
文章目录
一:深度估计应用背景
1.深度估计的定义
假设我们有一张2d图片
I
I
I,我们需要一个函数
F
F
F 来求取其相对应的深度
d
d
d.这个过程可以写为:
d
=
F
(
I
)
d = F(I)
d=F(I)
这里的深度信息
d
d
d其实就代表着**由3D物体投射而来的2D图像中每个像素点与相机的实际距离**。
但是众所周知,
F
F
F是非常复杂的函数,因为从单张图片中获取具体的深度相当于从二维图像推测出三维空间,即使人眼在两只眼睛来定位自然世界的物体的情况下也依然会有问题存在,更何况使用单张照片了。所以传统的深度估计在单目深度估计上效果并不好,人们更着重于研究立体视觉 (Stereo Vision),即从多张图片中得到深度信息.因为两张图片就可以根据视角的变化得到图片之间disparity的变化,从而达到求取深度的目的。话说多了,先往后看。
2.深度估计的应用场景


除了上面两张图片中提到的应用场景,深度估计还可以运用于3D重建,障碍物检测,SLAM等一系列需要深度信息的下游任务中。因此,可见深度估计往往作为上游任务存在,重要性不言而喻。
3.几种深度估计的方法
- 利用激光雷达或结构光在物体表面的反射获取深度点云 这种方法可谓是“土豪法”,直接利用传感器扫一扫,便可获得高精度点云深度信息,但是价格昂贵!
- 传统的双目测距 双目立体视觉,由两个摄像头组成,像人的眼睛能看到三维的物体,获取物体长度、宽度信息,和深度的信息。摄像头的位置是一般手动标定(比如张正友相机标定算法),然后通过目标点在图像坐标系和世界坐标系中的位置来推导相机内外参数矩阵的过程,往往是一个坐标转换的过程。
- 传统的单目测距 单目视觉是能获取二维的物体信息,即长度、宽度,所以如果想要测距,需要拍摄出几张不同角度(时序)的图像,再通过Mobileye单目测距等一系列方法,进行求解。同时,计算量复杂,而且精度不如双目高,往往是在条件艰难的时候使用。
4.使用深度学习估计的优缺点
前面铺垫完了几种传统领域的几种常见方法,现在开始聊聊今天的主角–深度学习单目估计。顾名思义,深度学习深度学习,第一反应End2End,把图像往训练好的网络里一扔,不需要任何人工参与,直接得出最后的深度图,一个词,方便!同时,我们只需要单目相机,一个词,成本低!
那有什么缺点呢,首先是80m以内的深度估计精度还行,但是再远误差就很大了,可见精度低、估计距离局限性,都是它的缺点。当然,还有一个深度学习一直绕不走的问题,需要大量训练集,在一些缺少训练数据的环境里显然是不容忽视的问题。
但是毕竟和时代前沿技术搭边了,咱们就来好好唠一唠,下面进入正题。
二:单目深度估计模型
1.使用的数据集
这里讲解的深度估计模型,使用的是KITTI数据集,取景于城市、乡村的道路上,该数据集在多个研究领域内被广泛使用,具体见下图:

2.整体网络架构
深度估计模型是输入一张图像,输出一张包含深度信息的图片,所以是一种生成模型,那么必然离不开编码和解码这个核心过程了,见下图: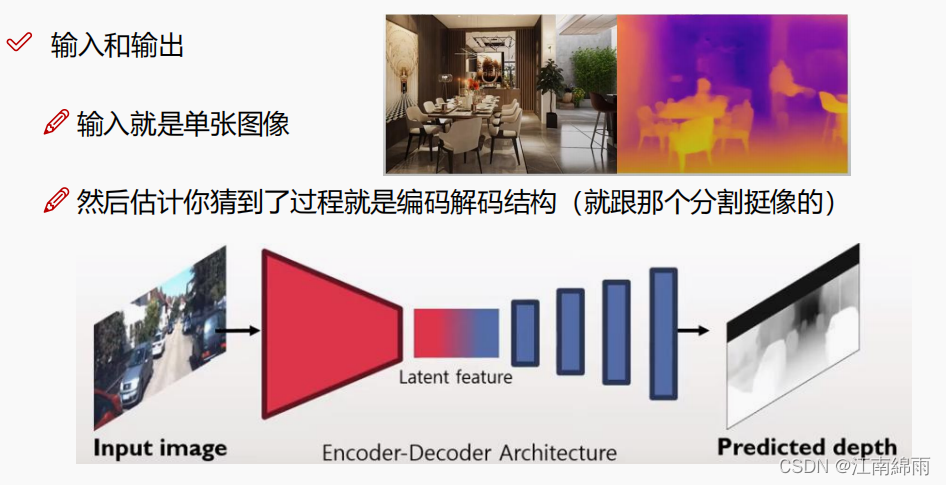
当然,真正的网络架构没有这么简单,但都是围绕编码-解码进行的,下面展示CVPR最近发布的一种网络架构,我将逐模块地讲解这个“庞然大物”: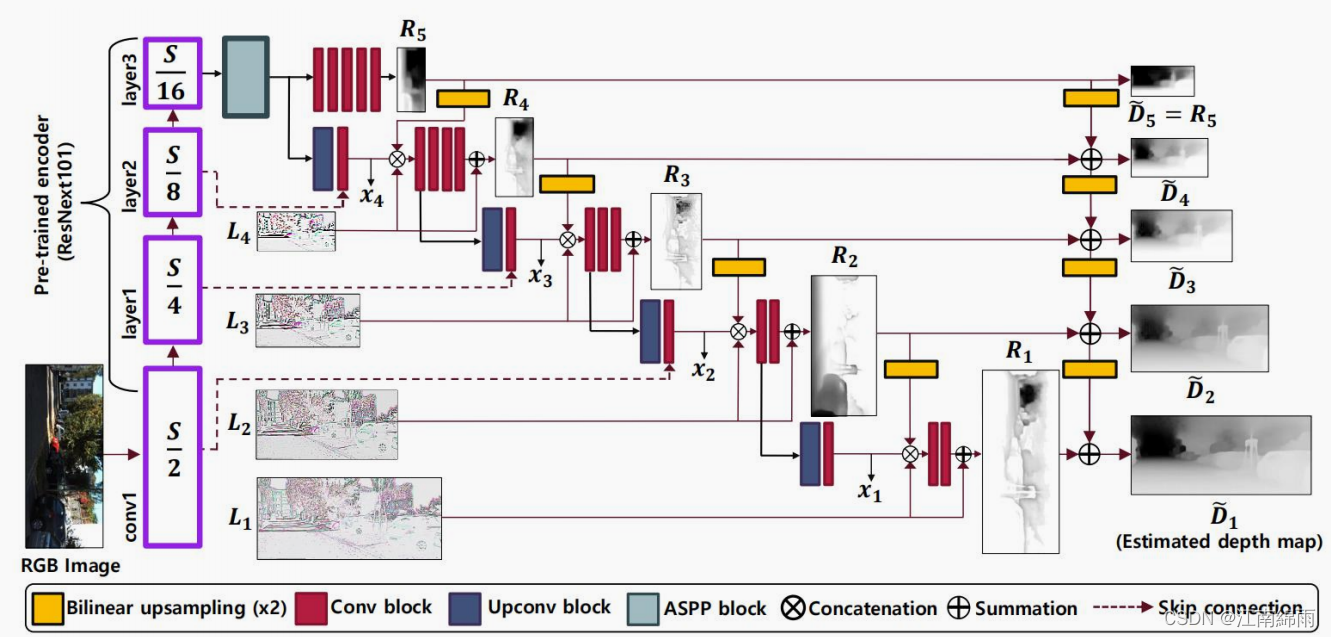
3.分模块解析
Ⅰ:层级
其实就是经过几层池化后,每次缩一半,这里的backbone使用的是Resnet101。和U-net等网络的操作相似,主要是为了后面的操作,如图:
Ⅱ:ASPP
作者在backbone的最后一个特征图做了ASPP,这里什么是ASPP不再赘述了,就是空洞卷积和SPP的结合,之所以用ASPP目的就是加点特征多样性,同时保留一定的分辨率(也是图像分割领域常规操作)。如图所示:
Ⅲ:特征图减法操作
在深度估计研究领域,物体的轮廓深度信息是一个挑战,作者为了有效解决这个问题,进行了神操作,将两张特征图
A
−
B
A-B
A−B相减(特征图B是上采样后和A一样尺寸的特征图),提取出了差异特征,得到轮廓特征图L。如下图:


Ⅳ:特征融合
进行一顿叠加,首先充分利用高层特征图与本层特征图的融合,得到中间特征图X,来增加特征的多尺度性。接着拼接高层的预测结果R‘’和本层的轮廓图L,大杂烩乱炖后得到本层预测结果R。每层都是这样操作,如图所示: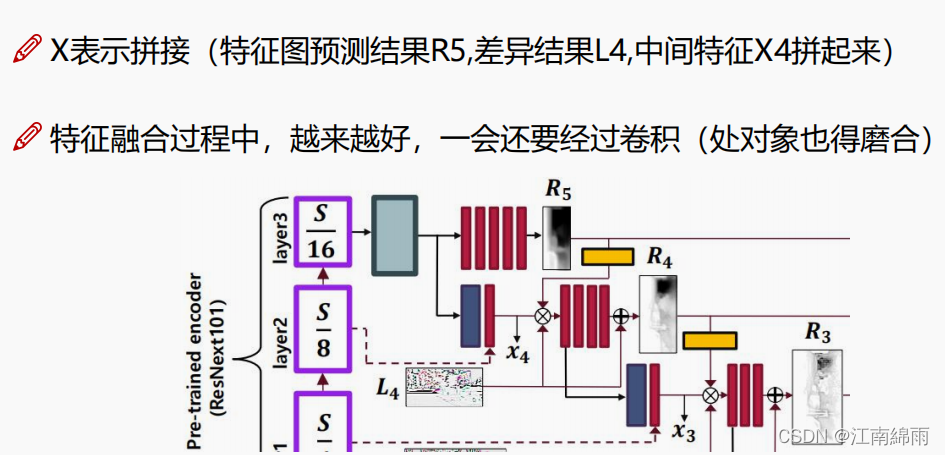
Ⅴ:Coarse-to-Fine
最后是细节“雕琢”的阶段,对每一层的R进行融合,得到最后的预测结果R‘’‘,如图所示:
Ⅵ:权重参数预处理WS与pre_act操作
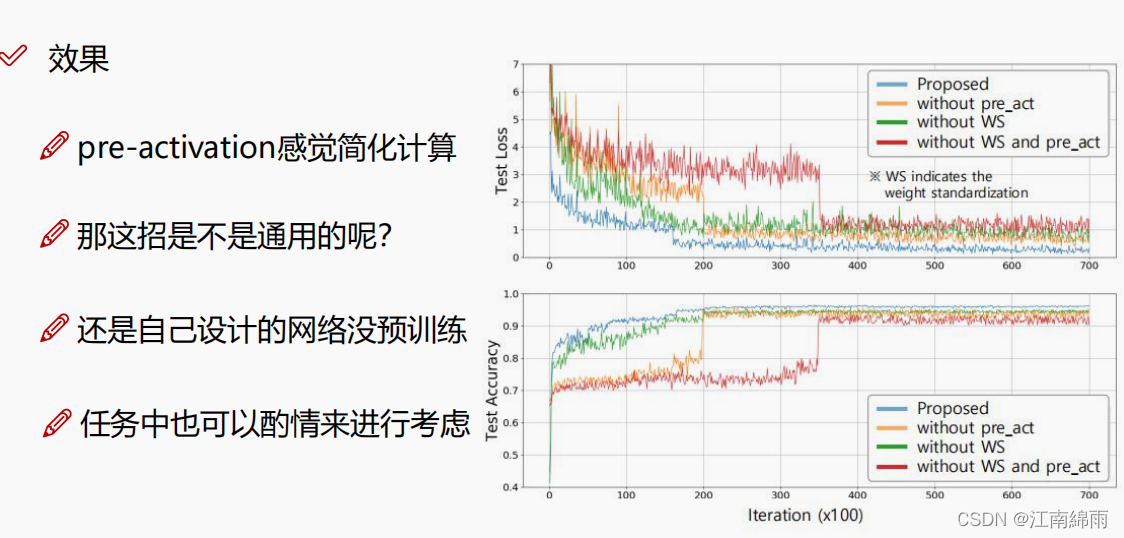
在真个网络中还加入了一些细节,首先是加入了权重标准化WS操作,让权重参数分布更均匀一些,不然经过ReLU后大量权重会被杀死(笔者提出疑问,那这样为什么不换一下激励函数,比如Mish,Leaky ReLU,Swish啥的??),接着还加入了pre_act,就是先对x进行ReLU,然后再进入卷积层,比较佛系,对于他们的实验,确实准确度有了质的飞跃,如下图所示: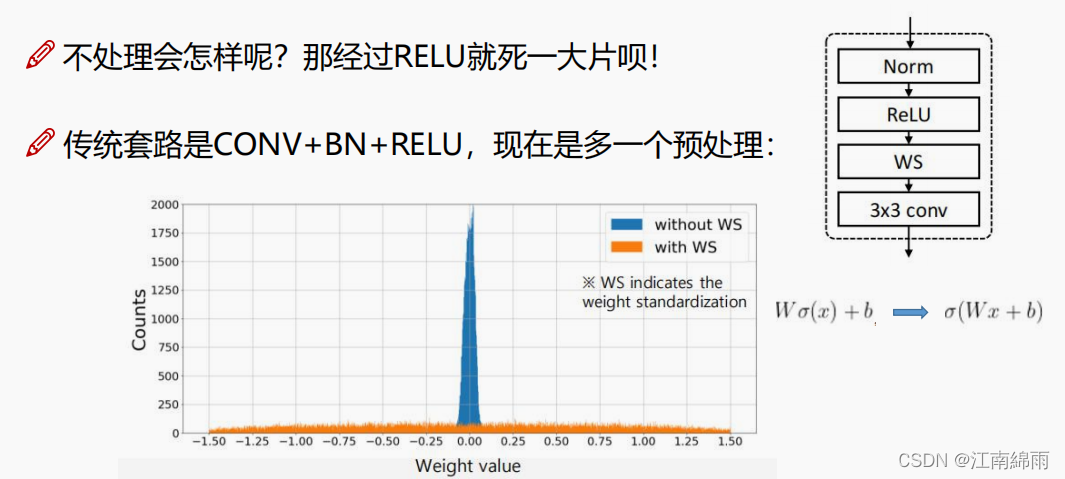
Ⅶ:损失函数
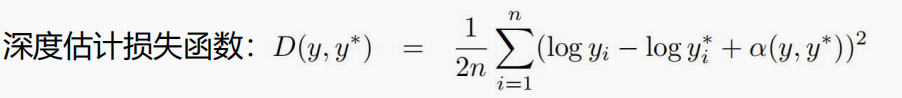
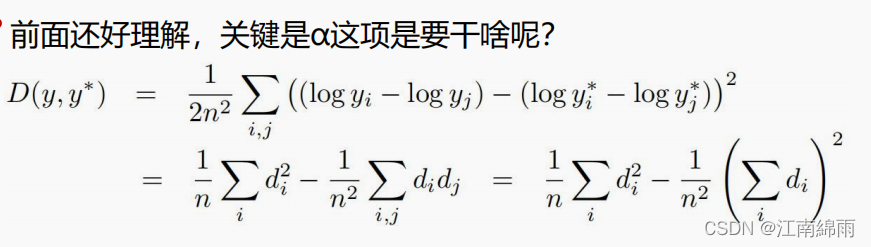
化简后的损失函数中的
d
d
d 其实就是每个像素点预测深度和真实深度的差值,重点是后面的
d
i
d
j
di dj
didj求和是什么意思,前面为什么还加了个负号。举个例子,大家就理解了,找出两个像素点,预测值和真实值的差值分别是
d
1
d1
d1和
d
2
d2
d2,如果两个差值都是负数,那么相乘是个正值,前面加个负号,那么代表不被惩罚,相反的如果两者异号则被惩罚。可见损失函数中这一项的目的是,希望得到的预测值要么都是低了一点,要么都高了一点,而不是这里预测大了,那里预测小了,这样效果其实更糟糕,模型更不可靠。
至此我对利用深度学习进行单目深度估计的原理,进行了简单讲解,希望对大家有所帮助,有不懂的地方或者建议,欢迎大家在下方留言评论。
我是努力在CV泥潭中摸爬滚打的江南咸鱼,我们一起努力,不留遗憾!
版权归原作者 江南綿雨 所有, 如有侵权,请联系我们删除。