
离线数仓-9-数据仓库开发DWS层设计要点-1d/nd/td表设计
离线数仓-9-数据仓库开发DWS层设计要点-1d/nd/td表设计
一、DWS层设计要点
- DWS层计算是依托于业务层面的需求来实现的,是需求驱动的。
- 设计要点: - 1.DWS层的设计参考指标体系; - 具体参考之前文档笔记:https://blog.csdn.net/weixin_38136584/article/details/129167647?spm=1001.2014.3001.5501- 从0-1搭建dws层步骤: - 1.分析现有的每个业务需求,这一步最难,每个业务需求怎样计算,然后分析每个业务需求依赖哪些指标,每个指标依赖的派生指标有哪些,构建出业务需求指标的分析视图。- 2.从分析出来的业务需求视图里面,可以提炼到表格汇总,然后寻找共用的派生指标有哪些- 3.根据派生指标,来进行设计DWS层表格,在DWS层创建表格和派生指标关系?一对多;哪些派生指标共用公共派生指标表格呢? - 将业务过程相同、统计周期相同、统计粒度相同的派生指标汇总到一个派生指标对应的表格中,这样DWS层表格就会减少很多。 - 业务过程相同:来自于同一张事实表- 统计周期相同:在进行过滤的时候,过滤的分区也相同。 - 不同周期的可以放在一个表格中,但是这样存储的话,在进行数据装载的时候,如果牵涉到历史至今的周期和最近一天的周期,那么会全量扫描dwd层全表,但是最新一天的数据,仅仅跟前一日的分区有关系,数据装载的效率降低。- 建议将不同周期的存放在不同的表格中,即便是业务过程和统计粒度相同。- 统计粒度相同: 统计粒度相同的话,派生指标计算完毕的数据都是一个值,对应到的都是统计粒度维度,这些计算完的指标,新增一个字段,将结果存放进去即可。- 2.DWS层的数据存储格式为ORC列式存储 + snappy压缩。- 3.DWS层表名的命名规范为:dws_数据域_统计粒度_业务过程_统计周期(1d/nd/td) 注:1d表示最近1日,nd表示最近n日,td表示历史至今。
二、DWS层设计分析 - 1d/nd
1.DWS层设计一:不考虑用户维度
1.首先需要对ADS层业务需求进行明确,需求如下: - 1.各品牌商品交易统计- 2.各品类商品交易统计
统计周期统计粒度指标最近1、7、30日品牌订单数最近1、7、30日品牌订单人数最近1、7、30日品牌退单数最近1、7、30日品牌退单人数统计周期统计粒度指标最近1、7、30日品类订单数最近1、7、30日品类订单人数最近1、7、30日品类退单数最近1、7、30日品类退单人数2.构建指标体系,对于需求进行指标分析,分析出每个需求对应什么类型指标- 各品牌的指标体系分析
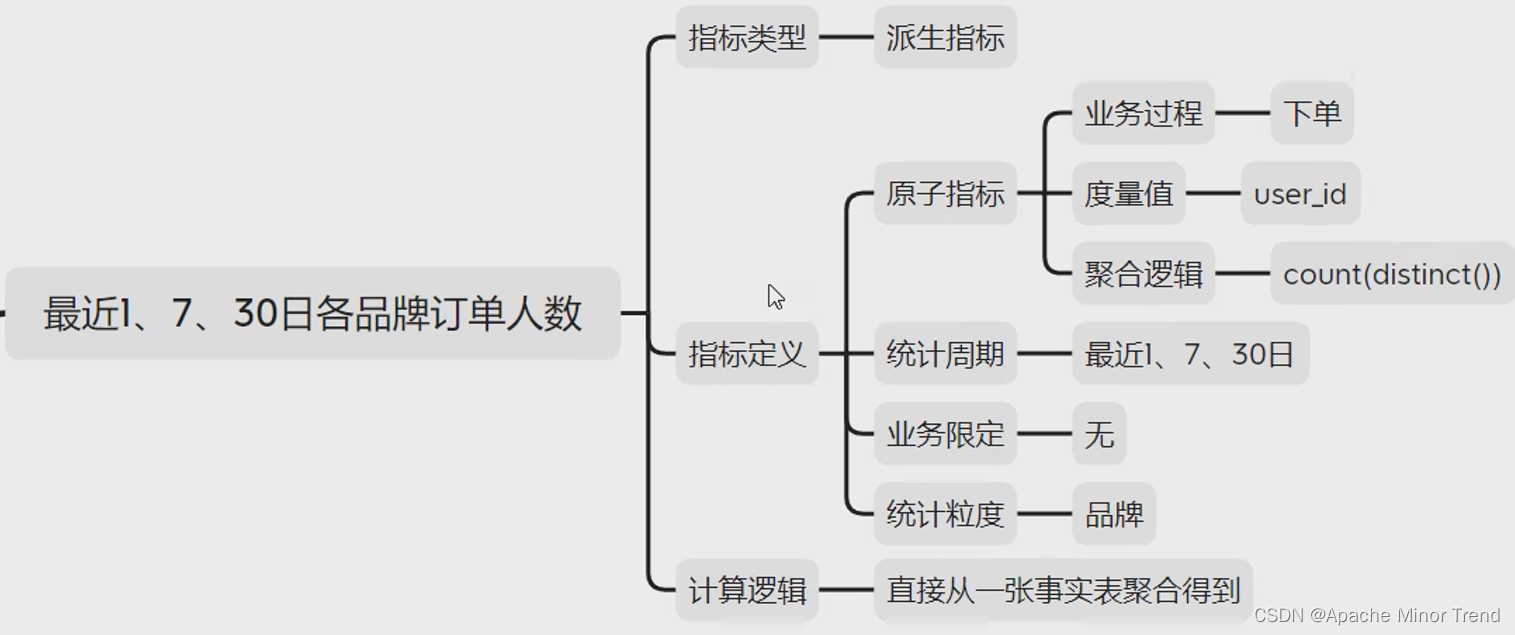 - 各品类的指标体系分析
- 各品类的指标体系分析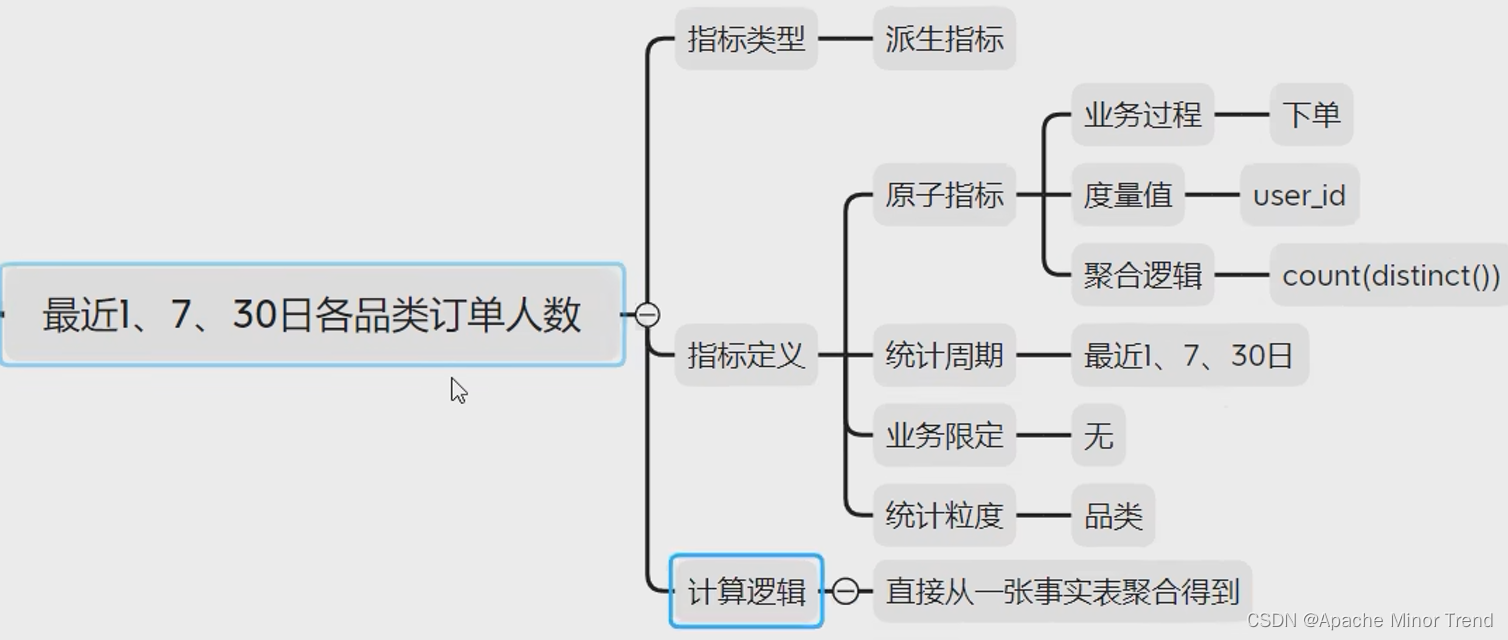
3.抽取派生指标,将刚刚思维导图中汇总的指标体系,梳理到表格中,抽取共用的派生指标
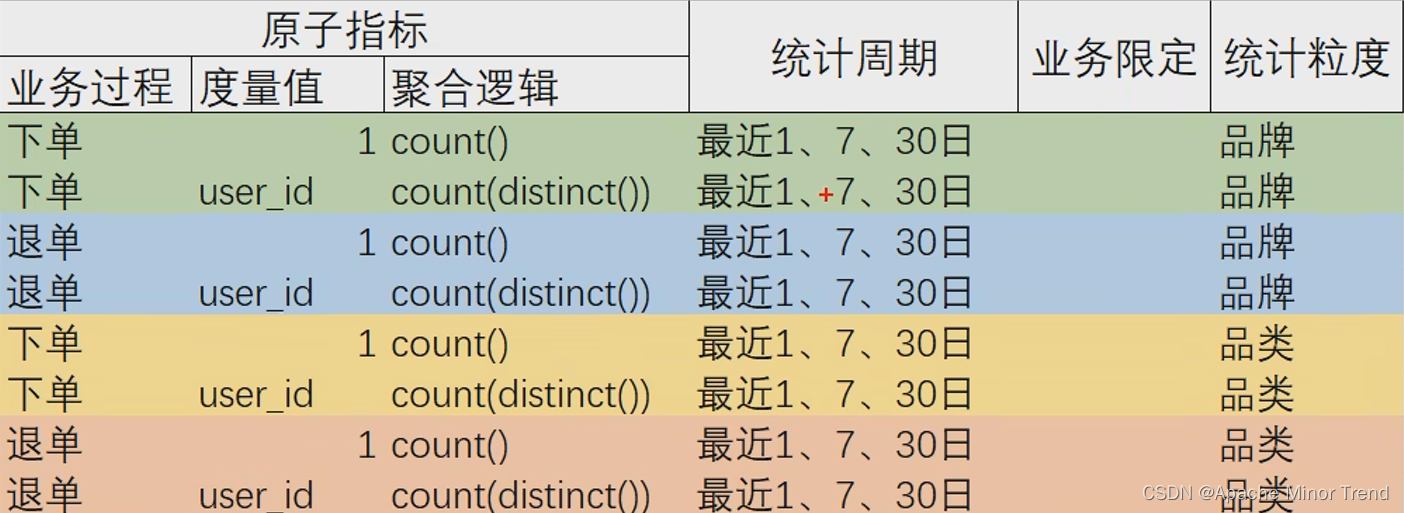
4.设计DWS层汇总表,根据刚刚梳理的指标体系表格,梳理出DWS层需要创建哪些表格。 DWS层表名的命名规范为:dws_数据域_统计粒度_业务过程_统计周期(1d/nd/td)- 针对表格第一行和第二行,设计表格名:dwd_trade_tm_order_1d- 行信息规划:每行代表此品牌最近1天下单总数量- 列字段规划:品牌id,聚合后的值(下单次数),聚合后的值(下单人数),品牌的名称(可以加,可以不加,直接关联维度表即可)- 分区规划:每天计算,最近一日的汇总结果。按天创建分区,每天分区里面存放当天的汇总结果
5.创建dwd_trade_tm_order_1d表格的DDL语句- 数仓表格设计的时候,尽量避免后期改表操作,怎么避免? - 1. 在DWS添加指标信息的时候,尽量考虑全面,参考维度是:DWD层的相关的表格的度量值。- 最近1天指标DDL语句如下:
create external table dws_trade_tm_order_1d
(
tm_id string comment'品牌id',
tm_name string comment'品牌名称',
order_count bigintcomment'最近1日下单次数',
order_user_count bigintcomment'最近1日下单人数',
order_num bigintcomment'最近1日下单件数',
order_total_amount decimal(16,2)comment'最近1日下单金额')comment'交易域品牌粒度订单最近1日汇总事实表'partitionby(dt string)
stored as orc
location '/warehouse/gmall/dws/dws_trade_tm_order_1d'
tblproperties('orc.compress'='snappy')
- 6.对于dwd_trade_tm_order_1d表格进行数据装载 - 装载数据SQL如下:
insert overwrite table dws_trade_tm_order_1d partition(dt='2020-06-14'SELECT
tm_id,
tm_name,COUNT(1),count(DISTINCT(user_id)),sum(sku_num),sum(split_total_amount)from(SELECT
sku_id, user_id, sku_num, split_total_amount
from
dwd_trade_order_detail_inc
where
dt ='2020-06-14')od
leftJOIN(select
id, tm_id, tm_name
FROM
dim_sku_full
where
dt ='2020-06-14')sku on
od.sku_id = sku.id
GROUPby
tm_id,
tm_name;
- 7.nd表的创建表格DDL语句:
create external table dws_trade_tm_order_nd
(
tm_id string comment'品牌id',
tm_name string comment'品牌名称',
order_count_7d bigintcomment'最近7日下单次数',
order_user_count_7d bigintcomment'最近7日下单人数',
order_num_7d bigintcomment'最近7日下单件数',
order_total_amount_7d decimal(16,2)comment'最近7日下单金额',
order_count_30d bigintcomment'最近30日下单次数',
order_user_count_30d bigintcomment'最近30日下单人数',
order_num_30d bigintcomment'最近30日下单件数',
order_total_amount_30d decimal(16,2)comment'最近30日下单金额')comment'交易域品牌粒度订单最近7日和30日汇总事实表'partitionby(dt string)
stored as orc
location '/warehouse/gmall/dws/dws_trade_tm_order_nd'
tblproperties('orc.compress'='snappy')
- 8.nd表的数据装载 - 存在1d表的数据,优先从1d表中获取,否则直接从dwd层事实表中获取。
insert overwrite table dws_trade_tm_order_nd partition(dt='2020-06-14')select
tm_id,
tm_name,sum(if(dt>=date_sub('2020-06-14',6),order_count,0)),//计算最近7天的数据sum(if(dt>=date_sub('2020-06-14',6),order_user_count,0)),sum(if(dt>=date_sub('2020-06-14',6),order_num,0)),sum(if(dt>=date_sub('2020-06-14',6),order_total_amount,0)),sum(order_count),sum(order_user_count),sum(order_num),sum(order_total_amount),from dws_trade_tm_order_1d
where dt >= date_sub('2020-06-14',29)groupby tm_id,tm_name;
- 9.nd表的装载语句存在重复计算的问题,一个下单用户 可能在30个分区都有,但是仅仅是一个下单用户,但在计算的时候,每个分区都有此下单用户,没有进行去重操作,那么相加完毕后,全部一个用户就变成了30个用户了,数据不准确了。 - 怎样解决? - 1.从dwd层获取原始数据,最近7天,最近30天,dws层直接去重汇总即可。- 2.降低1d表的维度,之前表格不体现用户维度,现在表格体现用户维度,要重新修改1d表格。
2.DWS层设计二:考虑用户维度
- 1.重新创建1d表 DDL如下:
create external table dws_trade_user_tm_order_1d
(
user_id string comment'用户id',
tm_id string comment'品牌id',
tm_name string comment'品牌名称',
order_count bigintcomment'最近1日下单次数',
order_num bigintcomment'最近1日下单件数',
order_total_amount decimal(16,2)comment'最近1日下单金额')comment'交易域用户品牌粒度订单最近1日汇总事实表'partitionby(dt string)
stored as orc
location '/warehouse/gmall/dws/dws_trade_tm_order_1d'
tblproperties('orc.compress'='snappy')
- 2.1d表数据装载语句
insert overwrite table dws_trade_user_tm_order_1d partition(dt='2020-06-14'SELECT
user_id,
tm_id,
tm_name,COUNT(1),sum(sku_num),sum(split_total_amount)from(SELECT
sku_id, user_id, sku_num, split_total_amount
from
dwd_trade_order_detail_inc
where
dt ='2020-06-14')od
leftJOIN(select
id, tm_id, tm_name
FROM
dim_sku_full
where
dt ='2020-06-14')sku on
od.sku_id = sku.id
GROUPby
user_id,
tm_id,
tm_name;
- 3.nd表的创建表格DDL语句:
create external table dws_trade_user_tm_order_nd
(
user_id string comment'用户id',
tm_id string comment'品牌id',
tm_name string comment'品牌名称',
order_count_7d bigintcomment'最近7日下单次数',
order_num_7d bigintcomment'最近7日下单件数',
order_total_amount_7d decimal(16,2)comment'最近7日下单金额',
order_count_30d bigintcomment'最近30日下单次数',
order_num_30d bigintcomment'最近30日下单件数',
order_total_amount_30d decimal(16,2)comment'最近30日下单金额')comment'交易域用户品牌粒度订单最近7日和30日汇总事实表'partitionby(dt string)
stored as orc
location '/warehouse/gmall/dws/dws_trade_tm_order_nd'
tblproperties('orc.compress'='snappy')
- 4.指标体系调整:其他指标也需要跟着调整
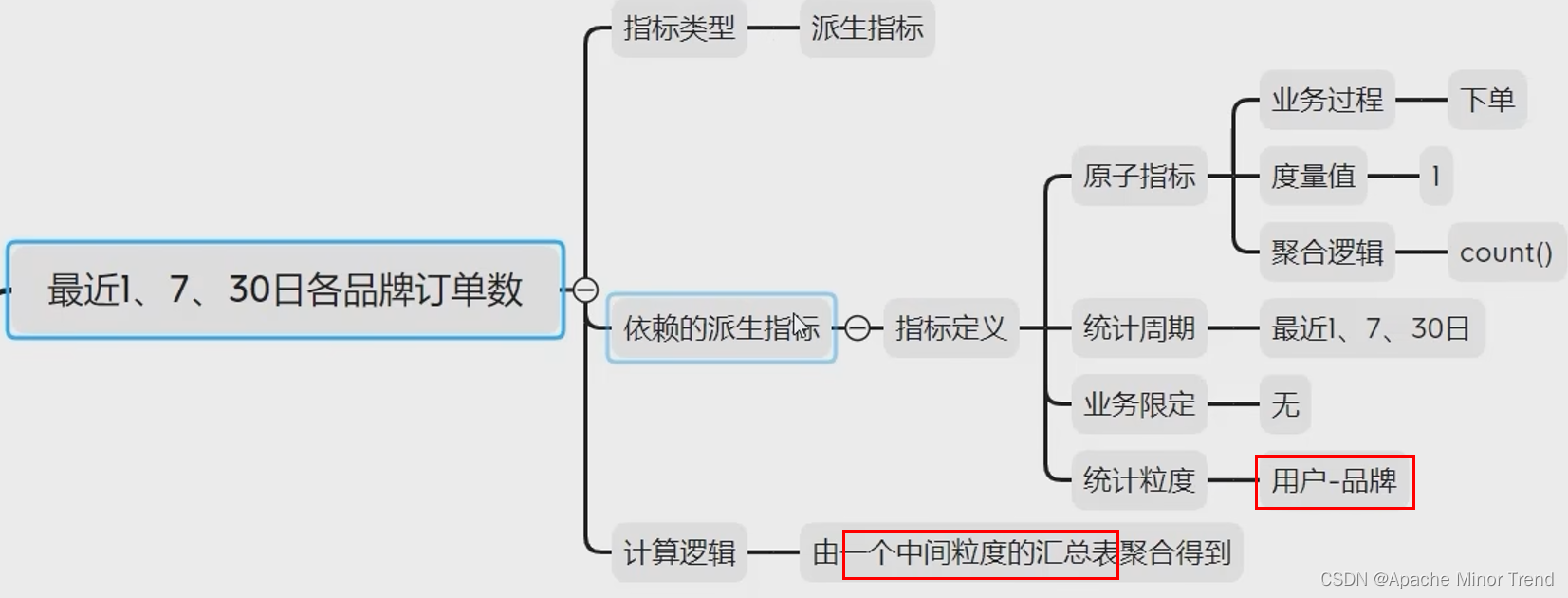
- 5.对应需求矩阵
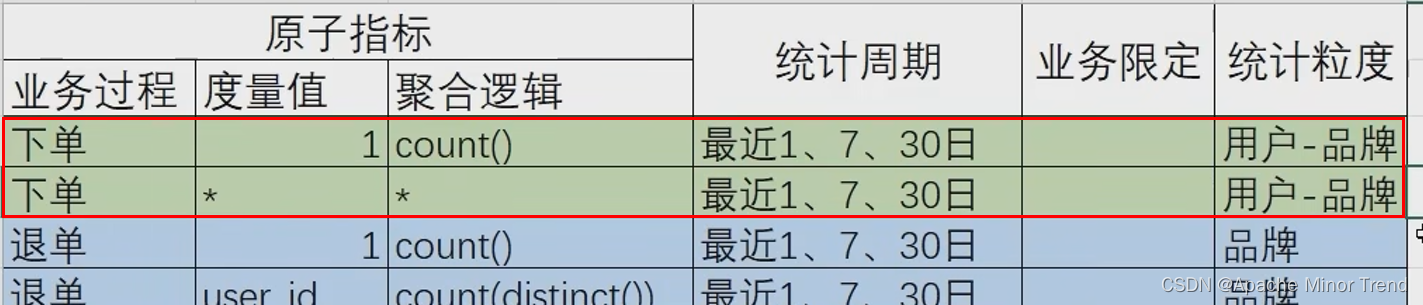
- 6.nd表的数据装载- 存在1d表的数据,优先从1d表中获取,否则直接从dwd层事实表中获取。
insert overwrite table dws_trade_user_tm_order_nd partition(dt='2020-06-14')select
user_id ,
tm_id,
tm_name,sum(if(dt>=date_sub('2020-06-14',6),order_count,0)),//计算最近7天的数据sum(if(dt>=date_sub('2020-06-14',6),order_num,0)),sum(if(dt>=date_sub('2020-06-14',6),order_total_amount,0)),sum(order_count),sum(order_num),sum(order_total_amount),from dws_trade_tm_order_1d
where dt >= date_sub('2020-06-14',29)groupby user_id ,tm_id,tm_name;
2.DWS层设计三 :考虑用户+商品维度,形成DWS层汇总表
- 直接考虑用户+商品维度,创建的表格,就不需要去考虑建表的时候的品牌维度和品类维度了。
- 只创建一张用户+商品维度的DWS层表格,就可以直接提供给 品牌类需求使用,也可以提供给 品类需求使用,这样比较一下,上面几个设计在处理表的时候,较本设计模式增加了不少工作量; - 本设计模式,可以只提供一张表,然后供给品牌和品类需求使用。- 创建的DWS层表格粒度越小,将来服务的表格会越多。
最终建表方案:
- 1.1d建表语句:用户+商品维度建表DDL语句:
DROPTABLEIFEXISTS dws_trade_user_sku_order_1d;CREATE EXTERNAL TABLE dws_trade_user_sku_order_1d
(`user_id` STRING COMMENT'用户id',`sku_id` STRING COMMENT'sku_id',`sku_name` STRING COMMENT'sku名称',`category1_id` STRING COMMENT'一级分类id',`category1_name` STRING COMMENT'一级分类名称',`category2_id` STRING COMMENT'一级分类id',`category2_name` STRING COMMENT'一级分类名称',`category3_id` STRING COMMENT'一级分类id',`category3_name` STRING COMMENT'一级分类名称',`tm_id` STRING COMMENT'品牌id',`tm_name` STRING COMMENT'品牌名称',`order_count_1d`BIGINTCOMMENT'最近1日下单次数',`order_num_1d`BIGINTCOMMENT'最近1日下单件数',`order_original_amount_1d`DECIMAL(16,2)COMMENT'最近1日下单原始金额',`activity_reduce_amount_1d`DECIMAL(16,2)COMMENT'最近1日活动优惠金额',`coupon_reduce_amount_1d`DECIMAL(16,2)COMMENT'最近1日优惠券优惠金额',`order_total_amount_1d`DECIMAL(16,2)COMMENT'最近1日下单最终金额')COMMENT'交易域用户商品粒度订单最近1日汇总事实表'
PARTITIONED BY(`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dws/dws_trade_user_sku_order_1d'
TBLPROPERTIES ('orc.compress'='snappy');
- 2.nd建表语句:DDL语句
DROPTABLEIFEXISTS dws_trade_user_sku_order_nd;CREATE EXTERNAL TABLE dws_trade_user_sku_order_nd
(`user_id` STRING COMMENT'用户id',`sku_id` STRING COMMENT'sku_id',`sku_name` STRING COMMENT'sku名称',`category1_id` STRING COMMENT'一级分类id',`category1_name` STRING COMMENT'一级分类名称',`category2_id` STRING COMMENT'一级分类id',`category2_name` STRING COMMENT'一级分类名称',`category3_id` STRING COMMENT'一级分类id',`category3_name` STRING COMMENT'一级分类名称',`tm_id` STRING COMMENT'品牌id',`tm_name` STRING COMMENT'品牌名称',`order_count_7d` STRING COMMENT'最近7日下单次数',`order_num_7d`BIGINTCOMMENT'最近7日下单件数',`order_original_amount_7d`DECIMAL(16,2)COMMENT'最近7日下单原始金额',`activity_reduce_amount_7d`DECIMAL(16,2)COMMENT'最近7日活动优惠金额',`coupon_reduce_amount_7d`DECIMAL(16,2)COMMENT'最近7日优惠券优惠金额',`order_total_amount_7d`DECIMAL(16,2)COMMENT'最近7日下单最终金额',`order_count_30d`BIGINTCOMMENT'最近30日下单次数',`order_num_30d`BIGINTCOMMENT'最近30日下单件数',`order_original_amount_30d`DECIMAL(16,2)COMMENT'最近30日下单原始金额',`activity_reduce_amount_30d`DECIMAL(16,2)COMMENT'最近30日活动优惠金额',`coupon_reduce_amount_30d`DECIMAL(16,2)COMMENT'最近30日优惠券优惠金额',`order_total_amount_30d`DECIMAL(16,2)COMMENT'最近30日下单最终金额')COMMENT'交易域用户商品粒度订单最近n日汇总事实表'
PARTITIONED BY(`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dws/dws_trade_user_sku_order_nd'
TBLPROPERTIES ('orc.compress'='snappy');
- 3.指标体系和需求矩阵调整后结果
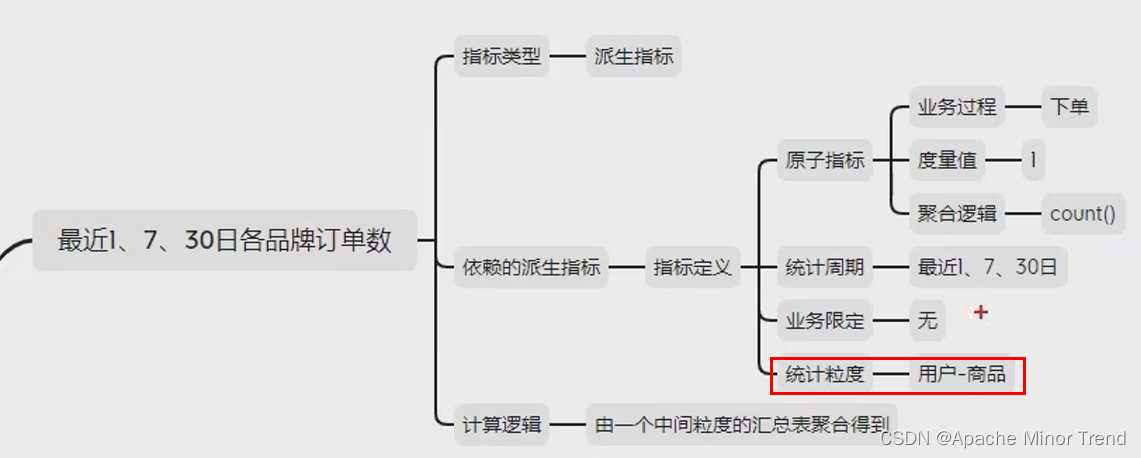
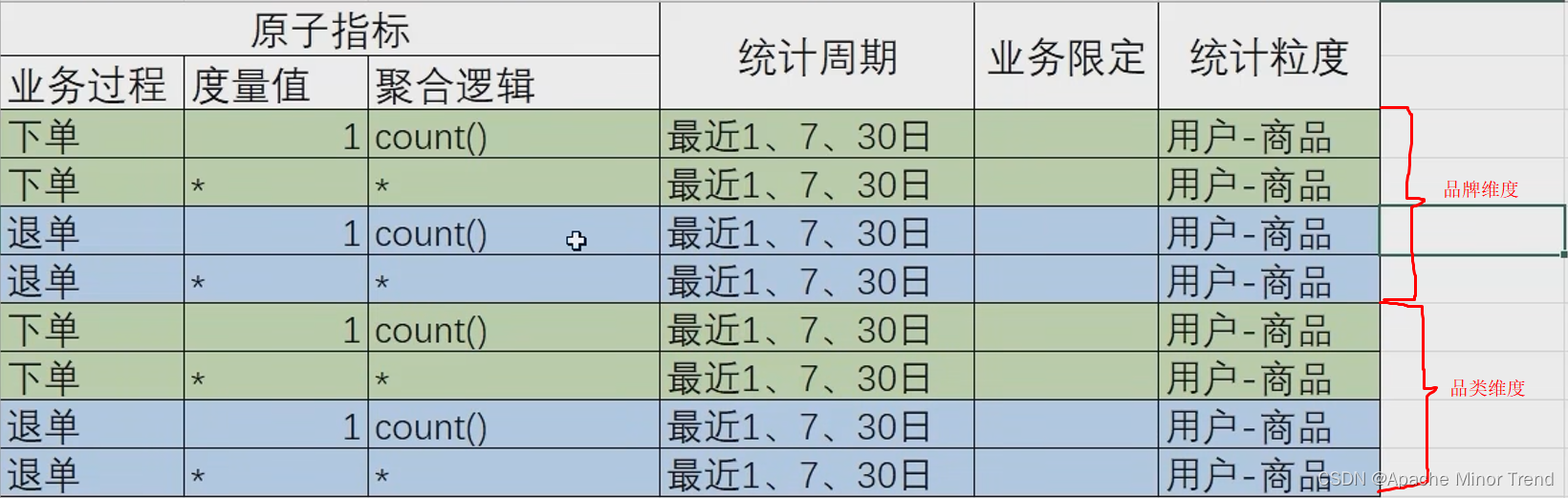
三、DWS层设计分析 - td 历史至今
1.以新增下单人数的需求为例
- 需求如下:
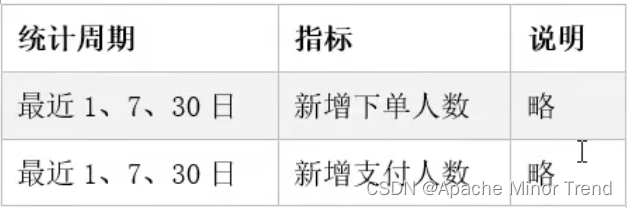
- 如果根据需求指标来直接处理的话,可能计算量以及sql复杂程度很高,可以换一种思路来解决此类需求;
- 维护一张表格,首次该用户下单的信息维护到这张表格里面,怎样整合这张表,需要根据dwd层全表数据进行汇总,然后将全量数据,根据需求进行逻辑计算,将所需数据维护到dws层的汇总表中,历史全量数据在首次导入的时候,进行sql处理后录入,每日新增数据只需要判断此表格有没有该用户记录即可,没有该用户直接插入表格。
- 创建表格:表格命名:dws_trade_user_order_td - 每行代表信息:某用户首次下单信息,以及用户维度其他信息- 每列信息:与用户相关的维度信息都可以汇总到此表格中- 分区:按天创建分区,每天存放的数据都是历史至今的最新数据。- 具体表格创建语句如下:
DROPTABLEIFEXISTS dws_trade_user_order_td;CREATE EXTERNAL TABLE dws_trade_user_order_td
(`user_id` STRING COMMENT'用户id',`order_date_first` STRING COMMENT'首次下单日期',`order_date_last` STRING COMMENT'末次下单日期',`order_count_td`BIGINTCOMMENT'下单次数',`order_num_td`BIGINTCOMMENT'购买商品件数',`original_amount_td`DECIMAL(16,2)COMMENT'原始金额',`activity_reduce_amount_td`DECIMAL(16,2)COMMENT'活动优惠金额',`coupon_reduce_amount_td`DECIMAL(16,2)COMMENT'优惠券优惠金额',`total_amount_td`DECIMAL(16,2)COMMENT'最终金额')COMMENT'交易域用户粒度订单历史至今汇总事实表'
PARTITIONED BY(`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dws/dws_trade_user_order_td'
TBLPROPERTIES ('orc.compress'='snappy');
- 装载数据: - 如果每次都求dwd层表格中全量数据的话, 太损耗计算资源,可以基于前一日计算结果进行计算。这样比较高效解决数据问题。
- 首日全量装载sql:
insert overwrite table dws_trade_user_order_td partition(dt='2020-06-14')select
user_id,min(dt) login_date_first,max(dt) login_date_last,sum(order_count_1d) order_count,sum(order_num_1d) order_num,sum(order_original_amount_1d) original_amount,sum(activity_reduce_amount_1d) activity_reduce_amount,sum(coupon_reduce_amount_1d) coupon_reduce_amount,sum(order_total_amount_1d) total_amount
from dws_trade_user_order_1d
groupby user_id;
- 每日增量装载sql:
- 方案一:之间使用full outer join ,然后获取的数据进行判断即可
insert overwrite table dws_trade_user_order_td partition(dt='2020-06-15')select
nvl(old.user_id,new.user_id),if(new.user_id isnotnulland old.user_id isnull,'2020-06-15',old.order_date_first),if(new.user_id isnotnull,'2020-06-15',old.order_date_last),
nvl(old.order_count_td,0)+nvl(new.order_count_1d,0),
nvl(old.order_num_td,0)+nvl(new.order_num_1d,0),
nvl(old.original_amount_td,0)+nvl(new.order_original_amount_1d,0),
nvl(old.activity_reduce_amount_td,0)+nvl(new.activity_reduce_amount_1d,0),
nvl(old.coupon_reduce_amount_td,0)+nvl(new.coupon_reduce_amount_1d,0),
nvl(old.total_amount_td,0)+nvl(new.order_total_amount_1d,0)from(select
user_id,
order_date_first,
order_date_last,
order_count_td,
order_num_td,
original_amount_td,
activity_reduce_amount_td,
coupon_reduce_amount_td,
total_amount_td
from dws_trade_user_order_td
where dt=date_add('2020-06-15',-1))old
fullouterjoin(select
user_id,
order_count_1d,
order_num_1d,
order_original_amount_1d,
activity_reduce_amount_1d,
coupon_reduce_amount_1d,
order_total_amount_1d
from dws_trade_user_order_1d
where dt='2020-06-15')new
on old.user_id=new.user_id;
- 方案二:两部分子查询之间使用union all进行关联
SELECT
user_id,min(order_date_first),max(order_date_last),sum(order_count_td),sum(order_num_td),sum(original_amount_td),sum(activity_reduce_amount_td),sum(coupon_reduce_amount_td),sum(total_amount_td)from(select
user_id, order_date_first, order_date_last, order_count_td, order_num_td, original_amount_td, activity_reduce_amount_td, coupon_reduce_amount_td, total_amount_td
from
dws_trade_user_order_td
where
dt = date_add('2020-06-15',-1)UNIONALLselect
user_id,'2020-06-15','2020-06-15', order_count_1d, order_num_1d, order_original_amount_1d, activity_reduce_amount_1d, coupon_reduce_amount_1d, order_total_amount_1d
from
dws_trade_user_order_1d
where
dt ='2020-06-15'GROUPby
user_id ) t1
groupby
user_id ;
- hive 中sql语法:- nvl(字段1,字段2) :取两个字段中不为空的那个字段,如果都不为空,取前一个,两个都为空,就不取。
- 开窗和分组- 开窗:在原有表格列的基础上,添加一列开窗列,可以基于此列进行分析数据- 分组:改变原有表格的粒度, 结果的粒度跟原来表格的粒度不一样了。
三、DWS层设计分析 - 总结
- dws层设计要点:1d表表结构设计,nd表表结构设计,td表表结构设计,以及对应的数据装载。 - 1d表表结构: - 行设计:派生指标的粒度决定的- 列设计:粒度的id,派生指标决定,设计时需要有一定的前瞻性,参考与之对应的dwd层的事实表的度量值- 分区设计: 按天分区,每天分区放的是当天明细的汇总结果,跟明细表分区对应- 数据装载:dwd层与之对应的明细表,从明细表中获取一个分区的数据,之后进行汇总,汇总完成后放到汇总表一天的分区里面。- nd表表结构: - 行设计:派生指标的粒度决定的- 列设计:跟1d表相比,多n维度字段,7d的指标,30d的指标- 分区设计:按天分区,截止当天的,最近N天的汇总数据- 数据装载:优先从1d表里面取数,如果没有1d表,那就去dwd层明细表取数。 - 直接拿30天的求和,然后在sql里面加个判断,获取最近7天的数据,这样就可以通过一个sql实现不同周期的计算。- td表表结构: - 行设计:派生指标的粒度决定的- 列设计:派生指标决定- 分区设计:按天分区,每个分区里面存放历史截止当天的汇总数据。- 数据装载: - 首日: 从dws层的1d或者dwd层明细表获取全表数据,优先1d表。- 每日:首先拿前一天的分区结果,然后拿1d表或者明细表里今天的结果,做加法运算,join或者union。
本文转载自: https://blog.csdn.net/weixin_38136584/article/details/129223090
版权归原作者 Apache Minor Trend 所有, 如有侵权,请联系我们删除。
版权归原作者 Apache Minor Trend 所有, 如有侵权,请联系我们删除。