
更多优秀文章借鉴:
使用Selenium实现黑马头条滑块自动登录
使用多线程采集爬取豆瓣top250电影榜
使用Scrapy爬取去哪儿网游记数据
数据采集技术综合项目实战1:国家水稻网数据采集与分析
数据采集技术综合项目实战2:某东苹果15数据采集与分析
数据采集技术综合案例实战3:b站弹幕采集与分析
数据采集部分:
目标网址
https://www.ricedata.cn/variety/index.htm
爬虫思路分析
1.获取特殊代号: 打开目标网址,通过谷歌开发者工具,可看到各个省份以及对应的超链接的a标签,每个省份有自己对应的特殊代号(如:农业部对应’nation’),后期可通过来正则表达式来获取对应的特殊代号。

2.获取最终页:打开农业部对应的超链接,通过谷歌开发者工具可发现定位至右上角,可找到带有“调至末页”的a标签,其中的超链接即为爬取目标,(后期可通过正则表达式来获取其最终页)

3.获取发起HTTP请求目标:通过步骤1、步骤2即可获得相应城市的特殊代号以及最终页,通过字符串拼接可确定超链接目标。
from lxml import etree
import requests
import re
import pandas as pd
import ray
url = "https://www.ricedata.cn/variety/index.htm"
response = requests.get(url)
response.encoding = "utf8"
# print(html)
dom = etree.HTML(response.text)
city_names = dom.xpath("/html//table[2]//tr[4]/td/div/a//text()")
print(len(city_names))
# 获得带有数据的省的超链接(共30个)
city_hrefs = dom.xpath("/html//table[2]//tr[4]/td/div/a/@href")
city_hrefs.pop(-3)
# 获得带有数据的省名称(共30个)
nopro = ['青海','西藏','钓鱼岛','台湾','香港','澳门']
clean_list =[item.replace("\u3000",'')for item in city_names if item not in nopro]
clean_list.remove(' ')
# 以只取农业部为例子,取其首地址
content_urls = "https://www.ricedata.cn/variety/" + city_hrefs[0]
con_res = requests.get(content_urls)
con_res.encoding = "gbk"
# 对发出内容头网址获得的源代码进行解析
dom = etree.HTML(con_res.text)
last_nums = dom.xpath("/html/body/table[2]/caption/b//a[12]/@href")
# print(last_nums)
# 通过正则表达式获取最后一页(提取数字),构建最终网址以便循环
for last_num in last_nums:
last_num = re.findall('\d+',last_num)
# print(last_num),
# 通过正则表达获取城市对应特殊值
specific_value = re.findall(r'/(.*?)_',city_hrefs[0])
# 要强转为整数型变量,再字符串格式化
specific_url = ["https://www.ricedata.cn/variety/identified/{}_{}.htm".format(specific_value[0], i) for i in range(1,int(last_num[0]))]
# print(specific_url)
建立分布式爬虫框架:通过‘@ray.remote’语句即可快速建立分布式爬虫框架;使用for循环对步骤三获取到的超链接目标进行循环发起请求。
@ray.remote
# i 表示第几个省
def get_provice_data(i):
# 循环省份和翻页,获取所有数据
alldata = pd.DataFrame()
print(f"正在爬取第{i+1}个省份")
# 获取每个省份首页网址
provice_web = "https://www.ricedata.cn/variety/" + city_hrefs[i]
print("正在爬取的网站:",provice_web)
# 获取每个省份对应的特殊字符如:农业部对应的nation
specific_value = re.findall(r'/(.*?)_', city_hrefs[i])[0]
print(specific_value)
# 对获取的每个省份的首页网址发起请求
rqq = requests.get(provice_web)
rqq.encoding = 'gbk'
# 解析为HTML格式
html = etree.HTML(rqq.text)
last_nums = html.xpath("/html/body/table[2]/caption/b//a[12]/@href")
# 获取最后一页的页码, last_num为列表形式
# num = int(re.findall('\d+', last_nums[0])[0])
# 循环每一个页面
4.确定解析方法:通过谷歌开发者工具,可发现每一条内容存储在table标签的tr行标签中,使用padas库的read_html()方法即可快速爬取出每一条数据,其中data = pd.read_html(table, header=0)[0]意为将爬取将表格中第一行的内容作为DataFrame的列名(序号、品种名称等)。最后通过pandas库的pancat()方法对数据框进行拼接。
for j in range(1, num+1):
# 拼接字符串,获取所有网址
content_urls = 'https://www.ricedata.cn/variety/identified/{}_{}.htm'.format(specific_value,j)
print(content_urls)
content_response = requests.get(content_urls)
content_response.encoding = 'gbk'
con_html = etree.HTML(content_response.text)
# 把html文件转为字符串
table = etree.tostring(con_html)
# 通过pd.read_html()方法读取表格
# header = 0:表示将表格中的第一行作为列名。这意味着在提取数据时,会将表格中第一行的内容作为DataFrame的列名
data = pd.read_html(table, header=0)[0]
# 添加省份名称
data['省份'] = clean_list[i]
# 使用panda的concat()拼接方法把每个表格拼接在一起
alldata = pd.concat([alldata, data])
return alldata
5.初始化分布式计算框架:确定分配的cpu个数,将逐个获取到的数据框进行全拼接,并以第一个的数据框的第一行作为全数据框的第一行,最后将数据框保存为csv文件即可。
# 对分布式爬虫设置参数
# 前者为cpu个数,后者表示如果 Ray 已经被初始化过了,就忽略重新初始化的错误
ray.init(num_cpus=6, ignore_reinit_error=True)
# 传给函数的参数,既省份;这行代码使用 Ray 分布式计算框架来并行地获取 xx 个省份的数据
settings = [get_provice_data.remote(x) for x in range(31)]
# 结果中每个列表即为每个省份的数据
results = ray.get(settings)
len(results)
# 创建一个空的 DataFrame ricedata,列名由 results[0] 的列名决定。这样可以保证 ricedata 的列名与后续要合并的 DataFrame 一致
ricedata = pd.DataFrame(columns=results[0].columns)
for i in range(len(results)):
ricedata = pd.concat([ricedata, results[i]])
# 数据保存
ricedata.to_csv('data.csv', index=None, encoding='gbk')
结果演示

数据预处理部分:
确定处理需求
将’?’数据、’/’数据、重复数据、空数据等脏数据进行处理,提取出干净数据。
清洗步骤
1.清洗脏数据:将数据采集部分的步骤5所保存data.csv文件的通过pandas库的read_csv()方法进行读取,被赋值到的变量主要使用两个方法这里主要用到padas库的drop_duplicates()方法(去除括号内的某列重复值)、isna()方法(当括号内的值为‘True’时,即取出括号内的值;换言之,当括号内的值为’False’时,即取出不包含的括号内的其他值)。对于本例中的母本、审定公司可通过字符串分割、正则表达式等方法提取出干净数据;最后将新的csv文件进行保存。
import pandas as pd
import re
# 读取数据
rice_data = pd.read_csv("./data.csv",encoding = "gbk")
rice_data = rice_data[(rice_data['亲本来源("×"前为母本)'].isin(['?'])==False)|(rice_data['审定编号'].isin(['/'])==False)]
# 删除重复数据
rice_data = rice_data.drop_duplicates(subset=['品种名称', '审定编号'])
# (6)提取水稻母本
rice_data['母本'] = [i.split('×')[0] for i in rice_data['亲本来源("×"前为母本)']]
rice_data['母本'].value_counts()
# (7)提取审定方:中文
rice_data['审定方'] = [re.findall('[\u4e00-\u9fa5]{2,}', i) for i in rice_data['审定编号']]
# 函数,处理空字符
# lambda函数是一种匿名函数,也称为内联函数或者函数字面量。它允许你在代码中快速定义简单的函数,而不需要使用def关键字来定义一个函数。
# 如果x的长度大于等于1,并且x的第一个元素以'第'开头,那么将第一个元素中的'第'替换为空字符串,并返回结果。如果x的长度小于1,或者第一个元素不以'第'开头,则返回'-'。
strfunc = lambda x:x[0].replace('第', '')if len(x)>=1 else '-'
# apply是DataFrame中的一个方法,用于对DataFrame中的某一列(Series)应用指定的函数
# DataFrame的名为'审定方'的列上的每个元素。这意味着对于'审定方'列中的每个元素,都会调用strfunc函数来处理。
rice_data['审定方'] = rice_data['审定方'].apply(strfunc)
# 审定公司、选育单位
rice_data.columns
rice_data['审定公司'] = rice_data['原产地/选育单位'].str.replace('等', '')
# 数据保存
rice_data.to_csv('data2.csv', index=None, encoding='gbk')
2.查看清洗后的数据:通过value_counts()方法来查看该列中的元素出现了几次,则可看见是否仍有脏数据未被清洗干净;通过shape()方法即可观察清洗后的数据框剩余几行数据;通过columns()方法可看出清洗后的数据框的列索引。
# (2)异常值
# 数据类型基本为字符串类型,统计每列的类别属性(以下列三种为例)
rice_data["品种名称"].value_counts()
rice_data['亲本来源("×"前为母本)'].value_counts()
rice_data["类型"].value_counts()
rice_data.shape
rice_data.columns
数据可视化部分
以生成堆叠型的柱状图为例
1.将干净数据的csv文件进行读取,统计出不同的审定方对应的数量以及不同的品种数量并排序方便观察。
import pandas as pd
import matplotlib.pyplot as plt
# 设置绘图参数
# 指定了 Matplotlib 使用的字体为宋体(SimSun),即 'simHei'。这样设置可以确保在绘制图表时使用宋体字体显示中文文本,避免中文显示乱码的问题。
plt.rcParams['font.sans-serif'] = 'simHei'
# 设置了 Matplotlib 绘图时坐标轴上的负号显示为正常的减号。在某些情况下,默认设置下负号可能显示不正确,通过将该参数设置为 False,可以确保负号显示正确。
plt.rcParams['axes.unicode_minus'] = False
# 读取数据
ricedata = pd.read_csv('data2.csv', encoding='gbk')
2.统计出审定数量超过平均审定数量的审定方并选择出排名前四数量的水稻品种。
# 主要水稻类型在每个省定方的统计情况
# (1).审定数量大于均值的审定方
departments_mean = departments[departments > departments.mean()].index
# (2).排名前4的水稻类型
rice_type_4 = rice_type[:4].index
# (3).统计数量
# 'isin' 这个方法通常用于筛选DataFrame中符合某些条件的行(是否在括号中的列表内),可以结合布尔索引来实现数据的过滤和选择操作
rice_type_filter = ricedata[(ricedata['审定方'].isin(departments_mean)) & (ricedata['类型'].isin(rice_type_4))]
3.通过padas库的crosstab()函数创建交叉表的函数,可以用来计算两个或多个变量之间的交叉频数。
rice_data_cro = pd.crosstab(rice_type_filter['审定方'], rice_type_filter['类型'])
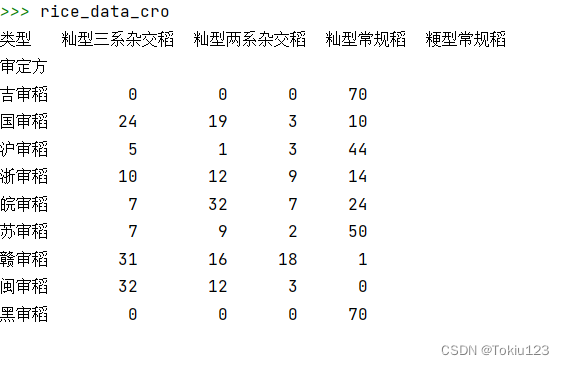
4.通过步骤3可看出所显示的数据类似一个二维矩阵,通过for循环即可获得获得某个审定方对应的品种的个数。再通过在图中添加一个图例,并显示 rice_data_cro 数据框中的列名作为标签,方便读者理解不同颜色的含义。最后通过show()方法来显示数据图表。
# 4.绘制堆叠的柱形图
for i in range(0, 4):
# [:, i]表示对二维数组或矩阵进行切片操作,其中逗号前面的部分表示对行进行切片,逗号后面的部分表示对列进行切片。在这种情况下,:表示选择所有行,而i表示选择第i列。
# 例如,如果有一个二维数组arr,arr[:, 2]表示选择arr中所有行的第3列数据(Python中索引从0开始)
# 例如,如果有一个二维数组arr,arr[:, :3]表示选择arr中所有行的第0列到第2列(Python中索引从0开始,所以3实际上是第4列)的数据。
plt.bar(x = rice_data_cro.index, height = rice_data_cro.iloc[:, i], bottom = rice_data_cro.iloc[:, :i].sum(axis = 1))
plt.legend(rice_data_cro.columns) #图例
plt.xlabel("审定方")
plt.ylabel("审定数量")
# x坐标上倾斜度为30
plt.xticks(rotation = 30)
plt.show()
结果演示

注意:因篇幅有限,部分源代码无法展示;需要源代码请私聊博主哦~
创作不易,请点个赞哦~
版权归原作者 Tokiu123 所有, 如有侵权,请联系我们删除。