
Python中文分词及词频统计
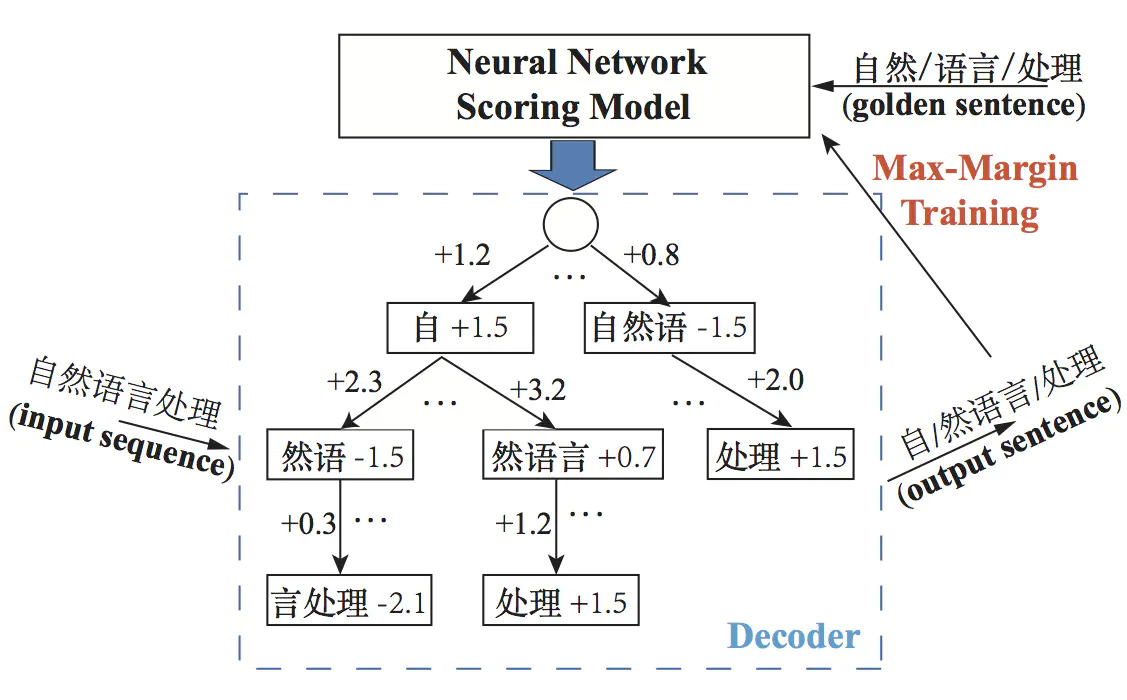
中文分词
中文分词(Chinese Word Segmentation),将中文语句切割成单独的词组。英文使用空格来分开每个单词的,而中文单独一个汉字跟词有时候完全不是同个含义,因此,中文分词相比英文分词难度高很多。
分词主要用于NLP 自然语言处理(Natural Language Processing),使用场景有:
搜索优化,关键词提取(百度指数)语义分析,智能问答系统(客服系统)非结构化文本媒体内容,如社交信息(微博热榜)文本聚类,根据内容生成分类(行业分类)
分词库
Python的中文分词库有很多,常见的有:
- jieba(结巴分词)
- THULAC(清华大学自然语言处理与社会人文计算实验室)
- pkuseg(北京大学语言计算与机器学习研究组)
- SnowNLP
- pynlpir
- CoreNLP
- pyltp
通常前三个是比较经常见到的,主要在易用性/准确率/性能都还不错。我个人常用的一直都是结巴分词(比较早接触),最近使用pkuseg,两者的使用后面详细讲。
结巴分词
简介
- “结巴”中文分词:做最好的 Python 中文分词组件
- 支持三种分词模式:- 精确模式,试图将句子最精确地切开,适合文本分析;- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- 支持繁体分词
- 支持自定义词典
实例
我们使用京东商场的美的电器评论来看看结巴分词的效果。如果你没有安装结巴分词库则需要在命令行下输入pip install jieba,安装完之后即可开始分词之旅。
评论数据整理在文件meidi_jd.csv文件中,读取数据前先导入相关库。因为中文的文本或文件的编码方式不同编码选择gb18030,有时候是utf-8、gb2312、gbk自行测试。
# 导入相关库
import pandas as pd
import jieba
# 读取数据
data = pd.read_csv('meidi_jd.csv', encoding='gb18030')
# 查看数据
data.head()

# 生成分词
data['cut'] = data['comment'].apply(lambda x : list(jieba.cut(x)))
data.head()
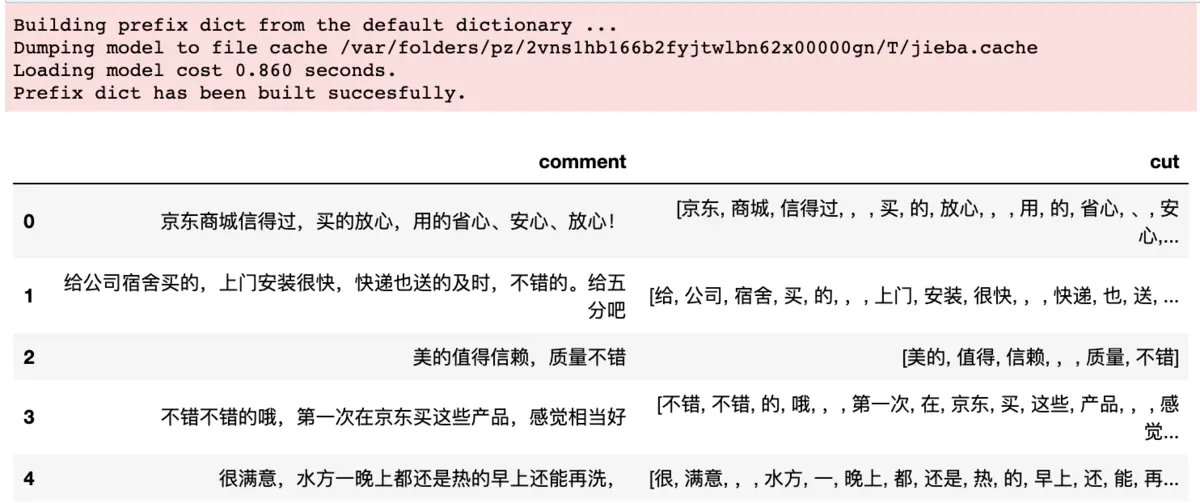
到这里我们仅仅通过一行代码即可生成中文的分词列表,如果你想要生成分词后去重可以改成这样。
data['cut'] = data['comment'].apply(lambda x : list(set(jieba.cut(x))))
['很', '好', '很', '好', '很', '好', '很', '好', '很', '好', '很', '好', '很', '好', '很', '好', '很', '好', '很', '好', '很', '好']
这时候我们就需要导入自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率。自定义词典采用一词一行,为了演示我添加了“很好”并保存在dict.txt文件中,让我们开始用自定义的词典吧!
data['cut'] = data['comment'].apply(lambda x : list(jieba.cut(x)))
data.head()
print(data['cut'].loc[14])
['很好', '很好', '很好', '很好', '很好', '很好', '很好', '很好', '很好', '很好', '很好']
停用词
分词的过程中我们会发现实际上有些词实际上意义不大,比如:标点符号、嗯、啊等词,这个时候我们需要将停用词去除掉。首先我们需要有个停用词词组,可以自定义也可以从网上下载词库,这里我们使用网上下载的停用词文件StopwordsCN.txt。
# 读取停用词数据
stopwords = pd.read_csv('StopwordsCN.txt', encoding='utf8', names=['stopword'], index_col=False)
stopwords.head()
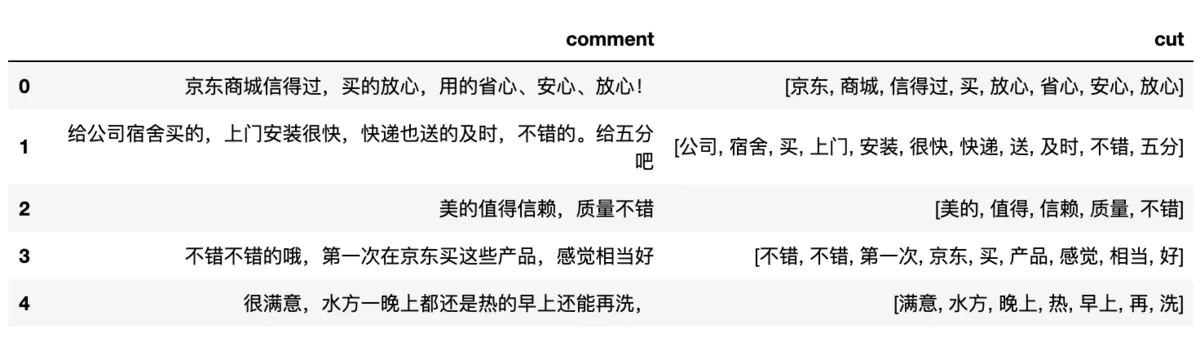
接下里我们只要适当更改分词的代码即可在分词的时候去掉停用词:
# 转化词列表
stop_list = stopwords['stopword'].tolist()
# 去除停用词
data['cut'] = data['comment'].apply(lambda x : [i for i in jieba.cut(x) if i not in stop_list])
data.head()
词频统计
到这里我们基本是已经学会用Python库进行分词,关于词频统计的方式也很多,我们先将所有分词合并在一起方便统计。
# 将所有的分词合并
words = []
for content in data['cut']:
words.extend(content)
方式一:
# 创建分词数据框
corpus = pd.DataFrame(words, columns=['word'])
corpus['cnt'] = 1
# 分组统计
g = corpus.groupby(['word']).agg({'cnt': 'count'}).sort_values('cnt', ascending=False)
g.head(10)
方式二:
# 导入相关库
from collections import Counter
from pprint import pprint
counter = Counter(words)
# 打印前十高频词
pprint(counter.most_common(10))
[('不错', 3913),
('安装', 3055),
('好', 2045),
('很好', 1824),
('买', 1634),
('热水器', 1182),
('挺', 1051),
('师傅', 923),
('美', 894),
('送货', 821)]
结尾
我个人的使用建议,如果想简单快速上手分词可以使用结巴分词,但如果追求准确度和特定领域分词可以选择pkuseg加载模型再分词。另外jieba和THULAC并没有提供细分领域预训练模型,如果想使用自定义模型分词需使用它们提供的训练接口在细分领域的数据集上进行训练,用训练得到的模型进行中文分词。
代码练习
import jieba
import jieba.analyse
import codecs
import re
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import wordcloud
str = "我在河南大学上学,今年22岁了"
seg_list = jieba.cut(str,cut_all=True)
print("全模式:"+"/".join(seg_list))
seg_list = jieba.cut(str,cut_all=False)
print("默认(精确模式):"+"/".join(seg_list))
# 搜索引擎模式
seg_list = jieba.cut_for_search(str)
print("搜索引擎模式:"+"/".join(seg_list))
# 添加用户自定义词典
str = "大连圣亚在大连"
seg_list = jieba.cut(str,cut_all=False)
print("默认(精确模式):"+"/".join(seg_list))
# 添加自定义词典后
jieba.load_userdict(r"./user_dict.txt")
seg_list = jieba.cut(str,cut_all=False)
print("默认(精确模式):"+"/".join(seg_list))
str = "我家在河南省驻马店市汝南县东官庄镇"
seg_list = jieba.cut(str) #默认是精确模式
print("精确模式:"+"/".join(seg_list))
# 动态调整词典
jieba.add_word("东官庄镇")
seg_list = jieba.cut(str)
print("精确模式:"+"/".join(seg_list))
# 加载停用词
# 创建停用词列表
def stopwordlist():
stopwords = [line.strip() for line in open('./hit_stopwords.txt',encoding='UTF-8').readlines()]
return stopwords
# 对句子进行中文分词
def seg_depart(sentence):
print('正在分词')
sentence_depart = jieba.cut(sentence.strip())
# 创建一个停用词列表
stopwords = stopwordlist()
# 输出结果为 outstr
outstr = ''
# 去停用词
for word in sentence_depart:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
return outstr
# 给出文档路径
filename = "./text.txt"
outfilename = "./out.txt"
inputs = open(filename,'r',encoding='UTF-8')
outputs = open(outfilename,'w',encoding='UTF-8')
jieba.add_word("停用词")
# 将输出结果写到out.txt中
for line in inputs:
line_seg = seg_depart(line)
outputs.write(line_seg + '\n')
print("-------------------------正在分词和去停用词--------------------------")
print("原文:"+line)
print("去停用词:"+line_seg)
outputs.close()
inputs.close()
print("删除停用词和分词成功!!!")
# class WordCounter(object):
def count_from_file(file,top_limit=0):
with codecs.open(file,'r','UTF-8') as f:
content = f.read()
# 将多个空格替换为一个空格
content =re.sub(r'\s+',r' ',content)
content = re.sub(r'\.+',r' ',content)
# 去停用词
content = seg_depart(content)
return count_from_str(content,top_limit=top_limit)
def count_from_str(content,top_limit=0):
if top_limit <= 0:
top_limit = 100
# 提取文章的关键词
tags = jieba.analyse.extract_tags(content,topK=100)
words = jieba.cut(content)
counter = Counter()
for word in words:
if word in tags:
counter[word] += 1
return counter.most_common(top_limit)
# if __name__ == '__main__':
# counter = WordCounter()
# retult = counter.count_from_file(r'./text.txt',top_limit=10)
# print(retult)
print("打印词频==============")
retult = count_from_file(r'./text.txt',top_limit=10)
print(retult)
print("*"*100)
# 例子
# sentence = 'Ilikeyou '
# wc = wordcloud.WordCloud()
# pic = wc.generate(sentence)
# plt.imshow(pic)
# plt.axis("off")
# plt.show()
# wc.to_file('test.png')
print("分词并生成词云图")
def create_word_cloud(file):
content = codecs.open(file,'r','UTF-8').read()
# 结巴分词
wordlist = jieba.cut(content)
wl = " ".join(wordlist)
print(wl)
# 设置词云图
wc = wordcloud.WordCloud(
# 设置背景颜色
background_color='pink',
# 设置最大显示的词数
max_words=100,
# 设置字体路径
font_path = 'C:\Windows\Fonts\msyh.ttc',
height = 1200,
width=1600,
# 设置字体最大值
max_font_size=300,
# 设置有多少种配色方案,即多少种随机生成状态
random_state=30,
)
# 生成词云图
myword = wc.generate(wl)
# 展示词云图
plt.imshow(myword)
plt.axis("off")
plt.show()
wc.to_file('py_pic.png')
# content = codecs.open("./text.txt",'r','UTF-8').read()
create_word_cloud("text.txt")
版权归原作者 lishuaics 所有, 如有侵权,请联系我们删除。