

目录
- 一:Kafka 简介
- 二:Kafka 基本架构
- 三:Kafka 基本原理
- 特
- 五:Kafka 的特性
- 六:Kafka 的应用场景
一:Kafka 简介
Apache Kafka 是分布式发布 - 订阅消息系统,在 kafka 官网上对 kafka 的定义:一个分布式发布 - 订阅消息传递系统。
Kafka 最初由 LinkedIn 公司开发,Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。
Kafka 的主要应用场景有:日志收集系统和消息系统。

二:Kafka 基本架构
Kafka 的架构包括以下组件:
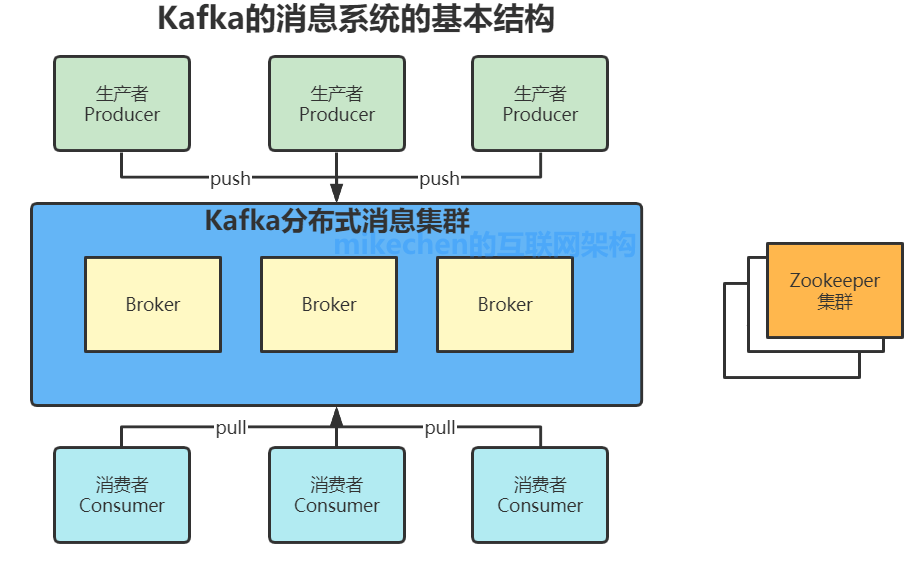
1、话题(Topic):是特定类型的消息流。消息是字节的有效负载(Payload),话题是消息的分类名;
2、生产者(Producer):是能够发布消息到话题的任何对象;
3、服务代理(Broker):已发布的消息保存在一组服务器中,它们被称为代理(Broker)或 Kafka 集群;
4、消费者(Consumer):可以订阅一个或多个话题,并从 Broker 拉数据,从而消费这些已发布的消息;
上图中可以看出,生产者将数据发送到 Broker 代理,Broker 代理有多个话题 topic ,消费者从 Broker 获取数据。
三:Kafka 基本原理
我们将消息的发布(publish)称作 producer,将消息的订阅(subscribe)表述为 consumer,将中间的存储阵列称作 broker (代理),这样就可以大致描绘出这样一个场面:

生产者将数据生产出来,交给 broker 进行存储,消费者需要消费数据了,就从 broker 中去拿出数据来,然后完成一系列对数据的处理操作。
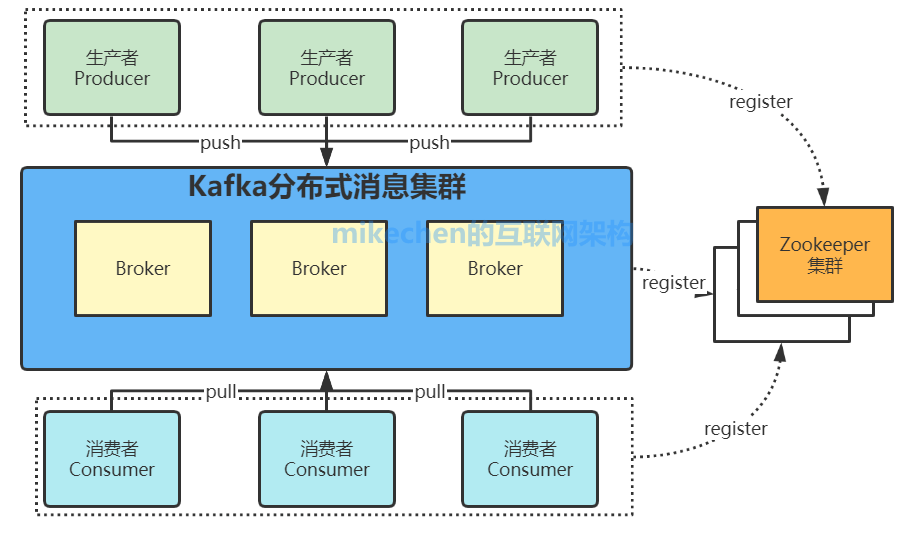
多个 broker 协同合作,producer 和 consumer 部署在各个业务逻辑中被频繁的调用,三者通过 zookeeper 管理协调请求和转发,这样一个高性能的分布式消息发布订阅系统就完成了。
图上有个细节需要注意,producer 到 broker 的过程是 push,也就是有数据就推送到 broker,而 consumer 到 broker 的过程是 pull,是通过 consumer 主动去拉数据的。
四:Zookeeper 在 Kafka 的作用
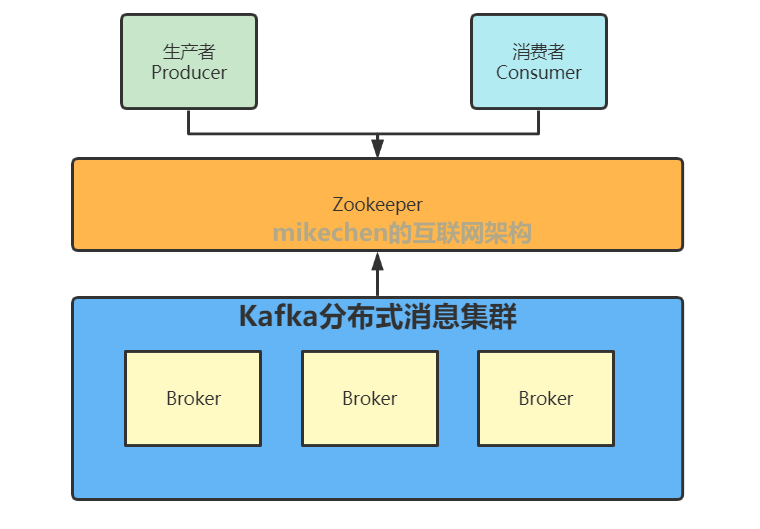
无论是 Kafka 集群,还是 producer 和 consumer ,都依赖于 Zookeeper 来保证系统可用性集群保存一些 meta 信息。
Kafka 使用 Zookeeper 作为其分布式协调框架,可以很好地将消息生产、消息存储、消息消费的过程结合在一起。
Kafka 借助 Zookeeper,让生产者、消费者和 broker 在内的所有组件,在无状态的情况下,建立起生产者和消费者的订阅关系,并实现生产者与消费者的负载均衡。
五:Kafka 的特性
1. 高吞吐量、低延迟
Kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个 topic 可以分多个 partition , consumer group 对 partition 进行 consume 操作。
2. 可扩展性
Kafka 集群支持热扩展。
3. 持久性、可靠性
消息被持久化到本地磁盘,并且支持数据备份防止数据丢失。
4. 容错性
允许集群中节点失败(若副本数量为 n, 则允许 n-1 个节点失败)
5. 高并发
支持数千个客户端同时读写。
六:Kafka 的应用场景
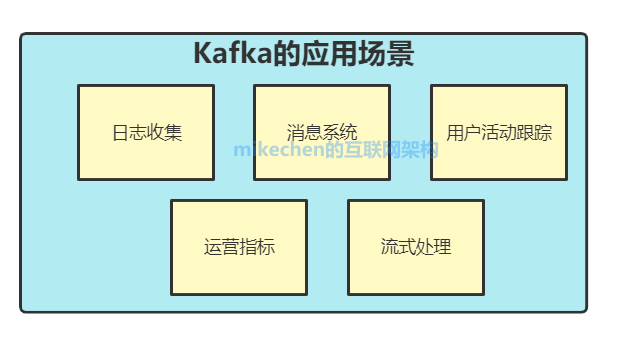
1. 日志收集
一个公司可以用 Kafka 收集各种服务的 log ,通过 Kafka 以统一接口服务的方式开放给各种 consumer,例如:hadoop、Hbase、Solr 等。
2. 消息系统
解耦和生产者和消费者、缓存消息等。
3. 用户活动跟踪
Kafka 经常被用来记录 web 用户、或者 app 用户的各种活动,例如:浏览网页、搜索、点击等活动。
这些活动信息,被各个服务器发布到 Kafka 的 topic 中,订阅者再通过订阅这些 topic 来做实时的监控分析,或者装载到 hadoop 、数据仓库中做离线分析和挖掘。
4. 运营指标
Kafka 也经常用来记录运营监控数据。
包括收集各种分布式应用的数据,生产各种操作的集中反馈等,例如:报警和报告。
5. 流式处理
例如:spark streaming、storm 。
以上!
作者简介
陈睿 | mikechen , 10 年 + 大厂架构经验,「mikechen 的互联网架构」系列文章作者,专注于互联网架构技术。
阅读「mikechen 的互联网架构」40W 字技术文章合集
Java 并发 | JVM | MySQL | Spring | Redis | 分布式 | 高并发
版权归原作者 mikechen的互联网架构 所有, 如有侵权,请联系我们删除。