
一.了解Spark架构

1.客户端:用户提交作业的客户端。
- Driver:主运用程序,该进程运行应用的 main() 方法并且创建 SparkContext。
3.SparkContext:应用上下文,控制整个生命周期。
4.Cluster manager:集群资源管理器(例如,Standlone Manager,Mesos,YARN)。
5.Spark Worker:集群中任何可以运行应用程序的节点,运行一个或多个Executor进程。
6.Executor:位于工作节点上的应用进程,负责执行计算任务并且将输出数据保存到内存或者磁盘中。
7.Task:被发送到 Executor 中的工作单元。
二.了解Spark作业运行流程
Spark有3种运行模式,即Standalone,YARN和Mesos。
1.Standalone模式

客户端提交作业给Master,Master让一个Worker启动Driver,即SchedulerBackend。Worker创建一个DriverRunner线程,DriverRunner启动SchedulerBackend进程。另外,Master还会让其余Worker启动Executor,即ExecutorBackend。Worker创建一个ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend进程。ExecutorBackend启动后会向Driver的SchedulerBackend注册。SchedulerBackend进程中包含DAGScheduler,它会根据用户程序生成执行计划,并调度执行。对于每个Stage的Task,都会被存放到TaskScheduler中,ExecutorBackend向SchedulerBackend汇报时把TaskScheduler中的Task调度到ExecutorBackend执行。所有Stage都完成后作业结束。
程序执行过程中,由Worker节点向Master发送心跳,随时汇报Worker的健康状况。
2.YARN模式
1.YARN集群模式的作业运行流程

基于YARN的Spark作业首先由客户端生成作业信息,提交给ResourceManager,ResourceManager在某一NodeManager汇报时把AppMaster分配给NodeManager,NodeManager启动SparkAppMaster,SparkAppMaster启动后初始化作业,然后向ResourceManager申请资源,申请到相应资源后SparkAppMaster通过RPC让NodeManager启动相应的SparkExecutor,SparkExecutor向NodeManager上的SparkAppMaster汇报并完成相应的任务。
2.YARN客户端模式的作业运行流程
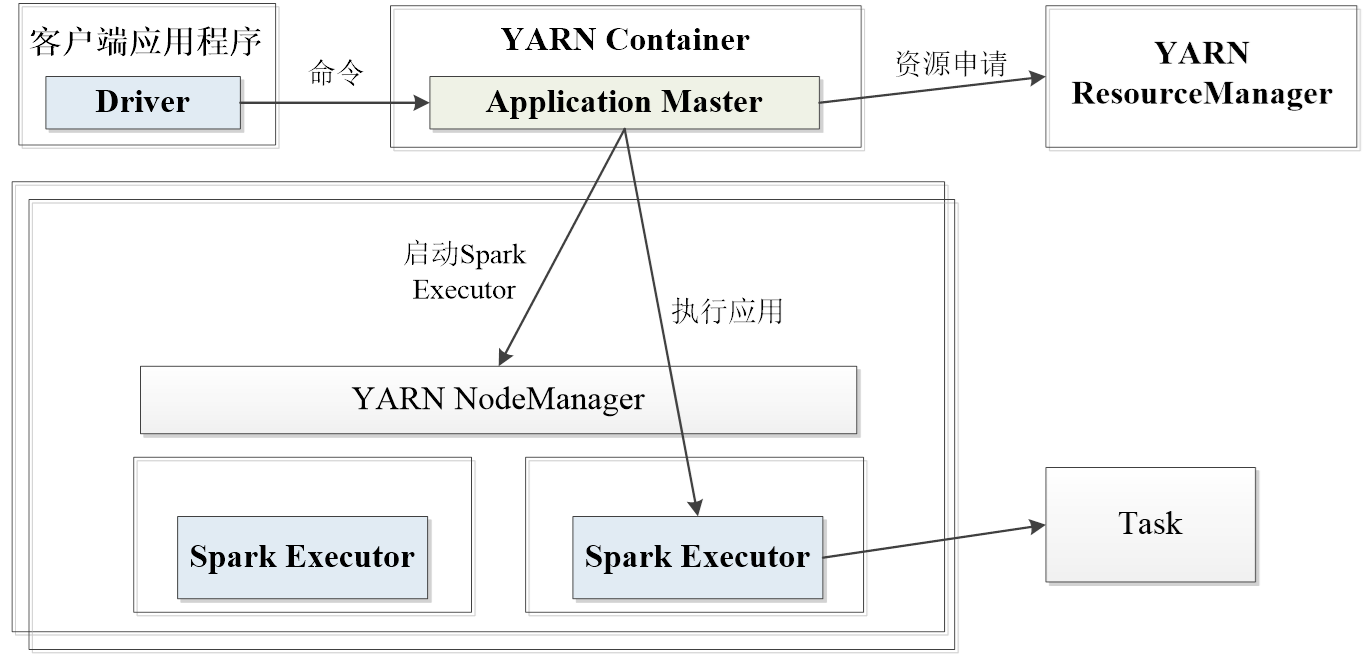
基于YARN的Spark作业首先由客户端生成作业信息,提交给ResourceManager,ResourceManager在某一NodeManager汇报时把AppMaster分配给NodeManager,NodeManager启动SparkAppMaster,SparkAppMaster启动后初始化作业,然后向ResourceManager申请资源,申请到相应资源后SparkAppMaster通过RPC让NodeManager启动相应的SparkExecutor,SparkExecutor向本地启动的SparkAppMaster汇报并完成相应的任务。
三.了解Spark核心数据集RDD
RDD全称叫做Resilient Distributed Datasets,直译为弹性分布式数据集,是spark中非常重要的概念。RDD是一个数据的集合,这个数据集合被划分成了许多的数据分区,而这些分区被分布式地存储在不同机器的内存或磁盘当中。
1.常用的转换算子
map(func): 将原 RDD 中的每个元素传递给函数 func,得到一个新的 RDD。
flatMap(func): 与 map 类似,但每个元素都可以生成多个输出,这些输出被平铺(flattening)成一个新的 RDD。
filter(func): 返回输入 RDD 中通过函数 func 的筛选结果为 true 的元素。
distinct([numTasks])): 返回输入 RDD 中所有不同的元素,可选参数 numTasks 指定任务的数量。
union(otherRDD): 返回对输入 RDD 和参数 RDD 执行联合操作的结果,生成一个新的 RDD,不去重。
intersection(otherRDD)): 返回对输入 RDD 和参数 RDD 执行交集操作的结果,生成一个新的 RDD。
subtract(otherRDD): 返回对输入 RDD 和参数 RDD 执行差集操作的结果,生成一个新的 RDD。
cartesian(otherRDD): 返回对输入 RDD 和参数 RDD 执行笛卡尔积的结果,生成一个新的 RDD。
2.常用的行动算子
reduce(func): 使用函数 func 组合 RDD 中的所有元素,返回计算结果。
collect(): 将 RDD 中的所有元素都返回给驱动程序程序。
count(): 返回 RDD 中元素的数量。
first(): 返回 RDD 的第一个元素。
take(n): 返回 RDD 的前 n 个元素。
takeSample(withReplacement, num, [seed]): 从 RDD 中随机取样 num 个元素,withReplacement 指定是否允许取样后返回的元素有重复,seed 指定随机数种子。
takeOrdered(n, [ordering]): 返回包含 RDD 前 n 个元素的列表,元素是按顺序排序的。
aggregate(zeroValue, seqOp, combOp): 使用给定的函数对 RDD 的元素进行聚合,seqOp 计算在分区中初始值到中间结果的聚合计算,而 combOp 在节点上对中间结果进行聚合。
fold(zeroValue, func): 与 aggregate 类似,但这里的 seqOp 和 combOp 相同。
foreach(func): 对 RDD 中的每个元素执行指定的函数。
四.了解Spark核心原理
Spark Stage划分依据主要是基于Shuffle。
Shuffle是产生宽依赖RDD的算子。
即Stage划分基于数据依赖关系的。
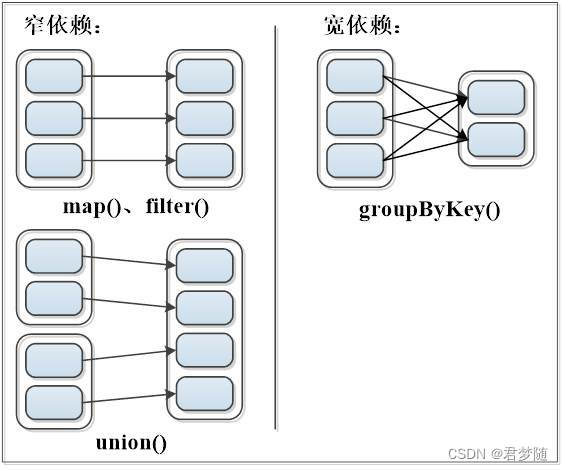
1.窄依赖
窄依赖:表现为一个父RDD的分区对应于一个子RDD的分区或者多个父RDD的分区对应于一个子RDD的分区。
2.宽依赖
宽依赖:表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。
版权归原作者 君梦随 所有, 如有侵权,请联系我们删除。