
1. nn.CrossEntropyLoss()
分类中,经常用 nn.CrossEntropyLoss() 交叉熵损失函数
y 为真实值 、 y(hat) 为预测值
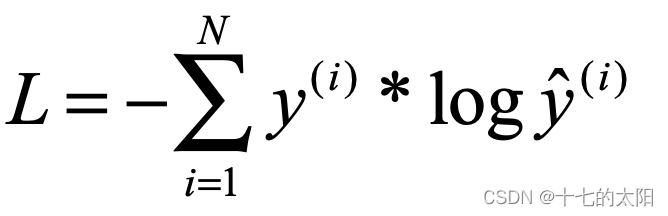
** 这种采用了 one-hot 编码的形式,多分类中,只有一个label为1**
softmax 可以将数据以概率的形式输出,所以输出是在 0-1 之间,那么log 就会是负数,因此交叉熵损失函数前面有个负号。
这也是为什么多分类需要输出经过softmax
nn.CrossEntropyLoss() 已经将 softmax 封装在里面了
2. 多分类中 nn.CrossEntropyLoss() 的应用
测试需要的文件

demo 如下,reshape为(1,-1) 是假设batch为1的情况
分类label的 one-hot 编码需要是float类型,因为分类的label需要进行计算
1.0 * ln predict

损失结果为:

接下来验证 nn.CrossEntropyLoss() 交叉熵损失函数

结果是一样的
3. 分割中 nn.CrossEntropyLoss() 的应用
一般来说,图像分割的网络输出是4维度的,对应的label 是3维的
predict : 1,2,2,2
label : 1,2,2
假设:预测结果是两个channel 的图像
- 假如第一个channel 的左上角经过softmax 后概率是0.2
- 假如第二个channel 的左上角经过softmax 后概率是0.8
假设第一个channel 是背景(0)的类别,第二个channel是前景(1)的类别,****因此需要保证两个预测概率的和为1。
然后取最大的概率为第二个channel的0.8
所以认为这个2*2图像的左上角为前景像素点(1)的概率大
如果计算损失的话,假设label 的左上角是1的话,那么当前像素点的损失为:
L = -(0 * ln 0.2 + 1 * ln 0.8)# label 不参与计算,只是这样解释而已
最后将四个像素点同样计算后,求平均即可
3.1 测试文件
测试需要的文件

分割的label 是整形,因为不需要参与运算,label 的数字只是代表哪一个类别而已
测试的demo

3.2 输出可视化
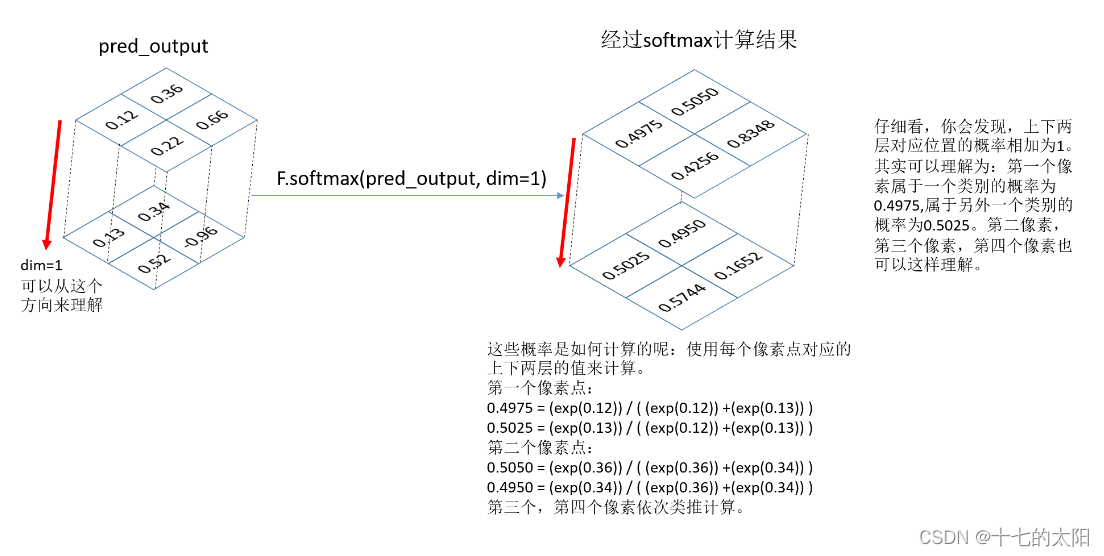
维度的解释:输出的预测是 2 个维度的,2*2 大小的1个batch的图像

图像的label 是:

3.3 softmax
因为 nn.CrossEntropyLoss() 是经过了 softmax 层的,预测值经过softmax后为

可视化
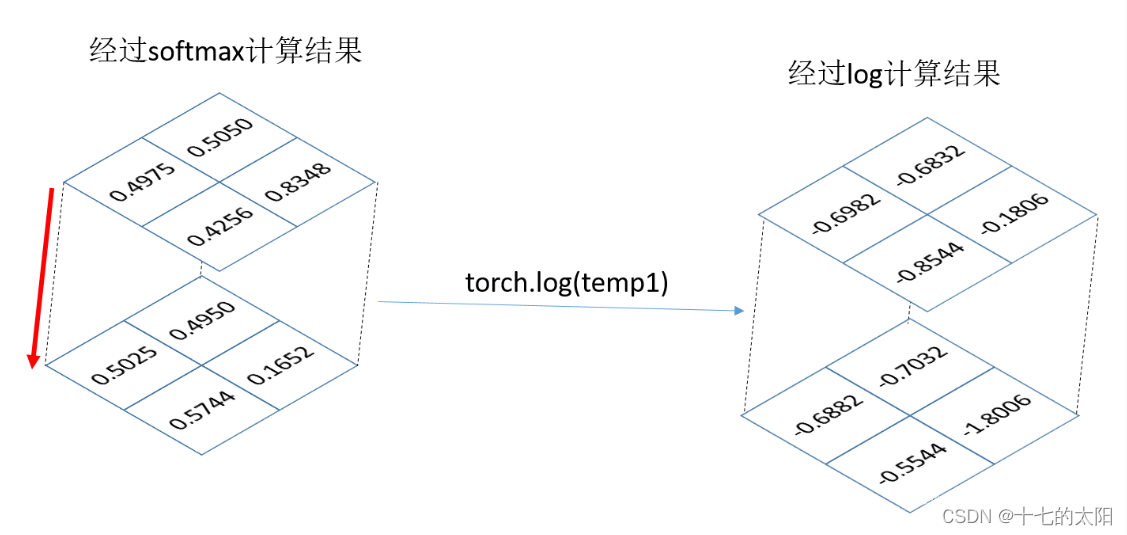
3.4 log
将概率经过log后为
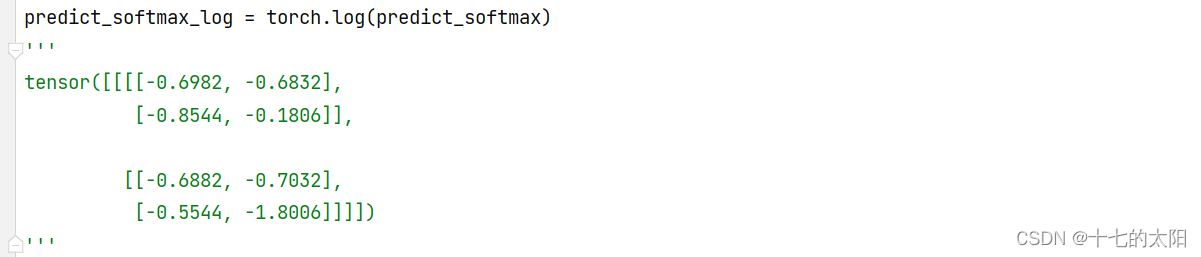
可视化
3.5 CrossEntropyLoss
把每个像素点都认为是一个分类就行了
左上角的预测值有两个 0.4975 和0.5025,左上角的label是1,因此取第二个0.5025
channel = 0channel = 1label预测值左上角0.49750.502510.5025左下角0.42560.574400.4256右上角0.50500.495000.5050右下角0.83480.165210.1652
因此,损失为
L = - (ln 0.5025 + ln 0.4256 + ln 0.5050 + ln 0.1652) / 4 =

用 nn.CrossEntropyLoss() 计算值一样

版权归原作者 听风吹等浪起 所有, 如有侵权,请联系我们删除。