
基本概念
通过深度学习进行视频处理是一个非常复杂的领域,因为它需要处理空间和时间两个方面。为了总结现代比较流行的方法是什么,在这篇文章中我们将对视频回归任务的深度学习方法进行一些研究。
处理视频意味着处理图像,所以这里需要cnn。但是,有不同的方法来处理时态组件。我试着概括出主要的几点:
现有的方法
1、只使用CNN的回归
斯坦福大学的一篇非常有趣的论文(http://vision.stanford.edu/pdf/karpathy14.pdf)讨论了视频分类任务中可能遇到的挑战,并提供了处理这些挑战的方法(这些方法也可以应用于有轻微变化的回归问题)。简而言之,作者尝试了各种CNNs架构来跨时间组件融合信息,并学习时空特征。

2、3d CNN
这种方法背后的逻辑非常直观,因为卷积中的第三维可以对应于时间域,从而可以直接从一个网络学习时空特征。
3、长期循环卷积网络(LRCN)
2016年,一组作者提出了用于视觉识别和描述的端到端可训练类架构。其主要思想是使用CNNs从视频帧学习视觉特征,使用LSTMs将图像嵌入序列转换为类标签、句子、概率或任何您需要的东西。因此,我们用CNN对原始的视觉输入进行处理,CNN的输出被输入到一堆递归序列模型中。
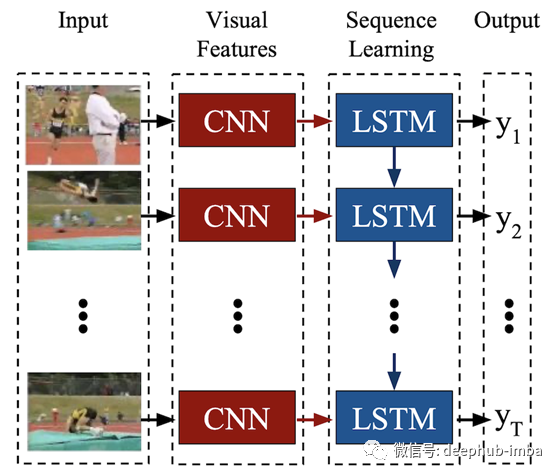
在我看来,LRCN架构在实现方面似乎比其他架构更有吸引力,因为您必须同时练习卷积和循环网络。
我是个电影迷,已经看了大约一千部电影。基于此,我决定对电影预告片进行深度学习,预测预告片的收视率。不幸的是,收集训练数据集非常困难,因为除了下载视频之外,我还需要对它们进行标记。为了扩展数据集,我们可以应用一些数据增强,对于视频可以旋转,添加不同种类的噪声,改变速度等。然而,最初的相机角度、图像质量和电影速度都是未来评级的一部分,所以保留分数而改变这些特征似乎是错误的。我决定从一个视频中取几个不重叠的部分然后将每个部分分割成帧最终得到n个训练样本
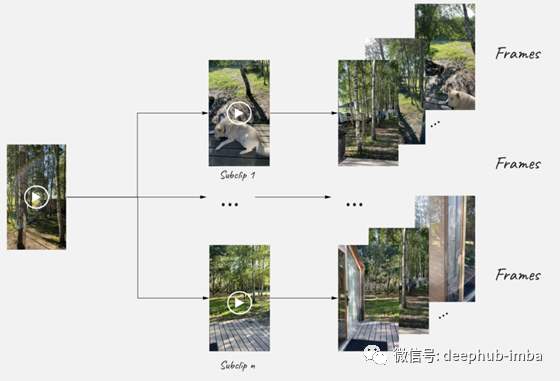
def preprocess(movie_name, train=True, n_subclips=3, subclip_duration=30, frequency=45, verbose=False):
"""
Preprocesses a movie trailer making subclips and then extracting sequences of frames
:param movie_name: movie name
:train: boolean flag to determine whether preprocessing is performed for training videos or not
:param n_subclips: number of subclips to make from the trailer
:param subclip_duration: duration of a subclip
:param frequency: frequency of extracting frames from subclips
:param verbose: increase verbosity if True
"""
name = '.'.join(movie_name.split('.')[:-1])
format_ = movie_name.split('.')[-1]
if not format_ok(format_):
print('Skipping file, which is not a video...')
return
if train == True:
if not os.path.isdir(TRAINING_PATH):
os.mkdir(TRAINING_PATH)
DEST = TRAINING_PATH
else:
if not os.path.isdir(PREDICTION_PATH):
os.mkdir(PREDICTION_PATH)
DEST = PREDICTION_PATH
if format_ == 'flv': #Decord does not work with flv format
format_ = 'mov'
#Extracting subclip from trailer
base = 10
os.makedirs(f"{FPATH}/{name}", exist_ok=True)
for i in range(n_subclips):
if verbose:
print(f"{i} iteration...")
print("....Making subclip....")
try:
ffmpeg_extract_subclip(f"{FPATH}/{movie_name}", base, base+subclip_duration, targetname=f"{FPATH}/{name}/{i}.{format_}")
base = base + subclip_duration
except BaseException:
print(f"Some error occured during {i+1} extraction")
continue
#Check if all subclips were correctly created
try:
video = moviepy.editor.VideoFileClip(f"{FPATH}/{name}/{i}.{format_}")
if int(video.duration) <= subclip_duration//2:
raise DurationError
except:
print(f"The {i} subclip was not correctly created, deleting...")
os.remove(f"{FPATH}/{name}/{i}.{format_}")
continue
#Creating frames
if verbose:
print("....Extracting frames....")
os.makedirs(f"{DEST}/{name+'_'+str(i)}", exist_ok=True) #Creating directory for Train dataset
try:
video_to_frames(f"{FPATH}/{name}/{i}.{format_}", f"{DEST}/{name+'_'+str(i)}", overwrite=False, every=frequency)
except:
print("Error occured while executing VIDEO_TO_FRAMES")
os.rmdir(f"{DEST}/{name+'_'+str(i)}/{i}")
os.rmdir(f"{DEST}/{name+'_'+str(i)}")
continue
#Delete directory with subclips
if name in os.listdir(f"{FPATH}"):
shutil.rmtree(f"{FPATH}/{name}")
现在我们可以开始构建网络架构并训练模型。原论文中的CNN base是对CaffeNet的修改,但为了简单和更快的训练,我只创建了两个卷积层(batch normalization) dropout和max pooling作为编码器,两个稠密层作为解码器。虽然该技术通过平均LSTM输出用于视觉识别,但我们只要将结果使用softmax函数去掉就可以使用相同的方法进行视频回归,。
class CNN(torch.nn.Module):
def __init__(self, channels1=10, channels2=20, embedding_size=15, activation='relu'):
super(CNN, self).__init__()
self.layer1 = torch.nn.Sequential(torch.nn.Conv2d(3, channels1, kernel_size=5, padding=2),
activation_func(activation), torch.nn.BatchNorm2d(num_features=channels1),
torch.nn.MaxPool2d(2, 2))
self.layer2 = torch.nn.Sequential(torch.nn.Conv2d(channels1, channels2, kernel_size=3, padding=1),
torch.nn.Dropout2d(p=0.2), activation_func(activation),
torch.nn.BatchNorm2d(num_features=channels2), torch.nn.MaxPool2d(2, 2))
self.encoder = torch.nn.Sequential(self.layer1, self.layer2)
self.decoder = torch.nn.Sequential(torch.nn.Linear(56*56*channels2, 6000), activation_func(activation),
torch.nn.Linear(6000, 500), activation_func(activation), torch.nn.Linear(500, embedding_size))
def forward(self, x):
x = self.encoder(x)
#flatten heatmap before utilizing dense layers
x = x.view(x.size(0), x.size(1) * x.size(2) * x.size(3))
out = self.decoder(x)
return out
class LRCN(torch.nn.Module):
def __init__(self, channels1=10, channels2=20, embedding_size=15, LSTM_size=64, LSTM_layers=1, activation='relu'):
super(LRCN, self).__init__()
self.cnn = CNN(channels1, channels2, embedding_size, activation)
#batch first: data formatted in (batch, seq, feature)
self.rnn = torch.nn.LSTM(input_size=embedding_size, hidden_size=LSTM_size, num_layers=LSTM_layers, batch_first=True)
self.linear = torch.nn.Linear(LSTM_size, 1)
def forward(self, x):
heatmaps = []
for seq in x:
heatmaps.append(self.cnn.forward(seq))
heatmaps = torch.stack(heatmaps)
out, (_, _) = self.rnn(heatmaps)
out = self.linear(out)
return out[:,-1,:]
一旦我们准备好了数据和模型,就该开始训练了。我选择的默认参数不会导致高质量但快速的训练。
def fit(self, dir_names, X_test, y_test, lr=3e-4, loss_name='mse', n_epoch=5, batch_size=10, device='cpu', saving_results=False, use_tensorb=False, verbose=False):
optimizer = torch.optim.Adam(self.parameters(), lr=lr)
loss = loss_choice(loss_name) #Specifying loss function
dir_names = list(filter(lambda x: os.path.isdir(f"{TRAINING_PATH}/{x}"), dir_names)) #Filtering waste files
random.shuffle(dir_names)
train_loss_history = []
test_loss_history = []
learning_dir_names = dir_names.copy()
#Training model
print('---------------TRAINING----------------')
for epoch in range(n_epoch):
dir_names = learning_dir_names.copy()
train_loss = 0
for i in range(0, len(learning_dir_names), batch_size):
optimizer.zero_grad()
print(dir_names)
X_batch, y_batch, dir_names = load_data(dir_names, train=True, verbose=verbose, batch_size=batch_size)
X_batch = X_batch.to(device).float()
y_batch = y_batch.to(device).float()
preds = self.forward(X_batch).view(y_batch.size()[0])
loss_value = loss(preds, y_batch)
loss_value.backward()
train_loss += loss_value.data.cpu()
optimizer.step()
train_loss_history.append(train_loss)
with torch.no_grad():
test_preds = self.forward(X_test).view(y_test.size()[0])
test_loss_history.append(loss(test_preds, y_test).data.cpu())
print(f"{epoch+1}: {loss_name} = {test_loss_history[-1]}")
if saving_results==True:
torch.save(self.state_dict(), MODEL_WEIGHTS)
print('---------------------------------------')
return [train_loss_history, test_loss_history]
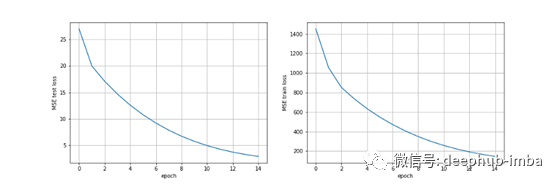
即使训练一个简单的端到端LRCN模型也需要大量的计算能力和时间,因为我们的任务包括图像和序列。此外,训练数据集必须相当大,z这样模型可以很好地推广。从下图可以看出,经过训练后的模型存在明显的拟合不足。
总结
LRCN是一种用于处理视觉和时间输入的模型,它提供了很大的灵活性,可应用于计算机视觉的各种任务,并可合并到CV处理管道中。然后这种方法可用于各种时变视觉输入或序列输出的问题。LRCN提供了一个易于实现和训练的端到端模型体系结构。
本文代码:https://github.com/DJAlexJ/LRCN-for-Video-Regression
作者:Alexander Golubev
deephub翻译组