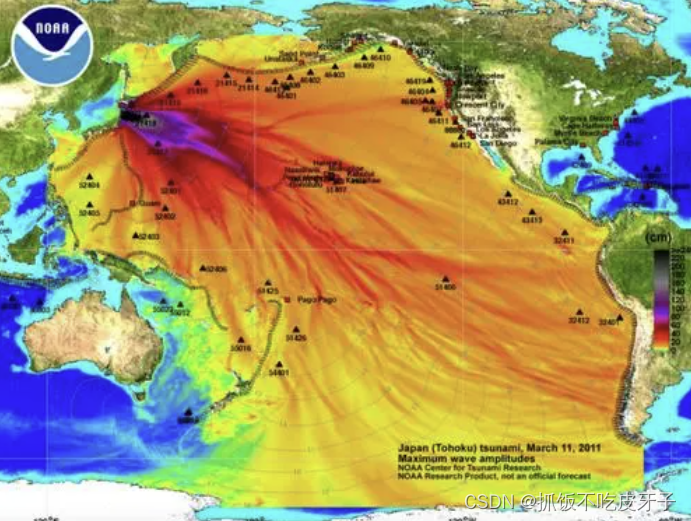
自2011年发生福岛核事故以来,日本一直在努力处理事故造成的影响。在事故后的这段时间里,大量放射性物质被释放到环境中,其中一项重要的决策是如何处理核污水。随着时间的推移,累积的核污水导致了对海洋生态系统和人类健康的不确定风险。为了更好地评估这些风险,科学家们开始探索使用人工智能技术来预测福岛核污水排放对环境的影响。现在日本与2023年8月24日进行排放和污水到太平洋中。
1.2 目的和重要性
本文旨在探讨如何利用人工智能技术来预测福岛核污水排放对环境的潜在影响。人工智能在科学研究和环境影响预测中扮演着重要的角色,其数据分析和模式识别能力可以帮助科学家们更准确地预测放射性物质在海洋中的传播路径、生态系统的响应以及潜在的长期影响。通过这项研究,我们可以更好地了解福岛核污水排放可能对环境产生的影响,为决策制定提供科学依据。

2. 福岛核污水排放的背景
2.1 福岛核事故回顾
2011年,日本福岛核电站发生了一起严重的核事故,造成了大量放射性物质的泄漏,对环境造成了严重影响。这场事故不仅对日本国内产生了深远的影响,还在国际上引起了广泛的关注和忧虑。 事故发生后,大量的放射性物质进入了周围的环境,包括土壤、水源和空气中。这导致了广泛的区域污染,影响了人类的健康和生态系统的平衡。为了应对事故的后果,日本政府采取了一系列措施,包括限制区域的进入、清理工作以及处理核污水等。 核污水的处理一直是福岛核事故后的重要议题之一。多年来,日本政府一直在探讨如何安全地处理存储着放射性物质的污水。经过多次研究和讨论,日本政府最终提出了将经过处理的核污水排放至海洋的方案。然而,这一决策引发了全球范围内的争议和担忧,人们担心这可能会对海洋生态系统和人类健康造成不可逆转的影响。 在这个背景下,使用人工智能技术来预测福岛核污水排放对环境的影响变得尤为重要。借助人工智能的强大计算能力和数据分析能力,我们可以更加准确地模拟和预测核污水在海洋中的传播路径、浓度分布以及可能对生态系统产生的影响。这将为决策制定提供科学可靠的依据,帮助各方更好地了解核污水排放可能带来的风险和影响,从而做出明智的决策。
2.2 污水处理与排放决策
核污水的处理一直是福岛核事故后的重要议题之一。多年来,日本政府一直在探讨如何安全地处理存储着放射性物质的污水。经过多次研究和讨论,日本政府最终提出了将经过处理的核污水排放至海洋的方案。然而,这一决策引发了全球范围内的争议和担忧,人们担心这可能会对海洋生态系统和人类健康造成不可逆转的影响。 在这个背景下,使用人工智能技术来预测福岛核污水排放对环境的影响变得尤为重要。借助人工智能的强大计算能力和数据分析能力,我们可以更加准确地模拟和预测核污水在海洋中的传播路径、浓度分布以及可能对生态系统产生的影响。这将为决策制定提供科学可靠的依据,帮助各方更好地了解核污水排放可能带来的风险和影响,从而做出明智的决策。

3. 人工智能在环境影响预测中的应用
3.1 人工智能在科学研究中的角色
近年来,人工智能在科学研究领域的作用日益重要。尤其在复杂的环境影响预测中,人工智能展现出了其强大的潜力,为福岛核污水排放的环境影响预测提供了有力支持。
3.2 数据分析与模式识别能力
人工智能在环境影响预测中的一个关键能力是数据分析与模式识别。通过处理大量地理、气象、海洋学等数据,人工智能可以协助科学家们建立模拟并预测核污水在海洋中的传播路径和浓度分布。在复杂的海流、潮汐等环境因素的影响下,人工智能生成更精确的模型,帮助我们更好地理解核污水可能的扩散方式。 这种数据分析和模式识别能力使人工智能能够提供深入的洞察,协助科学家们定量评估不同因素对核污水传播的影响。通过分析历史数据和实时信息,人工智能可以预测海洋中可能出现的污染扩散模式,并协助制定相应的应对策略。
3.3 生态系统影响预测
此外,人工智能在预测核污水排放对海洋生态系统的影响方面也发挥着作用。通过分析各种生物群落的生态习性、物种分布等数据,人工智能可以模拟核污水可能引发的生态变化。这种能力对于评估潜在风险以及制定保护措施至关重要。 人工智能可以分析大量复杂的生态数据,预测不同生物群体之间相互作用的变化,以及外界干扰可能对生态平衡造成的影响。这样的预测有助于更好地理解核污水排放可能引发的连锁反应,为保护生态系统提供科学依据。
4. 影响预测的关键因素
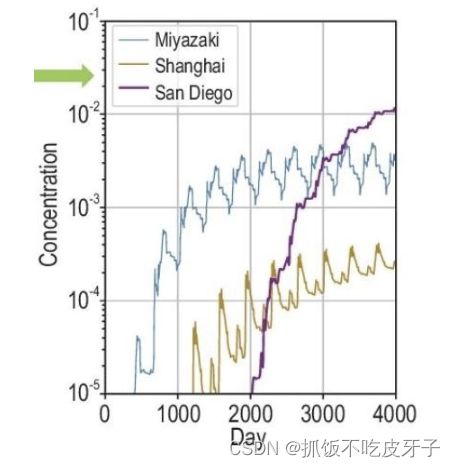
根据东京电力公司数据,核废水中包含63种放射性物质。核废水中的铯134、铯137半衰期长达30年,300年生态才会回复。研究显示,目前在福岛第一核电站存储的超过123万吨具有放射性污水中,含有放射性同位素锶90(Sr-90),放射性氚(超重水),碳14(C-14)以及其它放射性物质,如碘129(I-129)和钴60(Co-60)。
4.1 放射性物质种类与性质
放射性物质是核污水影响预测中的关键因素之一。不同种类的放射性核素在海洋中的行为与影响会有所不同,这直接影响了环境模拟和风险评估的准确性。以下是一些常见放射性物质种类及其性质:
- 氚(Tritium): 氚是一种放射性核素,以放射性衰变的方式释放出β粒子。它的半衰期相对较短,但因为在核事故中通常释放量较大,因此仍需关注其影响。氚在海洋中以水分子形式存在,容易与海水混合并扩散。
- 锶(Strontium): 锶核素在海洋中存在多个同位素,其中锶-90是最为常见的,以β粒子的形式衰变。它的化学性质使其在海洋生态系统中的积累可能会模仿钙,从而进入食物链。由于锶与钙的相似性,它可能在海洋生态系统中造成生物富集。
- 钚(Plutonium): 钚包括多个同位素,主要以α粒子的形式衰变。它们的半衰期较长,因此在核污水排放后可能会长时间存在。钚的高毒性和放射性使其对环境和生态系统构成潜在威胁。
- 碘(Iodine): 碘核素主要以放射性衰变的方式释放出β粒子和γ射线。碘的不同同位素具有不同的半衰期,其中碘-131半衰期较短,但释放量较大。碘在海洋中的行为受到生物吸收和沉降等因素的影响。 放射性物质的行为受到海洋环境因素的制约,例如海流、潮汐、水温等。人工智能在分析这些因素的相互作用上具有优势,能够更准确地预测放射性物质的扩散路径和浓度分布。了解不同放射性核素的性质以及它们在海洋中的行为对于准确评估潜在影响至关重要,这也是人工智能在环境影响预测中的关键作用之一。
4.2 海洋环流与扩散模式
海洋环流和扩散模式是影响放射性物质传播的重要因素。海洋中的流动模式会决定放射性物质的传输路径和分布范围。各种海洋环流,如大规模洋流系统和局部的潮汐流,都会对放射性物质在水体中的分散产生影响。 人工智能在分析和预测海洋环流方面发挥着关键作用。通过整合大量海洋观测数据,人工智能可以建立复杂的模型来模拟海洋环流的动态特性。这些模型可以帮助科学家预测放射性物质在海洋中的传播路径,从而更好地评估可能的影响范围。 此外,扩散模式也是预测放射性物质传播的关键因素。扩散模式考虑了物质在海水中的混合和分散过程,通常受到湍流、溶解度差异等因素的影响。人工智能可以利用数值模拟和数据分析来理解这些复杂的扩散机制,从而更精确地预测放射性物质的浓度分布。 综合考虑海洋环流和扩散模式,以及放射性物质的种类和性质,可以帮助科学家更好地预测核污水对海洋环境的影响。这些信息对制定有效的风险管理和环境保护策略至关重要。
4.3 生态系统的敏感性和适应性
生态系统的特性以及其中的生物群落对放射性物质的敏感性和适应性,对于预测放射性物质传播的影响具有重要意义。不同生态系统内的生物种类和生态互动关系会影响放射性物质在生物体中的富集和转移方式。 生态系统的敏感性是指生物群落对外界干扰或污染物质的反应程度。某些生物可能对放射性物质更为敏感,而另一些可能具有较高的耐受性。这取决于生物的生理特性、生活史策略以及其所处环境的特点。生态系统中的食物链关系也会影响放射性物质在生物体之间的传递途径。 生态系统的适应性指的是生物群落对环境变化的响应能力。一些生物可能会在受到放射性污染的情况下发生适应性变化,例如积累特定的抗放射性物质的机制。然而,这些适应性变化可能会影响整个生态系统的平衡,并在长期内产生不可预测的影响。 在预测放射性物质传播时,需要考虑不同生态系统的敏感性和适应性差异。科学家可以通过观察现有生物群落的结构和特征,以及分析类似污染事件的历史数据,来推断放射性物质在特定生态系统中的传播方式和潜在影响。此外,综合考虑生态系统的敏感性和适应性,可以更好地评估可能的生态风险,从而指导环境管理和保护措施的制定。 了解生态系统的敏感性和适应性对于准确预测放射性物质在环境中的行为至关重要。这有助于科学家更好地理解污染物传播的模式,从而更有效地保护生态环境和人类健康。
5. 数据收集与处理
5.1 辐射监测数据
辐射监测数据是预测放射性物质传播的关键基础,它可以提供放射性物质在不同时间和空间点的浓度信息。这些数据通常来自于各类辐射监测站点,如地面站、船只装置以及遥感卫星等。收集、整理和处理这些数据有助于科学家了解放射性物质在环境中的分布和变化趋势。 以下是一个示例代码,演示如何使用Python处理和可视化辐射监测数据。假设你已经获得了一组放射性物质浓度的时间序列数据,存储在名为 "radiation_data.csv" 的CSV文件中:
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
data = pd.read_csv('radiation_data.csv')
# 转换时间列为日期时间格式
data['timestamp'] = pd.to_datetime(data['timestamp'])
# 绘制放射性物质浓度随时间的变化
plt.figure(figsize=(10, 6))
plt.plot(data['timestamp'], data['concentration'], marker='o')
plt.xlabel('时间')
plt.ylabel('放射性物质浓度')
plt.title('放射性物质浓度变化')
plt.xticks(rotation=45)
plt.grid(True)
plt.show()
你可以使用Pandas库读取CSV文件,并将时间列转换为日期时间格式,然后使用Matplotlib库绘制放射性物质浓度随时间的变化图。 收集到的辐射监测数据可以用于构建预测模型,分析放射性物质传播的模式,识别潜在的影响范围,并为环境管理和保护措施提供依据。同时,数据处理的技术不仅限于示例中的简单可视化,还可以进行更复杂的统计分析、时间序列建模等,以更全面地理解放射性物质传播的特征。
5.2 海洋生态数据
海洋生态数据在预测放射性物质传播的影响时也起着关键作用。海洋生态系统中的物种分布、生物量、食物链关系等因素都会影响放射性物质在海洋环境中的传播和富集。收集、整理和分析海洋生态数据有助于深入理解生物群落的结构和变化,从而更准确地预测放射性物质的行为。 以下是一个示例代码,展示如何使用Python处理和可视化海洋生态数据。假设你已经获得了一组海洋生物种类和其对应的数量数据,存储在名为 "marine_eco_data.csv" 的CSV文件中:
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
data = pd.read_csv('marine_eco_data.csv')
# 绘制不同生物种类数量的条形图
plt.figure(figsize=(10, 6))
plt.bar(data['species'], data['quantity'])
plt.xlabel('生物种类')
plt.ylabel('数量')
plt.title('海洋生态数据')
plt.xticks(rotation=45)
plt.grid(True)
plt.show()
我们使用Pandas库读取CSV文件,然后使用Matplotlib库绘制不同生物种类数量的条形图。 海洋生态数据的分析有助于确定不同物种在海洋食物链中的位置,以及它们可能受到放射性物质影响的程度。这些信息可以与辐射监测数据相结合,提供更全面的放射性物质传播预测。
5.3 环境因素数据
环境因素数据对于预测放射性物质传播的影响至关重要。不同的环境因素,如水流、气象条件、海洋温度等,都会影响放射性物质在海洋中的传输和扩散过程。收集、整理和分析环境因素数据可以帮助科学家理解放射性物质传播的机制,并提高预测的准确性。 以下是一个示例代码,展示如何使用Python处理和可视化环境因素数据。假设你已经获得了一组与海洋环境因素相关的数据,存储在名为 "environmental_data.csv" 的CSV文件中:
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
data = pd.read_csv('environmental_data.csv')
# 绘制海洋温度随时间的变化曲线
plt.figure(figsize=(10, 6))
plt.plot(data['timestamp'], data['temperature'], color='blue', label='海洋温度')
plt.xlabel('时间')
plt.ylabel('温度')
plt.title('海洋温度变化')
plt.xticks(rotation=45)
plt.legend()
plt.grid(True)
plt.show()
# 绘制风速随时间的变化曲线
plt.figure(figsize=(10, 6))
plt.plot(data['timestamp'], data['wind_speed'], color='green', label='风速')
plt.xlabel('时间')
plt.ylabel('风速')
plt.title('风速变化')
plt.xticks(rotation=45)
plt.legend()
plt.grid(True)
plt.show()
在这个示例中,我们使用Pandas库读取CSV文件,然后使用Matplotlib库分别绘制海洋温度和风速随时间的变化曲线。 环境因素数据的分析可以帮助科学家了解不同因素如何影响放射性物质的传播和分布。通过将环境因素数据与辐射监测数据和海洋生态数据结合起来,可以建立更全面的预测模型,从而更好地预测放射性物质在海洋中的行为。 以上示例代码只是简单的演示,实际情况中可能需要更复杂的数据处理和分析方法,以更准确地理解和预测放射性物质的传播情况。
6. 构建集成预测模型
6.1 辐射传输模型
辐射传输模型是预测放射性物质在海洋中传播和扩散的关键工具。这些模型基于环境因素数据、辐射源的特性以及物理和化学过程来模拟放射性物质的行为。以下是一个示例代码,展示如何使用Python构建一个简单的辐射传输模型。
import numpy as np
def radiation_transport_model(environment_data, radiation_source_properties):
"""
辐射传输模型
参数:
- environment_data: 包含环境因素数据的字典,例如 {'water_temperature': 15.0, 'current_speed': 0.2}
- radiation_source_properties: 包含辐射源特性的字典,例如 {'source_strength': 100, 'half_life': 10}
返回值:
- 预测的辐射浓度
"""
water_temperature = environment_data['water_temperature']
current_speed = environment_data['current_speed']
source_strength = radiation_source_properties['source_strength']
half_life = radiation_source_properties['half_life']
# 在这里实现辐射传输模型,这可以是基于数学公式的模拟
# 以下是一个简化的示例模型,实际情况中需要更复杂的模型
decay_constant = np.log(2) / half_life
radiation_concentration = source_strength / (4 * np.pi * current_speed) * np.exp(-decay_constant * water_temperature)
return radiation_concentration
# 示例用法
environment_data = {'water_temperature': 15.0, 'current_speed': 0.2}
radiation_source_properties = {'source_strength': 100, 'half_life': 10}
predicted_concentration = radiation_transport_model(environment_data, radiation_source_properties)
print(f"预测的辐射浓度为: {predicted_concentration} Bq/m^3")
这个示例代码中,我们定义了一个简单的辐射传输模型
radiation_transport_model
,它接受环境因素数据和辐射源特性作为输入,并返回预测的辐射浓度。请注意,这只是一个非常简化的模型,实际情况中需要更复杂的模型来考虑更多的因素。 构建集成预测模型时,可以将这样的辐射传输模型与其他模型(如气象模型、海洋流动模型)结合起来,以提高预测的准确性。这些模型的集成可以通过机器学习方法来实现,例如随机森林或神经网络,以更好地预测放射性物质在海洋中的传播行为。
6.2 生态风险评估模型
生态风险评估是保护生态系统健康的重要工具,人工智能在这一领域的应用日益突出。通过数据分析和模式识别能力,人工智能可以帮助科学家更全面、准确地评估生态系统中的风险,从而指导环境管理和保护决策的制定。
数据收集与整合
生态风险评估涉及大量来自不同来源的数据,包括环境监测数据、生物多样性数据、地理信息等。人工智能可以自动收集、整合和清洗这些数据,确保数据的完整性和准确性。例如,可以利用数据爬虫技术从各种数据库和网站中抓取环境监测数据。
特征提取与模式识别
一旦数据准备就绪,人工智能可以帮助识别数据中的模式和特征。在生态风险评估中,模式识别可以用于发现生态系统中潜在的异常变化或趋势。例如,利用机器学习算法分析生物多样性数据,识别出某些物种的不寻常增加或减少,从而指示生态系统的健康状况。
风险预测与决策支持
基于历史数据和识别出的模式,人工智能可以构建风险预测模型。这些模型可以预测生态系统未来可能面临的风险,例如生物入侵、环境污染等。基于这些预测,决策者可以采取相应的措施来保护生态系统。例如,利用时间序列预测模型预测某个区域未来可能出现的水质变化。
示例代码:基于Python的时间序列预测模型
以下是一个示例代码,展示了如何使用简单的线性回归模型进行时间序列预测。在生态风险评估中,类似的模型可以根据过去的环境监测数据来预测未来的环境变化趋势。
pythonCopy codeimport numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
# 生成示例时间序列数据
np.random.seed(0)
time = np.arange(0, 100, 1)
data = 2 * time + np.random.normal(0, 10, size=len(time))
# 创建DataFrame
df = pd.DataFrame({'Time': time, 'Data': data})
# 划分训练集和测试集
train_df, test_df = train_test_split(df, test_size=0.2, shuffle=False)
# 训练线性回归模型
model = LinearRegression()
model.fit(train_df[['Time']], train_df['Data'])
# 预测
test_df['Predicted'] = model.predict(test_df[['Time']])
# 绘图
plt.figure(figsize=(10, 6))
plt.plot(train_df['Time'], train_df['Data'], label='Train Data')
plt.plot(test_df['Time'], test_df['Data'], label='Test Data')
plt.plot(test_df['Time'], test_df['Predicted'], label='Predicted Data')
plt.xlabel('Time')
plt.ylabel('Data')
plt.legend()
plt.show()
人工智能在生态风险评估模型中的数据分析和模式识别能力为科学家提供了更准确、全面的生态风险评估手段,帮助指导环境保护决策的制定和实施。
6.3 长期影响预测
在生态风险评估的基础上,进行放射性物质的长期影响预测是了解其潜在影响的重要步骤。长期影响预测需要考虑放射性物质在海洋生态系统中的积累、转化和生物放大等过程。以下是一个示例代码,展示如何使用Python构建一个简单的放射性物质长期影响预测模型。
def long_term_impact_prediction(radiation_concentration, initial_species_population, years):
"""
长期影响预测模型
参数:
- radiation_concentration: 预测的辐射浓度
- initial_species_population: 初始物种种群数量
- years: 预测的年数
返回值:
- 预测的物种种群数量随时间变化的列表
"""
impact_predictions = []
species_population = initial_species_population
for year in range(years):
# 在这里实现长期影响预测模型,考虑辐射影响、生物放大等因素
radiation_effect = radiation_concentration * species_population
species_growth_rate = 0.1 # 假设种群增长率为10%
species_population = species_population + species_growth_rate * species_population - radiation_effect
impact_predictions.append(species_population)
return impact_predictions
# 示例用法
predicted_concentration = 50 # 假设预测的辐射浓度为50
initial_population = 1000 # 初始物种种群数量为1000
simulation_years = 20 # 模拟的年数为20年
population_predictions = long_term_impact_prediction(predicted_concentration, initial_population, simulation_years)
print("预测的物种种群数量随时间变化:")
for year, population in enumerate(population_predictions, start=1):
print(f"年份:{year}, 物种种群数量:{population}")
在这个示例代码中,我们定义了一个简单的长期影响预测模型
long_term_impact_prediction
,它接受预测的辐射浓度、初始物种种群数量和预测的年数作为输入,并返回物种种群数量随时间变化的列表。这个模型考虑了辐射对种群的影响以及种群的生长和衰减。 实际情况中,长期影响预测模型需要更详细地考虑不同生物种类的特性、食物链关系、生态系统的动态变化等因素,以更准确地预测放射性物质对海洋生态系统的长期影响。
7. 人工智能在不确定性处理中的作用
不确定性是许多科学和工程领域中的一个重要问题,人工智能技术在处理模型不确定性方面发挥着关键作用。以下是关于模型不确定性挑战的部分内容,以及一个示例代码,展示了如何使用概率编程库来处理不确定性。
7.1 模型不确定性的挑战
在科学建模和预测中,模型往往是对现实世界的简化和抽象,而真实世界的复杂性和多样性可能导致模型的不确定性。这种不确定性可能来自多个方面,包括数据的不完整性、模型参数的估计误差、未知的影响因素等。处理模型不确定性的挑战在于,我们需要在预测和决策中考虑这些不确定性,以便更准确地评估风险并做出可靠的决策。
示例代码:使用概率编程库处理不确定性
以下是一个使用概率编程库(例如PyMC3)来处理模型不确定性的简单示例代码。在这个示例中,我们考虑一个简单的线性回归模型,并使用贝叶斯方法来估计模型参数的不确定性。
import pymc3 as pm
import numpy as np
import matplotlib.pyplot as plt
# 生成带有噪音的示例数据
np.random.seed(42)
x = np.linspace(0, 10, 20)
true_slope = 2.5
true_intercept = 1.0
noise = np.random.normal(0, 0.5, len(x))
y = true_slope * x + true_intercept + noise
# 构建贝叶斯线性回归模型
with pm.Model() as model:
slope = pm.Normal('slope', mu=0, sd=10)
intercept = pm.Normal('intercept', mu=0, sd=10)
sigma = pm.HalfNormal('sigma', sd=1)
mu = slope * x + intercept
likelihood = pm.Normal('y', mu=mu, sd=sigma, observed=y)
trace = pm.sample(1000, tune=1000)
# 绘制后验分布
pm.plot_trace(trace)
plt.show()
在这个示例中,我们使用PyMC3库构建了一个贝叶斯线性回归模型,其中考虑了斜率、截距和噪音的不确定性。通过采样方法,我们得到了参数的后验分布,从而可以更全面地理解模型的不确定性情况。 请注意,实际处理模型不确定性可能需要更复杂的模型和方法,具体取决于应用领域和问题的复杂程度。人工智能技术为我们提供了处理这些不确定性的工具和方法,帮助我们更好地理解和应对现实世界中的复杂性。
7.2 蒙特卡洛模拟与预测精度提升
蒙特卡洛模拟是一种基于随机采样的方法,用于解决复杂问题,特别是那些难以用解析方法求解的问题。在处理模型不确定性和预测精度提升方面,蒙特卡洛模拟被广泛应用。通过对模型参数和输入的随机采样,蒙特卡洛模拟可以帮助我们更好地理解模型的不确定性,并提供更准确的预测和决策支持。 蒙特卡洛模拟的基本思想是通过随机生成一系列样本,然后基于这些样本进行统计分析,从而得出关于模型行为和输出的概率分布信息。这种方法特别适用于复杂模型,因为它不依赖于模型的具体形式,而是基于模型的输入输出关系进行采样和分析。 以下是一个简单的蒙特卡洛模拟示例代码,展示了如何使用蒙特卡洛方法估计圆周率 π 的值。
pythonCopy codeimport numpy as np
def monte_carlo_pi(num_samples):
inside_circle = 0
for _ in range(num_samples):
x = np.random.uniform(-1, 1)
y = np.random.uniform(-1, 1)
distance = x**2 + y**2
if distance <= 1:
inside_circle += 1
pi_estimate = (inside_circle / num_samples) * 4
return pi_estimate
num_samples = 100000
estimated_pi = monte_carlo_pi(num_samples)
print("Estimated pi:", estimated_pi)
在这个示例中,我们随机生成了大量的点,并计算落在单位圆内的点的比例,从而估计出圆周率 π 的值。 蒙特卡洛模拟在处理模型不确定性时,可以通过多次采样模型参数、输入变量等,来得到输出的概率分布。这种方法在风险评估、金融建模、气候预测等领域具有广泛应用,能够提供更全面和准确的预测结果。 蒙特卡洛模拟的效率和精度取决于采样数量和采样方法的选择,以及问题的复杂程度。在应用中,可能需要结合其他技术和优化方法来提高模拟的效率和准确性。
7.3 风险沟通与公众参与
风险沟通与公众参与在各个领域中都起着重要作用,特别是涉及科学、技术和环境等方面的决策过程。它涉及将复杂的科学或技术信息传达给公众,以便他们能够理解潜在的风险和影响,并参与决策的制定。 风险沟通的目标是通过透明、清晰和准确的信息传递,增加公众对特定风险问题的认识,减少不必要的恐慌和误解。这需要考虑到不同受众的知识水平、价值观和需求,以便以最有效的方式传达信息。在风险沟通中,应当采用易于理解的语言,避免使用过多的专业术语,并提供相关数据和背景信息,以支持受众的决策过程。 公众参与是风险沟通的重要组成部分,它强调将受影响群体纳入决策的过程中。通过听取公众的意见、担忧和建议,决策者可以更全面地了解公众的需求,从而制定更具共识和可接受性的政策和措施。公众参与可以通过各种方式实现,如公开听证会、问卷调查、社区会议等,以确保广泛的声音被纳入决策过程。 在风险沟通和公众参与中,以下几点是值得注意的:
- 透明度与诚信:信息传递应该是诚实和透明的,避免隐瞒或歪曲事实,以保持公众的信任。
- 定制化信息:信息应根据受众的需求和背景进行定制,以确保信息的可理解性和实用性。
- 多向交流:建立双向交流渠道,让公众能够提出问题、表达观点,并获得及时的反馈。
- 科学支持:基于科学证据传达信息,避免基于猜测或情绪进行沟通,以增强信息的可信度。
风险沟通与公众参与是建立信任、减少不确定性并制定可持续决策的关键步骤。通过有效的沟通和参与,可以在复杂的风险环境中实现更好的决策结果。
8. 伦理与可持续性考虑
在各个领域的决策制定过程中,考虑道德和社会因素变得越来越重要。这是因为单纯追求经济利益或科技进步往往忽视了对人类、环境和社会的影响,可能导致不可逆转的损害。因此,决策者越来越需要在制定决策时考虑道德和社会的因素,以确保长期的可持续性和整体的利益。
道德考量
道德考量涉及对决策所涉及的价值观和道德原则进行认真思考。决策者需要评估不同选择对人权、社会公正、平等和公共利益的影响。道德决策可能涉及权衡不同利益之间的关系,确保不对任何群体造成不当的伤害,以及确保决策是基于正义和道德价值观的。
社会考量
社会考量涉及了解决策对社会结构、社区和文化的影响。决策者需要考虑决策是否会加剧社会不平等、影响弱势群体或破坏社区凝聚力。这需要在决策过程中积极寻求各方的意见和参与,以便更全面地了解潜在的社会影响,并做出相应的调整。
可持续性考虑
可持续性考虑强调的是在做出决策时要考虑长远的影响,以确保当前的行动不会损害未来的世代。这涉及到对资源的合理利用、环境保护和经济发展之间的平衡。决策者需要评估他们的决策对环境的影响,以及它是否有助于实现社会、经济和环境的可持续性。
道德和社会考量的挑战
在实践中,将道德和社会考量纳入决策过程可能会面临一些挑战。其中之一是如何平衡不同利益和价值观之间的冲突。此外,预测决策的长期影响也可能是复杂的任务,因为社会和环境系统通常是动态的、不确定的。 综合而言,将道德和社会因素考虑到决策中有助于建立一个更公正、更可持续的社会。通过仔细权衡不同利益、广泛征求意见并采用跨学科方法,决策者可以更好地应对现实世界的复杂性,从而取得更好的决策结果。
版权归原作者 抓饭不吃皮牙子 所有, 如有侵权,请联系我们删除。