
作者:来自 Elastic Steve Dodson
有多种策略可以将特定领域的知识添加到大型语言模型 (LLM) 中,并且作为积极研究领域的一部分,正在研究更多方法。 对特定领域数据集进行预训练和微调等方法使 LLMs 能够推理并生成特定领域语言。 然而,使用这些 LLM 作为知识库仍然容易产生幻觉。 如果领域语言与 LLM 训练数据相似,则通过检索增强生成 (RAG) 使用外部信息检索系统向 LLM 提供上下文信息可以改善事实响应。 最终,微调和 RAG 的组合可能会提供最佳结果。
该博客试图描述一些存储和检索 LLMs 知识的基本过程。 后续博客将更详细地描述不同的 RAG 策略。
Pre-training(预训练)Fine-tuning (微调)Retrieval Augmented Generation (RAG)训练时间几天,几周甚至几个月几分钟到几小时不需要定制需要大量领域训练数据
可定制模型架构、大小, 分词器等
创建新的 “基础” LLM 模型添加特定于域的数据
针对特定任务进行调整。
更新LLM模型。没有模型权重
外部信息检索系统可以调整以与 LLM 对齐。
提示可以优化以提高任务性能。目的下一个 token 预测提高任务绩效提高特定领域文档集的任务性能专业知识高中低
介绍
基于大型语言模型 (LLM) 的生成式人工智能技术极大地提高了我们开发处理、理解和生成文本工具的能力。 此外,这些技术引入了创新的信息检索机制,其中生成式人工智能技术使用模型存储的(参数)知识直接响应用户查询。
然而,值得注意的是,模型的参数知识是整个训练数据集的浓缩表示。 因此,将这些技术应用于原始训练数据之外的特定知识库或领域确实存在一定的局限性,例如:
- 生成人工智能的响应可能缺乏上下文或准确性,因为它们无法访问训练数据中不存在的信息。
- 有可能产生听起来合理但不正确或误导性的信息(幻觉)。
存在不同的策略来克服这些限制,例如扩展原始训练数据、微调模型以及与特定领域知识的外部源集成。 这些不同的方法会产生不同的行为并带来不同的实施成本。
特定领域的预训练

LLMs 接受了代表各种自然语言用例的庞大数据集的预训练:
模型总数据集大小数据来源训练成本PaLM 540B7800 亿 tokens社交媒体对话(多语言)50%; 过滤网页(多语言)27%; 书籍(英文)13%; GitHub(代码)5%; 维基百科(多语言)4%; 新闻(英文)1%8.4M TPU v2 hoursGPT-34990 亿 tokens普通爬行(已过滤)60%; WebText2 22%; 书籍18%; 书籍 28%; 维基百科 3%0.8M GPU hoursLLaMA 22 兆 tokens“来自公开来源的数据混合”3.3M GPU hours
这个预训练步骤的成本是巨大的,并且需要大量的工作来整理和准备数据集。 这两项任务都需要高水平的技术专业知识。
此外,预训练只是创建模型的第一步。 通常,然后在针对特定任务精心策划和定制的较小数据集上对模型进行微调。 此过程通常还涉及人工审核员,他们对可能的模型输出进行排名和审核,以提高模型的性能和安全性。 这进一步增加了过程的复杂性和成本。
这种方法应用于特定领域的示例包括:
- ESMFold、ProGen2 等 - 蛋白质序列的 LLM:蛋白质序列可以使用类似语言的序列表示,但不被自然语言模型覆盖
- Galatica - 科学 LLM:专门接受大量科学数据集的培训,并包括处理科学符号的特殊处理
- BloombergGPT - 金融 LLM:接受 51% 金融数据、49% 公共数据集的培训
- StarCoder - 代码 LLM:使用 384 种编程语言的 6.4TB 许可源代码进行培训,并包含 54GB GitHub 问题和存储库级元数据
特定领域模型通常优于各自领域内的通用模型,在与自然语言显着不同的领域(例如蛋白质序列和代码)中观察到最显着的改进。 然而,对于知识密集型任务,这些特定领域模型由于依赖参数知识而受到相同的限制。 因此,虽然这些模型可以更有效地理解领域的关系和结构,但它们仍然容易出现不准确和幻觉。
特定领域的微调
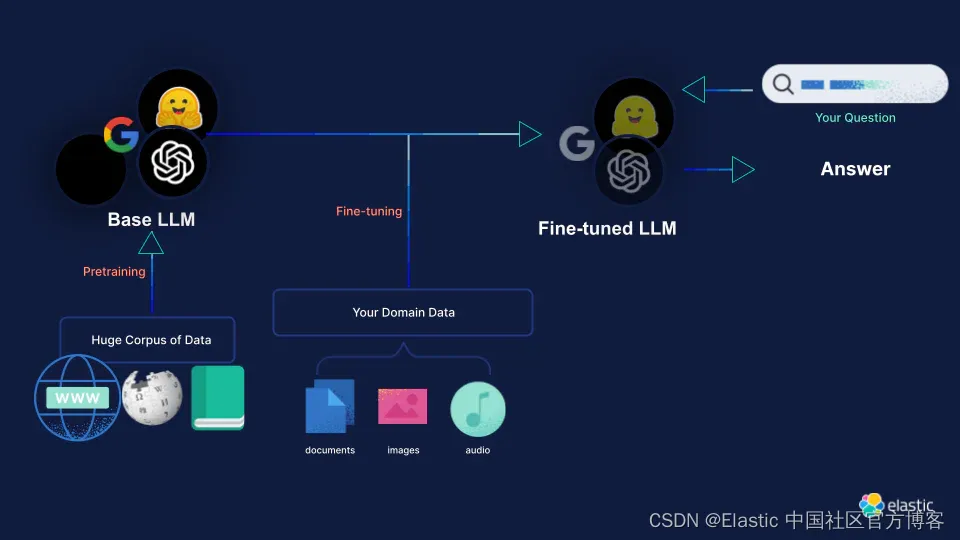
LLMs 的微调涉及针对特定任务或领域训练预先训练的模型,以提高其在该领域的表现。 它通过使用特定于任务的数据更新模型的参数,使模型的知识适应更狭窄的上下文,同时保留在预训练期间获得的一般语言理解。 这种方法针对特定任务优化了模型,与从头开始训练相比,节省了大量时间。
例子
- Alpaca - 经过微调的 LLaMA-7B 模型,其行为在质量上与 OpenAI 的 GPT-3.5 类似
- xFinance - 针对特定金融任务的微调 LLaMA-13B 模型。 据报道,其表现优于 BloombergGPT
- ChatDoctor - 用于医疗聊天的微调 LLaMA-7B 模型。
- falcon-40b-code-alpaca - 经过微调的 falcon-40b 模型,用于从自然语言生成代码
成本
微调的成本明显低于预训练的成本。 此外,诸如参数高效微调(PEFT)方法(例如如上所述的 LoRA、适配器、提示调整和上下文学习)等新颖方法可以使预训练语言模型(PLM)非常有效地适应各种不同的环境。 下游应用程序无需微调所有模型参数。 例如,
模型微调方法微调数据集成本Alpaca Self-Instruct52K 条独特的指令和相应的输出3 hours on 8 80GB A100s:24 GPU hoursxFinance使用 xTuring 库进行无监督微调和指令微调493M token文本数据集; 82K指令数据集25 hours on 8 A100 80GB GPUs:200 GPU hoursChatDoctorSelf-Instruct11 万次医患互动3 hours on 6 A100 GPUS: 18 GPU hoursfalcon-40b-code-alpacaSelf-Instruct52K指令数据集; 20K 指令输入代码三元组4 hours on 4 A100 80GB GPUs: 16 GPU hours
与特定领域的预训练模型类似,这些模型通常在各自的领域内表现出更好的性能,但它们仍然面临与参数知识相关的限制。
检索增强生成 - RAG
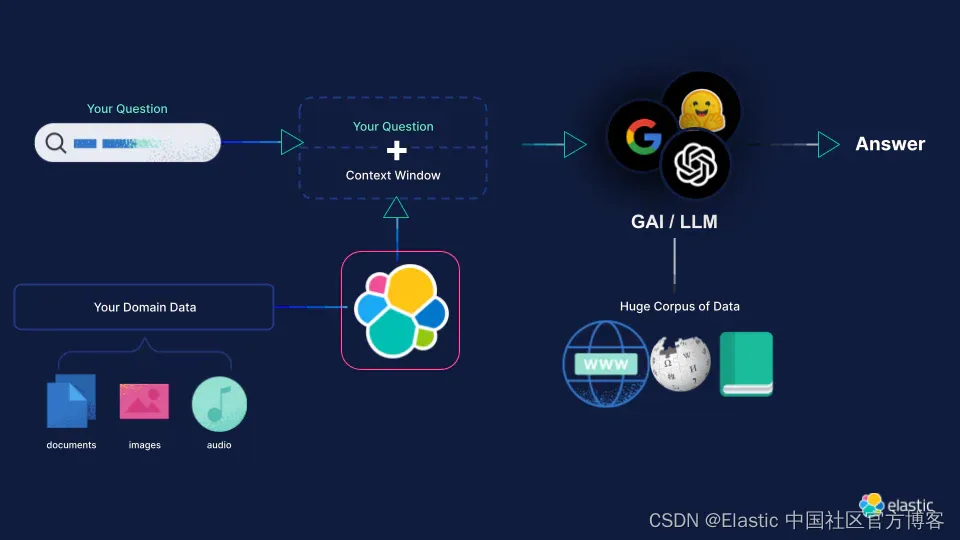
LLMs 将事实知识存储在其参数中,但他们访问和精确操纵这些知识的能力仍然有限。 这可能会导致 LLMs 提供非事实但看似合理的预测(幻觉)—— 特别是对于不受欢迎的问题。 此外,为他们的决策提供参考并有效地更新他们的知识仍然是开放的研究问题。
解决这些限制的通用方法是 RAG,其中 LLM 的参数知识以来自信息检索系统的外部或非参数知识为基础。 这些知识作为提示中的附加上下文传递给 LLM,并向 LLM 提供有关如何使用此上下文信息的具体说明。这使其更符合迄今为止有关参数知识的讨论。这种方法的优点是 :
- 与微调和预训练不同,LLM 参数不会改变,因此没有训练成本
- 简单实施所需的专业知识较低(尽管存在更高级的策略)
- 响应可以严格限制于从信息检索系统返回的上下文,从而限制幻觉
- 可以使用较小的特定于任务的 LLM - 因为 LLM 用于特定任务而不是知识库。
- 知识库很容易更新,因为它不需要改变 LLM
- 回复可以引用人工验证的来源和链接输出
将这种非参数知识(即检索到的文本)与 LLM 的参数知识相结合的策略是一个活跃的研究领域。

其中一些方法涉及结合检索策略修改 LLM,因此不能像本博客中的定义那样明确分类。 我们将在以后的博客中深入探讨更多细节。
简单的例子
在一个简单的示例中,我们使用了基于本博客信息的微调 LLaMA2 13B 模型。 该模型使用 LLaMA2 预训练和微调数据截止日期(特别是 2023 年 7 月 23 日之后)发布的 AWS 博客文章进行了微调。我们还将这些文档提取到 Elasticsearch 中,并建立了一个简单的 RAG 管道。 在此管道中,模型响应是根据作为上下文的检索到的文档生成的。 红色突出显示表示错误的响应,蓝色突出显示正确的响应。

不过,需要注意的是,这只是一个单一的例子,并不构成对 fine-tuning 与 RAG 的综合评价,只是提供了一个之前的 fine-tuning 的例子,用于形式,而不是事实。我们计划在即将发布的博客中进行更彻底的研究的比较。
原文:Domain Specific Generative AI: Pre-Training, Fine-Tuning, and RAG — Elastic Search Labs
版权归原作者 Elastic 中国社区官方博客 所有, 如有侵权,请联系我们删除。