
实验1:卷积神经网络应用
一:实验目的与要求
1:掌握卷积神经网络的原理。
2:掌握利用卷积神经网络建立训练模型,并对模型进行评估。
3:掌握使用卷积神经网络完成分类任务。
二:实验内容
1:搭建一个卷积神经网络CNN,完成某公开图像数据的分类任务,二分类或多分类。如(植物叶片病虫害_数据集-飞桨AI Studio星河社区)植物病虫害数据集。
2:分别实验小样本和大样本数据集,进行训练和测试,观察两者结果的差异。
3:调整CNN网络层数、过滤器大小数量、池化策略(最大池化、平均池化等)等,观察对识别准确率的影响。
三:实验环境
本实验所使用的环境条件如下表所示。
操作系统
Ubuntu(Linux)
程序语言
Python(3.11.4)
第三方依赖
torch, torchvision, matplotlib
四:方法流程
本实验方法设计的流程如下:
- 下载公开数据集,分析数据集的特点,并分别选择全球种植的大米米粒图像数据集(https://www.kaggle.com/datasets/muratkokludataset/rice-image-dataset)、苹果的病虫害图像数据集(https://aistudio.baidu.com/datasetdetail/171121)作为后续的大样本数据集和小样本数据集,样本量分别为7.5万张和4000张。
- 配置容器的运行环境,并将数据集通过远程连接协议传入容器。
- 按照【数据集读取】——【数据集划分】——【CNN结构搭建】——【模型实例化】——【损失函数和优化器选择】——【迭代训练模型】——【训练结果可视化】的步骤撰写代码。
- 得到基本框架的训练结果,分析结果产生的原因。
- 改变CNN的结构,改变网络层数、过滤器、池化策略等因素,多次重复实验。
- 分析对比实验的结果,总结CNN的特点。
五:实验展示(训练过程和结果进行可视化)
1:自己搭建的CNN模型(不同样本数量的数据集对比)
【1】CNN类下的网络结构
各个层的参数设置如下图所示。

前向传播的过程如下图所示。

CNN类下的网络结构如下表所示,详细介绍了每一层的功能和具体类容。
层数编号
功能
具体内容
1
卷积层
将2242243的图像,经过stride=1的55的卷积核,得到220220*6的卷积结果
2
池化层
将2202206的卷积结果,经过stride=2的22的窗口,得到110110*6的池化结果
3
卷积层
将1101106的池化结果,结果stride=1的55的卷积核,得到106106*16的卷积结果
4
池化层
将10610616的卷积结果,经过stride=2的22的窗口,得到5353*16的池化结果
5
全连接层
将535316的池化结果,转成1维的结果,经过全连接,得到120的全连接结果
6
全连接层
将120的全连接结果,经过全连接,得到84的全连接结果
7
全连接层
将84的全连接结果,经过全连接,得到4的全连接结果(即4种类别)
同时,网络将relu函数作为卷积层1和2、全连接层6和7的激活函数。
【2】CNN类训练过程的输出
采用小样本数据集的训练过程如下图所示。

由上图可知,经过30次训练迭代后,**训练准确率最高可达到100%,测试准确率最高可达到96.12%**。对比训练准确率和测试准确率可知,模型不存在明显的过拟合现象。
采用大样本数据集的训练过程如下图所示。

由上图可知,经过30次训练迭代后,**训练准确率最高可达到99.95%,测试准确率最高可达到99.69%**。对比训练准确率和测试准确率可知,模型不存在明显的过拟合现象。
【3】CNN类的模型损失可视化图
采用小样本数据集的损失可视化图如下图所示。

采用大样本数据集的损失可视化图如下图所示。
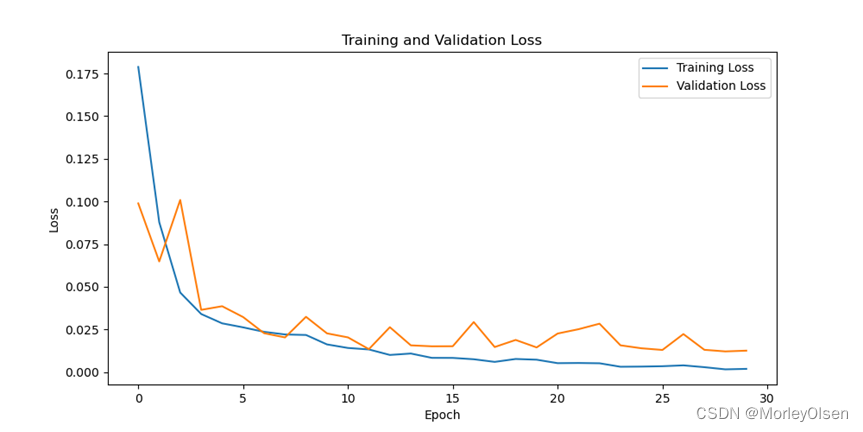
由上图可知,经过30次训练迭代后,蓝色部分的训练损失值曲线和橘色部分的测试损失值曲线整体均呈现下降趋势,且训练损失值的下降速度快于验证损失值的下降速度。
【4】CNN类的分类准确率可视化图
采用小样本数据集的分类准确率可视化图如下图所示。
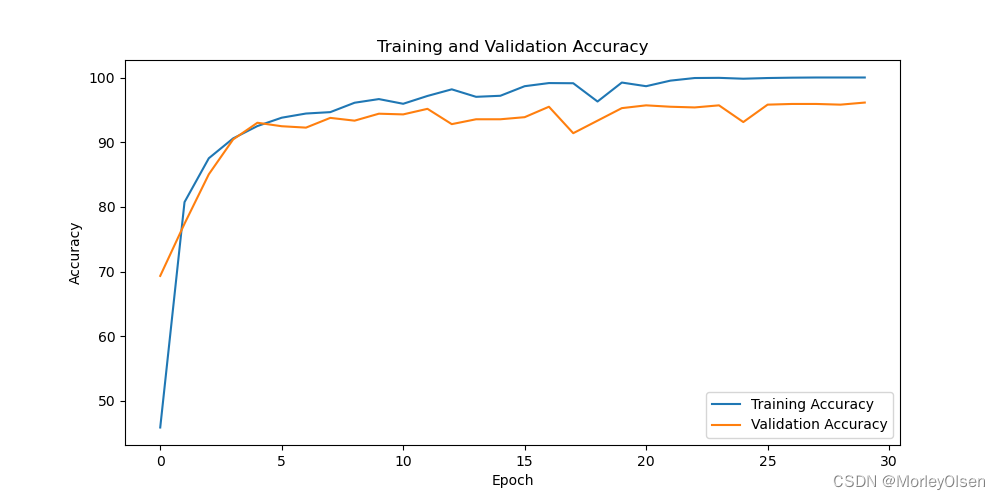
采用大样本数据集的分类准确率可视化图如下图所示。

由上图可知,经过30次训练迭代后,蓝色部分的训练准确率曲线和橘色部分的测试准确率曲线整体均呈现上升趋势,且训练准确率的上升速度快于验证准确率的上升速度。
2:传统卷积网络结构的AlexNet模型(CNN的网络层数对比、不同样本数量的数据集对比)
【1】AlexNet类下的网络结构
各个层的参数设置如下图所示。

前向传播的过程如下图所示。

该网络主要由【特征提取器features】和【分类器classifier】两个部分组成。
特征提取器features部分的内容如下:
- 第一个卷积层:输入通道数为3(RGB图像),输出通道数为64,卷积核大小为11x11,步幅为4,填充为2。
- ReLU激活函数:应用在第一个卷积层之后。
- 最大池化层:池化窗口大小为3x3,步幅为2。
- 第二个卷积层:输入通道数为64,输出通道数为192,卷积核大小为5x5,填充为2。
- ReLU激活函数:应用在第二个卷积层之后。
- 最大池化层:池化窗口大小为3x3,步幅为2。
- 第三个卷积层:输入通道数为192,输出通道数为384,卷积核大小为3x3,填充为1。
- ReLU激活函数:应用在第三个卷积层之后。
- 第四个卷积层:输入通道数为384,输出通道数为256,卷积核大小为3x3,填充为1。
- ReLU激活函数:应用在第四个卷积层之后。
- 第五个卷积层:输入通道数为256,输出通道数为256,卷积核大小为3x3,填充为1。
- ReLU激活函数:应用在第五个卷积层之后。
- 最大池化层:池化窗口大小为3x3,步幅为2。
- 自适应平均池化层:输出特征图的大小被自适应地调整为6x6。
分类器classifier部分的内容如下:
- 第一个dropout层,用于防止过拟合。
- 全连接层:输入大小为256 * 6 * 6,输出大小为4096。
- ReLU激活函数:应用在第一个全连接层之后。
- 第二个dropout层,用于防止过拟合。
- 全连接层:输入大小为4096,输出大小为4096。
- ReLU激活函数:应用在第二个全连接层之后。
- 全连接层:输出大小根据类别数num_classes参数确定。
【2】AlexNet类训练过程的输出
采用小样本数据集的训练过程如下图所示。

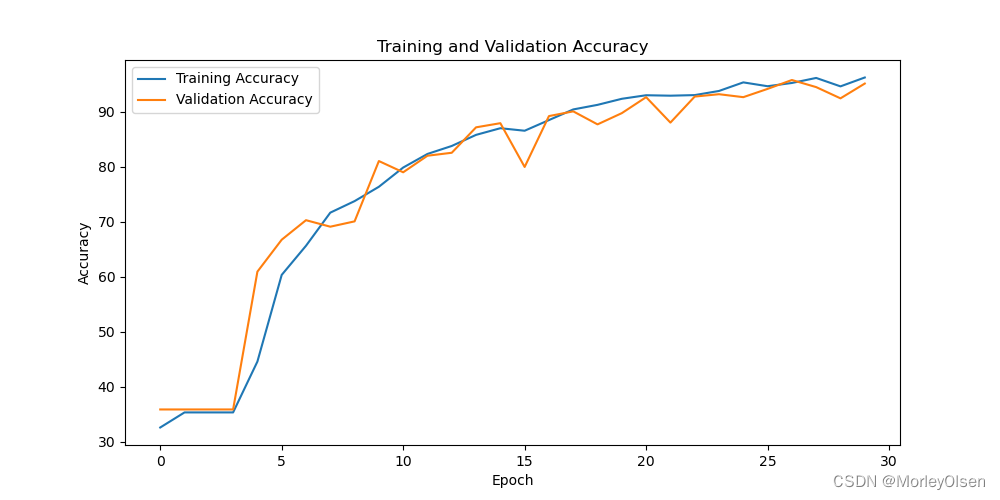
由上图可知,经过30次训练迭代后,**训练准确率最高可达到96.26%,测试准确率最高可达到95.16%**。对比训练准确率和测试准确率可知,模型不存在明显的过拟合现象。
采用大样本数据集的训练过程如下图所示。

由上图可知,经过30次训练迭代后,**训练准确率最高可达到99.9%,测试准确率最高可达到99.85%**。对比训练准确率和测试准确率可知,模型不存在明显的过拟合现象。
【3】AlexNet类的模型损失可视化图表
采用小样本数据集的损失可视化图如下图所示。

采用大样本数据集的损失可视化图如下图所示。

由上图可知,经过30次训练迭代后,蓝色部分的训练损失值曲线和橘色部分的测试损失值曲线整体均呈现下降趋势,且训练损失值的下降速度快于验证损失值的下降速度。
【4】AlexNet类的分类准确率可视化图表
采用小样本数据集的分类准确率可视化图如下图所示。
采用大样本数据集的分类准确率可视化图如下图所示。
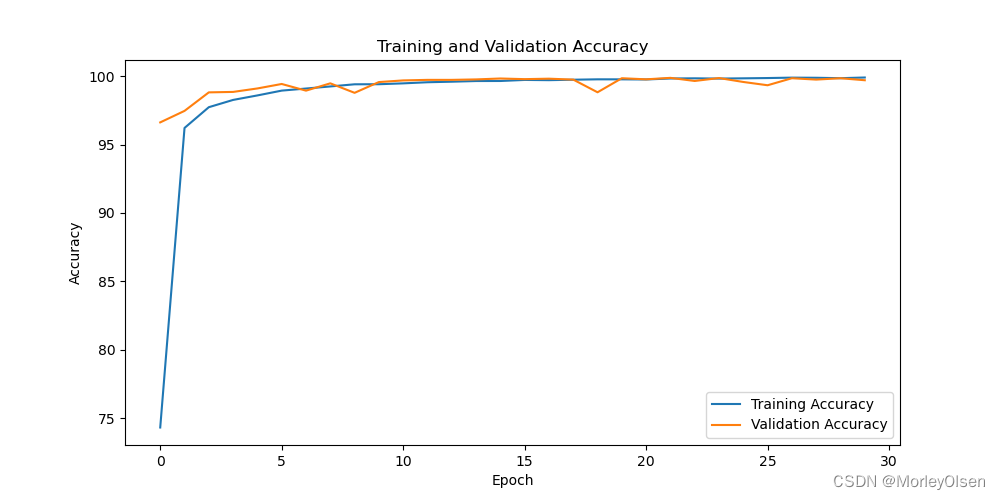
由上图可知,经过30次训练迭代后,蓝色部分的训练准确率曲线和橘色部分的测试准确率曲线整体均呈现上升趋势,且训练准确率的上升速度快于验证准确率的上升速度。
对比不同网络层数和样本数量数据集的模型表现(分类准确率、模型训练时间)后,最终选择自构建CNN模型和小样本数据集作为后续池化策略和过滤器大小数量的对比实验的基础模型。
3:CNN的池化策略对比
在【实验内容1】中,CNN采用了全局池化的方法,因此本部分将使用平均池化的方法进行对比。需要修改的代码段如下图所示。

采用小样本数据集的训练过程如下图所示。

由上图可知,经过30次训练迭代后,**训练准确率最高可达到100%,测试准确率最高可达到94.19%**。对比全局池化的结果(训练准确率最高可达到100%,测试准确率最高可达到96.12%),可以发现在CNN类中平均池化的效果比全局池化的效果差。
采用小样本数据集的损失可视化图如下图所示。

采用小样本数据集的分类准确率可视化图如下图所示。

4:CNN的过滤器大小数量对比
首先,进行过滤器数量改变的实验。在此处新增一个过滤器(第三层卷积层),使得整个卷积层的结构如下表所示。
层数编号
功能
具体内容
1
卷积层
将2242243的图像,经过stride=1的55的卷积核,得到220220*6的卷积结果
2
池化层
将2202206的卷积结果,经过stride=2的22的窗口,得到110110*6的池化结果
3
卷积层
将1101106的池化结果,结果stride=1的55的卷积核,得到106106*16的卷积结果
4
池化层
将10610616的卷积结果,经过stride=2的22的窗口,得到5353*16的池化结果
5
卷积层
将535316的池化结果,结果stride=1的44的卷积核,得到5050*32的卷积结果
6
池化层
将505032的卷积结果,经过stride=2的22的窗口,得到2525*32的池化结果
7
全连接层
将252532的池化结果,转成1维的结果,经过全连接,得到120的全连接结果
8
全连接层
将120的全连接结果,经过全连接,得到84的全连接结果
9
全连接层
将84的全连接结果,经过全连接,得到4的全连接结果(即4种类别)
函数init处的代码调整如下图所示。

函数forward处的代码调整如下图所示。

采用小样本数据集的训练过程如下图所示。

由上图可知,经过30次训练迭代后,**训练准确率最高可达到99.92%,测试准确率最高可达到94.83%**。对比2层卷积层的结果(训练准确率最高可达到100%,测试准确率最高可达到96.12%),可以发现在CNN类中3层卷积层的效果比2层卷积层的效果差。
采用小样本数据集的损失可视化图如下图所示。

采用小样本数据集的分类准确率可视化图如下图所示。
然后,进行过滤器大小改变的实验。将原来的第一、二层卷积层的kernel尺寸改小,分别缩小到33和22,使得整个卷积层的结构如下表所示。
层数编号
功能
具体内容
1
卷积层
将2242243的图像,经过stride=1的33的卷积核,得到222222*6的卷积结果
2
池化层
将2222226的卷积结果,经过stride=2的22的窗口,得到111111*6的池化结果
3
卷积层
将1111116的池化结果,结果stride=1的22的卷积核,得到110110*16的卷积结果
4
池化层
将11011016的卷积结果,经过stride=2的22的窗口,得到5555*16的池化结果
5
全连接层
将555516的池化结果,转成1维的结果,经过全连接,得到120的全连接结果
6
全连接层
将120的全连接结果,经过全连接,得到84的全连接结果
7
全连接层
将84的全连接结果,经过全连接,得到4的全连接结果(即4种类别)
函数init处的代码调整如下图所示。

函数forward处的代码不变。
采用小样本数据集的训练过程如下图所示。

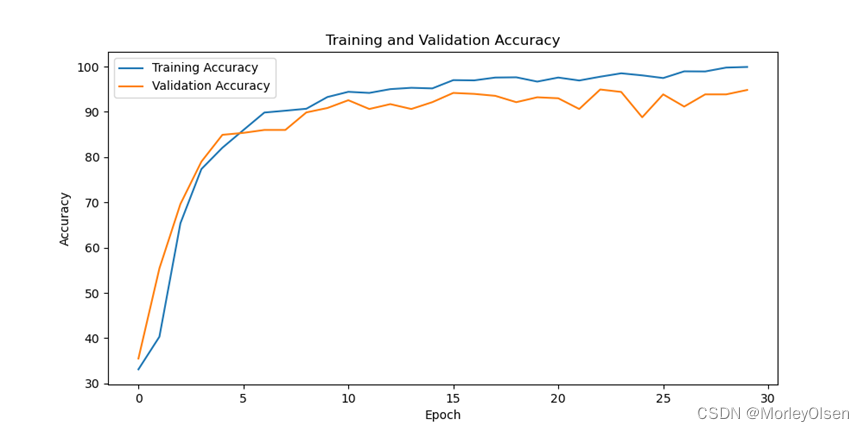
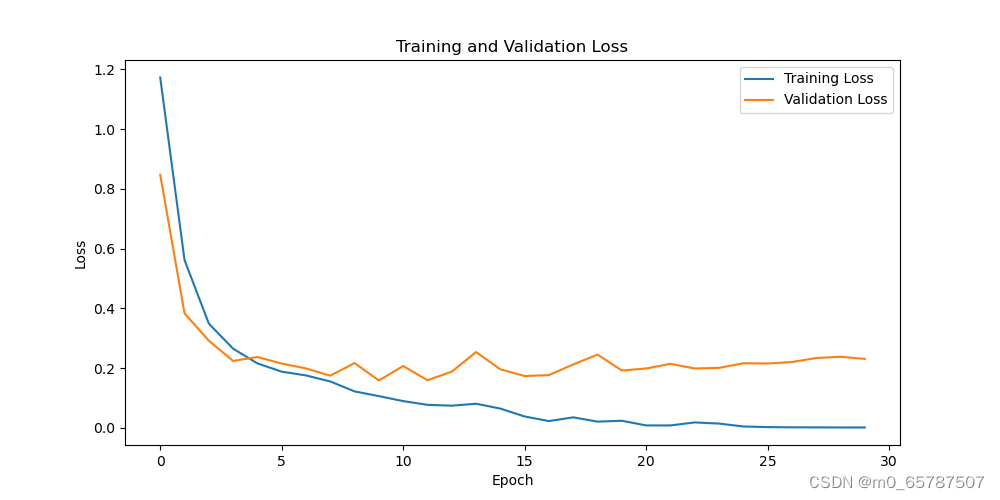
由上图可知,经过30次训练迭代后,**训练准确率最高可达到100%,测试准确率最高可达到95.05%**。对比kernel尺寸大的结果(训练准确率最高可达到100%,测试准确率最高可达到96.12%),可以发现在CNN类中kernel尺寸小的效果比kernel尺寸大的效果差。
采用小样本数据集的损失可视化图如下图所示。
采用小样本数据集的分类准确率可视化图如下图所示。

六:实验结论和心得
1:输出图像尺寸的计算公式如下图所示。根据该公式,可以得到图像在各层处理后的尺寸大小情况,以便调整网络结构。

2:卷积神经网络层级设计的复杂程度(例如:卷积核大小、卷积层层数、通道数、池化策略等参数),应该根据数据集本身的特点而定,并不是设计越复杂分类准确率越高。例如,在本实验的小样本数据集训练中,自构建的轻量化CNN效果在同样的迭代次数下优于经典网络AlexNet。
3:在卷积神经网络中,激活函数(如ReLU)对于增加网络的非线性和帮助网络学习复杂模式至关重要。
4:在卷积神经网络中,池化层(最大池化和平均池化)对于减少参数数量、控制过拟合以及提高模型泛化能力方面至关重要。
5:通过卷积核在输入图像上滑动,执行元素乘积和操作,用于提取图像特征。每个卷积核负责捕捉图像中的特定类型的特征,如边缘、角点、纹理。
6:在网络的末端,全连接层用于将学到的“高级”特征表示映射到样本的最终类别或回归值上。
七:遇到的问题和解决方法
问题1:一开始尝试使用tensorflow的框架进行CNN的搭建,但是服务器【pip install tensorflow】之后,依然无法调用【tensorflow.keras】依赖。
解决1:更换为pytorch的框架进行CNN的搭建,并使用cuda进行GPU加速。
八:程序源代码
importtorch
importtorchvision
importtorchvision.transformsastransforms
fromtorchvisionimportmodels
importtorch.nnasnn
importtorch.optimasoptim
fromtorch.utils.dataimportDataLoader, random_split
importtorch.nn.functionalasF
importmatplotlib.pyplotasplt
visualization part
defplot_loss(train_losses, val_losses):
plt.figure(figsize=(10, 5))
plt.plot(train_losses, label='Training Loss')
plt.plot(val_losses, label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
# plt.show()
plt.savefig('loss-cnn.png')
defplot_accuracy(train_accuracies, val_accuracies):
plt.figure(figsize=(10, 5))
plt.plot(train_accuracies, label='Training Accuracy')
plt.plot(val_accuracies, label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
# plt.show()
plt.savefig('acc-cnn.png')
Data Preparation
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
dataset = torchvision.datasets.ImageFolder(root=r"/home/ubuntu/apple", transform=transform)
划分 train 和 test 数据集
train_size = int(0.8 * len(dataset))
test_size = len(dataset) - train_size
train_dataset, val_dataset = random_split(dataset, [train_size, test_size])
创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=4)
"""
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # 输入通道:3(RGB图像),输出通道:6,卷积核大小:5x5
self.pool = nn.MaxPool2d(2, 2) # 池化层,2x2的窗口,步幅为2
self.conv2 = nn.Conv2d(6, 16, 5) # 输入通道:6,输出通道:16,卷积核大小:5x5
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 全连接层,输入大小为16*5*5,输出大小为120
self.fc2 = nn.Linear(120, 84) # 全连接层,输入大小为120,输出大小为84
self.fc3 = nn.Linear(84, 4) # 全连接层,输入大小为84,输出大小为4(类别数)
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = torch.flatten(x, 1) # 展平多维的卷积输出为一维
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
"""
self-designed model
classCNN(nn.Module):
def__init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # 输入通道:3(RGB图像),输出通道:6,卷积核大小:5x5
self.pool = nn.MaxPool2d(2, 2) # 池化层,2x2的窗口,步幅为2
self.conv2 = nn.Conv2d(6, 16, 5) # 输入通道:6,输出通道:16,卷积核大小:5x5
self.fc1 = nn.Linear(16 * 53 * 53, 120) # 全连接层,输入大小为16*53*53,输出大小为120
self.fc2 = nn.Linear(120, 84) # 全连接层,输入大小为120,输出大小为84
self.fc3 = nn.Linear(84, 4) # 全连接层,输入大小为84,输出大小为4(类别数)
defforward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # 展平多维的卷积输出为一维
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
returnx
Alex-net model
classAlexNet(nn.Module):
def__init__(self, num_classes=4):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
defforward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
returnx
实例化模型
model = CNN()
model = AlexNet()
Training and Evaluation
device = torch.device("cuda:0"iftorch.cuda.is_available() else"cpu")
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
Training loopl
num_epochs = 30
train_losses = []
val_losses = []
train_accuracies = []
val_accuracies = []
forepochinrange(num_epochs):
# train
model.train()
running_loss = 0.0
correct = 0
total = 0
test_correct = 0
test_total = 0
fori, (inputs, labels) inenumerate(train_loader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
train_losses.append(running_loss / len(train_loader))
train_accuracies.append(100 * correct / total)
# evaluate
model.eval()
withtorch.no_grad():
val_loss = 0.0
val_correct = 0
val_total = 0
forinputs, labelsinval_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
val_total += labels.size(0)
val_correct += (predicted == labels).sum().item()
val_losses.append(val_loss / len(val_loader))
val_accuracies.append(100 * val_correct / val_total)
print(f"Epoch {epoch+1}, Loss: {train_losses[-1]}, Accuracy: {train_accuracies[-1]}%, Validation Loss: {val_losses[-1]}, Validation Accuracy: {val_accuracies[-1]}%")
绘制损失曲线和准确率曲线
plot_loss(train_losses, val_losses)
plot_accuracy(train_accuracies, val_accuracies)
print('Finished')
版权归原作者 MorleyOlsen 所有, 如有侵权,请联系我们删除。