
传统CNN,内存需求量大、运算量大,导致无法在移动设备以及嵌入式设备上运行。MobileNet是Google团队在2017年提出,专注于移动端或者嵌入式设备中的轻量级CNN网络。相比于传统的CNN,在准确率下幅度下降的前提下大大减少了模型参数与运算量。(相比于VGG16准确率下降了0.9%,但模型参数只有VGG的1/32)。MobileNet 作为 backbone 可以用于各种视觉任务。
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- MobileNetV2: Inverted Residuals and Linear Bottlenecks
- Searching for MobileNetV3
MobileNet v1
网络中的亮点:
- Depthwise Convolution,大大减少运算量和参数量
- 增加超参数α和β,宽度乘数和分辨率乘数,可以有效地在延迟和准确性之间进行权衡。这些超参数允许模型构建者根据问题的限制条件为其应用程序选择合适大小的模型。
传统卷积
卷积核channel=输入特征图channel,输出矩阵特征矩阵channel=卷积核的个数
Depthwise Convolution
卷积核channel=1,输入特征矩阵channel=卷积核个数=输出特征矩阵channel。每个卷积核都只负责输入图一个channel的卷积运算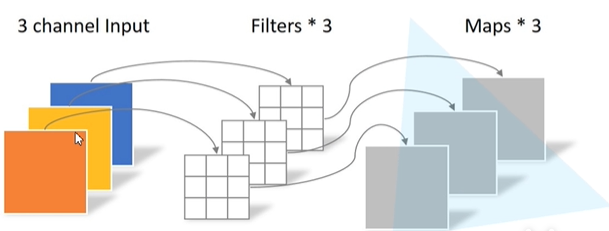
一、Depthwise Separable Convolution 深度可分离卷积
由两部分组成,分别是Depthwise convolution 和 Pointwise Convolution。
Pointwise Convolution
和普通卷积一样,只不过卷积核的大小为1。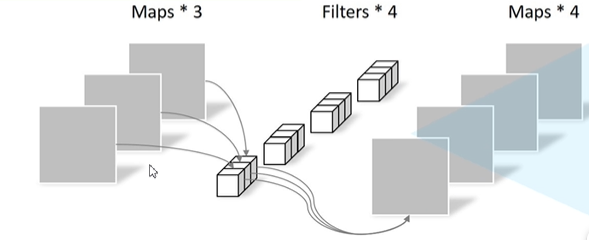
深度可分离卷积和普通卷积的实现对比
二、模型复杂度的衡量
1 模型复杂度的衡量
- 参数数量(Params):指模型含有多少参数,直接决定模型的大小,也影响推断时对内存的占用量 - 单位通常为 M,通常参数用 float32 表示,所以
模型大小是参数数量的 4 倍左右- 参数数量与模型大小转换示例:10M float32 bit = 10M × 4 Byte = 40MB- 理论计算量(FLOPs):指模型推断时需要多少计算次数 - 是 floating point operations 的缩写(注意 s 小写),可以用来衡量算法/模型的复杂度,这关系到算法速度,大模型的单位通常为 G(GFLOPs:10亿次浮点运算),小模型单位通常为 M- 通常只考虑
乘加操作(Multi-Adds)的数量,而且只考虑CONV 和 FC等参数层的计算量,忽略 BN 和 ReLU 等等。一般情况,CONV 和 FC 层也会忽略仅纯加操作的计算量,如 bias 偏置加和 shotcut 残差加等,目前有 BN 的卷积层可以不加 bias- PS:也有用 MAC(Memory Access Cost) 表示的
2 模型复杂度的计算公式
假设卷积核大小为
K
h
×
K
w
K_h \times K_w
Kh×Kw,输入通道数为
C
i
n
C_{in}
Cin,输出通道数为
C
o
u
t
C_{out}
Cout,输出特征图的宽和高分别为W和H,这里忽略偏置项
- Conv标准卷积层 - Params: K h × K w × C i n × C o u t K_h \times K_w \times C_{in} \times C_{out} Kh×Kw×Cin×Cout- FLOPs: K h × K w × C i n × C o u t × H × W K_h \times K_w \times C_{in} \times C_{out} \times H \times W Kh×Kw×Cin×Cout×H×W = params × H × W \times H \times W ×H×W
- FC全连接层 - Params: C i n × C o u t C_{in} \times C_{out} Cin×Cout- FLOPs: C i n × C o u t C_{in} \times C_{out} Cin×Cout
- 参数量与计算量:https://github.com/Lyken17/pytorch-OpCounter
下面比较普通卷积和深度可分离卷积的计算量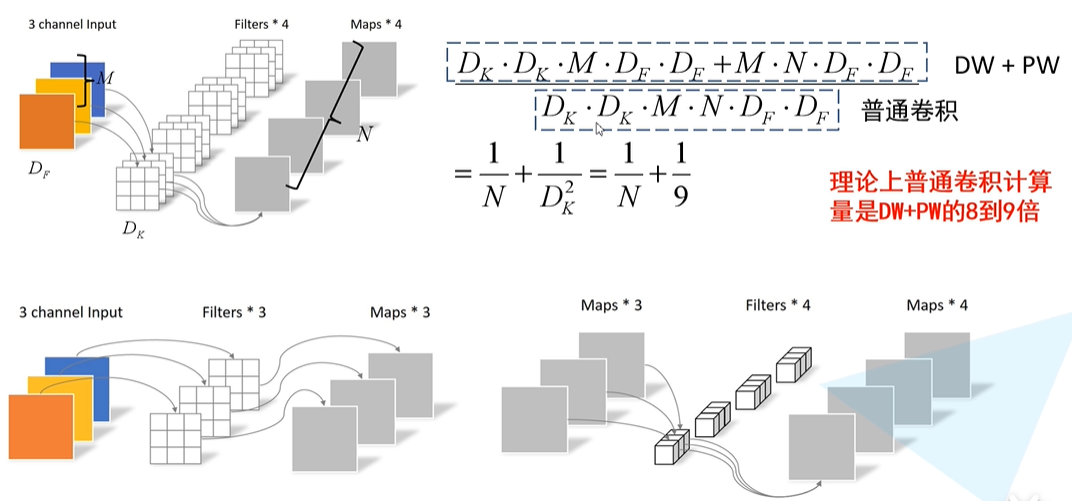
其中,
D
F
D_F
DF是输入特征图的宽和高,
D
K
D_K
DK是卷积核的大小,M是输入特征图的通道数,N是卷积核的个数。(stride=1,输入和输出矩阵的大小一样)
三、两个超参数
- Width Multiplier(α):缩减模型的宽度 - 所有层通道数(channel)乘以α参数(四舍五入),模大小近似下降到原来的 α 2 \alpha ^2 α2倍,计算量下降到原来的 α 2 \alpha ^2 α2倍- α ∈ ( 0 , 1 ] \alpha \in (0,1] α∈(0,1] 常用的值有1,0.75,0.5,0.25,降低模型的参数,可根据项目需要调整
- Resolution Multiplier(β):减小输入图像的分辨率 - 输入层分辨率乘以β参数,等价于所有层的分辨率乘以β,模型大小不变,分辨率降为原来的 β 2 \beta ^2 β2倍。- β ∈ ( 0 , 1 ] \beta \in (0,1] β∈(0,1],降低输入图像的分辨率
MobileNetV1存在的问题: Depthwise部分的卷积核容易废掉,即卷积核参数大部分为零。
MobileNet v2
MobileNet V2是谷歌团队在2018年提出,相比于V1网络,准确率更高,模型更小。
网络亮点:
- Inverted Residuals 倒残差结构。先升维再降维,增强梯度的传播,显著减少推理期间所需的内存占用
- Linear Bottlenecks 去掉 Narrow layer(low dimension or depth) 后的 ReLU,保留特征多样性,增强网络的表达能力(Linear Bottlenecks)
- 网络为全卷积的,使得模型可以适应不同尺寸的图像;使用 RELU6(最高输出为 6)激活函数,使得模型在低精度计算下具有更强的鲁棒性
Depthwise Conv存在的问题:
- 在处理低维数据(比如逐深度的卷积)时,relu函数会造成信息的丢失。
- DW 卷积由于本身的计算特性决定它自己没有改变通道数的能力,上一层给它多少通道,它就只能输出多少通道。所以如果上一层给的通道数本身很少的话,DW 也只能很委屈的在低维空间提特征,因此效果不够好。
论文中说明,对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少。
V2使用了跟V1类似的深度可分离结构,不同之处也正对应着V1中逐深度卷积的缺点改进:
- V2 去掉了第二个 PW 的激活函数改为线性激活。 论文作者称其为 Linear Bottleneck。原因如上所述是因为作者认为激活函数在高维空间能够有效的增加非线性,而在低维空间时则会破坏特征,不如线性的效果好。
- V2 在 DW 卷积之前新加了一个 PW 卷积。 给每个 DW 之前都配备了一个 PW,专门用来升维,定义升维系数t=6 ,这样不管输入通道数 C i n C_{in} Cin是多是少,经过第一个 PW 升维之后,DW 都是在相对的更高维( t ⋅ C i n t \cdot C_{in} t⋅Cin)进行更好的特征提取。
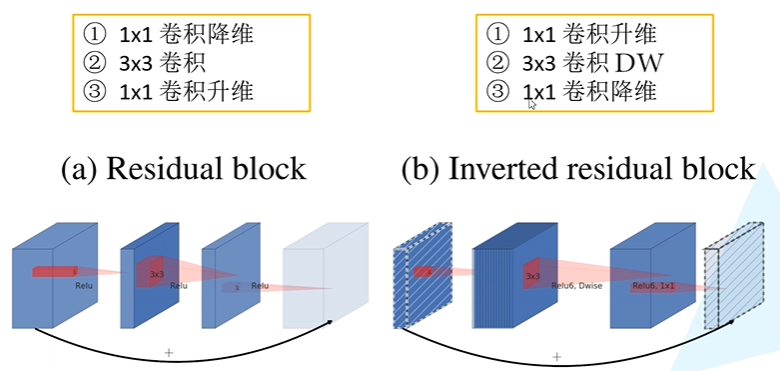 Inverted residuals block中使用的激活函数为ReLU6,其最大输出为6, y = R e L U 6 ( x ) = m i n ( m a x ( x , 0 ) , 6 ) y = ReLU6(x)=min(max(x,0),6) y=ReLU6(x)=min(max(x,0),6) 在倒残差结构中,只有当stride=1,且输入特征矩阵与输出特征矩阵shape相同时,才会有shortcut连接(残差连接)
Inverted residuals block中使用的激活函数为ReLU6,其最大输出为6, y = R e L U 6 ( x ) = m i n ( m a x ( x , 0 ) , 6 ) y = ReLU6(x)=min(max(x,0),6) y=ReLU6(x)=min(max(x,0),6) 在倒残差结构中,只有当stride=1,且输入特征矩阵与输出特征矩阵shape相同时,才会有shortcut连接(残差连接)
MobileNet v3
v3相比于v2和v1的改动如下:
- 更新了Block(bneck),在v3版本中原论文称之为bneck,在v2版倒残差结构上进行了简单的改动。
- 使用了NAS(Neural Architecture Search)搜索参数
- 重新设计了耗时结构:作者使用NAS搜索之后得到的网络,接下来对网络每一层的推理时间进行分析,针对某些耗时的层结构做了进一步的优化
一、更新Block
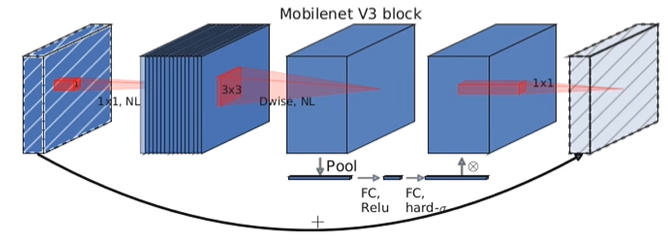
1 加入SE模块(注意力机制)

对特征矩阵的每一个channel进行池化操作,通过两个全连接层的得到输出向量,得到的向量可以理解为对特征矩阵的每一个channel的注意力权重,比较重要的channel赋予较大的权重。对于第二个全连接层使用H-sigmoid激活函数。
得到的权重向量与原有的特征矩阵加权,得到新的特征矩阵
2 更新了激活函数
之前在v2版本我们基本都是使用ReLU6激活函数,现在比较常用的激活函数叫swish激活函数。
s
w
i
s
h
x
=
x
⋅
σ
(
x
)
swish \; x = x \cdot \sigma (x)
swishx=x⋅σ(x)
其中,
σ
(
x
)
=
1
1
+
e
−
x
\sigma (x)=\frac{1}{1+e^{-x}}
σ(x)=1+e−x1,这个激活函数计算,求导复杂,对量化过程不友好(对移动端设备,基本上为了加速都会对它进行量化操作)。
由于存在这个问题,作者就提出了h-switch激活函数,在讲h-switch激活函数之前我们来讲一下h-sigmoid激活函数
h-sigmoid激活函数是在relu6激活函数上进行修改的:
R
e
L
U
6
(
x
)
=
m
i
n
(
m
a
x
(
x
,
0
)
,
6
)
h
−
s
i
g
m
o
i
d
=
R
e
L
U
6
(
x
+
3
)
6
ReLU6(x)=min(max(x,0),6) \\ h-sigmoid = \frac{ReLU6(x+3)}{6}
ReLU6(x)=min(max(x,0),6)h−sigmoid=6ReLU6(x+3)
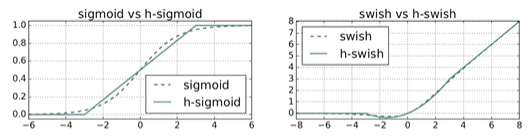
从图中可以看出h-sigmoid与sigmoid激活函数比较接近,所以在很多场景中会使用h-sigmoid激活函数去替代我们的sigmoid激活函数。因此h-switch中σ \sigmaσ替换为h-sigmoid之后,函数的形式如下:
h
−
s
w
i
t
c
h
[
x
]
=
x
R
e
L
U
6
(
x
+
3
)
6
h-switch[x] = x \frac{ReLU6(x+3)}{6}
h−switch[x]=x6ReLU6(x+3)
如上图右侧部分,是switch和h-switch激活函数的比较,很明显这两个曲线是非常相似的,所以说使用h-switch来替代switch激活函数还是挺棒的。
在原论文中,作者说将h-switch替换switch,将h-sigmoid替换sigmoid,对于网络的推理过程而言,在推理速度上是有一定帮助的,并且对量化过程也是非常友好的。
二、重新设计耗时层结构
在原论文中主要讲了两个部分:
- 减少第一个卷积层的卷积个数(32 -> 16) 在v1,v2版本第一层卷积核个数都是32,作者说将卷积核Filter个数从32变为16之后,它的准确率是和32是一样的,既然准确率没有影响,使用更少的卷积核计算量就变得更小了。这里节省了大概2ms的运算时间
- 精简Last Stage 在使用NAS搜索出来的网络结构的最后一部分,叫做Original last Stage,它的网络结构如下:
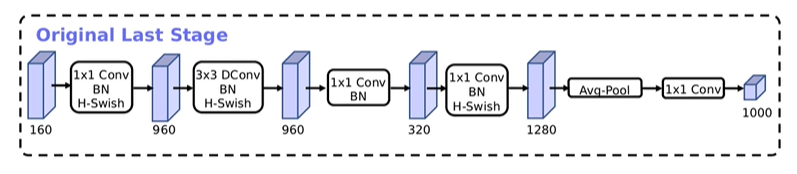 该网络是主要是通过堆叠卷积而来的,作者在使用过程中发现这个Original Last Stage是一个比较耗时的部分,作者就针对该结构进行了精简,提出了一个Efficient Last Stage
该网络是主要是通过堆叠卷积而来的,作者在使用过程中发现这个Original Last Stage是一个比较耗时的部分,作者就针对该结构进行了精简,提出了一个Efficient Last Stage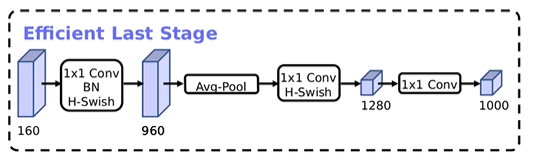 Efficient Last Stage相比之前的Original Last Stage,少了很多卷积层,作者发现更新网络后准确率是几乎没有变化的,但是节省了7ms的执行时间。这7ms占据了推理11%的时间,因此使用Efficient Last Stage之后,对我们速度提升还是比较明显的。
Efficient Last Stage相比之前的Original Last Stage,少了很多卷积层,作者发现更新网络后准确率是几乎没有变化的,但是节省了7ms的执行时间。这7ms占据了推理11%的时间,因此使用Efficient Last Stage之后,对我们速度提升还是比较明显的。
参考内容
- https://blog.csdn.net/mzpmzk/article/details/82976871
- https://zhuanlan.zhihu.com/p/402766063
- https://www.bilibili.com/video/BV1yE411p7L7/?spm_id_from=333.337.search-card.all.click&vd_source=e2905e52f4db50f33e7a0b5314867bee
- https://zhuanlan.zhihu.com/p/402766063
- https://blog.csdn.net/weixin_38346042/article/details/125470446
版权归原作者 weixin_44858167 所有, 如有侵权,请联系我们删除。