

本文总计 1350 字,预计阅读需要 3-5分钟
在构建数据湖时必须考虑多个方面问题,如数据导入、数据消费、数据治理、数据安全、数据存储等。在本文中,我将尝试介绍其中的一些方面,这些方面可以帮助你确定正确的数据湖构建策略。
下图说明了数据湖中需要聚合的数据类型和我们的数据湖数据集成模式。

在下图中,我们可以看到数据湖中的一些自然带(natural zones),以及我们如何基于它学习和关联我们的数据湖策略。
海岸带(Littoral Zone)是离海最近的地带所以里面包含了各种漂浮的杂质(原木、木棍、树叶、死虫等)。在数据湖中像海岸带一样拥有各种格式的结构化和非结构化的数据,并且这些数据是没有经过清洗包含了很多的杂质(需要清洗)。
光亮带(Euphotic Zone)可以看作是数据湖的清洁区。我们可以通过对数据应用统一的标准/原则来实现数据一致性(经过数据清洗,标准化等操作)。在该区域中所有数据都可以以单一格式存储,例如 Parquet或ORC(因为效率考虑肯定是以列式存储格式进行保存的)。这将有助于建立各种数据质量和数据治理检查,并实现数据的统一消费。
湖的深层区域可以比作归档区,保存以前的现在很少使用的历史归档数据。
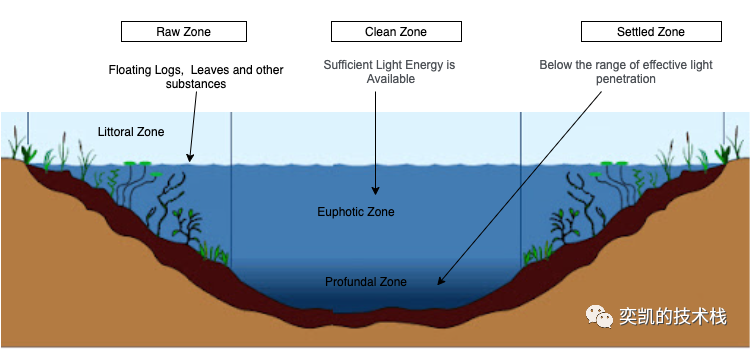
海岸带、光亮带等都是海洋生态的的专业名词,这里为了方便比较概念所以采用海洋生态的名词进行对比。如果我们将上面的海洋生态与数据湖设计策略结合起来并考虑构建数据湖,那么可以尝试以下的3个主要策略。
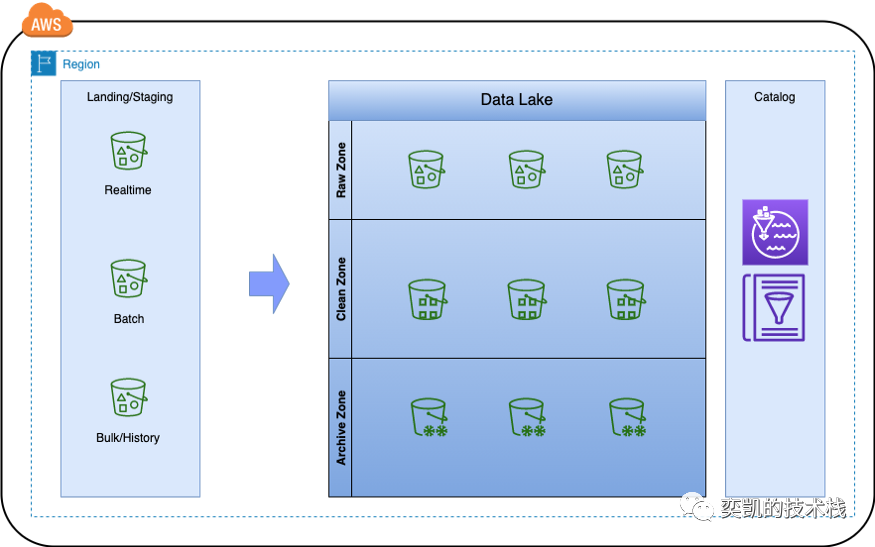
中央湖
从实现的角度来看这是最基本和实现起来最简单的策略。这种策略适用于系统数据较少,用户的使用者也较少的小规模业务。一个完整的数据团队就可以完全实现数据平台,数据处理,数据分析/报表等全流程业务的工作。
联邦湖
具有独立的不同业务线但需要在它们之间共享数据的中大型组织可以采用这种策略。每个业务线都有相应的并且熟悉业务的数据开发来编写不同业务的数据处理逻辑,在数据团队中还需要将数据平台团队独立出来作为上面说的开发团队的支撑,数据平台不负责具体业务代码的编写而是为其他业务线的数据开发提供相应的功能服务。
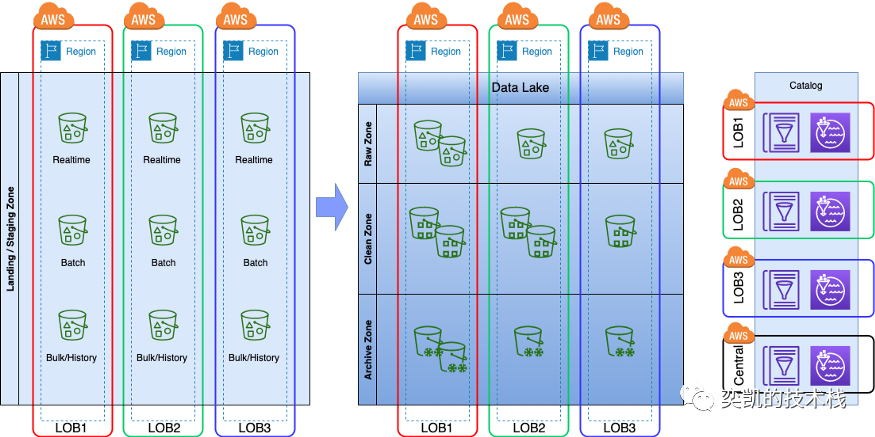
在联邦湖中进行数据治理非常重要,这就需要业务和平台一起合作进行,可以通过拥有一个中央数据目录和实现自动化数据治理来实现。中央数据目录将有助于对由各自的业务线管理的业务中的所有数据进行概述(业务数据开发整理和管理),并使用这些目录实现标准的数据治理检查(平台提供自动化工具或者平台完成数据治理的功能)。
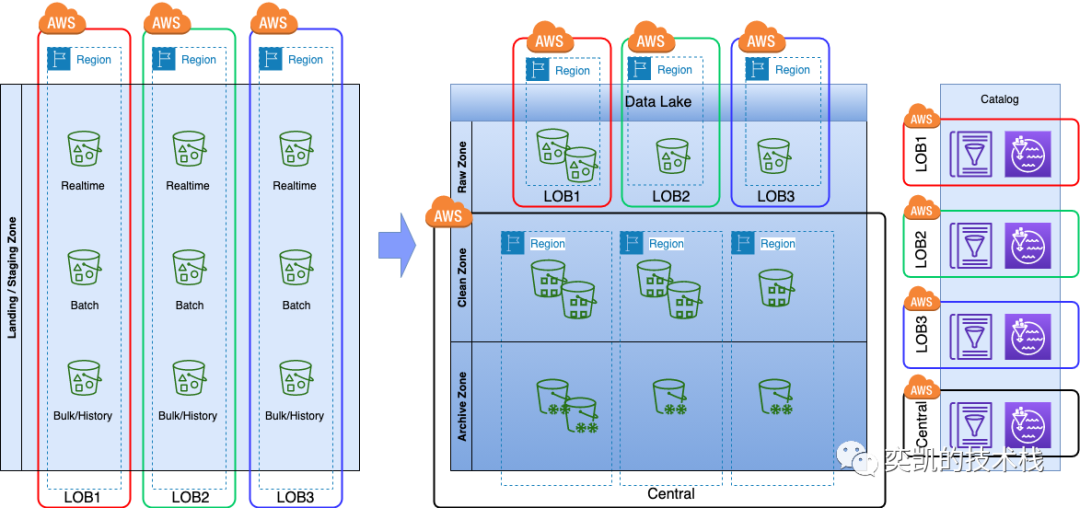
混合湖
这种策略对于具有不同业务单元但相互集成的组织非常有用。数据导入的主要工作是跨业务部门整合(听着是不是有点像数据中台?其实不是)。由一个中央团队负责管理数据湖的清洁和存档区域,并围绕它进行数据的治理。中央团队负责的数据是各业务中需要统一管理和集成并且能够在各业务中共享的数据(主要是为了统一数据的口径)。对于各个业务非共享的数据(或者业务独立的数据),各个业务之间是可以进行自我管理的,这样不仅可以在部分主要业务中统一口径,也不会因为统一管理而影响业务的独立和灵活性。
比较
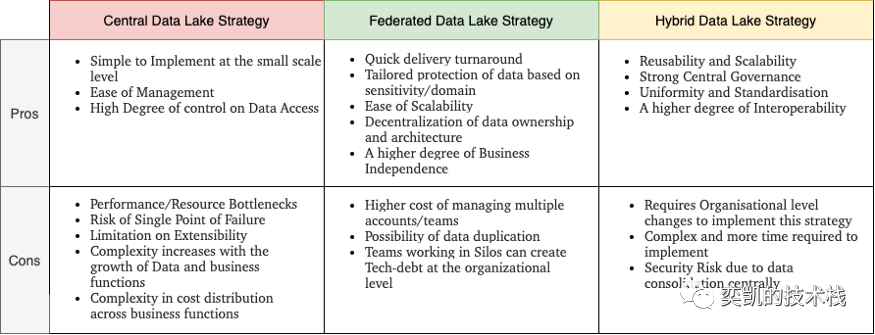
下表总结了 以上三个策略的优缺点。
总结
在选择数据湖策略时还必须考虑的一些关键考虑因素。
- 区域合规和监管要求
- 数据安全要求
- 可弹性扩充
- 业务数据关联性
- 数据消费模式
- 总拥有成本 (TCO) 和使用成本 (TCU)
除此以外,对于数据湖来说最关键部分是自动化的数据治理并且自动化数据治理的实现会根据策略的不同而不同。自动化数据治理必须要和数据湖一起实现,如果未能实现自动化治理将导致技术债务的积累,并为数据湖的可伸缩性带来风险。