
我们都知道,在机器学习模型的测试过程中,数据集很重要。在构造数据集的时候,要注意做好数据的清洗和标注,一个高质量的数据集往往能够提高模型训练的质量和预测的准确率。在缺乏数据的情况下,可以尝试寻找一些公开数据集,特别是得到公认的被普遍使用的数据集。对于常见的任务,比如:图像识别、目标检测和图像分割的任务方面,均有对应的公开数据集可以使用。模型的选择、构建很重要,训练数据对模型也是非常重要的,在改变模型架构来尝试提高模型预测准确率的同时,也需要注意提高输入数据的质量,同时也考虑增加输入数据的数量,看是否能够提高模型的预测效果。那么,今天我们整理并汇总了相关论文、数据竞赛和领域分享中所提到的机器学习数据集,希望各位小侠客喜欢并可以基于此推进自己的机器学习算法研究。来吧,展示~
01
—
Springleaf营销响应数据集
Springleaf通过向客户提供个人和汽车贷款来帮助他们控制自己的生活和财务,从而让人类重新投入到借贷中。直邮是Springleaf 团队与可能需要贷款的客户联系的一种重要方式。
直接报价为需要它们的客户提供了巨大的价值,并且是Springleaf营销策略的基本组成部分。为了提高他们的针对性工作,Springleaf 必须确保他们专注于可能响应并成为他们服务的优秀候选人的客户。
那么,Springleaf 使用大量匿名功能要求您预测哪些客户会响应直邮报价。我们面临的挑战是构建新的元变量并采用特征选择方法来处理这个令人生畏的广泛数据集。Springleaf营销响应数据集官方地址为:
https://www.kaggle.com/competitions/springleaf-marketing-response/data
数据集描述为,我们将获得一个匿名客户信息的高维数据集。每行对应一个客户。响应变量是二元的并标记为“目标”。我们必须预测测试集中每一行的目标变量。这些功能已匿名化以保护隐私,并且由连续和分类功能的组合组成。你会在数据中遇到很多“占位符”值,代表缺失值等情况。数据集有意保留它们的编码以匹配Springleaf的内部系统。竞赛“按原样”提供特征的含义、值和类型;处理大量杂乱的功能是挑战的一部分。
02
—
StumbleUpon Evergreen分类挑战数据集
StumbleUpon是一个用户策划的Web内容发现引擎,可根据用户的兴趣向其推荐相关的高质量页面和媒体。虽然推荐的某些页面(例如新闻文章或季节性食谱)仅在短时间内相关,但其他页面保持永恒的质量,并且可以在用户被发现后很长时间内推荐给用户。换句话说,页面可以被归类为“短暂的”或“常青的”。从社区获得的评级可以提供强烈的信号,表明页面可能不再相关,但如果可以提前做出这种区分呢?“短暂”或“常青”的高质量预测将极大地改进这样的推荐系统。
很多人一看到就知道evergreen的内容,但是算法可以在没有人类直觉的情况下做出同样的决定吗?我们的任务是构建一个分类器,该分类器将评估大量URL并将它们标记为常绿或短暂。你能超越StumbleUpon吗?作为奖励的额外奖励,在竞赛中的出色表现可能会让你在旧金山最好的工作场所之一进行职业生涯的实习。StumbleUpon Evergreen分类挑战数据集官方地址为:
https://www.kaggle.com/competitions/stumbleupon/data
数据集提供的数据有两个组成部分:第一个组件是两个文件:train.tsv和test.tsv。每个都是一个制表符分隔的文本文件,包含下面概述的字段,总共 10566个 URL。没有可用数据的字段用问号表示。train.tsv是训练集,包含 7395个url。为该集合提供了二元常绿标签(常绿 (1) 或非常绿 (0))。test.tsv 是测试/评估集,包含3171个 URL。第二个组件是raw_content.zip,这是一个包含每个url的原始内容的zip文件,如StumbleUpon的爬虫所见。每个url的原始内容存储在一个制表符分隔的文本文件中,以urlid命名。
03
—
Santander客户交易数据集
在桑坦德,使命是帮助人们和企业繁荣发展,企业一直在寻找方法来帮助客户了解他们的财务状况,并确定哪些产品和服务可以帮助他们实现财务目标。他们的数据科学团队不断挑战机器学习算法,与全球数据科学界合作,以确保能够更准确地找到解决我们最常见挑战的新方法,例如:客户满意吗?客户会购买这个产品吗?客户可以支付这笔贷款吗?
在这个挑战中,santander邀请Kagglers帮助确定哪些客户将在未来进行特定交易,无论交易金额如何。为本次比赛提供的数据可用于解决此问题的真实数据具有相同的结构。Santander客户交易数据集官方地址为:
https://www.kaggle.com/competitions/santander-customer-transaction-prediction/data
我们将获得一个匿名数据集,其中包含数字特征变量、二进制target列和字符串ID_code列,任务是预测target测试集中列的值。

04
—
Google Brain呼吸压力数据集
当病人呼吸困难时,医生会怎么做?他们使用呼吸机通过气管中的管子将氧气泵入镇静患者的肺部。但机械通气是一项临床医生密集型程序,这一限制在 COVID-19 大流行的早期就显著表现出来。同时,即使在进入临床试验之前,开发控制机械呼吸机的新方法也非常昂贵。高质量的模拟器可以减少这一障碍。
当前的模拟器被训练为一个整体,其中每个模型模拟一个肺设置。然而,肺部及其属性形成了一个连续的空间,因此必须探索一种考虑患者肺部差异的参数化方法。Google Brain 的团队与普林斯顿大学合作,旨在围绕机器学习发展机械通风控制社区。他们认为,与当前的行业标准 PID 控制器相比,神经网络和深度学习可以更好地泛化具有不同特征的肺部。
在竞赛中,我们将模拟连接到镇静患者肺部的呼吸机。最好的提交将考虑肺属性的顺应性和阻力。如果成功,我们将帮助克服开发控制机械呼吸机的新方法的成本障碍。这将为适应患者的算法铺平道路,并在这些新时期及以后减轻临床医生的负担。因此,呼吸机治疗可能会变得更广泛,以帮助患者呼吸。Google Brain呼吸压力数据集官方地址为:
https://www.kaggle.com/competitions/ventilator-pressure-prediction/data
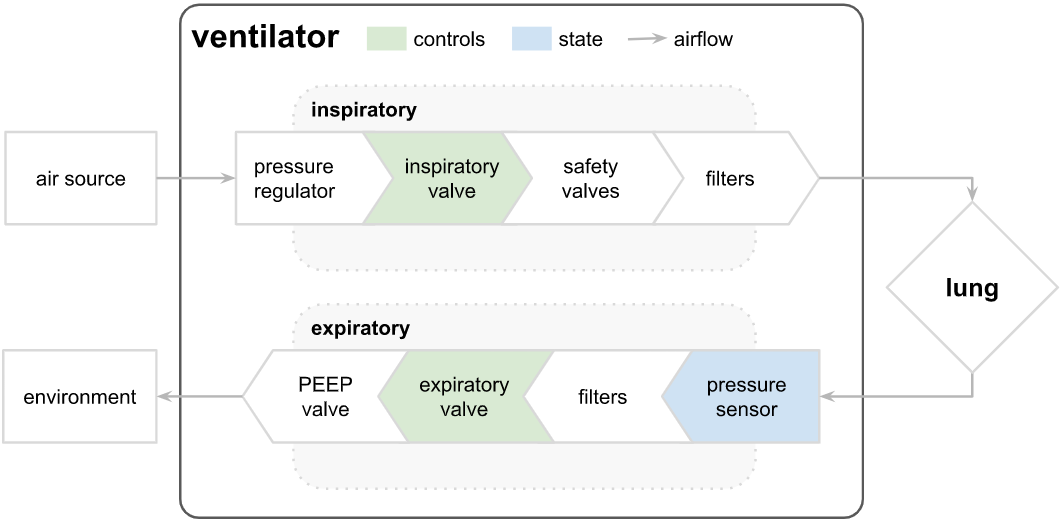
比赛中使用的呼吸机数据是使用改进的开源呼吸机产生的,该呼吸机通过呼吸回路连接到人工波纹管测试肺。下图说明了设置,两个控制输入以绿色突出显示,状态变量(气道压力)以蓝色突出显示。第一个控制输入是一个从0到 100的连续变量,表示吸气电磁阀打开以让空气进入肺部的百分比(即,0完全关闭,没有空气进入,100完全打开)。第二个控制输入是一个二进制变量,表示探测阀是打开 (1) 还是关闭 (0) 以排出空气。在比赛中,参与者被给予大量时间序列的呼吸,并将学习在给定控制输入的时间序列的情况下预测呼吸期间呼吸回路中的气道压力。
05
—
Allstate索赔成本数据集
当你被一场严重的车祸摧毁时,你的注意力会放在最重要的事情上:家人、朋友和其他亲人。与您的保险代理人一起推理是您最不想花费时间或精力的地方。这就是为什么美国个人保险公司Allstate不断寻求新的想法来改善他们为他们所保护的超过1600万个家庭提供的理赔服务。
Allstate目前正在开发预测索赔成本和严重程度的自动化方法。在本次挑战中,Kaggler受邀展示他们的创造力并通过创建一种准确预测索赔严重程度的算法来展示他们的技术实力。有抱负的竞争对手将展示对预测索赔严重程度的更好方法的洞察力,以便有机会参与Allstate确保无忧客户体验的努力。Allstate索赔成本数据集官方地址为:
https://www.kaggle.com/competitions/allstate-claims-severity/data
该数据集中的每一行代表一个保险索赔,我们需要预测“损失”列的值。以“cat”开头的变量是分类变量,而以“cont”开头的变量是连续变量。

06
—
“值得买”电子商务销量数据集
随着电子商务与全球经济、社会各领域的深度融合,电子商务已成为我国经济数字化转型巨大动能。庞大的用户基数,飞速发展的移动互联网行业,让中国成为全球电子商务规模最大、发展最快的国家之一。大数据、云计算、人工智能、虚拟现实等数字技术为电子商务创造了丰富的应用场景,不断催生如直播带货、推荐平台、农村电商、新国潮、新文创、在线生鲜等新营销模式和新商业业态。
为运用人工智能技术提升用户体验,解决电商企业痛点、难点问题,助力人工智能领域优秀人才的培养,在商务部电子商务和信息化司、北京市商务局指导下,首届电子商务AI算法大赛(ECAA)开幕。“值得买”电子商务销量数据集官方地址如下:
https://www.automl.ai/competitions/19
该比赛提供了消费门户网站“什么值得买”2021年1月-2021年5月真实平台文章数据约100万条,旨在根据文章前两个小时信息,利用当前先进的机器学习算法进行智能预估第三到十五小时的文章产品销量,及时发现有潜力的爆款商品,将业务目标转化成商品销量预测,为用户提供更好的产品推荐并提升平台收益。
07
—
爱荷华州房价数据集
这是经典的房价数据集,已被纳入sklearn的标准数据集当中。你有一些 R 或 Python 和机器学习基础知识的经验。对于已经完成机器学习在线课程并希望在尝试特色比赛之前扩展技能的数据科学学生来说,这是一场完美的比赛。
让购房者描述他们梦想中的房子,他们可能不会从地下室天花板的高度或靠近东西铁路的地方开始。但是这个比赛的数据证明,比卧室数量或白色栅栏更能影响价格谈判。爱荷华州房价数据集官方地址如下:
https://www.kaggle.com/competitions/house-prices-advanced-regression-techniques/data
该数据集共包含79个解释变量(几乎)描述了爱荷华州艾姆斯住宅的各个方面,这项竞赛挑战我们预测每栋房屋的最终价格。

08
—
TFI餐厅销售额数据集
TFI在全球拥有1200多家快餐店,是一些世界上最知名品牌背后的公司:汉堡王、Sbarro、Popeyes、Usta Donerci和Arby's。他们在欧洲和亚洲雇佣了 20000多名员工,并在开发新的餐厅网站方面进行了大量日常投资。
目前,决定何时何地开设新餐厅很大程度上是一个基于开发团队个人判断和经验的主观过程。这种主观数据很难跨地域和文化准确推断。新的餐厅网站需要大量的时间和资金来启动和运行。如果选择了错误的餐厅品牌位置,该站点将在18个月内关闭,并产生运营损失。
我们需要找到创建一个机器学习模型来提高对新餐厅网站的投资效率将使 TFI 能够在其他重要业务领域进行更多投资,例如可持续性、创新和新员工培训。本次竞赛使用人口统计、房地产和商业数据,挑战预测100000 区域位置的年餐厅销售额。TFI餐厅销售额数据集官方地址如下:
https://www.kaggle.com/competitions/restaurant-revenue-prediction/data
该数据集包含137家餐厅的训练集和100000家餐厅的测试集。数据列包括开放日期、位置、城市类型和三类混淆数据:人口数据、房地产数据和商业数据。收入列表示餐厅在给定年份的(转换后的)收入,是预测分析的目标。
9
—
Walmart零售数据集
对零售数据建模的一个挑战是需要根据有限的历史做出决策。如果圣诞节只来一年一次,那么了解战略决策如何影响利润的机会也是如此。
在本次竞赛中,我们将获得位于不同地区的45家沃尔玛门店的历史销售数据。每个商店包含许多部门,参与者必须预测每个商店中每个部门的销售额。为了增加挑战,数据集中包含选定的假日降价事件。众所周知,这些降价会影响销售,但很难预测哪些部门受到影响以及影响的程度。沃尔玛零售数据集官方地址如下:
https://www.kaggle.com/competitions/walmart-recruiting-store-sales-forecasting/data
我们将获得位于不同地区的 45 家沃尔玛商店的历史销售数据。每家商店都包含多个部门,我们的任务是预测每家商店的部门范围内的销售额。
此外,沃尔玛全年举办多次促销降价活动。这些降价促销是在重要节日之前进行的,其中四个最大的节日是超级碗、劳动节、感恩节和圣诞节。包括这些假期在内的周在评估中的权重是非假期周的五倍。该比赛提出的部分挑战是在没有完整/理想的历史数据的情况下模拟降价对这些假期周的影响。

版权归原作者 AbnerAI 所有, 如有侵权,请联系我们删除。