
事件抽取(Event Extraction, EE)是NLP领域中一种经典的信息抽取任务,在商业、军事等领域的情报工作中应用非常广泛。本文简单介绍了事件抽取任务和事件之间的几种关系。并根据现在的研究介绍了几种事件抽取和关系抽取的方法。最后简单盘点了事件抽取的研究的发展趋势。
事件抽取
事件抽取 : 被定义为从文本中提取出对人类有用的信息事件, 并以结构化的形式表示出来。
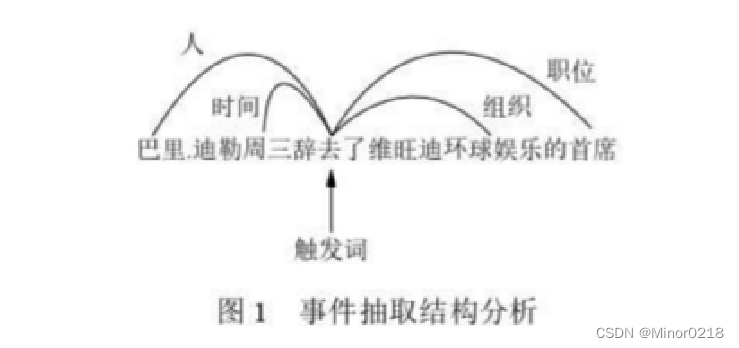
事件抽取主要的任务: 包括从文本中发现触发词和从文本中识别出元素扮演的角色。
例如:从“巴里·迪勒周三辞去了维旺迪环球娱乐的首席”文本中抽取出
事件{类型: 辞职, 人物: 巴里·迪勒, 组织: 维旺迪环球娱乐, 职位: 首席,时间:星期三}

事件关系抽取
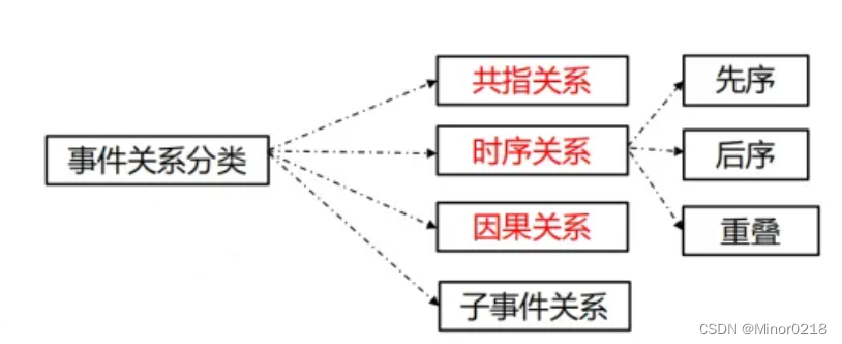
事件关系抽取目的是从一段文本中抽取出事件的关系,存储到知识数据库中。事件之间的关系主要关注三种关系类型:共指、时序、因果子。事件关系指的是:事件间的包含关系,比如第二次世界大战包含了偷袭珍珠港、斯大林格勒大会战等。
** 共指关系:指代表同一目标事件。通常情况下,共指关系需要被消解**。如下图
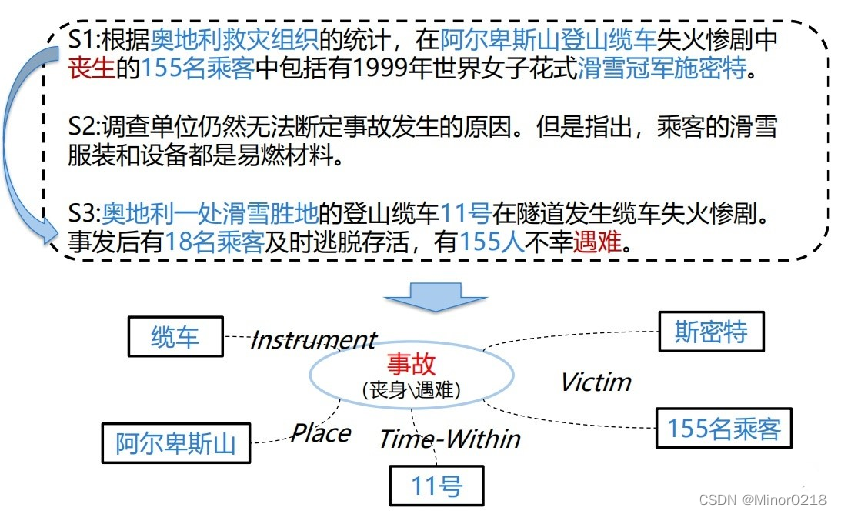
S1和S3描述的是同一目标事件。从这个事件中可以抽取出事件{类型:事故,受害人:斯密特、155名乘客,地点:阿尔卑斯山,时间:11号,器械:缆车}
时序关系:事件在时间上的先后顺序,有助于事件的发现和推理。如下图
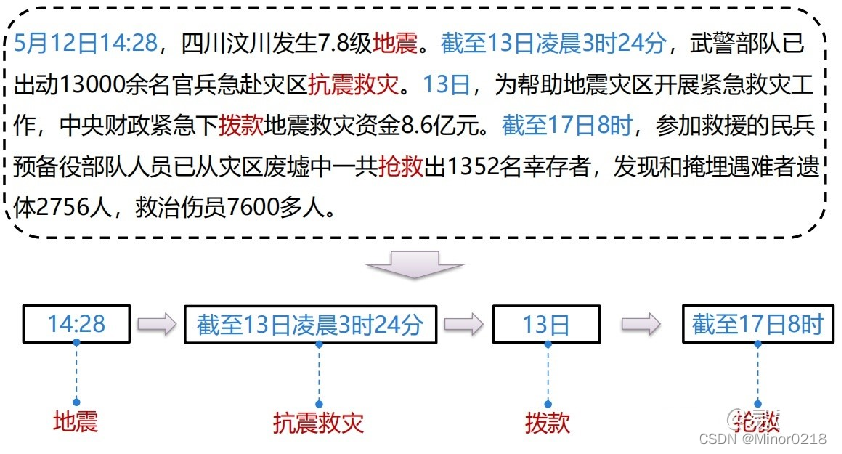
根据上述事件的先后时间关系,可以抽取出一条事件链
因果关系:指事件之间的作用关系,即某个事件是另一事件的结果。如下图
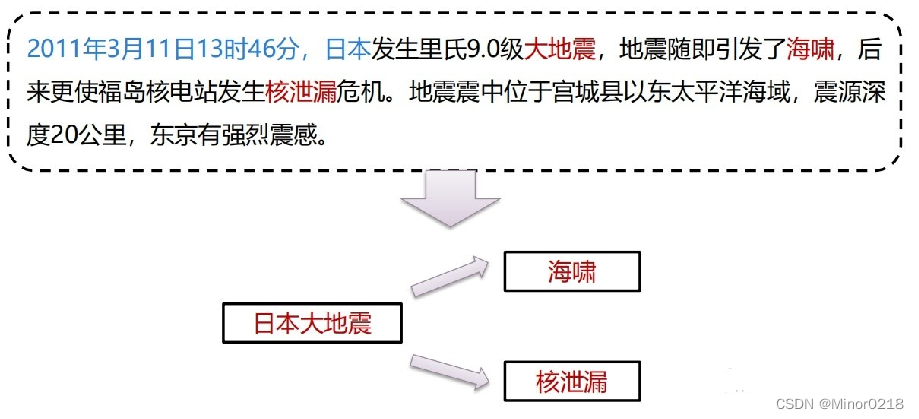
根据上述事件,可以抽取出一条因果关系事件链,由日本大地震引发了海啸和核泄漏
事件抽取方法
基于模式匹配的事件抽取
基于模式匹配的事件抽取方法一般需要领域专家人工构建规则与模板,这些规则与模板通常会以词典、正则、语法树等形式进行匹配。
这类基于模式匹配的方法通常包含构建与抽取两个步骤,即
- 事先在语料上发掘出规则
- 将规则应用到新的待抽取文本上进行匹配
如下图,是基于模式匹配的事件抽取的流程
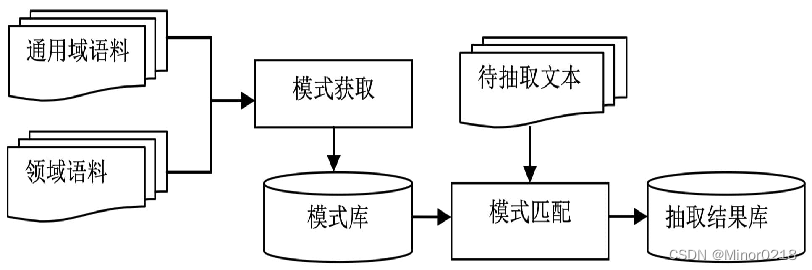
基于机器学习的事件抽取
由于基于模式匹配的方法通常需要大量人力资源,且效果不佳,特别是在迁移到新的领域数据上时需要重新挖掘模式,因此基于统计机器学习的方法在 20 世纪后逐渐替代了传统的模式匹配方法。
如下图,是基于机器学习的事件抽取流程

事件装配(Event Assembling)一般是对分类结果的后处理,如事件合并、聚类等。比较典型的统计机器学习方法包括最大熵模型、支持向量机、条件随机场等,一般来说此类工作的特点是作者会精心根据数据集和模型选择特征(如POS、bigram等),并将问题视为分类问题。
下面展示一个经典的基于机器学习的《Complex event extraction at PubMed scale》的事件抽取流水线
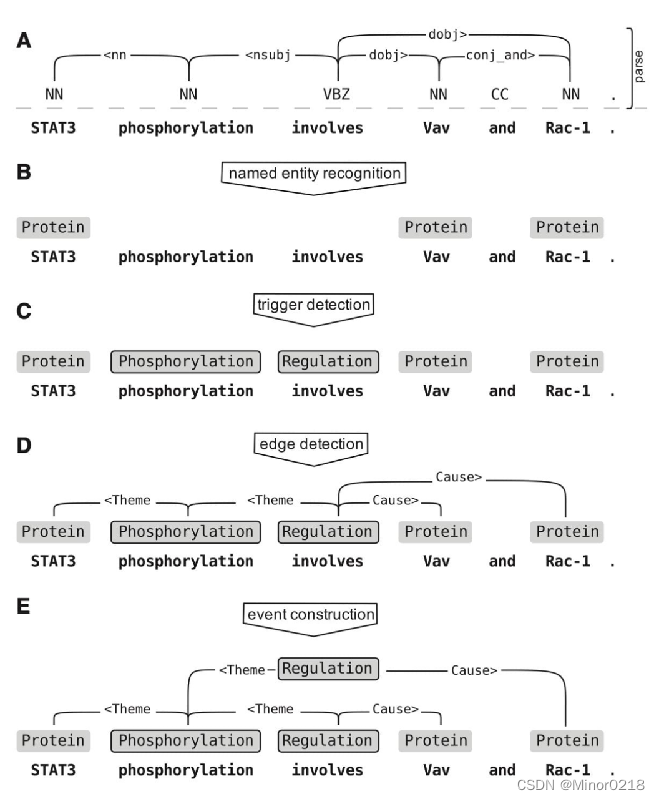 其中
其中
步骤 A 为句法树 parse
步骤 B 为利用 CRF 和已有特征进行命名实体识别
步骤 C 为利用分类模型对每个词单独分类从而识别触发词类型
步骤 D 为在触发词和实体间使用 SVM 构造多标签分类模型进行连边检测
最后在步骤E组合成为一个事件
基于深度学习的事件抽取
深度学习是机器学习技术的一个分支,通过深层神经网络解决了传统机器学习方法学习能力有限,无法通过持续增加数据量提升学习到的知识总量的问题,并有一定的自动表征能力。解放了设计机器学习模型时设计与构建特征的难题。
- 可以与 TextCNN 一样使用卷积神经网络来提取文本的特征,然后送入分类模型进行分类,或进行序列标注。
- 也可以利用长短记忆神经网络的链式网络结构对句子中各个词的上下文关系进行建模,以提升效果。
- 使用最新的BERT等预训练语言模型,在大规模预训练的基础之上再对事件抽取任务进行微调。
最新的事件抽取方法大都是基于深度学习模型所构建的。
下面展示《Exploring Pre-trained Language Models for Event Extraction and Generation》提出的一个两阶段的深度学习事件抽取模型
文中的抽取模型分为两步:触发词抽取(左)与论元抽取(右)
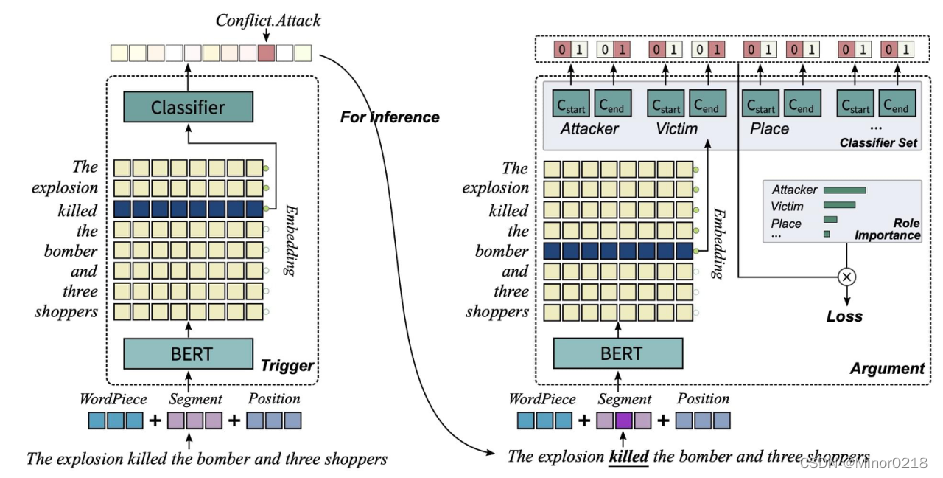
- 首先通过 BERT 的序列标注方式,对句子中的每个词进行分类,得到各个词能作为某一类触发词的可能性。
- 然后将各个触发词与原句字一同送入论元抽取模型中,对每个词执行二分类,即可得到单个词作为指定触发词论元的概率,通过这种方式解决了一个词同时作为多个事件的论元的重叠问题。
联合学习方法
对信息抽取中的实体抽取, 关系抽取和事件抽取的不断研究, 部分学者开始进行多任务联合学习的研究, 多任务联合学习解决了各任务独立学习时忽略了依存关系问题。 如下图所示,展示了联合抽取
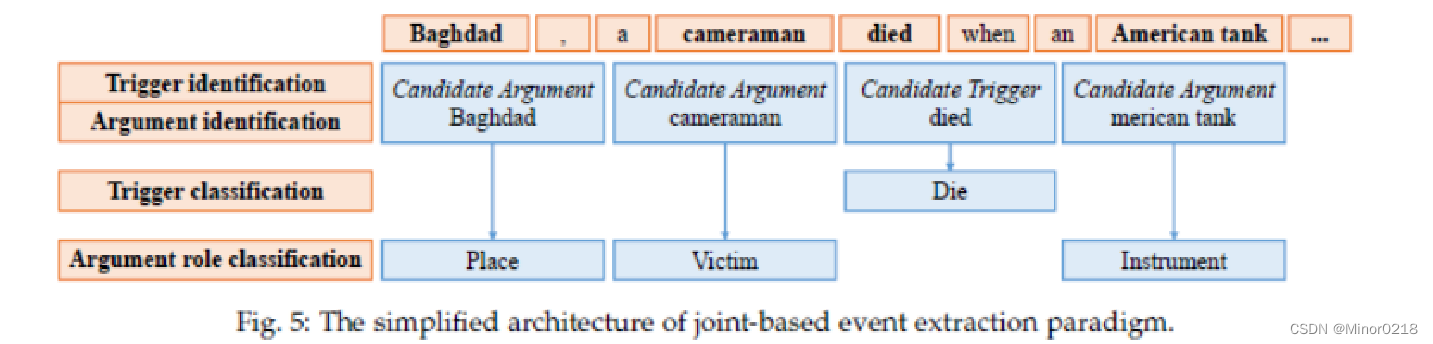
- 该方法在第一阶段根据候选触发器和实体识别触发器和元素。
- 在第二阶段,为了避免事件类型错误信息的传播,同时实现了触发器分类和元素角色分类。将触发器“died”分为Die事件类型,元素“Baghdad”分为Place元素角色等。
关系抽取方法
基于深度学习的方法
流水线学习
流水线学习方法中的关系抽取是在实体抽取完成的基础上进行的, 因此关系抽取结果的好坏与实体抽取的结果有直接关联。主要采用的方法是CNNs和RNNs。其中CNNs有利于识别目标的结构特征,RNNs有利于识别序列。
联合学习
为了避免流水线学习中存在的问题, 联合抽取将实体和关系放在同一模型中共同抽取。联合学习主要有两种类别: 参数共享和标注策略。
- 参数共享指的是命名实体识别模型与关系分类模型通过共享层联合训练,共享层的选择非常重要,现有的方法一般采用wordembedding+bilstm网络,但最近的研究表明现有的bilstm网络得到字的上下文表示性能弱于bert语言模型;
- 联合标注策略是指利用扩展的标注策略同时完成实体识别和关系抽取两个任务。联合标注策略法需要改变标注人员的原有习惯,增加学习成本。
远程监督学习
在文本中, 如果实体之间存在某种关联, 那么就会以某种形式表现出这种关联。 在这种前提下, 基于远程监督的方法, 首先从文本中抽取出存在关系的实体对句子, 然后将句子作为训练数据放入模型中进行关系抽取。
事件抽取技术发展趋势
随着深度学习的发展,事件抽取技术越发成熟,但同时也暴露出了一些问题。
- 数据集大小不足、多样性不足
- 小语种、低资源语种缺乏数据等
因此,近年来有研究者开始针对在数据受限的情况下,
- 引入外部知识、小样本(few-shot)抽取等手段
- 或者利用问答技术来提升事件抽取模型的泛用性与效果
利用外部知识增强事件抽取
为了弥补事件抽取数据集受限的实时,不少研究者尝试引入外部知识以增强事件抽取的效果。例如,ACL 2016《Leveraging FrameNet to Improve Automatic Event Detection》引入了额外的语言资源库FrameNet来自动生成符合ACE要求的带标签新数据,从而实现对ACE2005数据集的扩充,并提升模型效果。
小样本事件抽取范式
小样本学习与传统深度学习模式有所区别,通常形式为一个非常小的支撑集提供标签信息,通过度量学习等方式让模型得到一定的泛化能力。 还有不少的研究者也在研究如何用少量的数据来训练好一个事件抽取模型,甚至不用数据通过迁移学习等手段来让模型有良好的效果。
基于问答的事件抽取
针对传统深度学习事件抽取模型无法对标签中的语义进行建模、无法捕获标签到触发词或论元的交互、泛化能力低的问题,研究者们提出了利用问答的形式来增强事件抽取的效果。
参考文献
http://姜磊,刘琦,赵肄江,袁鹏,李媛,邹子维.面向知识图谱的信息抽取技术综述[J].计算机系统应用,2022,31(07):46-54.DOI:10.15888/j.cnki.csa.008590
https://blog.csdn.net/weixin_44853840/article/details/118897547
https://blog.sciencenet.cn/blog-3472670-1296543.html
https://blog.csdn.net/INTSIG/article/details/126057809
事件抽取综述_凡心curry的博客-CSDN博客_事件抽取综述
「深度学习事件抽取」最新2022研究综述 - 知乎
版权归原作者 Minor0218 所有, 如有侵权,请联系我们删除。