
1:本文主要讨论将神经网络的理念运用在股价预测或估值上;
2:本文主要为理念的讲解,模型也是笔者自建,因此不涉及任何主流机器学习框架,如果有读者是为了学习使用thenserflow,sklearn或者PyBrain这些模块就不必往下看了;
3:出于个人原因笔者暂不打算公开具体模型,函数及参数,仅使用部分简单代码及回测结果以作展示;
4:本文主要数据均通过Tushare(ID:444829)金融大数据平台接口获取;
5:笔者希望搭建出一套交易体系,原则是只做干货的分享。后续将更新更多模块,但工作学习之余的闲暇时间有限,更新速度慢还请谅解;
6:文中假设与观点是基于笔者对模型及数据的一孔之见,若有不同见解欢迎随时留言交流;
7:模型实现基于python3.8;
1. 论玄学
相信不少朋友在看了笔者上期发布的股价随机游走的文章后纷纷表示玄学,前两天笔者看见了更为玄学的东西,直接上图(关键部位打码,感兴趣的朋友去搜索都能搜到):

以笔者的经历,隔壁老缠师日夜“说缠论道”,楼上黑盘子团队打着灯笼在韭菜面前用阴阳八卦图找买卖点都没能吓退我,看到这幅图的瞬间虎躯一震, 这。。这莫非就是“天干地支择时,五行相生相克选股”大法,而且还是出自某券商首席。
不知和它比起来笔者上期经过数学推演的随机游走还算不算得玄学? 如果您的答案还是玄学,那么本期笔者将带来经过数学逻辑严密推演的神经网络模型,在基本面和技术面的加持下彻底摘下玄学的帽子。
2. 什么是神经网络
2.1 认识世界的过程
对于神经网络,度娘给出的解释是介样的:
看了半天跟没看一样。。
对于神经网络笔者有自己的理解,它其实是仿生学,即通过程序来模仿生物认识世界的过程,使得程序能自己“思考”。
笔者记得本科时候数学老师是位密码专家,一次上课时他语重心长的说:“万物皆可函数”。 当时笔者上课只感觉:
后来笔者在学习神经网络的时候明白了这句话的深意, 神经网络网络就是将现实存在的事或物以函数的形式抽象表达出来,下面笔者举一个例子:
这是一只橘猫

但我们为何知道这是一只橘猫?
这就涉及到特征的辨识,身体形状,颜色,眼睛大小,鼻子,胡子形状,总之这只动物有着橘猫的所有特征,因此大脑将它分类成脑中存在的一个标签——橘猫。
事实上,对一个初生小婴儿来说,大脑就是一片白纸,橘猫所有的特征都是我们人类通过后天学习得到的。第一次给小婴儿看这张橘猫图并且告诉他这是一种叫橘猫的动物, 在脑中形成一个橘猫的印象, 比如耳朵尖尖的,脑袋圆圆的样子,第二次再看一模一样的图,橘猫这个标签就自然而然地与这张图对应上了。
那么再看这张图:

尽管耳朵被遮住了,我们还是能分辨出它还是一只橘猫。这是因为我们已经不是单纯靠耳朵来辨认了,可我们的小baby只认识上面那张橘猫图,当把这张图给他看的时候我们可以误导他说这是一只英短或者橘狗,如图一,于是就有了赵高指鹿为马的典故。。
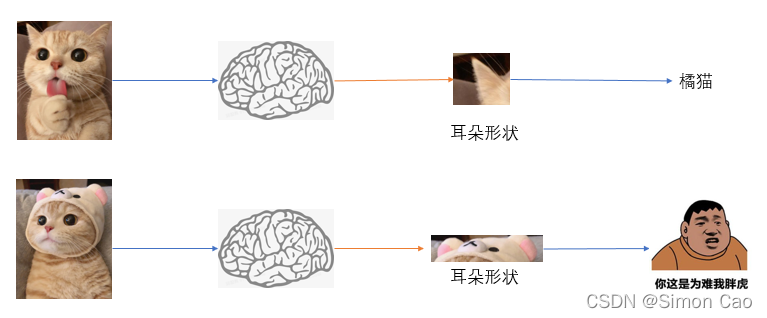
图一:图片单个特征
但如果我们依然告诉小baby这是一只橘猫,而且可以随机给他看很多橘猫耳朵被遮住和不被遮住的图,小baby或许会明白耳朵是不是尖尖的猫耳朵不重要,关键是这只猫要萌。

好吧,关键是鼻子,嘴巴,颜色,体态也很重要, 如图二:
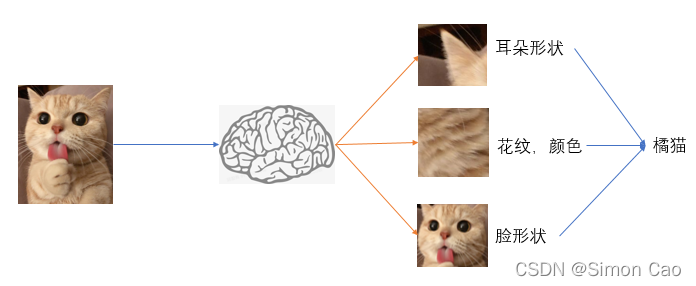
图二:多个特征
想象一下,当重复成百上千张不同的橘猫图,通过不断提取特征信息,下次再给小baby看一张陌生的橘猫图时,他自然而然就把橘猫这个标签匹配上了。我们小时候看的很多识字卡,看图说话的小游戏其实一直在重复这个过程。 可以说世上本没有橘猫,只是人们给他打了个标签一样的名字便成了橘猫。
2.2 神经网络正向传播
上一个小标题只是解释了特征量对辨识准确度的影响,但大脑内部是如何工作的?它就像一只black box, 我们依然无法建立模型。
如图三,生物的神经网络结构大家或许见怪不怪,一个细胞周边被无数丝线一样的东西连接到其它细胞, 一个成人的大脑中有上千亿个神经细胞相连。
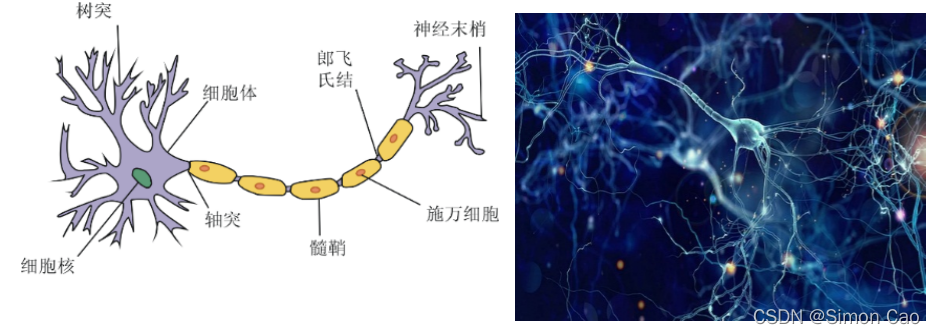
图三:生物的神经网络
人工神经网络是一门仿生学, 心理学家McCulloch和数学家Pitts在1943年参考了生物神经元的结构,发表了抽象的神经元模型MP。 既然自然界中的生物神经网络长成这样, 我们何不人工造一个?反正一个圆圆的细胞加一些突触,为了简化,就画上两个突触, 一个负责输入信号,另一个输出信号。由于神经元是要进行“思考”的,笔者将神经元分成两个半圆,白色表示输入,橙色表示经过处理后的输出,于是我们有图四:
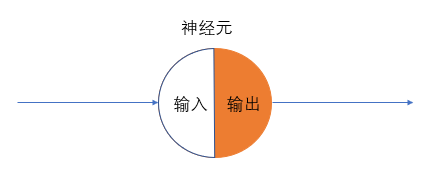
图四:一个神经元
正如笔者老师所言,“万物皆可函数”。输入到输出的过程即是神经元处理数据的过程,可以用函数y = f(x)表示, 例如:
橘猫 = f(耳朵,鼻子,颜色)
我们也称这个函数叫**激活函数**, 可以简单理解为将这一堆数据激活得到橘猫的效果。
通过输入耳朵,鼻子和颜色的数据,经过这个函数计算得到橘猫这个结果。但这显然也太粗糙了,补上几个规定:
1:输入数据——蓝色圆表示
2:神经元命名(输入):
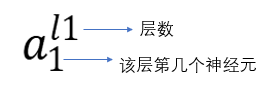
3:神经元命名(输出):
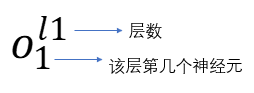
3:输入数据为输入层;中间神经元为隐藏层
4:最后一层为输出层,以白蓝色圆形表示
于是可以丰满一下网络,如图四所示:

图四:两个神经元
完善到这里,这个神经网络还只有形状,没有灵魂。 神经元之间的连接仅仅只是一条“虚”线线,只有赋值才能化虚为实。
2.2.1 权值的作用
生物神经元之间传递信号是通过神经信号, 这是一种电信号,度娘给出的解释是:

好吧,我们不是研究生物。笔者的理解是,当电信号越强烈,刺激越大。说人话就是被100度开水烫和60度水烫的区别。 如果用数学语言表达就是权重, 当被100度开水烫,传递一个非常大的权重值。
那么我们给刚刚图四种中的神经网络加上权重,再丰满一下,多加一层隐藏层,约定神经元权重表示如下:
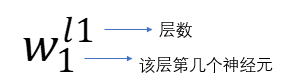
把代号也标上,于是有图五:
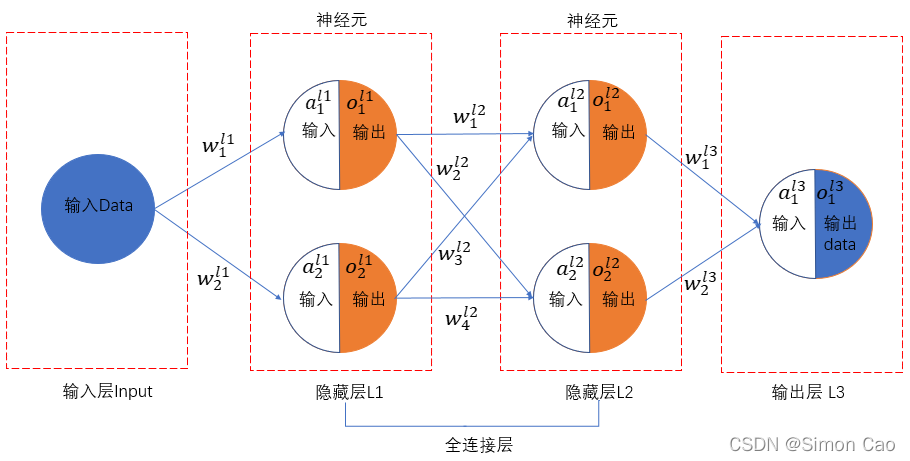
图五:一个两层的全连接网络
由于神经网络特点,中间层与层之间的神经元都是依靠权重连接起来的,因此我们也称之为全连接层。
至此,整个网络就算构建完善了, 计算也变为可能, 整个网络的运算规则是:**下一层某个神经元的输入值等于上层所有神经元输出值乘以各自的权重**。
第一层L1:

简写出来如下,后面统一这样简写表示,:
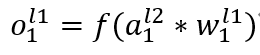
第二层L2就会稍微复杂一些,因为L2层每一个神经元都会接收L1神经元传入的值, 神经元的值变成多层复合函数如下:
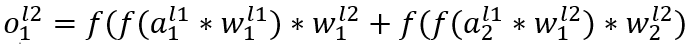
最后一层输出层如上类推,嵌套更多一层函数而已,写出来太长,就用上层输出直接简写:

至此,神经网络前向计算全部完成,但这样依旧有很大问题。如何得知计算出的结果就是橘猫呢,规定好权重,带真实数值进去算一通说不定算出个哈士奇, 这样算出的结果完全没有意义。下一部分将通过反向运算解决误差的问题, 也是模拟思考过程的关键步骤。
2.2.2 激活函数存在的必要性
神经网络运算规则是:下一层某个神经元的输入值等于上层所有神经元输出值乘以各自的权重。 先说结论,如果没有激活函数,整个神经网络其实只相当于一个线性函数,多层及多个神经元存在的意义就没有了。
一个很简单的例子: 某层神经元计算如下f(x) = 2x + 1, 下层神经元z(x) = 2 f(x) + 1, 由于线性函数的性质,其实z(x)就等价于4x + 3, 也就是说完全可以用一个线性模型代替这个所谓的神经网络, 于是这样的神经网络就算构建100层也依旧只相当于一个线性模型。
因此,一般情况下构建神经网络的激活函数一定要是非线性的。 笔者后面将用老掉牙的sigmoid函数做演示,不过前人也设计出许多不同类型的激活函数,例如tanh, relu函数, 这些函数被广泛验证并运用在各种模型中, 但笔者认为没有什么one size fits all的最优函数,很多时候需要根据实际问题自行构建属于这个模型的激活函数。
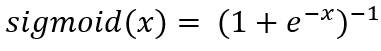
2.3 反向算法
如图一情景所示,当小baby看见一只从来没见过的猫耳朵时,他其实很难判断出是不是一只橘猫。 当大人告诉他这依旧是一只橘猫后会发生什么? 显然小baby的关注点不再局限于耳朵上,他会看颜色,体态,花纹等等其它特征, 根据这些特征判断是不是橘猫。这一过程中神奇的事情发生了——不依靠耳朵识别,转化为数学语言不就是耳朵的权重没有了吗? 而颜色,体态等其它特征形成更大的权重。
上述这一过程正是反向算法的精意所在, 即:正向计算——对比真实数据——得到误差——反向思考什么地方出了问题——进行权值调整。
为了知道是哪个神经元权值造成了多少的误差,我们借助偏导数的手段来处理, 这个视频讲解了梯度的几何意义,可以帮助理解后面的梯度下降算法。
2.3.1 损失函数
计算误差的过程其实有很多种方式,最简单的真实数据于神经网络跑出的数据做差, 也可以求平均绝对离差;由于绝对值不好进行求导,也可以平方一下,转化为方差;如果多对数据也可以使用协方差, 亦或者根据实际模型需要构建函数。下面以方差进行简单演示:
先把最后一个输出的神经元拎出来展示细节。 如图六所示, 为了量化出某个权值对最后结果造成了多少误差,这里采用偏导数,由于误差值是权值经过了激活函数, 又过了一个损失函数计算得到,因此误差对权值的偏导数需要采用链式求导的方式。

图六: 损失函数对权值求偏导
2.3.1.1 首先是输出层神经元对隐藏层神经元权重的偏导:
如图六, 对l2层第一个权重求偏导有:
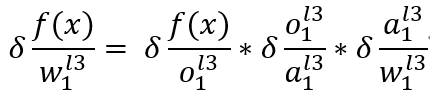
其中:
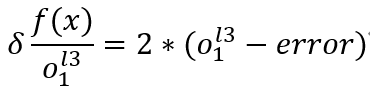
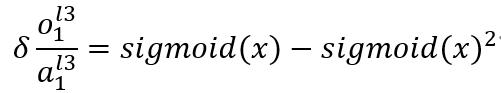
上面这步其实就是对sigmoid函数求导
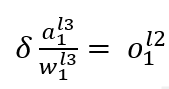
最后其实就是对上层加和计算下一个神经元输入值的那个线性函数求导,有点绕, 其实就算:
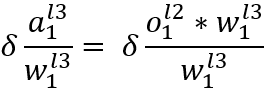
将以上拆分的几个式子相乘即可得到误差对权重的链式求导结果,但这个结果只是第一个权重的,还要如法炮制计算第二个权重, 计算都是一样的,换换角标而已,这里就不做过多展示。
2.3.1.2 隐藏层权重的偏导
即计算l1层w1和w2, 这里其实就算套用上面2.3.1.1里面的链式求导,只是再多加一层函数求导。
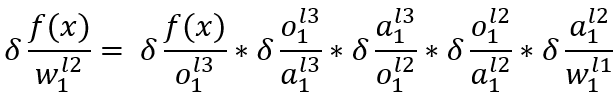
这个式子其实依旧是上面的链式求导后面多加一个神经元的运算, 唯一不同的是式子第三项不再是对权重求导,而是对神经元输出值求导,原因依旧是正向算法的线性运算:
这个式子对神经元求偏导就只剩下权值了, 而对权重求偏导则剩下神经元输入值。
刚刚那个长式子后面两项依旧是熟悉的权值求偏导。
如法炮制可以分别求出误差对剩下三个权重的偏导。
2.3.1.3 隐藏层神经元的偏导
** **上面一个式子笔者提到对权重和对神经元求偏导是不一样的,这里笔者还要加一个神经元的偏导,尤其是前面几层隐藏层的。与刚刚的不同之处在于前面几层隐藏层所有神经元都是全连接的形态,因此 计算偏导时下层所有神经元所传递的误差都要全部计算, 笔者依然把神经网络一部分拆出来展示, 如图七。

图七: 图五神经网络的一部分
可以看到L1层的输出o其实是与下一层所有的两个神经元连接起来的,因此o的误差其实来自于l2层神经元a1和a2, 因此计算偏导就不能像输出——隐藏那样只计算一个连接。
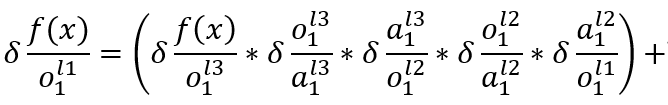
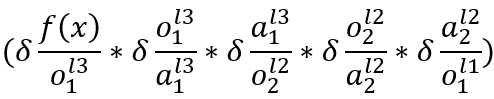
这个式子比较长,前半部分走的路径是图七中:L3层o1——L2层o1——L2层a1——L1层a1
后半部分则是:L3层o1——L2层o2——L2层a2——L1层a1
两条路径殊途同归,都指向L1层a1,
同样的,如法炮制可计算L1层a2的误差贡献。
如果一层有多个神经元,都需要用上面的几个算法依次计算,如果有很多层,很多个神经元,对计算机算力就逐渐有更高要求了。至此,整个反向计算就介绍完了, 但还有个小尾巴,我们只知道误差是多少,如何根据误差将社交网络中的权重调整到最优呢?
2.4 梯度下降算法
上一节已经知道了偏导数,即每个权重对误差的贡献。 由于神经网络最终目的是准确的计算出真实世界存在的值,我们有了已经误差,和每个权重对误差的贡献, 那么下一个不做自然而然就算把误差贡献减小。可以这样说,当没有误差时神经网络所计算的值 = 真实世界的值。 既然已经得到权重对误差贡献,只要反向的减去这个贡献,让权重往更接近真实值的那个方向调整。 数学处理上即是给偏导加个负号再减去权重, 但光加个负号其实就是默认以1为步长进行反向调整。这显然太粗糙, 于是人们在符号后面再加上个系数,例如-0.1, -0.01或者-0.05来限制或放大每次进行调整的大小。
神经网络在寻解的过程其实就是函数在寻解的过程,只有当权重取到某个值时,误差才是最小的,偏离这个值则会使误差变大, 因此可以用一个抛物线来刻画这一状态。
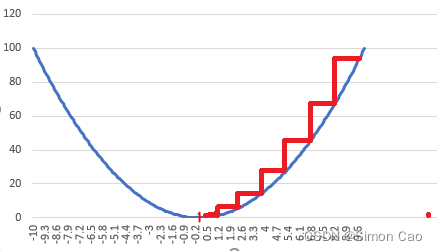
图八:梯度下降算法简图
如图八,横轴代表网络中权重与最佳拟合权重的差值,纵轴代表神经网络计算出的值与真实值的误差
权重设置得越离谱, 真实值与神经网络计算出的输出值差距也就越大。 我们的目标即是根据上节求出的偏导值调整权重, 不断缩小误差, 如图中红色阶梯所示。
2.4.1 学习率的调整
既然我们是根据真实值进行调整,那么下面该解决一次该调整多少的问题。上节中提到,在求出的偏导值前加上一个系数便能控制每次调整的步长, 我们称这个步长为学习率 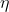。 如果系数设置过大,就是我们俗称的步子迈大了,就会一步跨太远距离,如果这个距离导致输出结果与真实值差距呈现扩散的结果,即误差越来越大,则称为梯度爆炸, 如图:
图九:输出误差越来越大
图八的梯度下降就比图九好很多,但设置过小的步长又太谨慎,如果是一个很大的网络就需要学习很多次才能逼近真实值, 大大降低了网络运行效率。笔者认为,对一个比较的的神经网络而言,最优的梯度寻解算法是自适应调整,当距离真实值较远时设置一个较大的学习率,逐渐逼近真实值的过程中,慢慢降低的值。不过对于一个小型网络,设计这样的算法其实可有可无,因为小网络对算力要求较低。
有了学习率后,我们在把学习率带入上一节的公式中,计算更新的权重:
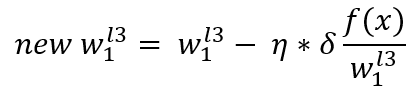
展开得:
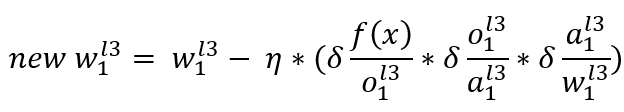
依旧如法炮制计算每一个权重连接,更新完整个网络的权重后再用数据跑一个神经网络输出值,将这个值与真实值比较,得到误差,根据误差再次进行反向运算, 然后再正向运算,得到误差,再反向运算, 如此循环,直到真实值与输出值一致。这个过程要重复多少次往往是神经网络大小,寻解算法决定的, 少则几十次,多则成千上万次。
2.4.2 全局最优解和局部最优解问题
在复杂的网络中,寻解算法所得的最优解或许站在全局来看并不是最优, 之前图八只是个很简单的单谷形态,实际问题中可能会遇上多谷形态,或许神经网络下降到某个谷底逼近了最优解,但其实比这个谷底还要低的地方可能还有一个谷底, 这时需要判断究竟哪个谷底才是全局最优解, 也并非是越低越好。看图说话, 如图十。一般只有复杂的网络算法才会遇到这样的问题,笔者暂不做讨论。
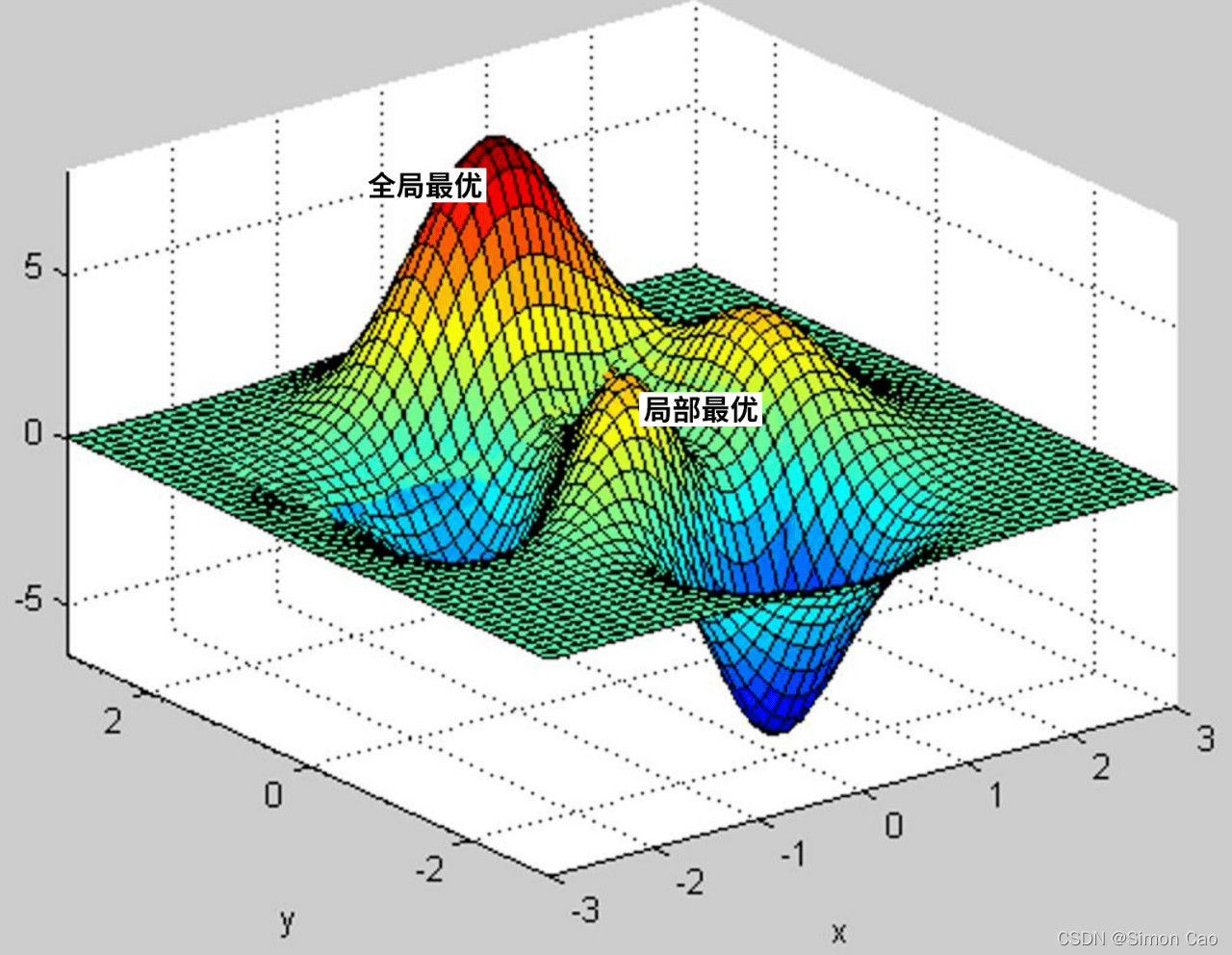
图十:局部最优解与全局最优解
2.5 神经网络偏置项
之前介绍正向算法笔者没有谈偏置项的问题,大家喜闻乐见的线性模型往往都是f(x) = ax + b, 由于神经网络用到了线性模型,这个b自然而然就被带进了神经网络里。 在线性模型中我们叫b截距, 神经网络中称为偏置。 线性模型加上截距后给予线性问题更大的可操作空间,因为如果没有b, f(x) = ax 一定是一条过原点的直线,现实情况下很大问题的解都不是一条过原点的直线所能描述的,往往需要向上或向下平移。将偏置项带入之前的网络结构中则如图十一:
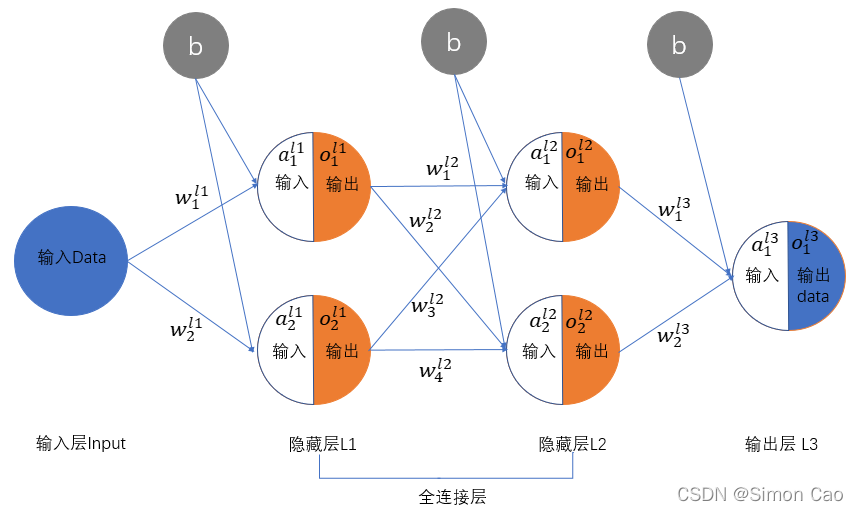
图十一:带偏置项的神经网络
隐藏层的输入是几个线性模型相加,因此每个神经元其实只要带一个偏置项就可以了,计算也非常简单,只要在神经元偏导的基础上把最后一项改成带偏导的线性函数,笔者就不做推导了。
3. 赋予神经网络金融思维
之前说了一通乱七八糟的公式和堆倒只为证明一件事,神经网络的运算是非常讲究逻辑的一套方法。 笔者将本期题目取名为全能大明星正是由于神经网络可以思考的这一特性, 通过不断的学习新数据,神经网络不断自我更新,自我进步,可以这样说,通过不断学习新数据,你的网络将不会落后于时代。(前提是网络结构,算法也能适应上数据的发展哈)
得到这样一套理论我们可以赋予它金融的思维, 通过学习市场中的数据帮助我们进行交易,择股等等。有人或许不这样想, 笔者以前听过一个百度的算法工程师说:“神经网络其实对股票市场的很多数据会感到很困惑”。 举一个很浅显的例子,市场爆炒ST股, 白马蓝筹统统躺下,这用基本面分析的神经网络去算收益恐怕。。股票市场是很复杂的一个整体,受到影响因素太多,很多时候不是业绩好公司股价才上去。 而市场中一些东西用量化手段极难解释,例如预期,短期情绪波动。这时候神经网络会感到很困惑,明明各项指标都非常不错,但股价却是下跌的。
对于这点,笔者想说的是神经网络进行的思考至少是理性的。 谁没因为情绪追涨杀跌过,但机器是没有感情的, 它所遵循的只是一套算法。其次,笔者认为近几年的a股正往好的方向发展。在如今4k+公司,全面注册制不断深入的大环境下,僧多粥少的格局依旧是未来的主旋律, 即是大盘连阳也不见得所有板块能万箭齐发,千股涨停。笔者的老师说过,股票市场短期是投票机,长期是称重机。偶尔的垃圾股爆炒注定只能昙花一现,投资者往往需要很强的投研能力才能获得长期超额回报。笔者认为神经网络正是一个具备理性投研能力的理性“投资者”, 通过学习基本面类指标,不断完善算法,提高胜率,基本面模型将成为投研中的行业挖掘机帮助人们做决策。
模型设计思路:构建数据集,导入神经网络模型训练,得到结果。 下面笔者将用少量数据构建一个3层的简单网络做展示。
4. 模型实现
导入必要模块
import tushare as ts
import random
import numpy as np
import pandas as pd
4.1 数据准备
首先准备数据, 本文采用Tushare金融大数据接口,非常方便,给笔者省下大把写爬虫的时间。笔者就随便挑三个指标吧:ROE,PE, PB。 实例化接口,需要输入自己的密钥。将相关数据请求放在静态方法下面方便重复调用。
pro = ts.pro_api("token") # 填自己的token
class report:
def __init__(self, ROE, PE, PB, pct_chg):
self.ROE = ROE
self.PE = PE
self.PB = PB
self.pct_chg = pct_chg
@staticmethod
def daily(code, start_date, end_date):
daily = pro.daily_basic(ts_code=code, start_date=start_date, end_date=end_date,
fields='ts_code,trade_date,close,total_mv,pe,pb')
return daily
@staticmethod
def roe(code, year):
indicator = pro.fina_indicator(ts_code=code, period=str(year) + "1231", fields='roe') # 最后一天表示年报, ocfps
roe = float(indicator[:1]["roe"])
return roe
@staticmethod
def trading_data(code, start_date, end_date):
trading_data = pro.daily(ts_code=code, start_date=start_date, end_date=end_date)
return trading_data
如果要请求其它财务类型指标也可以请求接口,例如资产负债表, 损益表, 通过输入参数可以返回相关指标, 非常方便。
BS = pro.balancesheet(ts_code=code, start_date=start_date, end_date=end_date,
fields='ts_code,ann_date,f_ann_date,end_date,report_type,total_assets,undistr_porfit,total_hldr_eqy_exc_min_int,'
'total_cur_assets,total_cur_liab, total_liab,total_hldr_eqy_exc_min_int, surplus_rese', end_type = 4)
IS = pro.income(ts_code=code, start_date=start_date, end_date=end_date,
fields='ts_code,ann_date,f_ann_date,end_date,report_type,'
'total_profit,revenue,n_income, fin_exp_int_exp', end_type = 4)
接下来定义下请求数据的时间点,需要注意的是财务数据和交易数据是不同步的, 财报公布是滞后的,年报于下一年4月底之前全部披露。Tushare period= “20210431”代表年报。 因为是做预测,这里请求的交易数据年份加一。
def data_craw(year, code, data_set):
# ___________________规定日期节点___________________
period = str(year)
end_date = str(year + 1) + "0431"
start_date = str(year) + "0101" # 财务数据时间点
start_trading = str(year+1) + "0101"
end_trading = str(year+1) + "1231" # 交易数据时间点
实例化交易数据,计算年涨幅;获取ROE;获取年均pe, pb, 最后输入年份,公司代码,实例化函数就好了。
trading_data = report.trading_data(code, start_trading, end_trading)
price_beg = trading_data["pre_close"][-1:].values
price_end = trading_data["close"][:1].values
pct_chg = (price_end - price_beg) / price_beg
roe = float(report.roe(code, year-1)) / 100
market = report.daily(code, start_trading, end_trading)
pe = market["pe"].mean()
pb = market["pb"].mean()
data = report(period, float(roe), pe, pb, float(pct_chg))
return data
data_collect = []
data_craw(years, code, data_collect)
4.2 构建网络
这里笔者没有采用矩阵,而是定义对象的方式算。 这是一个悲伤的故事,不说了。。
4.2.1 前向运算
定义神经元类对象,这里权值笔者采用Xavier权值初始化方法初始权重。Xavier是个人,也不多说了,感兴趣自行百度吧。
class Neural:
def __init__(self, neural, bias, weight, data): # 第几个神经元, 偏置, 权重,数据集
self.neural = neural
self.bias = bias
self.weight = weight
self.data = data
self.in_value = sum(np.multiply(self.weight, self.data)) + bias
self.out_value = self.sigmoid(float(self.in_value))
def sigmoid(self, x):
sig = 1 / (1 + np.exp(-x))
return sig
class Neu_layer:
def __init__(self, layer):
self.layer = layer # 第几层编号
def xavier_init(self, in_num, out_num): # xavier 权值初始化方法
A = - (6 / (in_num + out_num + 5)) ** 0.5
B = (6 / (in_num + out_num + 5)) ** 0.5
std_div = (((B - A) ** 2) / 12) ** 0.5
return std_div
def lay_data(self, numbers, data, input_neur_num, output_neur_num):
neural_list = [] # 放置每层神经元的数据对象
for i in range(numbers): # numbers-多少个神经元,给每个神经元创一个对象
w = [] # 跑完一个神经元初始化权重
std_div = self.xavier_init(input_neur_num, output_neur_num)
for a in range(len(data)):
w_value = np.random.normal(loc=0, scale=std_div, size=1)
w.append(float(w_value)) # 多个权重一一对应
bias = float(random.uniform(-0.1, 0.1)) # 为该层每个神经元设置一个偏置参数
a = Neural(i + 1, bias, w, data) # 第几个, bias, weight, 单个样本的一个特征值
neural_list.append(a)
self.neur_objs = neural_list
只要在lay_data函数的第二参数放每层构建几个神经元就好, 后面几个参数笔者定义的,大家可以自行改。 关键是还要让本层神经元的运算结果要当作下一层的输入, 笔者就不放这部分代码了,写的有些乱,大家可自行增加。
4.2.2 反向算法
class backward:
def __init__(self, forward_obj, actu, η): # 传入构建的神经元对象列表
self.forward_obj = forward_obj
self.o_h(actu, η)
def o_h(self, actu, η): # 输出层传递到隐藏层,传入实际值
result = self.forward_obj[-1].neur_objs[0].out_value # 输出结果
δerror = 2 * (actu - result) # 初始化成本函数偏导
new_layers = []
layer_number = 1
for layer in reversed(self.forward_obj):
new_neur_obj = []
neur_num = 1 # 记录第几个神经元
for neur in layer.neur_objs:
weight_count = 0 # 记第几个权重,避免乘错
δlast_out = [] # 上个神经元对下层某个神经元的偏导
new_weight = []
δb = δerror * (neur.out_value - neur.out_value ** 2) # 更新的偏置, δerror 是神经元的输出偏导
new_bias = neur.bias - η * δb
for data in neur.data:
if len(self.forward_obj) <= 2 or len(neur.data) <= 2: # 三层网络去执行else
δw = δerror * (0.5 - (neur.out_value ** 2)/8) * data
new_weight.append(float(
neur.weight[neur.data.index(data)] - η * δw)) # 更新的权重
out_error = δerror * (neur.out_value - neur.out_value ** 2)* neur.weight[weight_count]
δlast_out.append(out_error)
weight_count += 1
else:
δerror = new_layers[-1].δlast_neur[neur_num - 1]
δw = δerror * (neur.out_value - neur.out_value ** 2) * data
new_weight.append(float(neur.weight[neur.data.index(data)] - η * δw)) # 更新的权重
# print("out_error =", δerror, "乘以",neur.out_value -neur.out_value**2," 乘以", neur.weight[weight_count] )
out_error = δerror * (neur.out_value - neur.out_value ** 2) * neur.weight[weight_count]
δlast_out.append(out_error)
weight_count += 1
new_neu = new_neural(neur_num, new_weight, δlast_out, new_bias) # 本个神经元对象中,δlast_out 存的是下层神经元各自的偏导
new_neur_obj.append(new_neu)
neur_num += 1
δlast_neur_list = [0] * len(new_neur_obj[-1].δlast_out) # 生成一个列表用来加各自分别求的偏导,算下层神经元的总偏差
for i in new_neur_obj:
δlast_neur_list = [float(m) + float(n) for m, n in zip(δlast_neur_list, i.δlast_out)]
layer_number += 1
δlast_neur = δlast_neur_list
a = new_neu_layer(layer.layer, δlast_neur, new_neur_obj) # neur_error 原来data的偏导值
new_layers.append(a)
self.new_layers = new_layers
接下来反复调用正向算法和反向算法就可以了,定义一下训练多少次,学习率多少,再加上随机数据集进行投喂,不过要注意break条件,即梯度下降到某个阈值停止, 这些参数都要自己慢慢试才能找到最优的。
if a > actu + 0.00001 or a < actu - 0.00001: # 洗脑循环到阈值结束, actu代表正向运算跑出的值
back = backward(layer_list, actu, η)
new_layers = back.new_layers
counter += 1
print("正在学习......神经网络误差修正第{}次".format(counter), actu, a)
forward(new_layers, data, actu, η, counter)
最后给自己的网络加上个高大上的进度条吧!转义字符单行显示,process_bar可以在代码里定义个可加的变量,当作运行进度传进进去。 如果训练次数很多就要修改前面“[\033[32m%-100s\033[0m]\033[32m%.2f%%\033[0m” 这一串里100那个位置的参数。
print('\r学习进度: [\033[32m%-100s\033[0m]\033[32m%.2f%%\033[0m ' % ('>' * process_bar, process_bar + 1), end='')
4.3 回测
笔者以自建模型运行,策略也很简单,每年审计报告公告后用模型扫一遍全市场数据,取模型结果最优的前二十家公司无脑做多,每年调仓一次,价格加权,不考虑手续费,以下使用近两年回测结果略作展示。

2021年后三季度回测

2019年4月底至2020年4月底回测
20只股票从组合的角度来看已经属于比较分散化的组合了,但这是只看模型结果无脑买入,如果再结合一定的投研能力,收益率或许有可能再拔高一层。
5. 写在后面
目前根据近十年回测结果,平均年化收益率46%以上。但这意味这笔者能拳打巴菲特,脚踢暴龙兽?笔者也不这样认为,从目前回测结果看2017, 2016年笔者的模型收益率只有个位数,而且在某些年份出现较大的波动,例如19年回测结果,笔者算都不用算,眼睛扫一眼就知道夏普比率肯定不如21年。衡量一个好的组合有很多方面, 回测控制,波动率的控制都很重要。最后,笔者分析收益率较低的年份,怀疑是市场风格导致的,因为笔者目前所训练出的模型偏向成长型公司,一些年份,例如价值猛飙,st爆炒则会使模型表现非常一般,总之投资者的投研能力是模型能成功的保护伞,大势的研判也是非常重要的。
笔者还想说的一点是投资者教育,别一天到晚听网上什么炒股大神,什么金牌投顾,什么好朋友,尤其还有什么内幕消息!敲黑板画重点, 能赚钱的模型轮落不到白给的地步,做股票越是厉害越会自己做,而不是把收益无私的和别人分享, 市场是有反伸性的,人性如此。

本来这篇文章是打算元旦发出去的,不过有些事给耽搁了, 虽然晚了几天但笔者还是想祝大家22年长虹, 您若不弃,我们风雨共济。
版权归原作者 Simon Cao 所有, 如有侵权,请联系我们删除。