

❤️ 博客主页:水滴技术
🚀 支持水滴:点赞👍 + 收藏⭐ + 留言💬
🌸 订阅专栏:大数据核心技术从入门到精通
文章目录
大家好,我是水滴~~
IK 中文分词器是 Elasticsearch 的一个插件,它集成了 Lucene IK analyzer,支持自定义字典。
一、安装 IK 分词器
安装 IK 分词器有两种方式,我们来看一下
方式一:自行下载并解压安装包
- 打开 IK 分词器的下载页: https://github.com/medcl/elasticsearch-analysis-ik/releases
- 选择与 Elasticsearch 相同的版本进行下载,我选择的是
v7.12.1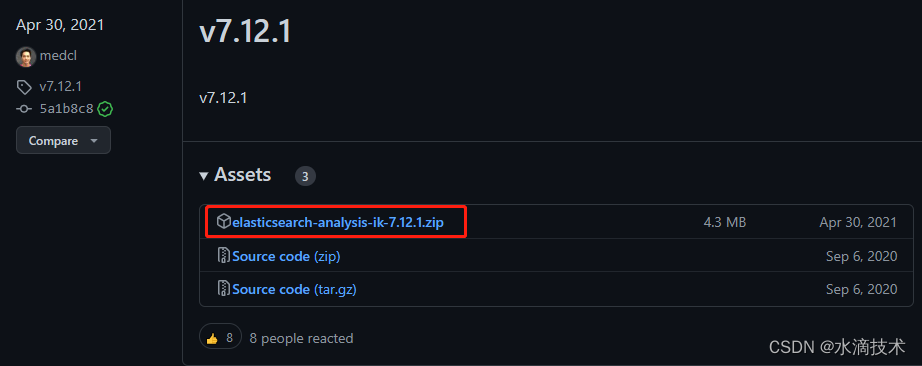
- 在你的 Elasticsearch 的安装目录中,找到
plugins文件,在里面创建一个elasticsearch-analysis-ik-7.12.1文件夹,并将下载的安装包解压到该文件夹中。 - 最后需要重启 Ealsticsearch 服务后,IK 分词器才能生效。
方式二:通过 elasticsearch-plugin 安装
- 同样打开 IK 分词器的下载页: https://github.com/medcl/elasticsearch-analysis-ik/releases
- 找到与 Elasticsearch 相同的版本,我选择的是
v7.12.1,复制下载地址。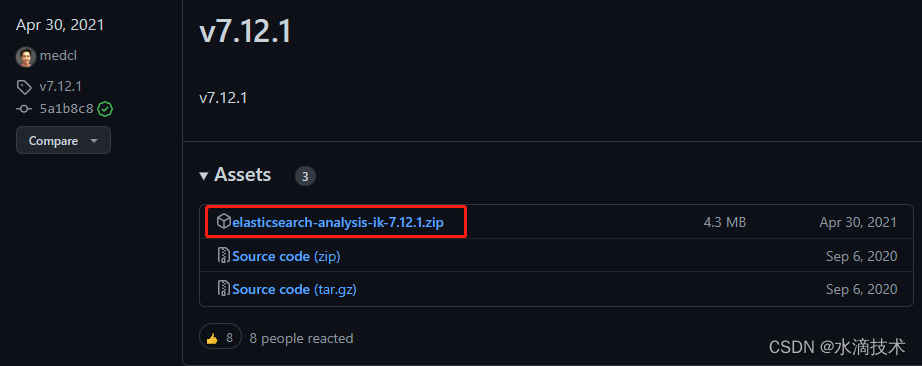
- 进入 Elasticsearch 安装目录,执行安装命令:
.\bin\elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip - 安装完后,别忘了重启 Elasticsearch 服务。
二、使用 IK 分词器
IK 分词器为我们提供了两种分析器:
ik_smart
和
ik_max_word
,我们分别来使用一下:
ik_max_word
ik_max_word
会将文本做最细粒度的拆分,它会穷尽各种可能的组合,适合 Term Query。
测试分词器:
POST/_analyze
{"analyzer":"ik_max_word","text":"中华人民共和国国歌"}
分词结果:
[ 中华人民共和国, 中华人民, 中华, 华人, 人民共和国, 人民, 共和国, 共和, 国, 国歌 ]
ik_smart
ik_smart
会做最粗粒度的拆分,适合 Phrase Query。
测试分词器:
POST/_analyze
{"analyzer":"ik_smart","text":"中华人民共和国国歌"}
分词结果:
[ 中华人民共和国, 国歌 ]
三、自定义字典(分词)
IK 分词器提供了一些扩展配置,可以使我们自定义一些字典。打开 IK分词器插件目录,进入
config目录,其中
IKAnalyzer.cfg.xml为 IK 分词器的扩展配置,而扩展名为
.dic的文件为分词或停止词的词典文件。
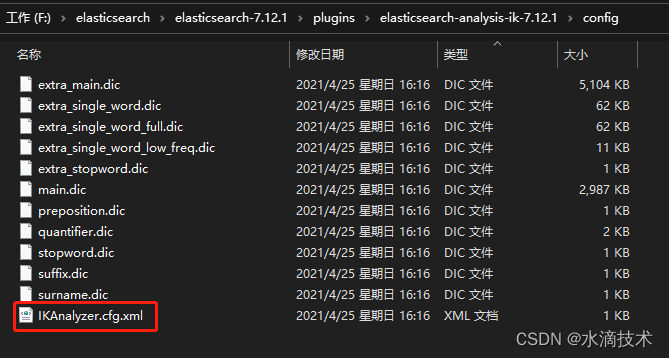
本地字典
我们可以添加一个自己的字典文件,例如:
mydict.dic
,该文件要求必须是 UTF-8 格式,每一行为一个分词,例如:
锐龙
酷睿
然后在
IKAnalyzer.cfg.xml
配置文件中,将自定义的字典文件名添加到
ext_dict
配置中,如果有多个文件,中间使用
;
隔开:
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPEpropertiesSYSTEM"http://java.sun.com/dtd/properties.dtd"><properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entrykey="ext_dict">mydict.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entrykey="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> --></properties>
配置完后,需要重启 Elasticsearch 服务才能生效。
我做了一个测试,在配置自定义分词前,这句话“联想(Lenovo)小新Pro16 笔记本2023锐龙版”中的“锐龙”会被分隔开。
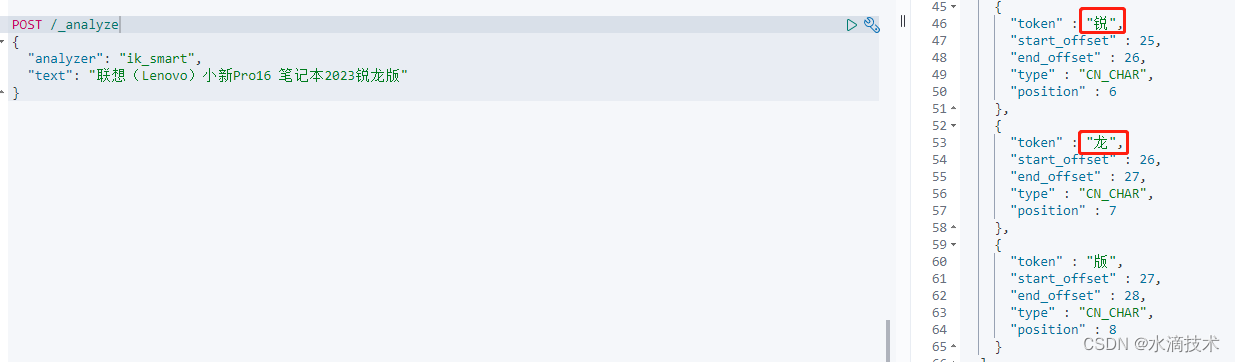
加上自定义的字典后,可以看出这两个字是一个词了。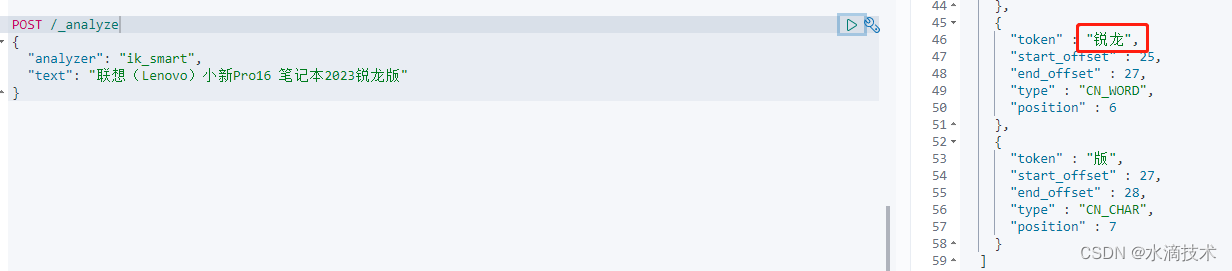
远程字典
从
IKAnalyzer.cfg.xml
配置文件的注释中也可以看出,我们还可以配置远程扩展字典,即在
remote_ext_dict
配置项中添加一个请求的地址,比如
http://127.0.0.1/getCustomDict
,该请求的响应内容格式必须是一行一个分词,换行符使用
\n
。
如果想要实现热更新 IK 分词的话,该请求需要返回两个头部(header):一个是
Last-Modified
,另一个是
ETag
。这两个都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。这样就可以在不重启 Elasticsearch 服务的情况下,完成词典的更新。
可以将需自动更新的热词放在一个 UTF-8 编码的 .txt 文件里,放在 nginx 或其他简易 http server 下,当 .txt 文件修改时,http server 会在客户端请求该文件时自动返回相应的 Last-Modified 和 ETag。可以另外做一个工具来从业务系统提取相关词汇,并更新这个 .txt 文件。
四、系列文章
🔥 Elasticsearch 核心技术(一):Elasticsearch 安装、配置、运行(Windows 版)
🔥 Elasticsearch 核心技术(二):elasticsearch-head 插件安装和使用
🔥 Elasticsearch 核心技术(三):Kibana 安装、配置、运行(Windows 版)
🔥 Elasticsearch 核心技术(四):索引管理、映射管理、文档管理(REST API)
🔥 Elasticsearch 核心技术(五):常用数据类型详解
🔥 Elasticsearch 核心技术(六):内置的 8 种分词器详解 + 代码示例
五、热门专栏
👍 《Python入门核心技术》
👍 《IDEA 教程:从入门到精通》
👍 《Java 教程:从入门到精通》
👍 《MySQL 教程:从入门到精通》
👍 《大数据核心技术从入门到精通》

版权归原作者 水滴技术 所有, 如有侵权,请联系我们删除。