
flink作为实时流处理平台,可以与kafka很好地结合。
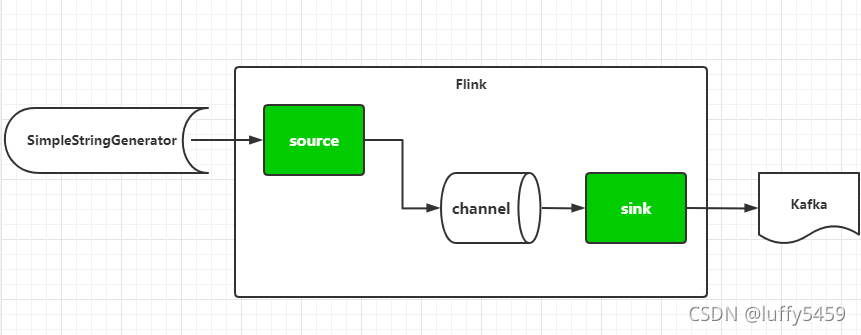
因为flink流处理的特点,需要source和sink作为流处理的源头和终端。与kafka的结合,可以让flink作为生产者,不断的向kafka消息队列中产生消息。这个作为今天的第一个示例。对应下图的场景。
还有一种情况,让flink作为kafka的消费者,读取消息队列中的消息,然后做处理。这时候flink的与kafka的角色发生了变化,对应下图的场景。

根据以上的两种情况,我们来编写相关程序:
首先 ,构建maven工程,加入flink与kafka的一些依赖:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xxx</groupId>
<artifactId>flinkdemo</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>flinkdemo</name>
<url>http://maven.apache.org</url>
<properties>
<flink.version>1.13.1</flink.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_${scala.binary.version}</artifactId>
<version>1.11.4</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.7.8</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers combine.children="append">
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer">
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
第一个,flink消费者示例:
package com.xxx.flinkdemo;
import java.io.Serializable;
import java.util.Properties;
import org.apache.commons.lang3.RandomStringUtils;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer010;
public class KafkaProducerApp {
public static void main(String[] args) throws Exception{
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
DataStream<String> stream = env.addSource(new SimpleStringGenerator());
stream.addSink(new FlinkKafkaProducer010<String>("test", new SimpleStringSchema(), props));
env.execute();
}
}
class SimpleStringGenerator implements SourceFunction<String>,Serializable{
private static final long serialVersionUID = 1L;
private volatile boolean isRunning = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
while(isRunning) {
String str = RandomStringUtils.randomAlphanumeric(5);
ctx.collect(str);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isRunning = false;
}
}
因为flink是生产者,这里要看结果,我们需要启动一个kafka的消费者终端,然后运行本示例:

示例中,采用了一个随机生成字符串的SourceFunction,字符串的长度是5,这里打印的字符串可以看出,长度都是5,而且是随机的,符合这个示例的运行情况。
再看第二个示例代码:
package com.xxx.flinkdemo;
import java.util.Properties;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
public class KafkaConsumerApp {
public static void main(String[] args){
try {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "flink");
DataStream<String> stream = env.addSource(new FlinkKafkaConsumer011<String>(
"test", new SimpleStringSchema(), properties) );
stream.map(new MapFunction<String, String>() {
private static final long serialVersionUID = -6867736771747690202L;
@Override
public String map(String value) throws Exception {
return "flink : " + value;
}
}).print();
env.execute("consumer");
} catch (Exception e) {
e.printStackTrace();
}
}
}
这里,flink作为消费者,要连接kafka,将FlinkKafkaConsumer011作为Source,这里面会做一个简单的映射,将kafka消息映射为"fink : xx",如果打印的消息都是flink : xx,表明运行正常。
为了测试,我们先开启一个生产者,不断往kafka中发送消息。
bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test
接着运行程序,然后再往生产者控制台输入文字并回车:

打印结果符合预期,flink与kafka结合的示例就演示完成了,主要的还是熟悉flink编程。
本文转载自: https://blog.csdn.net/feinifi/article/details/121330303
版权归原作者 luffy5459 所有, 如有侵权,请联系我们删除。
版权归原作者 luffy5459 所有, 如有侵权,请联系我们删除。