
金磊 发自 现场
量子位 | 公众号 QbitAI
刚刚,智谱来了一波大的——
你的手机、PC等设备,统统都是可以让AI来自动驾驶了。
在现场,智谱CEO张鹏直接来了一个live demo。
只见他掏出荣耀手机,仅仅是说了三句话,就让AI给现场和线上的观众发了两个大红包:
帮我创建一个面对面群聊,数字为1129,并将群聊名字改成智谱开放日。
帮我在智谱开放日的群聊里发个一万的红包,数量为一百个,名字为“AI给你发的第一个红包”。
帮我在支付宝发八百八十八个,总额为一万的口令红包。
比较有意思的是,AutoGLM现场“翻车”了,但这个小插曲不是因为自身能力……而是因为现场观众手速太快,AI挤不进去群 。
。
除了手机之外,张鹏在现场还展示手机和PC联动的自动驾驶。
例如群发文件:
微信给智谱开放日,发送文件:智谱开放日新闻稿.pdf。
再如给微博点赞:
打开微博,帮我给王心凌的微博点赞并发布评论。
嗯,在PC上执行这些任务,现在统统都变成发个指令就可以的事情了,然后AI就会像人一样,一步一步帮你去做。
由此可见,大模型的输出已不再局限于文本、图像、音频或视频这样的多模态;现在,它可以是一种动作(Action)。
正如张鹏在发布会中所述:
这一应用展现了大模型从对话(Chat)走向操作(Act),从生成式AI(GenAI)迈向代理式AI(Agentic AI)的演进趋势。
但纵观整场发布会,智谱不仅仅是“发布”这个动作,AI自动驾驶的能力也有了相应的提升。
外卖能比价,54个步骤不带断的
智谱此次在Auto这件事儿上,一共发布了三大产品,分别对应的是手机、Web和PC。
接下来,我们就逐个来看下。
手机:可自动驾驶更复杂的任务
AutoGLM,作为智谱在手机上的自动驾驶,其实在一个月前就已经开启内测。
而从今天的发布来看,是可以处理更加复杂的工作,例如跨APP“货比三家”。
在下面的这个案例中,AutoGLM就先打开了美团、再打开饿了么,对同一个商品的价格做了对比:

即使面对多达54个步骤的超长任务,AutoGLM也能不间断“唰唰唰”地自主执行。
在下面这个例子中,用户仅需说一句:
帮我在小红书上看下准备火锅都需要哪些食材,去小象超市采购回来。
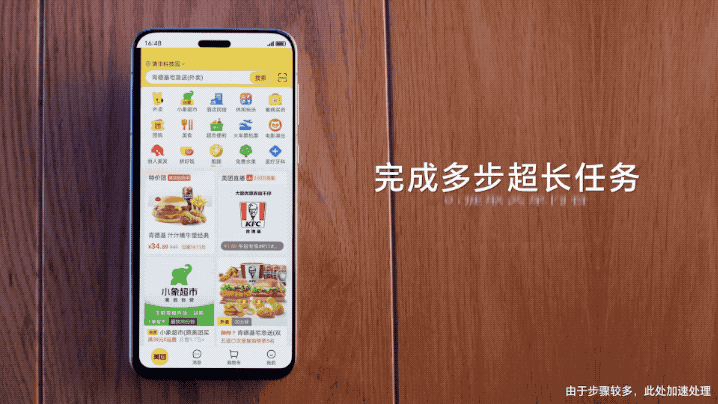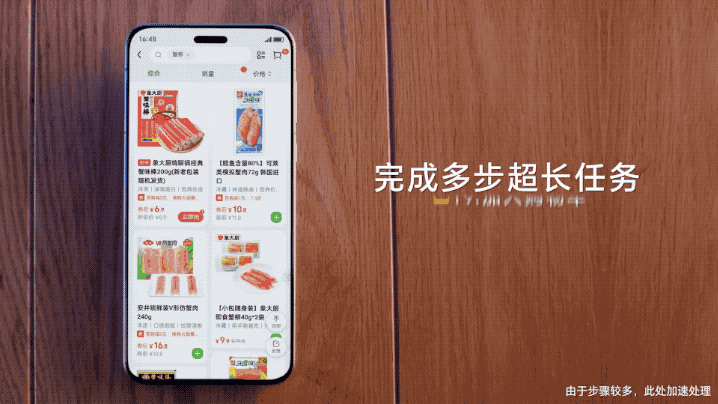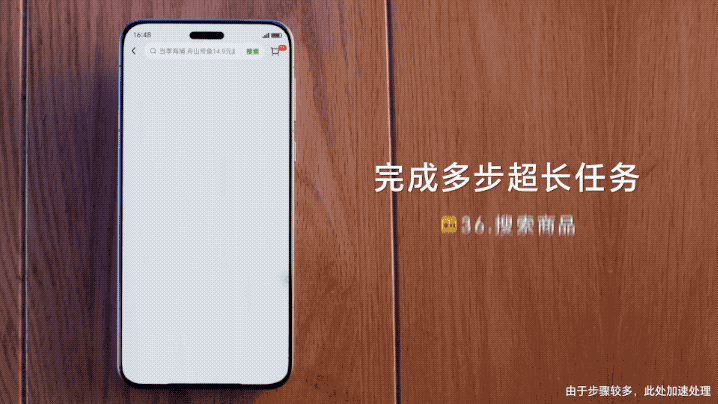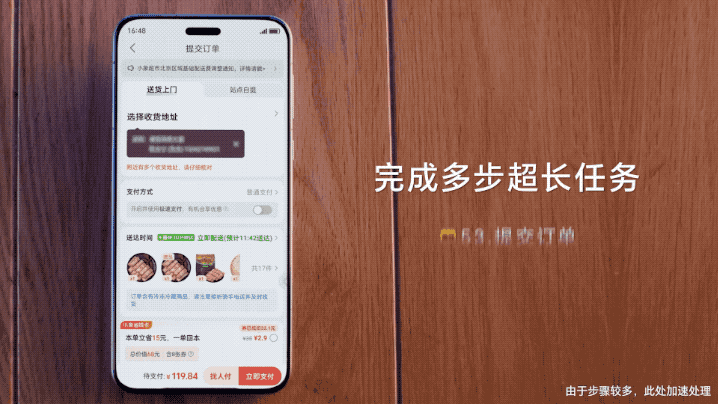
张鹏表示,他们还亲自测算了一下,AutoGLM处理时间要比人类还快一些。
除此之外,AutoGLM还推出了2个新玩法。
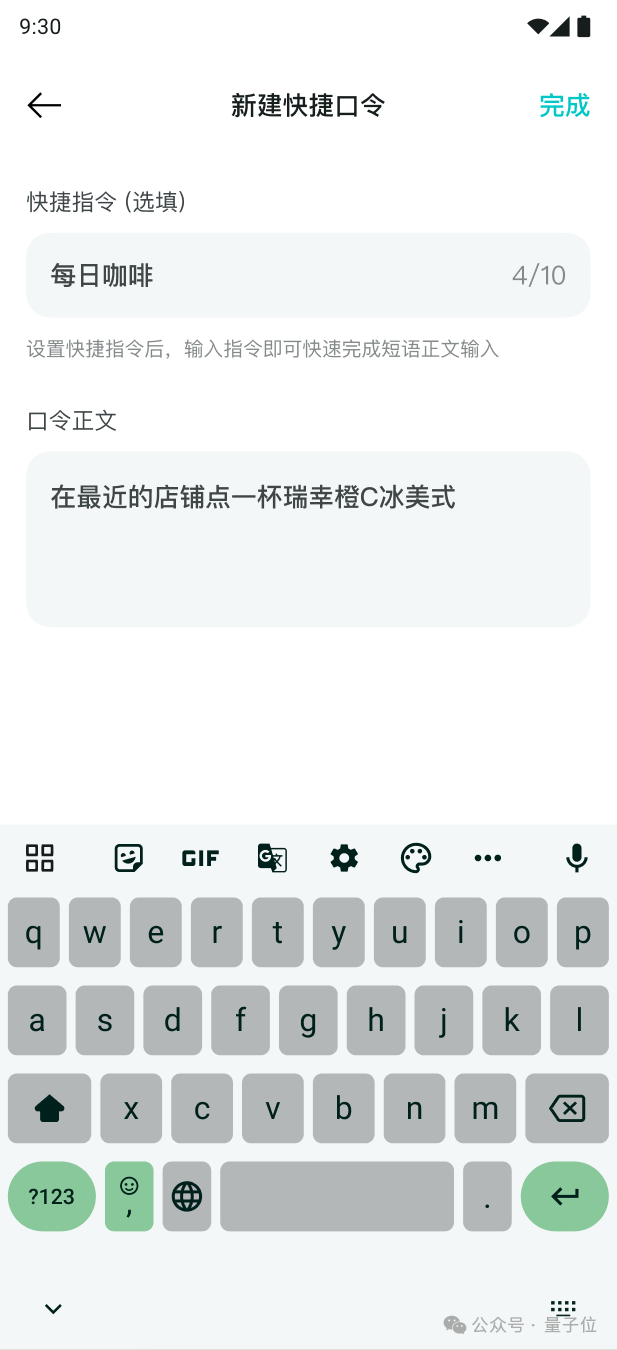
第一个就是快捷短口令,对于经常提的要求,例如“在最近的店铺点一杯瑞幸橙C冰美式”,以后不用每次都说这么多字了。
现在可以把它设置为“每日咖啡”这四个字即可:
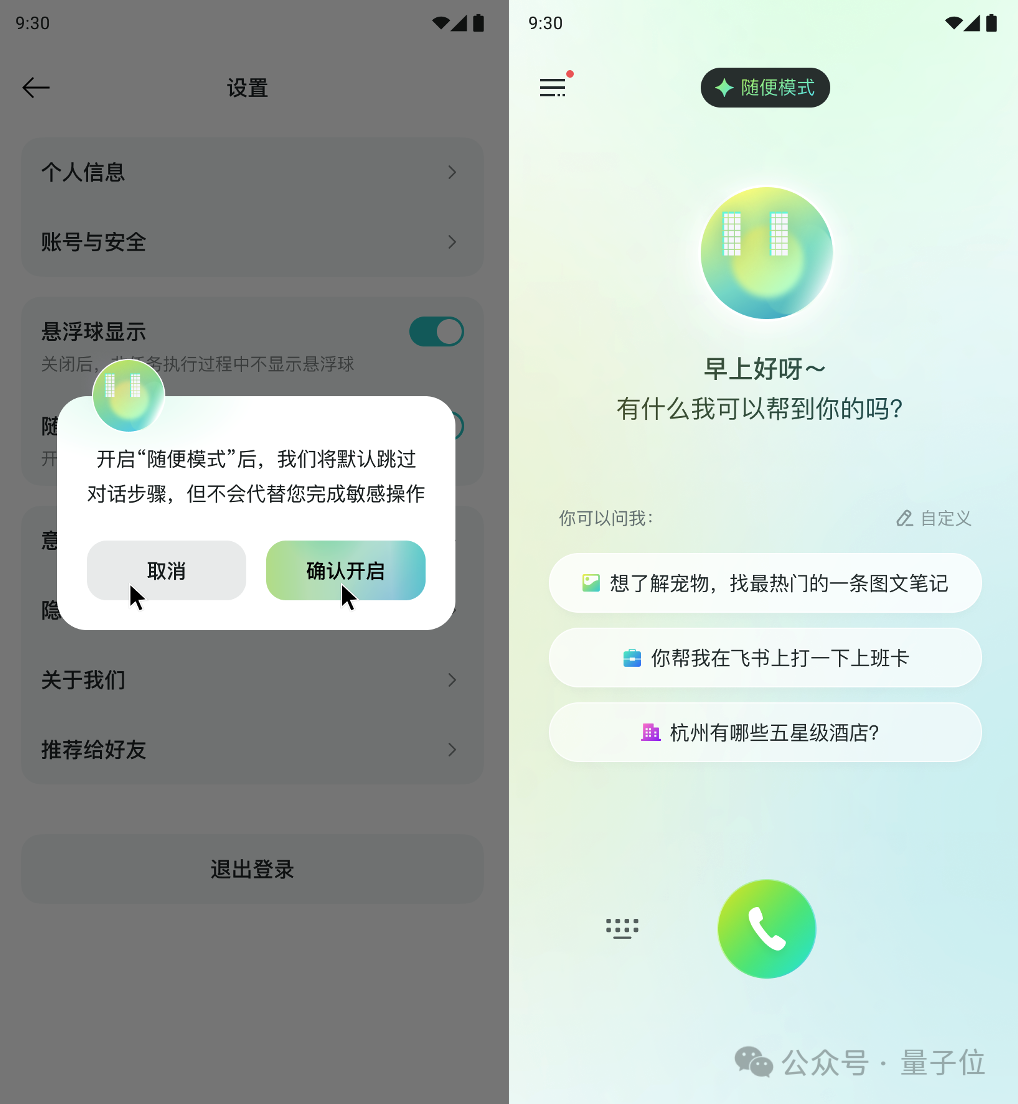
第二个新玩法就是随便模式——遇事不决,让AI来做选择。
还是点咖啡这个例子,在随便模式下,AI会随机咖啡品牌和种类,直到关键的付款界面才需要用户来操作。
Web:全自动上网
除了手机端之外,现在的Web端也可以Auto了。
在下面这个例子中,AutoGLM-Web自动完成了“在百度搜索芒果TV,打开再见爱人,播放最新一集,发弹幕”。全程没有人的干预。
据悉,这个功能目前已经支持百度搜索、微博、知乎、GitHub 等数十个网站的自动驾驶。
PC:琐碎工作交给AI
GLM-PC是智谱这次新发布的电脑端的自动驾驶。
例如这样的任务:
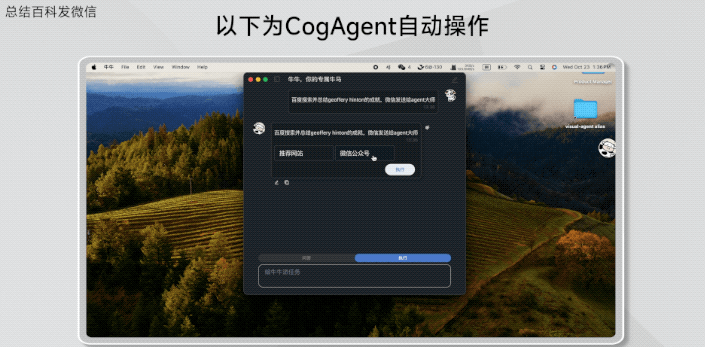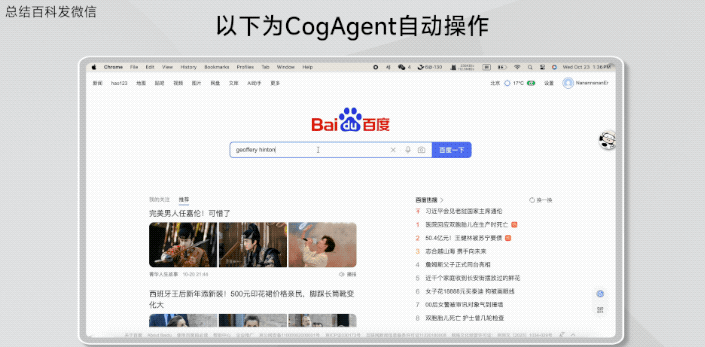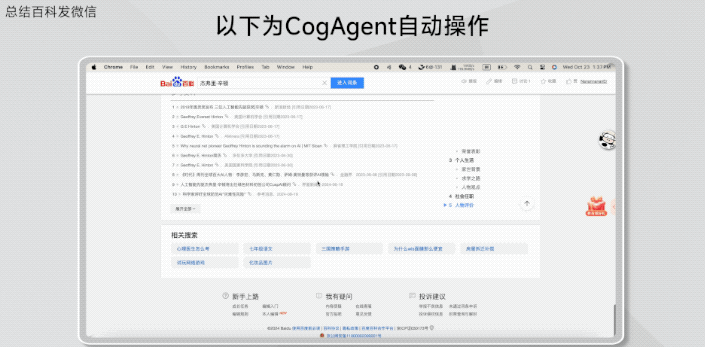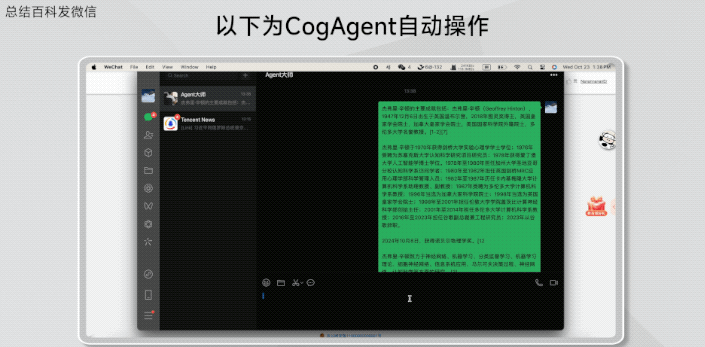
查询浏览并总结Geoffrey Hinton的百度百科,发给微信联系人。
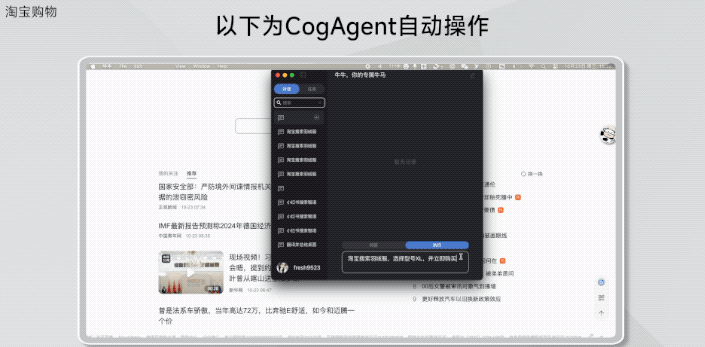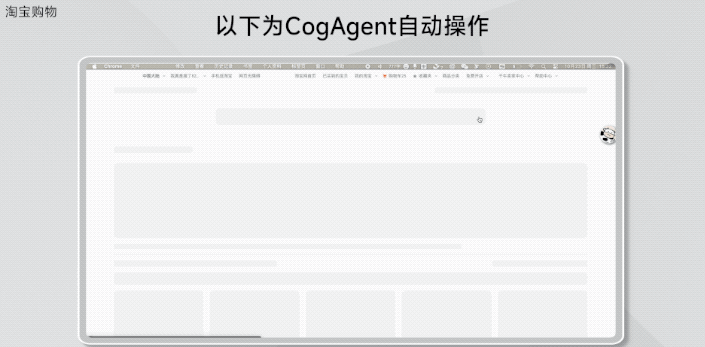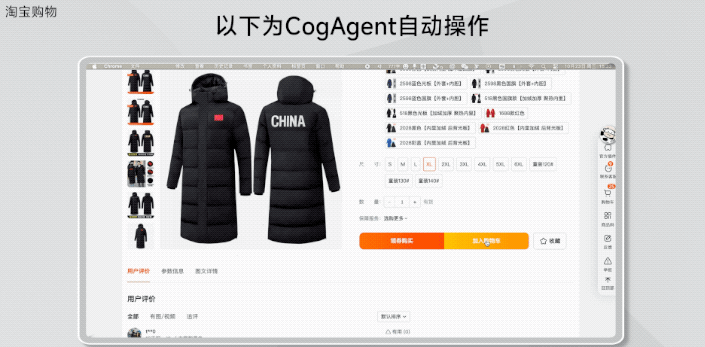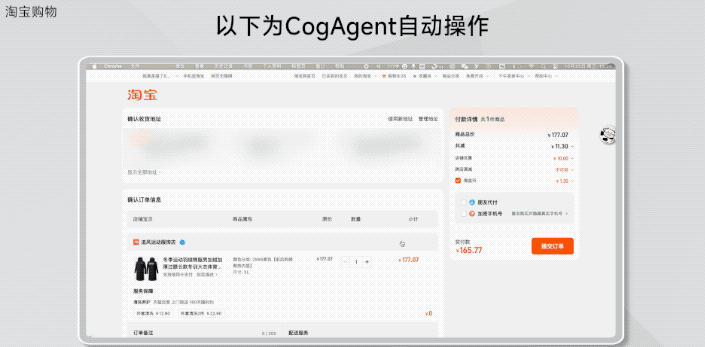
再如淘宝购物:
在淘宝上买XL的羽绒服并购买。
还有仅是把聊天截图丢给GLM-PC,它就直接能帮你预定会议:
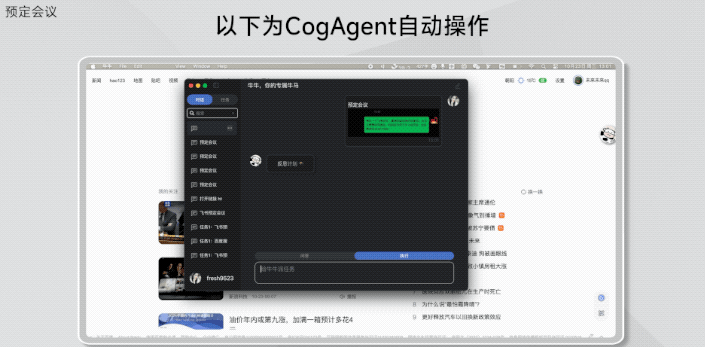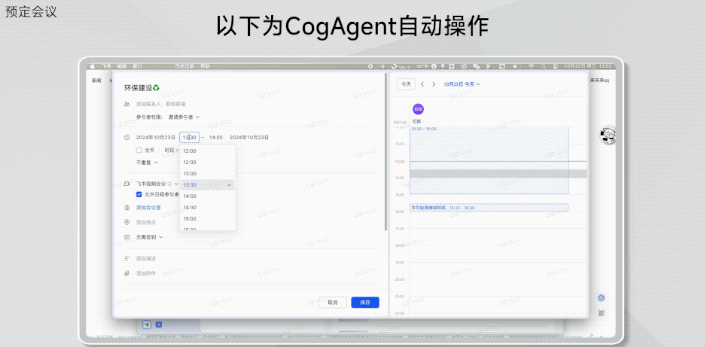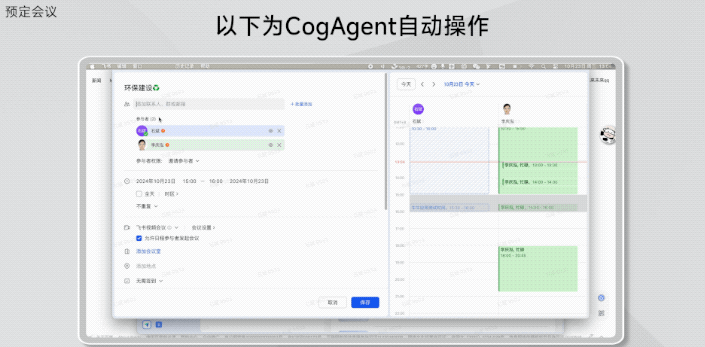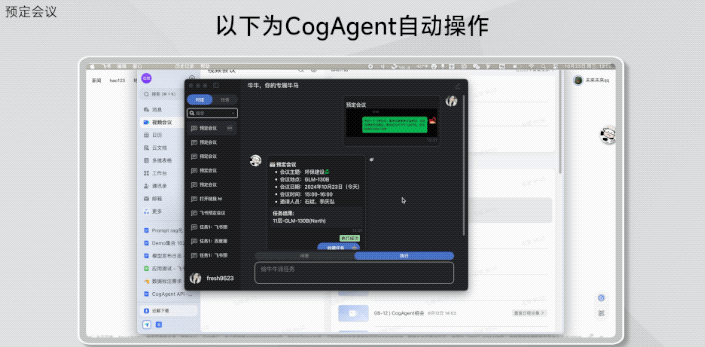
据悉,目前智谱开放第一阶段的内测体验场景整体包括:
- 信息:适配微信、飞书、钉钉,可向联系人或群聊发送发信息
- 参与会议:适配腾讯会议、飞书会议等,可定会议日程、发送会邀;可定时加入指定会议
- 文档处理:支持文档下载、文档发送、理解和总结文档
- 网页总结:可打开浏览器,在平百度、公众号、知乎、小红书等平台搜索关键词,进行阅读总结或者翻译等
总而言之,以往诸多琐碎的事务,都可以交给AI来自动完成了。
背后是全球首个UI Agent视觉基座模型。
对于AI自动驾驶背后的原理,其实智谱也已经发布过相关的论文。
而此次发布的GLM-PC是一种拟人的多模态的感知,正是基于这篇智谱自研模型CogAgent。
值得一提的是,这也是全球首个UI Agent视觉基座模型。

CogAgent是一种视觉语言模型(VLM),专门用于理解和导航GUI。
与仅能处理文本输入的语言模型不同,CogAgent可以处理截屏图像,通过视觉输入来识别页面元素,如按钮、图标和文本位置。
因此,它不仅能理解页面上的内容,还能直接模拟人类用户的操作进行交互。
CogAgent的特别之处在于它结合了低分辨率和高分辨率的图像编码器,以便更好地理解GUI页面中不同类型的信息。
其输入图像分辨率高达1120×1120,能够准确识别页面上较小的图标和文本,使其在复杂的GUI任务中表现优异。
而CogAgent的核心可以归结为两大部分:
- 一个视觉编码器
- 一个语言解码器
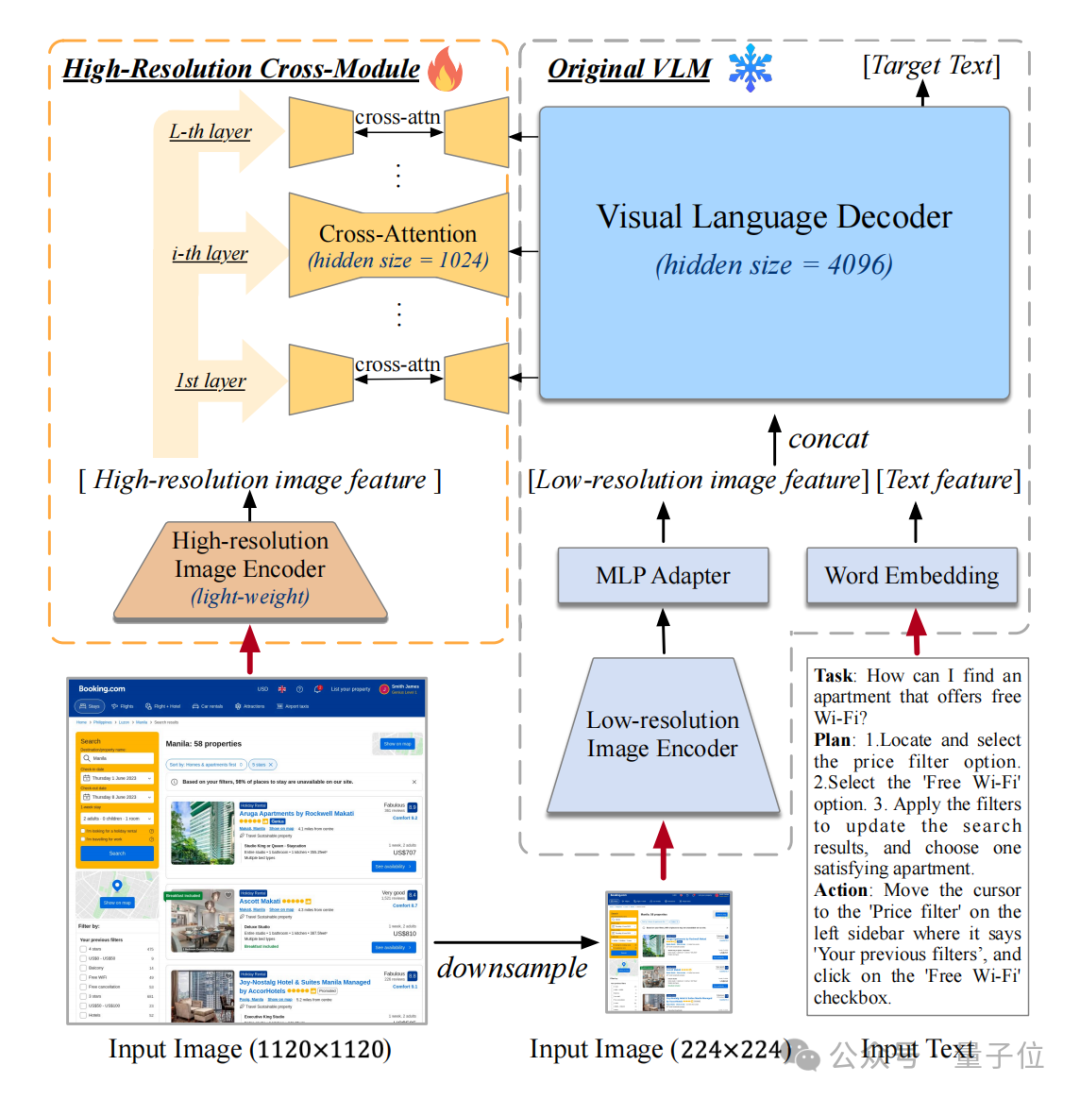
视觉编码器用于处理输入的GUI截屏,将其转换为适合模型理解的特征表示。
为了平衡计算复杂度和输入分辨率,CogAgent使用了一种称为高分辨率交叉模块的新设计,使得模型可以在高分辨率下仍然保持较低的计算开销。
这一模块的引入,使得CogAgent可以在无需显著增加计算资源的情况下,获得更精细的图像特征。
具体来说,CogAgent利用一种跨注意力机制,将高分辨率图像特征与语言特征进行融合,从而在不同层次上理解页面元素的关系。
这样的设计,使得CogAgent在理解和操作网页和移动设备的GUI任务上远超基于语言模型的其他方法。
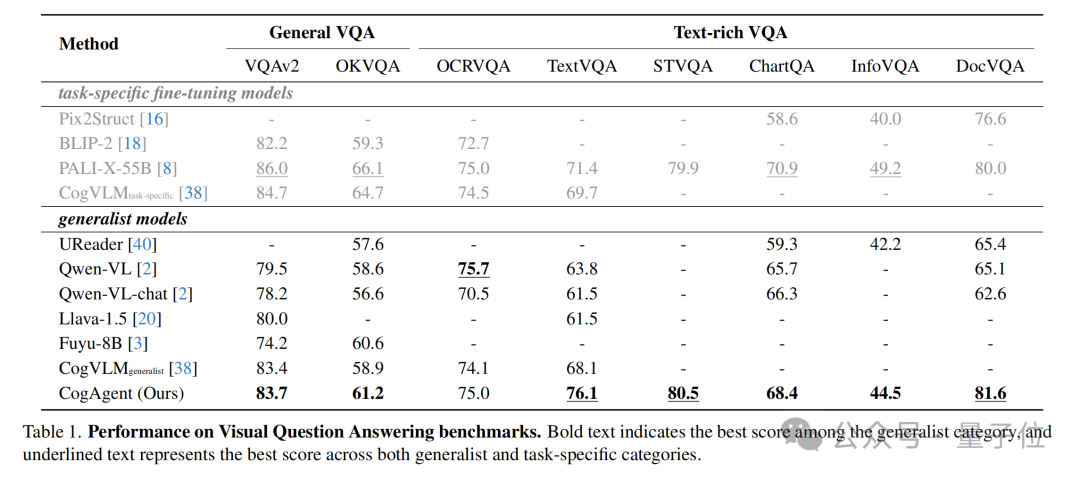
作为一种通用视觉语言模型,CogAgent在包括VQAv2、OK-VQA、Text-VQA、ST-VQA、ChartQA、infoVQA、DocVQA、MM-Vet和POPE在内的五个文本密集型和四个通用视觉问答基准任务上达到了最先进水平。
仅通过截图作为输入,CogAgent在PC和Android的GUI导航任务上超越了基于LLM的方法(例如Mind2Web和AITW)所使用的HTML提取文本输入,大幅提升了当前技术水平。
为什么Auto这件事很重要?
若是观察近期业内的发展趋势,Auto已然成为较为前沿的那一个。
例如苹果的Apple Intelligence,Anthropic的Computer Use、谷歌的Jarvis,再到传闻的OpenAI即将发布的Operator。
顶尖企业,纷纷剑指Auto。那么为何会如此?
先看技术发展。
在大模型技术出现之前,人们只能通过键盘、鼠标、多点触控等物理方式与机器交互,始终是人在适应机器。
而用户至今仍需花费大量时间学习各种软件操作,尤其是复杂的企业软件界面,频繁跨多个应用执行工作流,充满了重复的机械操作,必须手动完成。
大模型正在改变这一点,让机器适应人。这得益于大模型在自然语言、多模态感知和逻辑推理等方面的突破。
因此,现在的大模型可以理解界面、规划任务、使用工具,甚至实现自我改进,初步具备了模仿人类与物理世界互动的能力。
一言蔽之,Agent带来了更符合直觉的人机交互。
再来看市场趋势。
Gartner已将代理式AI列为 2025 年十大技术趋势之一,据其预测:
到2028年,至少有15%的日常工作决策将由代理式AI自主完成。
至于智谱对此的理解,张鹏在现场也给出了解释。
智谱将大模型的发展分为五个阶段:L1语言能力、L2逻辑能力(多模态)、L3工具使用能力、L4自我学习能力和L5探究科学规律。目前:
- L1语言能力:已达80%
- L2逻辑能力:已达60%
- L3工具使用能力:还在初期阶段
- L4自我学习能力和L5科学探究能力:正在探索中
在L3阶段,尽管取得了明显进展,但大模型在一些基本操作上仍存在挑战,例如滚动、拖动和缩放,这些对人类来说是轻而易举的。

并且智谱对于Agent技术的发展并非是一蹴而就。
从2023年4月的AgentBench开始,到8月的CogAgent模型,2024年的多项成果,智谱针对于AutoGLM和GLM-PC的模型CogAgent的研发工作,也进行了一年半的时间。
智谱还表示,未来将继续加速对Agent模型产品的研发。
One More Thing
AI要想Auto起来,技术能力固然是一方面,但生态亦然也是重要。
为此,智谱已经在芯片、操作系统 、模型侧和应用APP侧,进行了一段时间的探索,和诸多手机、PC厂商实现了深度合作。
在现场,包括荣耀、小鹏、华硕、高通、英特尔等合作伙伴也纷纷来站台。
智谱COO张帆还表示:
Agent不仅在操作系统和APP上可以实现用户体验变革,还将会推广到各类智能设备上,实现基于大模型的互联互通。
这种扩展,具体到当下的各种设备,从手机到电脑,再到汽车、眼镜、家居和各种边端设备,理论上是没有边界限制的。
对于万物皆可Auto的未来,你期待了吗?
内测地址放下面了,感兴趣的小伙伴可以去申请哦~
清言插件:
https://new-front.chatglm.cn/webagent/landing/index.html?channel=ads_news_openday
AutoGLM-安卓:
https://agent.aminer.cn/
GLM-PC:
https://www.wjx.top/vm/mOs9cHw.aspx

— 完 —
「MEET2025智能未来大会」
火热****报名中
定档12月11日!李开复博士、周志华教授、智源研究院王仲远院长都来量子位MEET2025智能未来大会探讨行业破局之道了!
最新嘉宾阵容在此,观众报名通道已开启!欢迎来到MEET智能未来大会,期待与您一起预见智能科技新未来 



















左右滑动查看最新嘉宾阵容
点这里👇关注我,记得标星哦~
版权归原作者 QbitAl 所有, 如有侵权,请联系我们删除。