
Visual-Attention-Network/VAN-Classification (github.com)
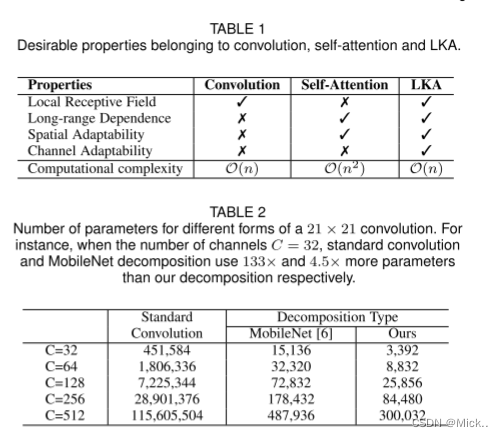
transformer在视觉领域得到良好的效果,是因为它可以捕捉长距离的信息。在视觉领域,通常有两种办法去获得长距离的信息,一是基于transformer的自注意力机制 ,二是大内核卷积。自注意力机制源于NLP,虽然在视觉领域得到很好的效果,但是仍然存在一些问题。比如说自注意力机制将2维的图像数据展开破坏了图像2D结构,而且其计算量和内存占用也比较大。大内核卷积,会引入大量的参数和计算量。作者基于这些问题,提出了大核注意力机制(LKA)。大内核注意力机制结合了卷积运算的局部感受野和旋转不变性和自注意力机制的长距离信息。
LKA
类似于mobilenet的深度可分离卷积,将一个大内核卷积分解。
将一个卷积核大小为K的卷积分解为三个卷积的和,分别是卷积核大小为K/d的深度卷积、卷积核大小为(2d-1)膨胀率为d的深度膨胀卷积,通道卷积(1*1卷积)。
下表介绍了卷积,自注意力机制,LKA(大核注意力机制)的特点
class LKA(nn.Module):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 7, padding=7//2, groups=dim) ###深度可分离卷积 卷积核的大小(2d-1)
self.conv_spatial = nn.Conv2d(dim, dim, 9, stride=1, padding=((9//2)*4), groups=dim, dilation=4) ###空洞率为4的深度可分离卷积 (卷积核大小 K/d)
self.conv1 = nn.Conv2d(dim, dim, 1) ###逐点卷积
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn = self.conv_spatial(attn)
attn = self.conv1(attn)
return u * attn
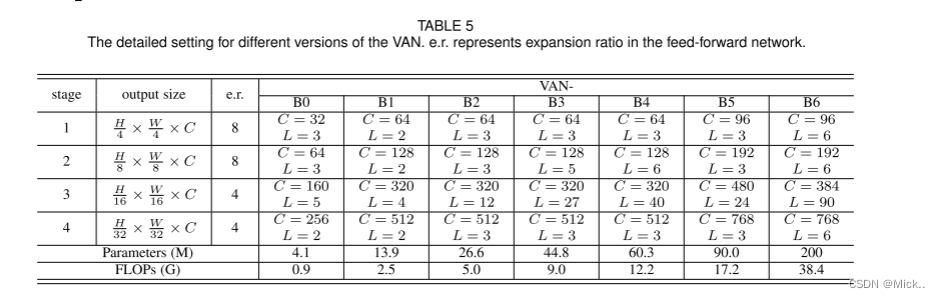
VAN
VAN结构是一个非常简单的层次结构,具有四个阶段,每个阶段的图像分辨率减半
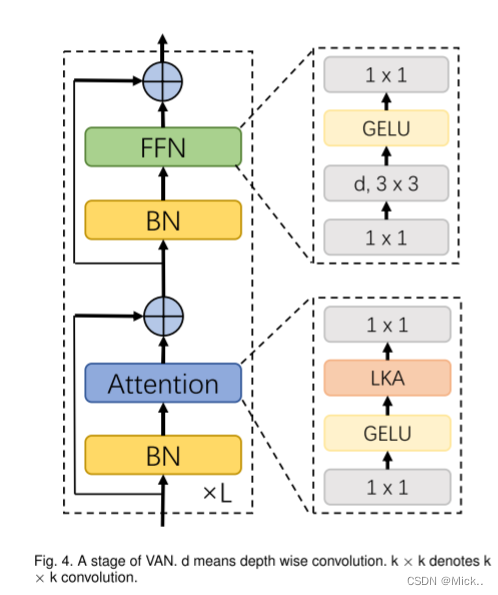
作者在每一个阶段采用卷积核的步长控制下采样的幅度,然后就是堆叠下面的结构进行特征的提取。
class Attention(nn.Module):
def __init__(self, d_model):
super().__init__()
self.proj_1 = nn.Conv2d(d_model, d_model, 1)
self.activation = nn.GELU()
self.spatial_gating_unit = LKA(d_model)
self.proj_2 = nn.Conv2d(d_model, d_model, 1)
def forward(self, x):
shorcut = x.clone()
x = self.proj_1(x)
x = self.activation(x)
x = self.spatial_gating_unit(x)
x = self.proj_2(x)
x = x + shorcut
return x
class Block(nn.Module):
def __init__(self, dim, mlp_ratio=4., drop=0.,drop_path=0., act_layer=nn.GELU):
super().__init__()
self.norm1 = nn.BatchNorm2d(dim)
self.attn = Attention(dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = nn.BatchNorm2d(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
layer_scale_init_value = 1e-2
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.attn(self.norm1(x)))
x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))
return x
实验
图像分类
设置
设置部分主要介绍了数据集的处理,一些数据增强的手段,模型训练的一些设置,具体请看原文。
消融实验
验证了LKA各个部分的有效性
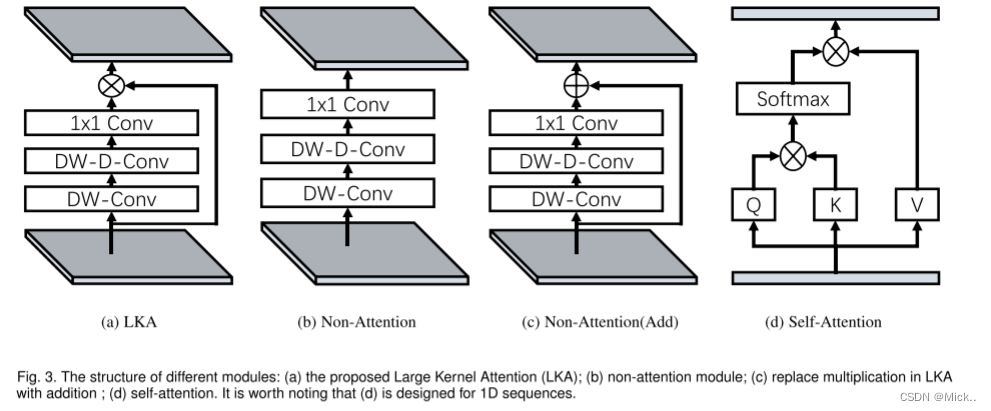
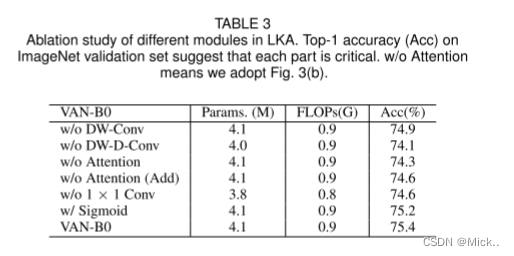
上表中第一行数据,说明了深度卷积可以充分利用图像的局部上下文信息。没有它,准确率下降了0.5
上表中的第二行数据,说明了深度扩张卷积可以捕获长范围的依赖
第三行对应得结构是图3b,第四行数据对应图3 c
第五行数据表明了1*1卷积可以捕获通道维度的关系。
第六行数据,说明了图3 1 中没有必要存在sigmoid函数。sigmoid用于将注意力图归一化到0-1之间。
最后一行,是基线模型。
通过以上分析,我们可以发现我们提出的LKA可以利用本地信息,捕获长距离依赖关系,并且在通道和空间维度上都具有适应性。此外,实验结果证明所有组件对于识别任务都是有效的。尽管标准卷积可以充分利用本地上下文信息,但它忽略了长期依赖性和适应性。对于自我注意,尽管它可以捕获远程依赖并在空间维度上具有适应性,但它忽略了局部信息和信道维度上的适应性
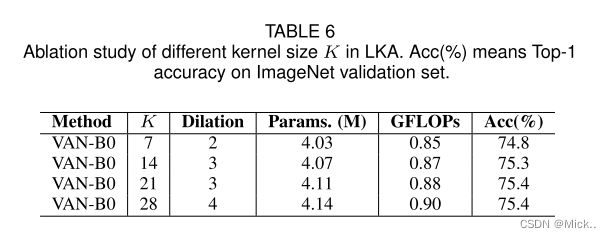
表6 验证了卷积核大小的影响
import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import math
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
x = self.fc1(x)
x = self.dwconv(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class LKA(nn.Module):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv_spatial = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3)
self.conv1 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn = self.conv_spatial(attn)
attn = self.conv1(attn)
return u * attn
class Attention(nn.Module):
def __init__(self, d_model):
super().__init__()
self.proj_1 = nn.Conv2d(d_model, d_model, 1)
self.activation = nn.GELU()
self.spatial_gating_unit = LKA(d_model)
self.proj_2 = nn.Conv2d(d_model, d_model, 1)
def forward(self, x):
shorcut = x.clone()
x = self.proj_1(x)
x = self.activation(x)
x = self.spatial_gating_unit(x)
x = self.proj_2(x)
x = x + shorcut
return x
class Block(nn.Module):
def __init__(self, dim, mlp_ratio=4., drop=0.,drop_path=0., act_layer=nn.GELU):
super().__init__()
self.norm1 = nn.BatchNorm2d(dim)
self.attn = Attention(dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = nn.BatchNorm2d(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
layer_scale_init_value = 1e-2
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.attn(self.norm1(x)))
x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))
return x
class OverlapPatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=7, stride=4, in_chans=3, embed_dim=768):
super().__init__()
patch_size = to_2tuple(patch_size)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride,
padding=(patch_size[0] // 2, patch_size[1] // 2))
self.norm = nn.BatchNorm2d(embed_dim)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
x = self.proj(x)
_, _, H, W = x.shape
x = self.norm(x)
return x, H, W
class VAN(nn.Module):
def __init__(self, img_size=224, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
mlp_ratios=[4, 4, 4, 4], drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], num_stages=4, flag=False):
super().__init__()
if flag == False:
self.num_classes = num_classes
self.depths = depths
self.num_stages = num_stages
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
for i in range(num_stages):
patch_embed = OverlapPatchEmbed(img_size=img_size if i == 0 else img_size // (2 ** (i + 1)),
patch_size=7 if i == 0 else 3,
stride=4 if i == 0 else 2,
in_chans=in_chans if i == 0 else embed_dims[i - 1],
embed_dim=embed_dims[i])
block = nn.ModuleList([Block(
dim=embed_dims[i], mlp_ratio=mlp_ratios[i], drop=drop_rate, drop_path=dpr[cur + j])
for j in range(depths[i])])
norm = norm_layer(embed_dims[i])
cur += depths[i]
setattr(self, f"patch_embed{i + 1}", patch_embed)
setattr(self, f"block{i + 1}", block)
setattr(self, f"norm{i + 1}", norm)
# classification head
self.head = nn.Linear(embed_dims[3], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def freeze_patch_emb(self):
self.patch_embed1.requires_grad = False
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed1', 'pos_embed2', 'pos_embed3', 'pos_embed4', 'cls_token'} # has pos_embed may be better
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
for i in range(self.num_stages):
patch_embed = getattr(self, f"patch_embed{i + 1}")
block = getattr(self, f"block{i + 1}")
norm = getattr(self, f"norm{i + 1}")
x, H, W = patch_embed(x)
for blk in block:
x = blk(x)
x = x.flatten(2).transpose(1, 2)
x = norm(x)
if i != self.num_stages - 1:
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
return x.mean(dim=1)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
class DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)
def forward(self, x):
x = self.dwconv(x)
return x
def _conv_filter(state_dict, patch_size=16):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {}
for k, v in state_dict.items():
if 'patch_embed.proj.weight' in k:
v = v.reshape((v.shape[0], 3, patch_size, patch_size))
out_dict[k] = v
return out_dict
model_urls = {
"van_b0": "https://huggingface.co/Visual-Attention-Network/VAN-Tiny-original/resolve/main/van_tiny_754.pth.tar",
"van_b1": "https://huggingface.co/Visual-Attention-Network/VAN-Small-original/resolve/main/van_small_811.pth.tar",
"van_b2": "https://huggingface.co/Visual-Attention-Network/VAN-Base-original/resolve/main/van_base_828.pth.tar",
"van_b3": "https://huggingface.co/Visual-Attention-Network/VAN-Large-original/resolve/main/van_large_839.pth.tar",
}
def load_model_weights(model, arch, kwargs):
url = model_urls[arch]
checkpoint = torch.hub.load_state_dict_from_url(
url=url, map_location="cpu", check_hash=True
)
strict = True
if "num_classes" in kwargs and kwargs["num_classes"] != 1000:
strict = False
del checkpoint["state_dict"]["head.weight"]
del checkpoint["state_dict"]["head.bias"]
model.load_state_dict(checkpoint["state_dict"], strict=strict)
return model
@register_model
def van_b0(pretrained=False, **kwargs):
model = VAN(
embed_dims=[32, 64, 160, 256], mlp_ratios=[8, 8, 4, 4],
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 3, 5, 2],
**kwargs)
model.default_cfg = _cfg()
if pretrained:
model = load_model_weights(model, "van_b0", kwargs)
return model
@register_model
def van_b1(pretrained=False, **kwargs):
model = VAN(
embed_dims=[64, 128, 320, 512], mlp_ratios=[8, 8, 4, 4],
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 4, 2],
**kwargs)
model.default_cfg = _cfg()
if pretrained:
model = load_model_weights(model, "van_b1", kwargs)
return model
@register_model
def van_b2(pretrained=False, **kwargs):
model = VAN(
embed_dims=[64, 128, 320, 512], mlp_ratios=[8, 8, 4, 4],
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 3, 12, 3],
**kwargs)
model.default_cfg = _cfg()
if pretrained:
model = load_model_weights(model, "van_b2", kwargs)
return model
@register_model
def van_b3(pretrained=False, **kwargs):
model = VAN(
embed_dims=[64, 128, 320, 512], mlp_ratios=[8, 8, 4, 4],
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 5, 27, 3],
**kwargs)
model.default_cfg = _cfg()
if pretrained:
model = load_model_weights(model, "van_b3", kwargs)
return model
@register_model
def van_b4(pretrained=False, **kwargs):
model = VAN(
embed_dims=[64, 128, 320, 512], mlp_ratios=[8, 8, 4, 4],
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 6, 40, 3],
**kwargs)
model.default_cfg = _cfg()
if pretrained:
model = load_model_weights(model, "van_b4", kwargs)
return model
@register_model
def van_b5(pretrained=False, **kwargs):
model = VAN(
embed_dims=[96, 192, 480, 768], mlp_ratios=[8, 8, 4, 4],
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 3, 24, 3],
**kwargs)
model.default_cfg = _cfg()
if pretrained:
model = load_model_weights(model, "van_b5", kwargs)
return model
@register_model
def van_b6(pretrained=False, **kwargs):
model = VAN(
embed_dims=[96, 192, 384, 768], mlp_ratios=[8, 8, 4, 4],
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[6,6,90,6],
**kwargs)
model.default_cfg = _cfg()
if pretrained:
model = load_model_weights(model, "van_b6", kwargs)
return model
if __name__=='__main__':
model=van_b0()
print(model)
讨论
最近,基于transformer的模型迅速征服了各种视觉排行榜。众所周知,自我注意只是一种特殊的注意机制。但是,人们逐渐默认采用自我注意,而忽略了潜在的注意方法。本文提出了一种新颖的注意力模块LKA和基于CNN的网络VAN。它超越了最先进基于transformer的视觉任务方法。我们希望本文能促进人们重新思考自我注意是否是不可替代的,以及哪种注意更适合视觉任务。
未来的工作
结构本身的不断改进。
在本文中,我们仅演示了一个直观的结构。有很多潜在的改进,例如采用不同的内核大小,引入多尺度结构 [11] 和使用多分支结构 [10]。
大规模自我监督学习和迁移学习。
VAN自然地结合了CNNs和vit的优点。一方面,VAN可以利用图像的2D结构信息。另一方面,VAN可以根据输入图像动态调整输出,这适合自我监督学习和迁移学习 [59],[64]。结合以上两点,我们相信VAN可以在图像自我监督学习和迁移学习领域取得更好的表现。
更多应用领域。
由于资源有限,我们仅在视觉任务中表现出出色的性能。VANs能否在NLP中像TCN [122] 这样的其他领域表现出色,仍然值得探讨。我们期待看到VANs成为通用模型。
版权归原作者 南妮儿 所有, 如有侵权,请联系我们删除。