
使用ChatGPT加个人微信公众号打造属于自己的AI助手
1、总体介绍
相信现在不少人已经体验过ChatGPT,并被它的智能程度所折服。ChatGPT可以高效的完成许多事,但就目前来说使用还是限制不少,如何进一步使用它和如何更加方便使用它是现在许多人的思考问题。在此,给各位介绍一下如何使用微信公众号和ChatGPT打造成一个方便的个人助手。
目的:将ChatGPT对接到个人公众号中,使得个人只需要携带能登录微信的设备且只连国内网的情况下可以顺利的使用ChatGPT;
实现方式:Python Flask(搭建微信公众号后台) + selenium(以类爬虫方式和ChatGPT交互);
前提:你已经能够使用ChatGPT(此处不教你怎么获得使用ChatGPT资格)。
2、实现
2.1 搭建微信公众号后台
网上很多教程,此处不予具体教学,自己直接去查即可。我的公众号后台也是直接csdn上copy别人的现成代码,使用Pyhon Flask框架搭建。
搭建到能实现将你发送过去的话再发回来即可,后面会对注意事项做补充。
2.2 用Python实现和ChatGPT的交互(核心)
此处使用Python selenuim实现的类爬虫,并将其封装成自己用的API,供微信公众号后台调用。基本流程为:
启动浏览器并打开ChatGPT网页 >> 浏览器监听 >> 登录验证 >> 进入对话页面 >> 输入对话内容并发问,然后等待回答完成 >> 提取答案
本人使用chrome浏览器,需要设置为浏览器记住openai的账户和密码,即每次进入时候只需要进行人机验证即可。公众号后台使用的是自己的电脑,所以本人的电脑已经设置为只有chrome从梯子访问,别的都是使用内网(因为公众号后台好像不能是国外网)。下面对各个环节的实现做介绍。
2.2.1 启动/关闭浏览器
这里的重点是通过python控制打开浏览器后能够自动加载用户的设置,因为这样打开的浏览器才能自动加载登录openai需要的内容。打开浏览器的程序如下(所有的def都已经封装到一个class中的):
defboot_chrome(self):return os.popen("\"C:\Program Files\Google\Chrome\Application\chrome.exe\" "+str(self.url)+" --remote-debugging-port=9527")defclose_chrome(self):return os.popen("powershell -command \"Get-Process chrome | ForEach-Object { $_.CloseMainWindow() | Out-Null}\"")
其中
self_url
是https://chat.openai.com/(字符串格式),
--remote-debugging-port=9527
即以9527端口进行debug,这是为了后面可以通过selenuim进行监听。
执行上面的程序后即可自动打开浏览器并打开ChatGPT页面。
2.2.2 开启监听(实现程序和浏览器交互)
这里作用是使用selenium控制浏览器。程序如下:
defstart_listen(self):# 整个的前提是开着外网,且chrome打开后自动使用设置的代理窗口,本机整体不使用代理端口print("开始监听端口")try:
self.driver = webdriver.Chrome(options=self.opt)except Exception as e:if"cannot connect to chrome"instr(e):try:
self.close_chrome()except Exception as e:passprint("重启 chrome")
self.close_chrome()
self.init_value()# time.sleep(1)
self.boot_chrome()
time.sleep(10)
self.driver = webdriver.Chrome(options=self.opt)
time.sleep(1)print("监听设置正常")
self.driver
即建立监听对象。这里是在启动浏览器后运行,如果出错,即浏览器没有打开或者别的原因,所以重新打开浏览器并初始化一些需要的变量。
self.opt
设置如下(结合程序启动需要构建了
inti function
,后面有些程序也需要里面的变量):
# def __init__的内容def__init__(self, url, inform_user =None):# 一些基本信息
self.listen_port ="127.0.0.1:9527"# 验证选框位置
self.screen_x =[(1337,1361),(1378,1456)]
self.screen_y =[(616,642),(622,633)]
self.move_range =[1919,1079]# 需要操作的元素的xpath,这是个体力活,从chatgpt对话页面逐个扒下来的
self.x_path ={"pre_stage":"//*[@id=\"challenge-stage\"]","confirm1":'//*[@id="cf-stage"]/div[6]/label',"confirm1_new":"//*[@id=\"cf-stage\"]/div[6]/label/span","ifram":"/html/body/div/div[2]/form/div[4]/div/div/iframe","confirm2":r"/html/body/div/div[2]/form/div[4]/div/input","send_content":"//*[@id=\"__next\"]/div[1]/div[1]/main/div[2]/form/div/div[2]/textarea","send_key":"//*[@id=\"__next\"]/div[1]/div[1]/main/div[2]/form/div/div[2]/button",# "verif_pic": ""# text获取"receive_path_base":"//*[@id=\"__next\"]/div[1]/div[1]/main/div[1]/div/div/div/div[2]/div/div[2]/div[1]/div/div","child_ele":"/child::*","code_copy":"/div/div[1]/button","re_ques_flag":"//*[@id=\"__next\"]/div[1]/div[1]/main/div[2]/form/div/div[1]/button/div","chatgpt_error1":"//*[@id=\"__next\"]/div[1]/div[1]/main/div[2]/form/div/div/span","chatgpt_error2":"//*[@id=\"__next\"]/div[1]/div[1]/main/div[1]/div/div/div/div[2]/div/div[1]/div/span","chatgpt_error3":"//*[@id=\"__next\"]/div[1]/div[1]/main/div[1]/div/div/div/div[2]/div/div[2]/div[1]/div/div","隐私":"//*[@id=\"privacy-link\"]","条款":"//*[@id=\"terms-link\"]"}
self.url = url
self.init_value()
self.screen_controler = pyautogui
self.screen_controler.PAUSE =1
self.screen_controler.FAILSAFE =True
self.opt = webdriver.ChromeOptions()
self.opt.debugger_address = self.listen_port # 后面可以尝试加opt,目标这个就够用了
self.init_value()
用于初始化一些辅助变量:
# 有的变量在新的程序中可能没有被用到definit_value(self):
self.content_num =0
self.answer_finish =0
self.verif_finish =0
self.get_content =0
self.confirm1 =0
2.2.3 人机验证(重点难点)
这是最麻烦的一步,不得不感叹openai这网页对人机识别的准确。我在2月20号左右开始使用ChatGPT,那时有两种人机验证形式,一种是一个灰色按钮,英文是verify you are human,这种直接selenium控制点击相应html元素即可,但后来被取消了;一种是给了个框,需要勾选,但直接用selenium控制元素去click发现成功率很低,并且这种是被保留下来的方式。
在两种都存在时候,我是去检测是否是第一种检测方式,不是则刷新网页,刷新几次后就会是第一种验证方式,但后来被取消了,为此不得不去攻关,重点是要模拟得够像一个人去操作。我的方式是固定浏览器的位置和大小,这样每次选择框都是在固定位置,然后用python模拟鼠标,将光标移动到选择框区域后控制点击鼠标。程序如下,并给出每步的注释(程序中只保留了勾选框进行验证的情况) :
defopenai_verif(self):# 要求打开浏览器不需要输入 账号密码,而是只需要# 一开始打开时候,会让你点击以证明你是真人
time.sleep(2)
self.driver = webdriver.Chrome(options=self.opt)#1、检测是否已经有对话框元素。有时不要进行人机验证,所以检测是否直接进入对话页面,是的话则跳过验证程序if self.isElementExist(self.x_path["send_content"])or self.isElementExist(self.x_path["chatgpt_error1"]):returnTrue
self.verif_finish =0#2、检测是否已经进入人机验证页面
wait = WebDriverWait(self.driver,120,0.5)
wait.until(EC.presence_of_element_located((By.XPATH, self.x_path["pre_stage"])))
makeSureFlag =0
self.confirm1 =0#3、开始进行人机验证while makeSureFlag ==0:if self.confirm1 ==2:# 限制验证次数print("自动验证次数超出限制")returnFalse# 如果有ifram需要格外的操作,这也是编程时候遇到的一个小槛
wait = WebDriverWait(self.driver,15,1)
wait.until(EC.presence_of_element_located((By.XPATH, self.x_path["ifram"])))try:#4、切换到ifram下
self.driver.switch_to.frame(0)
time.sleep(0.5)# 等待切换完成#5、验证是否已经出现验证框
wait = WebDriverWait(self.driver,15,1)if(self.confirm1/1==0):# 用两个元素交互着来判断,目的是默认人工操作
wait.until(EC.presence_of_element_located((By.XPATH, self.x_path["confirm1"])))else:
wait.until(EC.presence_of_element_located((By.XPATH, self.x_path["confirm1_new"])))
time.sleep(1.5)# 进入这一步说明已经出现验证勾选框# 6.控制鼠标模拟人的点击操作
self.verif_click()# 7、判断是否进入对话主页面
WebDriverWait(self.driver,10,1).until(EC.presence_of_element_located((By.XPATH, self.x_path["send_content"])))
makeSureFlag =1# 说明已经进入,对话主页面,while打断except Exception as e:# 说明人机验证没通过,所以通过while进入下一次验证
self.confirm1 = self.confirm1 +1
self.verif_finish =1returnTrue
其中
self.verif_click()
函数和检测html元素是否存在的函数如下:
# 点击鼠标进行人机验证操作defverif_click(self):#1、随便移动一个位置
position_x = random.randint(0, self.move_range[0])
position_y = random.randint(0, self.move_range[1])
self.screen_controler.moveTo(position_x, position_y, duration=random.uniform(0,0.2))#2、移动到验证区域,然后开始点击验证按钮
i = random.randint(0,1)
screen_x = self.screen_x[i]# 在init函数中
screen_y = self.screen_y[i]
position =(random.randint(screen_x[0], screen_x[1]),
random.randint(screen_y[0], screen_y[1]))
self.screen_controler.PAUSE =1
self.screen_controler.moveTo(position[0], position[1], duration=0.2)
self.screen_controler.doubleClick()#3、从验证按钮上移动开
position_x = random.randint(0, self.move_range[0])
position_y = random.randint(0, self.move_range[1])
self.screen_controler.moveTo(position_x, position_y, duration=random.uniform(0,0.1))
time.sleep(3)# 检测元素是否存在defisElementExist(self, xpath):
flag =Truetry:
self.driver.find_element(by=By.XPATH,value=xpath)except:
flag =Falsereturn flag
过程中会首先控制鼠标移动到一个任意位置,然后再移动到勾选框区域。勾选框区域是一个范围,所以具体到那个像素点通过用随机函数选择勾选框区域内一个任意点的方式得到,点击后停留0.25s,然后移开鼠标。这个过程的宗旨就是要模拟得尽量像个人。改用这样验证后可以达到80%的成功率。
还有一个补充是如果验证失败次数达到上限,则直接重启浏览器后再进行验证,直到成功,这也是人机验证程序的封装:
defenter_verif(self):while self.openai_verif()==False:print("重启浏览器和监听器")
self.reboot_chrome()
获取验证区域像素的程序如下:
pyautogui.PAUSE =1# 暂停的时间
pyautogui.FAILSAFE =True# 自启动故障处理whileTrue:print("获取登录按钮坐标")
time.sleep(3)print(pyautogui.position())##获取当前鼠标坐标
将鼠标放到验证区域,根据print结果去更改
self.screen_x
和
self.screen_y
即可。因为框和文字都可以点击来实现勾选,所以这个坐标区域有两个。如下: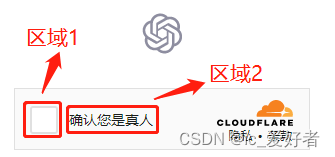
2.2.4 输入对话
通过人机验证进入主界面后,即可通过selenium控制着输入对话内容。程序如下:
definput_wait(self, str_conent):# str_conent为输入的问题
self.answer_finish =0# 1.检测是否出现对话错误ifnot self.input_error():returnFalse# 2.累加对话次数,以知道对应对话界面的第几个元素
self.content_num = self.content_num +2
self.x_path["receive_path_base"]="//*[@id=\"__next\"]/div[1]/div[1]/main/div[1]/div/div/div/div["+ \
str(self.content_num)+"]/div/div[2]/div[1]/div/div"
ques_content =str(str_conent)# 3.往对话框中输入问题,延时后点击发送按钮(也是为了模拟人的行为)
self.driver.find_element(by=By.XPATH, value=self.x_path["send_content"]).send_keys(str(ques_content))
time.sleep(1)
self.driver.find_element(by=By.XPATH, value=self.x_path["send_key"]).click()# 4.等待开始进行回答 # 即判断是否出现答案元素
wait = WebDriverWait(self.driver,120,1)
wait.until(EC.presence_of_element_located((By.XPATH, self.x_path["receive_path_base"])))
wait = WebDriverWait(self.driver,120,1)
wait.until(EC.presence_of_element_located((By.XPATH, self.x_path["re_ques_flag"])))# 5、等待回答结束while self.isElementExist(self.x_path["re_ques_flag"]):#re.match(r".*Stop.*", flag_cont):
time.sleep(1)ifnot self.input_error():# 过程中同时检测回答是否错误returnFalse# 6、检测回答停止按钮的内容
WebDriverWait(self.driver,120,1).until(EC.presence_of_element_located((By.XPATH, self.x_path["re_ques_flag"])))
flag_cont = self.driver.find_element(by=By.XPATH, value=self.x_path["re_ques_flag"]).text
# 7.这步配合微信使用,使得用户可以通过微信来停止chatgpt的回答if re.match(r".*Stop.*", flag_cont)and stop_flag["stop"]:
self.driver.find_element(by=By.XPATH, value=self.x_path["re_ques_flag"]).click()
stop_flag["stop"]=False# 8、回答停止按钮的内容变为重新生成回答,则说明回答结束,跳出循环if re.match(r".*Regenerate.*", flag_cont):break
self.answer_finish =1returnTrue
重点就是判断是否回答结束或者页面错误,并实现可以通过微信控制chatgpt停止回答。判断回答结束通过检测下面按钮的内容: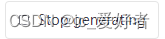 回答结束时候内容如下:
回答结束时候内容如下: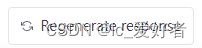
还有对于错误的处理。以下这种情况就是回答出错了: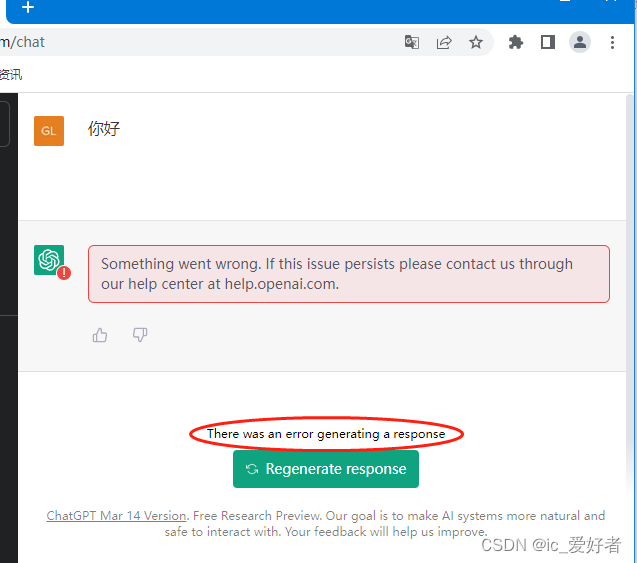
对错误的检测如下:
definput_error(self):if self.isElementExist(self.x_path["chatgpt_error1"]):
flag_cont = self.driver.find_element(by=By.XPATH, value=self.x_path["chatgpt_error1"]).text
if(flag_cont =="There was an error generating a response"):returnFalseelse:returnTrue
检测到错误的处理后面会介绍。
停止回答则是会在微信后台检测微信端发来的内容,如果内容是
停止回答
,则会设置相应的标志位,在等待回答结果的过程中会去检测这个标志位是否为1,为1则点击停止回答按钮,然后退出等待。
2.2.5 获取答案
在回答结束后就要获取答案,这也是关键一环,重点是能正确定位到回答内容元素并检测其中有啥内容。重要是能够提取出文字加代码,并按照chatgpt的回答安排对内容的顺序。为此,是首先定位到本次回答的内容,然后获取其中的children元素,根据children元素的顺序去获取内容,文字则直接通过元素获取,代码则利用回答中的
copy
按钮。这部分的代码以及注释如下:
defanswer_content(self):
answer_content =[]# 用列表装回答内容
self.get_content =0# 1、获取本次回答内容根路径下的子元素
childrens = self.driver.find_elements(by=By.XPATH, value=self.x_path["receive_path_base"]+self.x_path["child_ele"])# 用c求等差数列的和# 2、根据元素类别进行内容提取#分为文本类型、代码类型、列表类型(ol类型、ul类型)
text_num, code_num, ol_num, ul_num =0,0,0,0for i in childrens:# 3、获取子元素名称
i =str(i.tag_name)# 文本类型if i =="p":
text_num = text_num +1
text_content = self.driver.find_element(by=By.XPATH, value=self.x_path["receive_path_base"]+"/"+i+'['+str(text_num)+']').text
# 4.将内容提取到列表中
answer_content.append(text_content+"\n")# 列表类型,即1. xxx 2.xxx 或者 [] xxx [] xxx 这种# 列表类型需要得到有几个列表,然后逐个提取内容if i =="ol"or i =="ul":# list content
ol_xpath = self.x_path["receive_path_base"]+"/"+ i
if(i =="ol"):
ol_num =1+ ol_num
ol_xpath = ol_xpath +'['+str(ol_num)+']'if(i =="ul"):
ul_num =1+ ul_num
ol_xpath = ol_xpath +'['+str(ul_num)+']'
childrens_ol = self.driver.find_elements(by=By.XPATH, value=ol_xpath + self.x_path["child_ele"])
li_num =0for i_ol in childrens_ol:
li_num =1+ li_num
xpath = ol_xpath+"/"+str(i_ol.tag_name)+'['+str(li_num)+']'
childrens_li = self.driver.find_elements(by=By.XPATH,
value=xpath + self.x_path["child_ele"])try:
xpath = xpath +"/"+str(childrens_li[0].tag_name)except Exception as e:
xpath = xpath
text_content =str(li_num)+": "+ self.driver.find_element(by=By.XPATH,value=xpath).text
# 4.将内容提取到列表中
answer_content.append(text_content+"\n")# 代码类型if i =="pre":
code_num = code_num +1
xpath = self.x_path["receive_path_base"]+"/"+i+'['+str(code_num)+']'+self.x_path["code_copy"]# 点击copy按钮
self.driver.find_element(by=By.XPATH,value=xpath).send_keys(Keys.ENTER)# 从剪贴板中提取内容
text_content = cb.paste()
time.sleep(0.2)# 4.将内容提取到列表中
answer_content.append(text_content+"\n")
self.get_content =1# 表示回答结束# 5、将回答内容按顺序组织成完整对话内容
str_content =""for i in answer_content:
str_content = str_content + i
return str_content
这样即完成了输入问题和获取答案两步,将这两步整合到一起:
definput_get(self, ques_str):
fresh_flag =False# 1、# 如果输入的是这三种内容,这会刷新浏览器
fresh_list ="fresh 新建对话 刷新"if ques_str in fresh_list:
fresh_flag =True
self.refresh()# 刷新浏览器# 2、检测页面是否是重启浏览器if(ques_str =="reboot"):
fresh_flag =True
self.reboot_chrome()# 重启浏览器if fresh_flag ==False:# 说明不是刷新或者重启浏览器,则进入chatgpt对话
input_count =0
time.sleep(1)# 3.开始提问# 这时检测是否回答出错,如果错误前三次执行刷操作,三次刷新都不成则直接重启浏览器while self.input_wait(ques_str)==False:# 等待提问完成print("提问错误")if(input_count ==3):
self.reboot_chrome()else:
self.refresh()
input_count = input_count +1# 4.提取回答内容,并返回
answer_content = self.answer_content()# 获取答案并返回return answer_content
else:return"已经处理完成"
这里面的的补充操作有刷新和重启浏览器,这些操作都是为了应对页面出错,提高程序的鲁棒性。代码如下:
# 重启浏览器defreboot_chrome(self):
self.close_chrome()
self.init_value()
self.boot_chrome()
time.sleep(5)
self.start_listen()
self.enter_verif()# 刷新浏览器defrefresh(self):
self.driver.refresh()
self.content_num =0
self.answer_finish =0
self.verif_finish =0
self.get_content =0
self.start_listen()
self.enter_verif()
至此完成主体程序设计,将其封装为一个class即可。
2.3 python与chatgpt的简单验证和效果展示
代码如下:
if __name__ =='__main__':
url ="https://chat.openai.com/"
openai_ofme = ChatGPTOfMe(url)# 启动浏览器
openai_ofme.boot_chrome()
time.sleep(10)
openai_ofme.start_listen()# # 进行人机验证 # 超出验证次数则重新启动
openai_ofme.enter_verif()whileTrue:
ques_str =input("请输入你的问题:")if(ques_str =="quit"):
openai_ofme.close_chrome()breakprint(openai_ofme.input_get(ques_str))
效果如下: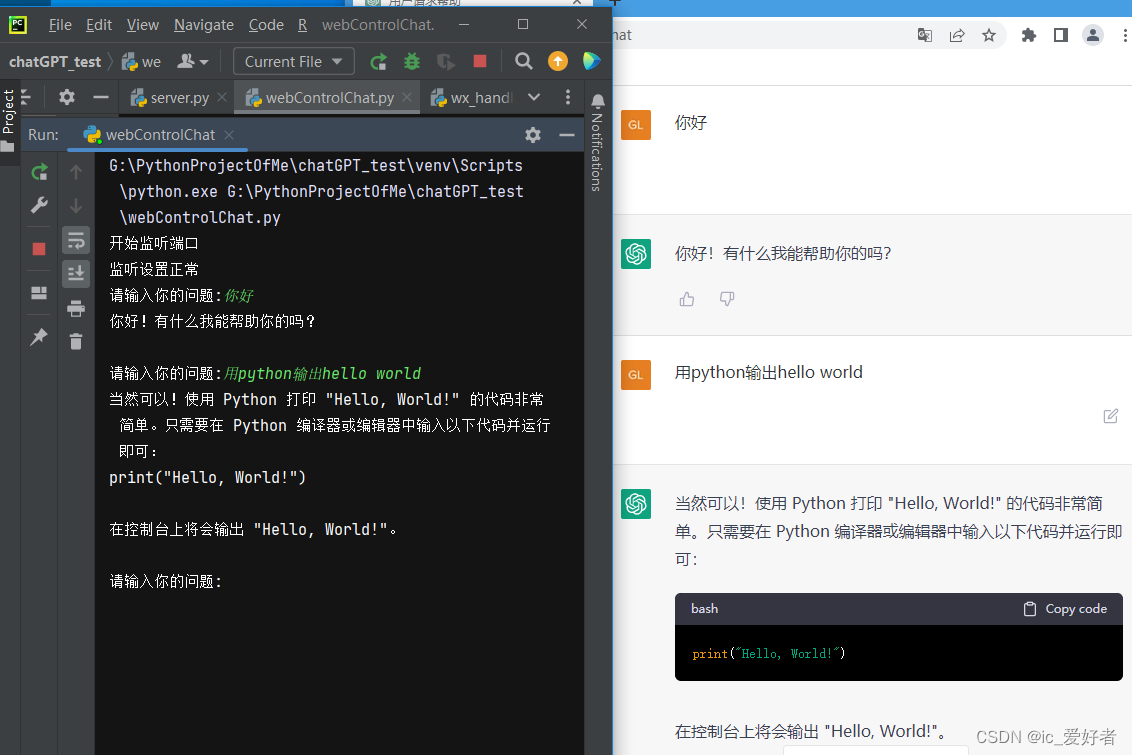
2.4 对接到微信公众号
我将chatgpt的控制程序使用一个单独的线程进行控制,代码如下:
dic_of_reply ={"answer":"","lock":False,"question":"","fresh_flag":False,"boot_done":False,"get_new":False,"stop":False,"pre_user_id":"","allow_user_id":["这里放允许的用户的openid"],"make_fresh":False,"stop_listen":False}defchat_with_GPT():# 专门开一个线程给他print("开始启动机器人")
url ="https://chat.openai.com/"# url = "https://www.bing.com/"
ChatGPTof_Me = ChatGPTOfMe(url)# 启动浏览器
ChatGPTof_Me.boot_chrome()
time.sleep(6)
ChatGPTof_Me.start_listen()
ChatGPTof_Me.enter_verif()print("验证成功")
i =0
dic_of_reply["boot_done"]=TruewhileTrue:if(dic_of_reply["stop_listen"]):
ChatGPTof_Me.driver.stop_client()
dic_of_reply["stop_listen"]=Falseif dic_of_reply["make_fresh"]:print("为新用户刷新页面")
ChatGPTof_Me.driver.stop_client()
ChatGPTof_Me.refresh()
dic_of_reply["fresh_flag"]=False
dic_of_reply["make_fresh"]=Falseif(dic_of_reply["lock"]):
i =0
ChatGPTof_Me.driver.stop_client()
dic_of_reply["answer"]= ChatGPTof_Me.input_get(dic_of_reply["question"])
dic_of_reply["lock"]=False#解锁
time.sleep(1)
i = i +1if(i ==8*60):# 5 分钟
i =0
dic_of_reply["fresh_flag"]=True
threading.Thread(target=chat_with_GPT).start()print("等待机器人启动完成")whilenot dic_of_reply["boot_done"]:
time.sleep(1)print("机器人完成启动")
机器人启动完成后会设置标志位,然后去启动公众号后台。启动后台后将来自微信端的消息进行处理,这里处理的带入如下:
# 1、提取提问内容和用户id
ques_str =str(receive_msg.content)
user =str(receive_msg.fromUser)print(user)# 2、判断用户是否在允许列表中,不在则返回固定消息,在这转发给gptif user in dic_of_reply["allow_user_id"]:passelse:return reply.TextMsg(receive_msg,"欢迎来到xxx").send()# 3、如果是停止回答的请求,则去设置字典中相关标志位if re.match(r"^停止.*", ques_str):
stop_flag["stop"]=Truereturn reply.TextMsg(receive_msg,"已经去停止机器人的回答").send()# 4、lock表示有用于正在提问if dic_of_reply["lock"]:if user != dic_of_reply["pre_user_id"]:# 表示正在回答你的问题,但还没回答完成
answer_str ="有人正在使用,请一会儿再来!!!"else:
answer_str ="正在为你获取答案,请一会儿再来!!!"# 5、判断是来获取答案elif(dic_of_reply["get_new"]and user == dic_of_reply["pre_user_id"]):
answer_str ="你上一个问题的答案是: \n"+ dic_of_reply["answer"]# 返回答案
answer_str_encode = answer_str.encode("utf-8")# 答案过大,则分段回复if(len(answer_str_encode)>2048):# 将答案分为几个段print(len(answer_str_encode))
answer_str = answer_str_encode[:1800].decode("utf-8", errors='ignore')
answer_str +="\n 由于答案过大,无法一次发送完整。请再发消息给我,获取剩余的答案"
dic_of_reply["answer"]= answer_str_encode[1800::].decode("utf-8", errors='ignore')# 表示全部答案已经拿走else:
dic_of_reply["get_new"]=False# 指示已经提取了新答案
dic_of_reply["stop_listen"]=True# 6、判断上一个用户是否把他的答案拿走elif(dic_of_reply["get_new"]and user != dic_of_reply["pre_user_id"]):
answer_str ="请稍等,上一个人还没拿走答案"# 7、进入正常提问环节else:
dic_of_reply["question"]= ques_str
dic_of_reply["lock"]=True# 上锁 # 开始去问答
dic_of_reply["get_new"]=True# 指示开始获取新答案if(user != dic_of_reply["pre_user_id"])or dic_of_reply["fresh_flag"]:
dic_of_reply["make_fresh"]=True# 表示是回答新用户的问题,要刷新页面
dic_of_reply["pre_user_id"]= user
answer_str ="你好,开始去回答你的问题,请过会再来"
这里有几个
个人公众号的坑点和自己的解决方案
:
(1)公众号要在5s内给出回答,不然认为后台错误。但chatgpt回答是需要时间的,长问题绝对超过5s,所以这里将一次问答分成两次微信端提问,第一个给gpt你的问题,第二次来拿走答案,这样来避开5秒限制;
(2)一次发送的内容不能超过2048个byte。所以每次发送答案检测答案是否超过2048,超过则对答案截断,分几次给答案;
(3)这样的chatgpt是不可能多人同时使用的,所以采用
分时使用策略
。如果有人在使用,则进行lock,在这个人拿走它的答案时候解锁,允许下一个用户进行提问。
至此完成全部关键设计。
2.5 最终效果展示
我们运行起后台,去公众号中提问,效果如下:
这样就可以随时随地的使用chatGPT且只需要连接内网。我个人的初衷是在公司里面也能使用chatGPT,因为基于安全考虑我不可能在公司的电脑上装个梯子,这样看是达到了自己想要的效果。
3、完结撒花
1、为何不使用api:我没能成功用起来,尝试了多次,所以另辟蹊径。并且api没上下文记忆功能;
2、介于ChatGPT人机验证的严格,我在一周期已经改为对接到New Bing,整体思路类似;
我的python-chatgpt交互代码:我的代码
版权归原作者 ic_爱好者 所有, 如有侵权,请联系我们删除。