
1.1 什么是图像分类?
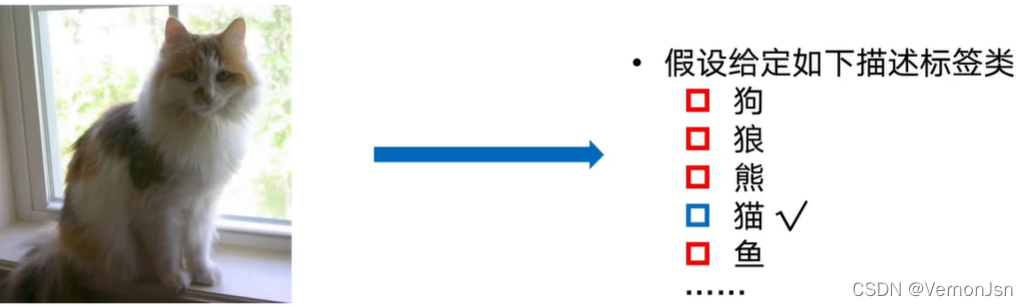
图像分类,根据图像信息中所反映出来的不同特征,把不同类别的目标区分开来的图像处理方法
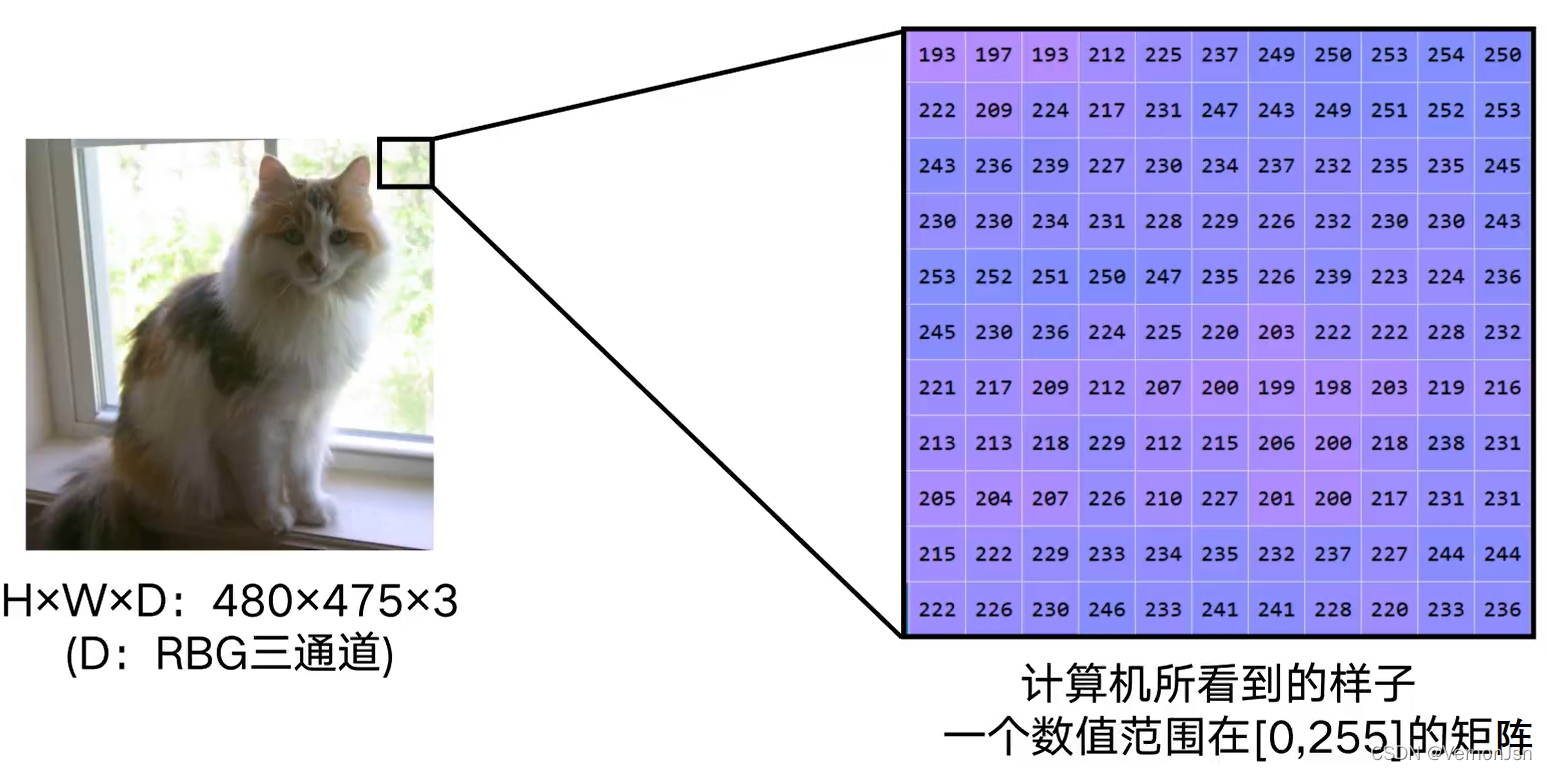
1.2 图像分类的难度
●任何拍摄情 况的改变都将提升分类的难度
1.3 CNN如何进行图像分类
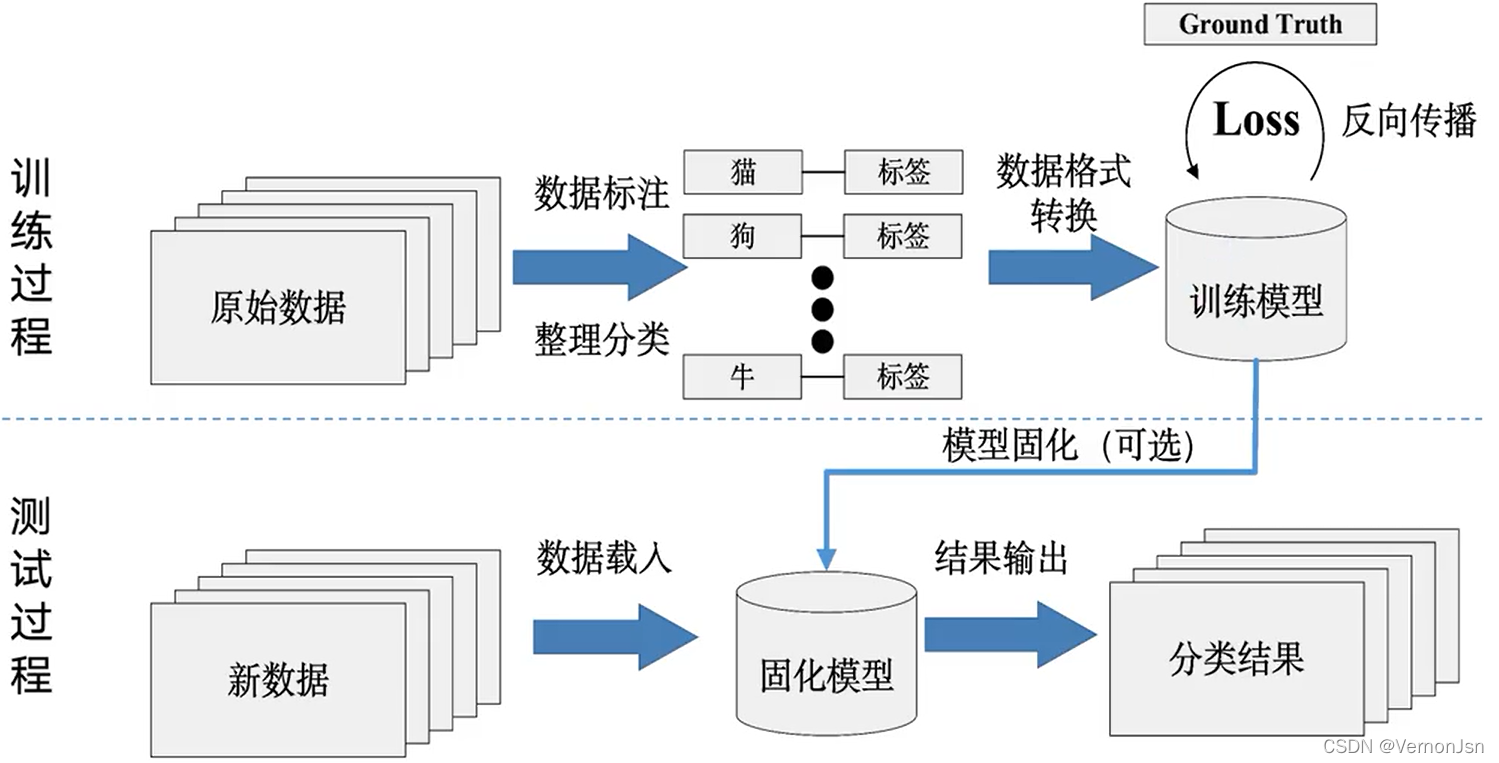
●数据驱动型方法通用流程
1.收集图像以及对应的标签,形成数据集
2.使用机器学习训练一个分类器
3.在新的图像.上测试这个分类器

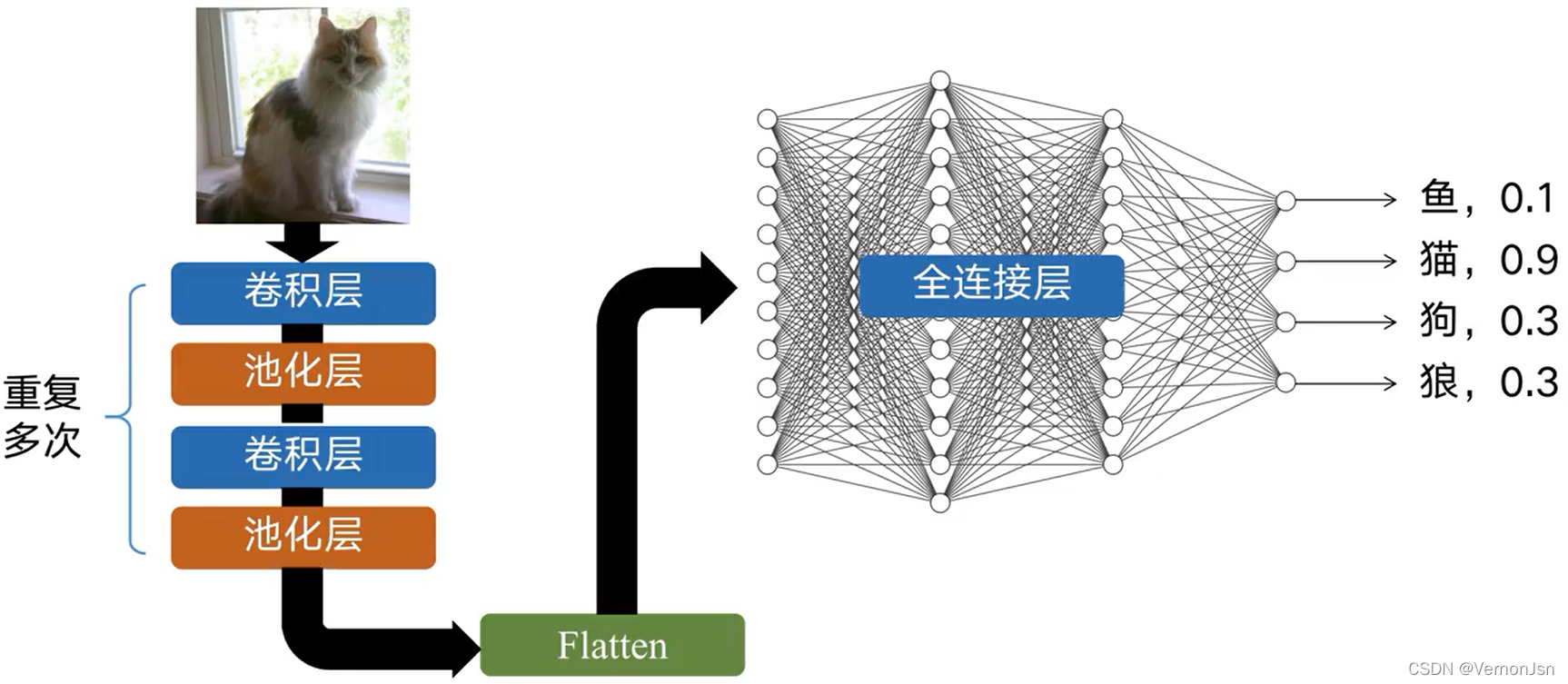
1.4 图像分类指标

精确率:查得准不准? 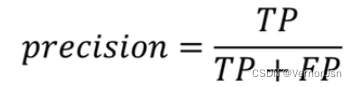
召回率:查得全不全? 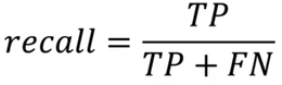
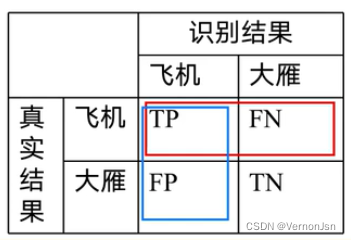
True positives (TP):飞机的图片被正确的识别成了飞机。
True negatives (TN): 大雁的图片没有被识别出来,系统正确地认为它们是大雁。
False positives (FP):大雁的图片被错误地识别成了飞机。
False negatives (FN):飞机的图片没有被识别出来,系统错误地认为它们是大雁。
True negatives (TN): 4,四个大雁 False negatives (FN): 2,二个飞机
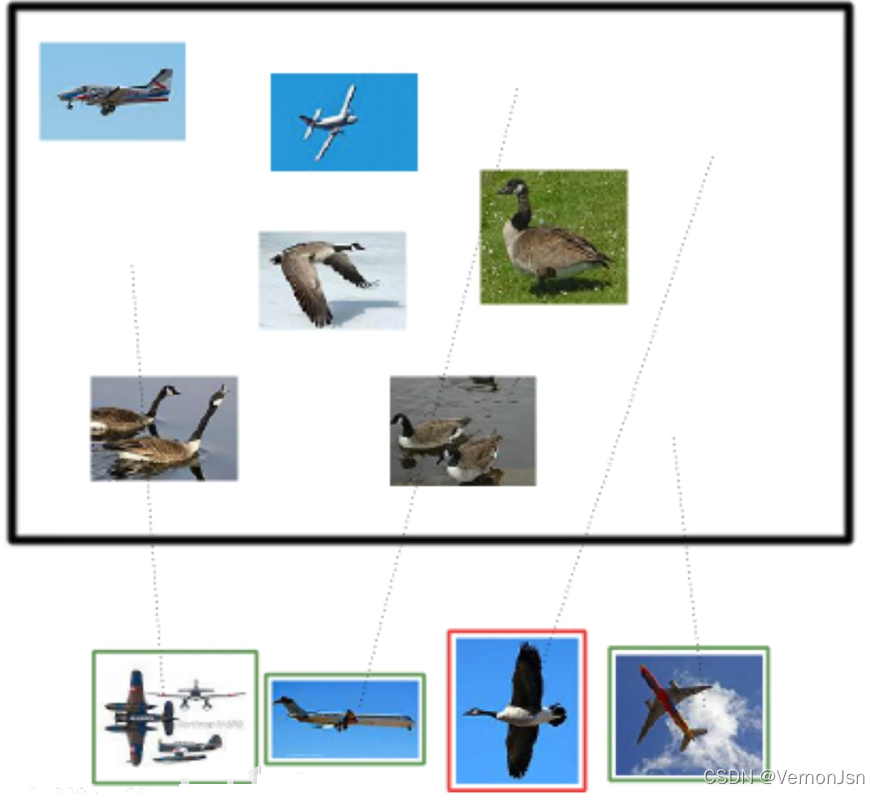
True positives (TP): 3,绿框. False positives (FP): 1,红框,
准确率:
平均精确度( Average Precision,AP) :PR曲线下的面积,这里的average,等于是对precision进行取平均。
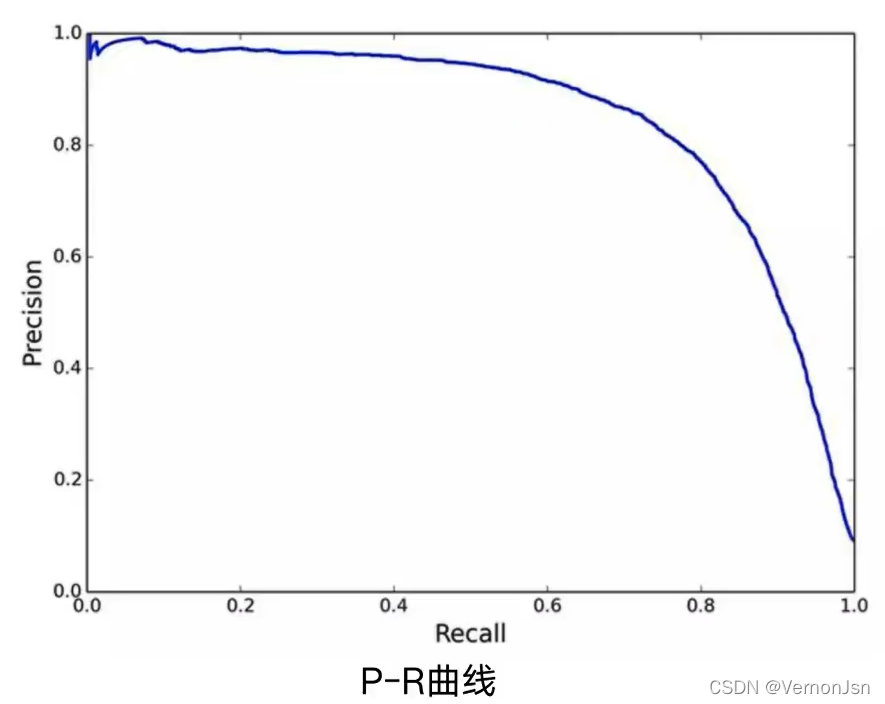
1.5 经典CNN网络性能演化
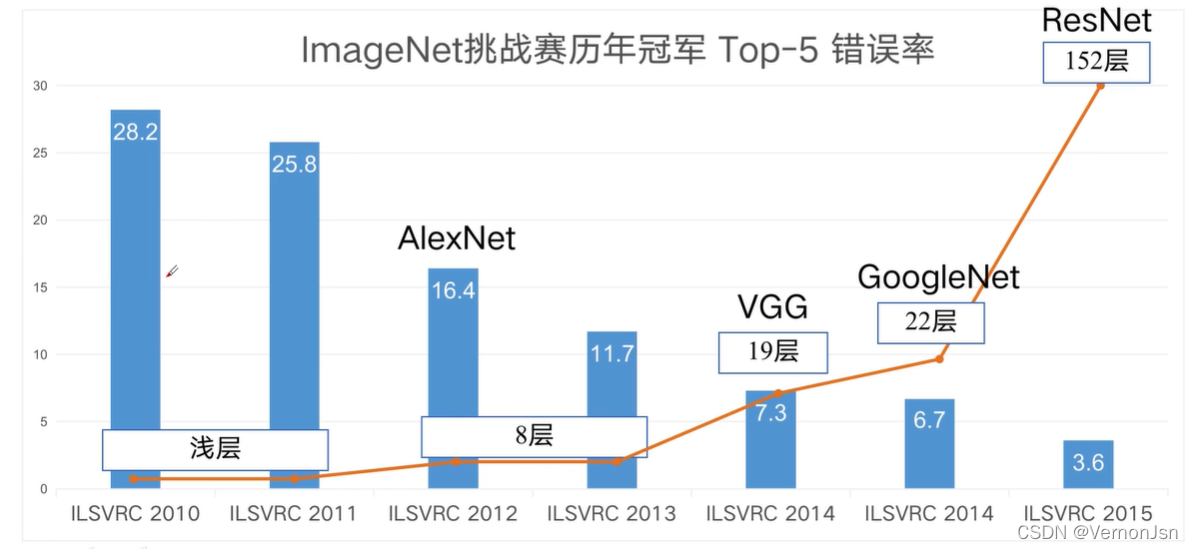 2 GoogleNet
2 GoogleNet
2.1 深度网络有什么好处?
1.丰富了低、中、高等级的特征
边缘、纹理、形状、颜色.....高纬度的人类无法理解的特征
2.越深、越宽的网络具有越强的表达能力
- 日有学者证明,一个宽度为K、深度为H的网络,能够产生至少
条线段
- 线段越多,拟合得越准确
- 因此,网络加宽、加深可以提升性能,并且加深效果比加宽好:

2.2 如何设计一个卷积层?
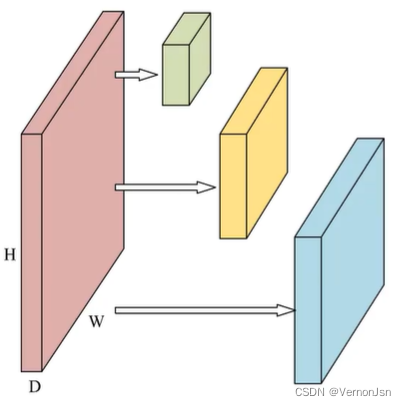
●选择什么样的层(Layer ) ?
3x3卷积核
5X5卷积核
池化层( Pooling Layer )
2.2.1 感受层
在卷积神经网络中,感受野( Receptive Field )的定义是卷积神经网络每- -层输出的特征图.上的像素点在输入图片.上映射的区域大小。换句话说,感受野是特征图上的一个点对应输入图上的区域。
- 假设两个卷积层的卷积核尺寸都为2x2,步长都为1,输入为4x4
- 经过两次卷积后,特征图的尺寸分别为3x3和2x2
- 对于特征图2的左上角像素点,它在特征图1上的感受范围为左上方的2x2区域,而此区域在输入。上的感受范围是左,上方的3x3区域,因此,感受野尺寸为3x3。
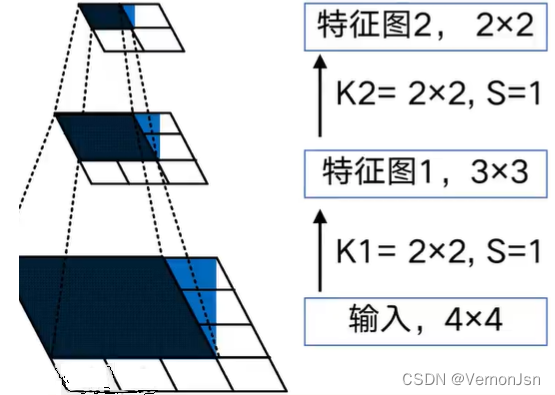
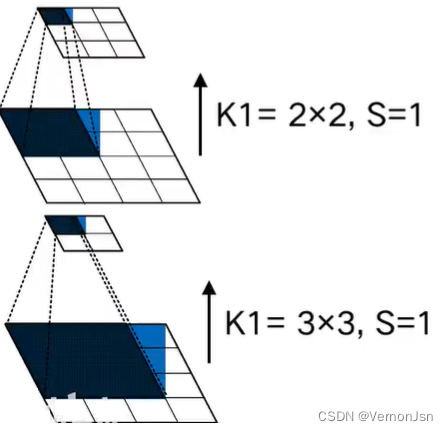
- 日越深层的特征图, 感受野越大
- 对同层而言,卷积核尺寸越大,感受野越大
- 大的感受野对大的物体更敏感,反之,小的感受野对小的物体更敏感
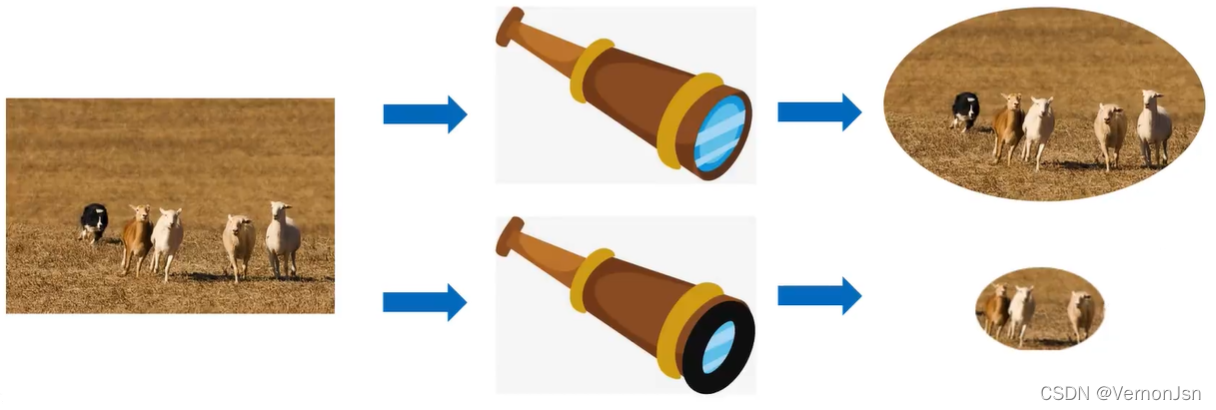
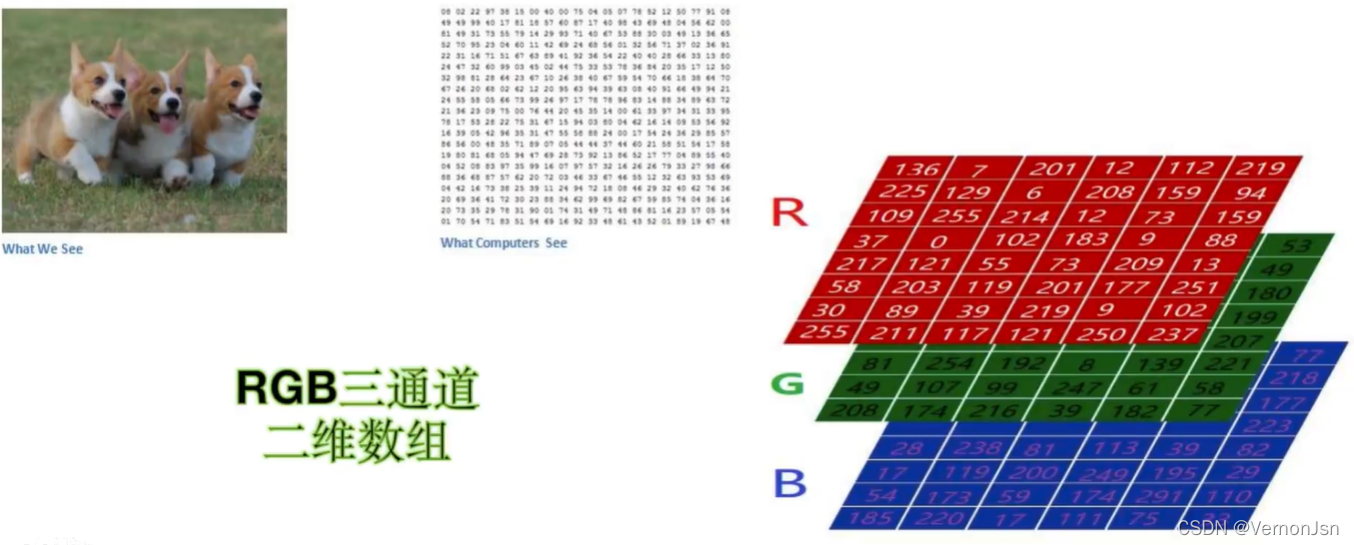
猫可以在图片里有大有小,可以在图片的局部,也可以整张图片都是;对一张图片而言,至少有RGB三个通道,如果这几多个卷积核则会导致计算量过大。
2.2.2 如何降低计算量——1x1卷积核
1 x 1卷积做了什么?
它在深度( Depth). 上进行了融合深度为D的输入经过一-个1 x 1卷积核,得到深度为1的输出(S=1, P=0);同理,尺寸为DxHxW的输入,经过D/2个1 X 1卷积核,将会得到D/2xHxW的输出(S=1,P=0);最终,在不损失太多信息的情况下,对输入进行了降维。
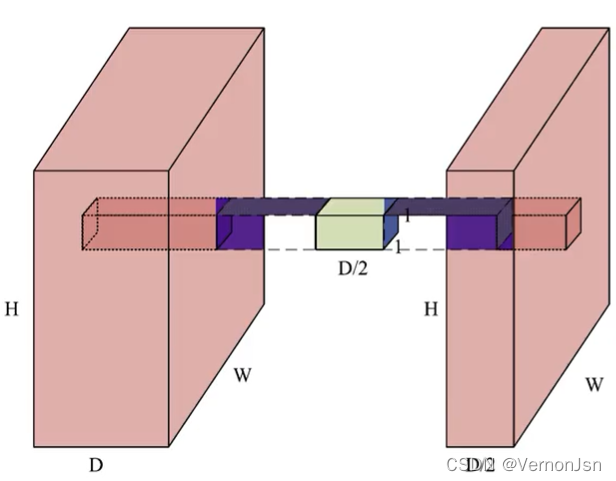
小结:1X1的卷积是--个非常优秀的结构它可以跨通道组织信息提高网络的表达能力,同时可以对输出通道升维和降维。[想象一下:两片面包压缩成一-片的宽度又或者加点膨化剂,膨胀成4片的宽度]
2.3 Inception模块
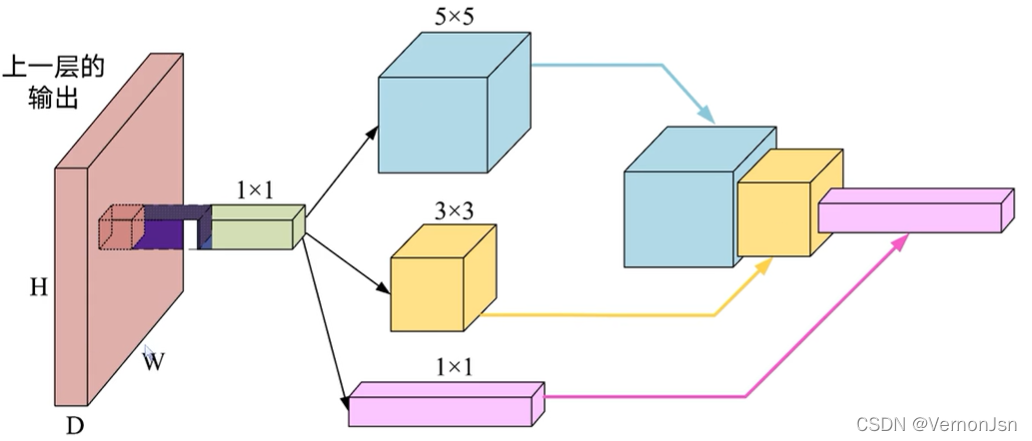
- 在1x1卷积后,添加不同的卷积分支
- 实现同一卷积层的多尺度特征提取与融合
2.4 整体网络结构
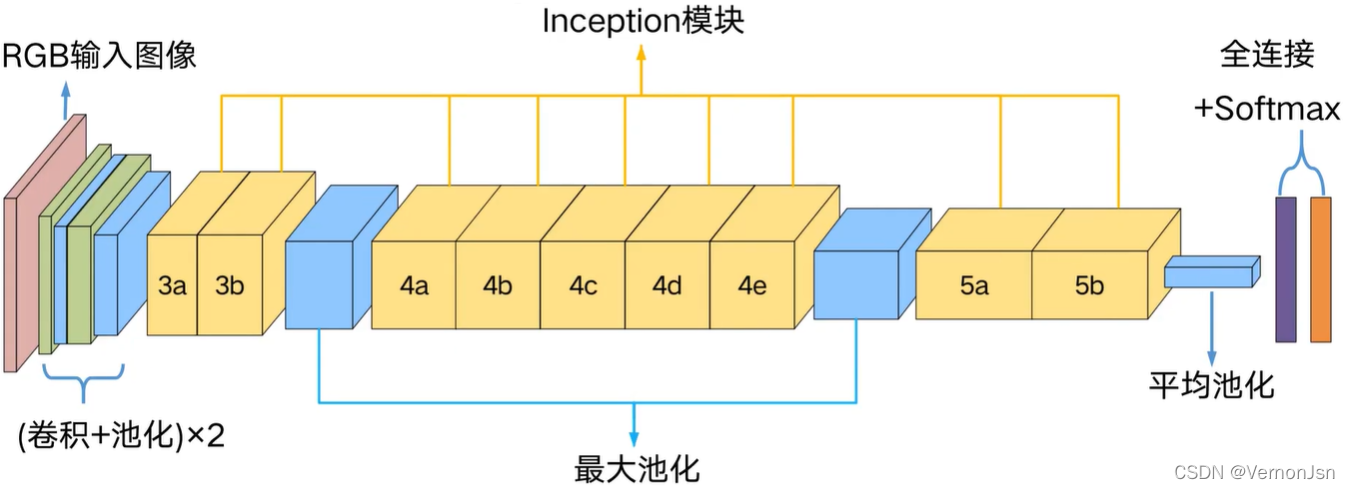
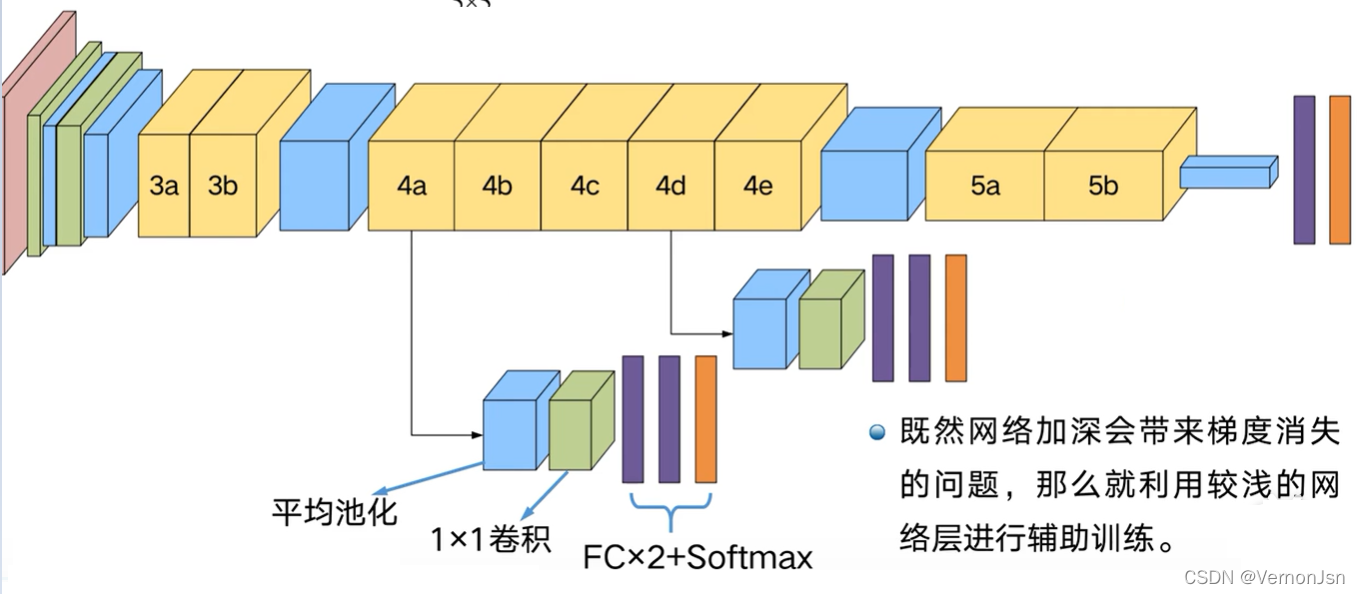
一个潜在的问题
➢在较深的网络中进行反向传播可能会出现“梯度消失”,导致训练无法继续进行一种解决方案
➢网络的中间层具有很高的判别能力 ➢在这些中间层增加辅助分类器 ➢在训练中,这些中间层分类器得到的L .oss以0.3的权重加到最终Loss
3 GoogleNet的keras实现
3.0 猫狗大战
本次实战采用的数据集来自kaggle . 上的一一个竞赛: Dogs Vs. Cats
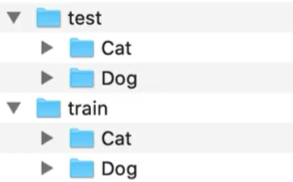


3.1 图像读取一图像增 强-图像生成器
数据增强策略
●翻转变换(lip):沿着水平或者垂直方向翻转图像;
●缩放变换(zoom):按照一定的比例放大或者缩小图像;
●平移变换(shift):在图像平面上对图像以一定方式进行平移;
●可以采用随机或人为定义的方式指定平移范围和平移步长,沿水平或竖直方向进行平移.图像内容的位置
●尺度变换(scale):对图像按照指定的尺度因子,进行放大或缩小;或者参照SIFT特征提取思想,利用指定的尺度因子对图像滤波构造尺度空间.改变图像内容的大小或模糊程度;
●对比度变换(contrast):在图像的HSV颜色空间,改变饱和度S和V亮度分量,保持色调H不变.对每个像素的S和V分量进行指数运算(指数因子在0.25到4之间),增加光照变化;
●噪声扰动(noise):对图像的每个像素RGB进行随机扰动,常用的噪声模式是椒盐噪声和高斯噪声;
代码如下:
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
from PIL import Image
import matplotlib.pyplot as plt
%matplotlib inline
train_dir="train" #训练集路径
test_dir="test"
#测试集路径
IM_WIDTH=224 #图像宽度
IM_HEIGHT=224 #图像高度
batch_size=32
#定义训练和测试的图像生成器
#train and val data
train_val_datagen = ImageDataGenerator (rotation_range=30,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
z0om_range=0.2,
horizontal_flip=True,
validation__split=0.1) #划分出验证集
#test data
test_datagen=ImageDataGenerator() #测试集就不用数据增强了
#训练集图像生成器
train_generator=train_val_datagen.flow_from_directory(train_dir,
target_size=(IM_WIDTH,IM_HEIGHT), #将目标图片缩放多大的尺寸
batch_size=batch_size, #分批次抽取
subset='training')
#验证集图像生成器
vaild_generator=train_val_datagen.flow_from_directory(train_dir,
target_size=(IM_WIDTH,IM_HEIGHT),
batch_size=batch_size,
subset='validation')
#测试集图像生成器
test_generator=test_datagen.flow_from_directory(test_dir,
target__size=(IM_WIDTH,IM_HEIGHT),
batch_size=batch_size,)
#验证图片生成器的效果,选取生成器的下一个图片并打印出来
samples_batch=train_generator.next()
print(samples_batch[0].shape)#第0位保存的是图像
print(samples_batch[1].shape)#第1位保存的是标签
#显示一张图片
fig1=samples_batch[0][0]
r=Image.fromarray(fig1[:,:,0]).convert('L')#读第0个通道内的值,转为灰度值
g=Image.fromarray(fig1[:,:,1]).convert('L')
b=Image.fromarray(fig1[:,:,2]).convert('L')
image=Image.merge("RGB",(r,g,b))#RGB合并起来
plt.imshow(image)
plt.show()
print(samples_batch[1][0])#打印标签——热编码
运行结果:

3.2 自定义图像生成器
#自定义训练集生成器
def myTrainDataGenerator():
while True:
trainDataBatch=train_generator.next() #取出一个批次的数据
images=trainDataBatch[0] #取图像
labels= [trainDataBatch[1] , trainDataBatch[1] , trainDataBatch[1]]#取标签
yield images, labels
#自定义验证集生成器
def myVaildDataGenerator():
while True:
vaildDataBatch=vaild_generator.next() #取出一个批次的数据
images=vaildDataBatch[0] #取图像
labels= [vaildDataBatch[1] , vaildDataBatch[1] , vaildDataBatch[1]]#取标签
yield images, labels
#自定义测试集生成器
def myTestDataGenerator():
while True:
testDataBatch=test_generator.next() #取出一个批次的数据
images=testDataBatch[0] #取图像
labels= [testDataBatch[1] , testDataBatch[1] , testDataBatch[1]]#取标签
yield images, labels
my_train_generator=myTrainDataGenerator()
my_vaild_generator=myVaildDataGenerator()
my_test_generator=myTestDataGenerator()
a=my_train_generator.__next__()
#显示一张图片
fig1=a[0][0]
r=Image.fromarray(fig1[:,:,0]).convert('L')#读第0个通道内的值,转为灰度值
g=Image.fromarray(fig1[:,:,1]).convert('L')
b=Image.fromarray(fig1[:,:,2]).convert('L')
image=Image.merge("RGB",(r,g,b))#RGB合并起来
plt.imshow(image)
plt.show()
print(samples_batch[1][0][0])
3.3 模型实现
#导入需要使用的包
from keras.models import Model
from keras.layers import Input , Dense, Dropout , BatchNormalization, Conv2D , MaxPool2D , AveragePooling2D, concatenate, Flatten
from keras.layers.convolutional import Conv2D ,MaxPooling2D, AveragePooling2D
from keras.callbacks import ReduceLROnPlateau,ModelCheckpoint , EarlyStopping
from keras.preprocessing.image import ImageDataGenerator
from keras.models import load_model
from keras.preprocessing.image import ImageDataGenerator
from PIL import Image
#若需要复现,可以把随机数固定下来
seed=42
np.random.seed(seed)
#卷积+BN
def Conv2d_BN(prev_layer, #卷积前一层网络
filters, #卷积核数量
kernel_size, #卷积核大小
padding='same', #‘sanme'指卷积填充是大小保持不小
strides=(1,1) , #步长
name=None #名字
):
if name is not None:
bn_name = name+'_bn'
conv_name = name +'_conv'
else:
bn_name = None
conv_name = None
x = Conv2D(filters, kernel_size, padding=padding,strides=strides , activation='relu',name=conv_name) (prev_layer) #2D图像卷积参数
x = BatchNormalization(axis=3, name=bn_name)(x) #批次归一化,- -种标准化操作,防止过拟合的手段
return x
#inception模块
def inception_block(prev_layer, num_filters, name, use_whistle = False, numclasses = -1):
#num_filters: [b0,(b11, b12)。(b21,b22)。 b3] 代表不同分支的通道数,即卷积核个数
#use_ whistle:是否要输出辅助分类器
#1x1卷积分支
branch0=Conv2d_BN(prev_layer=prev_layer,filters=num_filters[0],kernel_size=(1,1),name=name+'-br0-1x1')
#3x3卷积分支,1x1-3x3
branch1=Conv2d_BN(prev_layer=prev_layer,filters=num_filters[1][0],kernel__size=(1,1),name=name+'-br1-1x1')
branch1=Conv2d_BN(prev__layer=branch1,filters=num_filters[1][1],kernel_size=(3,3),name=name+'-br1-3x3')
#5x5卷积分支,1x1-5x5
branch2=Conv2d_BN(prev__layer=prev_layer,filters=num_filters[2][0],kernel_size=(1,1),name=name+'-br2-1x1')
branch2=Conv2d_BN(prev_layer=branch2,filters=num_filters[2][1],kernelsize=(5,5),name=name+'-br2-5x5')
#池化分支
branch3=MaxPool2D(pool_size=(3,3),strides=(1,1),padding='same',name=name+'-br3-pooL')(prev_layer)
branch3=Conv2d_BN(branch3,filters=num_filters[3],kernel__size=(1,1),name=name+'-br3-1x1')
#融合
x = concatenate([branch0, branch1, branch2, branch3], axis = 3,name = name)
#是否输出辅助分类器
if(use_whistle):
out = aux_whistle(prev_layer, numclasses = numclasses, name = name + '-whistle')
return x,out
return x
#辅助分类器
def aux_whistle(prev_layer,numclasses,name):
aux_clf=AveragePooling2D(pool_size=(5,5),strides=(3,3),name=name+'-averagePool')(prev_layer) #池化
aux_clf=Conv2d_BN(aux_clf,filters=128,kernel__size=(1,1),name=name+'-1x1conv') #卷积
aux_clf=Flatten(name=name+'-flatten')(aux_clf)
aux_clf=Dense(1024,activation='relu')(aux_clf) #全连接
aux_clf=Dropout(0.3,name=name+'-dropout')(aux_clf)
aux_clf=Dense(num_classes,activation='softmax',name=name+'-predictions')(aux_clf)
return aux_clf
def inceptionNet(input_shape,numclasses):
inp=Input(shape=input_shape)
#「卷积+池化」x2
x=Conv2d_BN(inp,filters=64,kernel_size=(7,7),strides=(2,2),name='2a')
x=MaxPool2D(poolsize=(3,3),strides=(2,2),padding='same',name='2pool-1')(x)
x=Conv2d_BN(x,filters=192,kernel_size=(3,3),name='2b')
x=MaxPool2D(pool__size=(3,3),strides=(2,2),padding='same',name='2pool-2')(x)
#第-Inception模块组,3a.3b
x=inception_block(x,(64,(96,128),(16,32),32),name='inception3a')
x=inception_block(x,(128,(128,192),(32,96),64),name='inception3b')
x=MaxPoo12D(pool_size=(3,3),strides=(2,2),padding='same',name='3pool')(x)
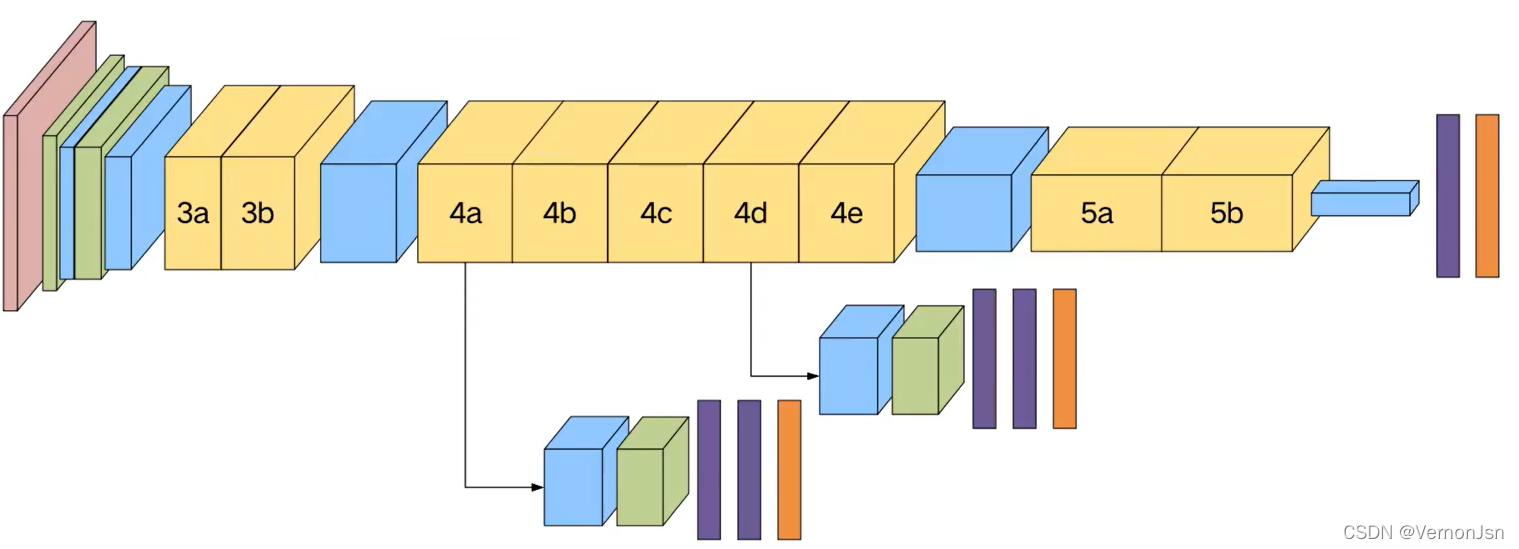
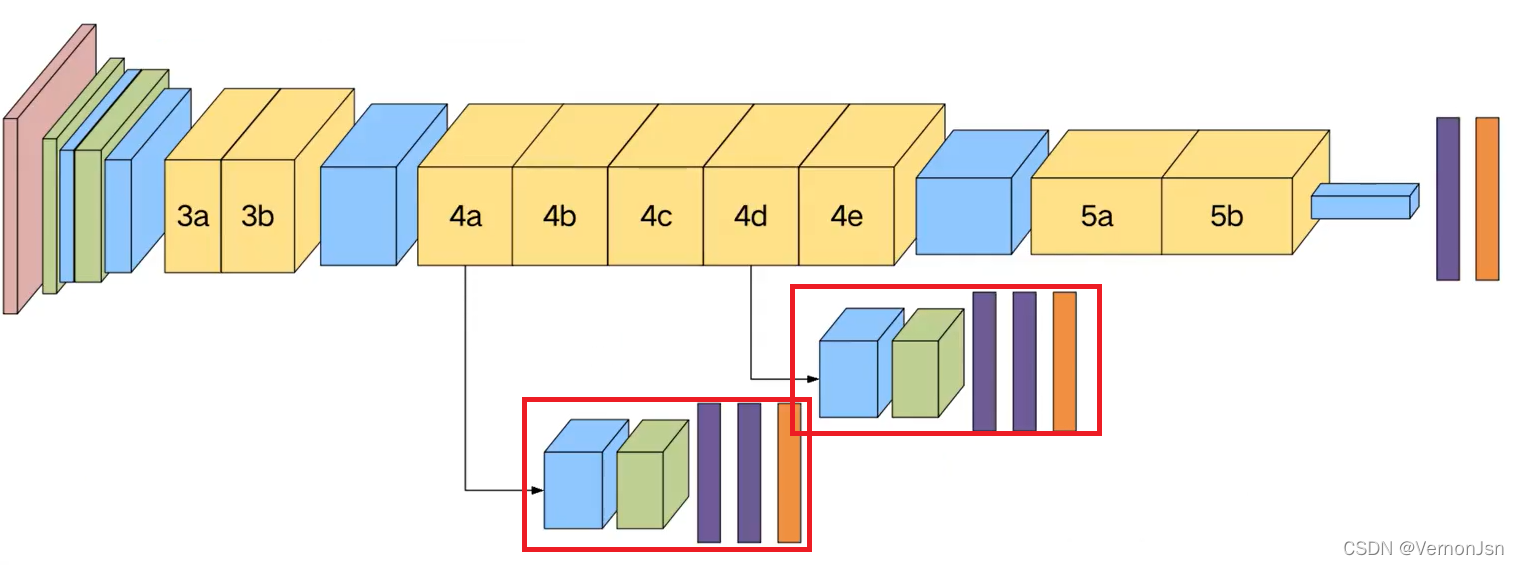
#第二Inception模块组,4a、4b(辅助)、4c.4d(辅助)、4e
x=inception_block(x,(192,(96,208),(16,48),64),name='inception4a')
x,whistle1=inception_block(x,(160,(112,224),(24,64),64),name='inception4b',use_whistle=True,numclasses=numclasses)
x=inception_block(x,(128,(128,256),(24,64),64),name='inception4c')
x,whistle2=inception_block(x,(112,(144,288),(32,64),64),name='inception4d',use_whistle=True,numclasses=numclasses)
x=inception_block(x,(256,(160,320),(32,128),128),name='inception4e')
x=MaxPool2D(poolsize=(3,3),strides=(2,2),padding='same',name='4pool')(x)
#第三Inception模块组,5a.5b
x=inception_block(x,(256,(160,320),(32,128),128),name='inception5a')
x=inception_block(x,(384,(192,384),(48,128),128),name='inception5b')
#全局平均池化
x=AveragePooling2D(pool_size=(7,7),strides=(1,1),padding='valid',name='avg7x7')(x)
#X=Dropout(0.4)(x)
# FC+Softmax分类
x = Flatten (name='flatten')(x)
x = Dense(numclasses, activation= 'softmax',name= 'predictions')(x)
model = Model( inp, [x, whistle1,whistle2] ,name=' inception_v1')
return model
3.4 模型编译
num_classes=len(train_generator.classindices) #获取类别数
model=inceptionNet(input_shape=(224,224,3),numclasses=num_classes)#获取model对象
model.compile(optimizer='adam', #优化器
loss='categorical_crossentropy', #损失函数
loss_weights=[1.0,0.3,0.3], #损失函数权重
metrics=['accuracy']) #评价标准(错误率),如果要用top-k:['accuracy',metric.top_k__categorical_accuracy]
model.summary()#打印出模型概述信息
3.5 模型训练
EPOCH=10 #一个Epoch代表遍历- -次所有数据
batch_size=32 #一 个批次内的图片数量
modelfilepath='model.best.hdf5' #保存路劲
#无法更优则自动终止
earlyStop=EarlyStopping(monitor='val_predictions__acc',
patience=30,
verbose=1,
mode='auto')
#保存最好的模型
checkpoint=ModelCheckpoint(modelfilepath,
monitor='val_predictions__acc',
verbose=1,
save__best_only=True,
mode='max')
#根据不同阶段,降低学习率
reduce_Ir=ReduceLROnPlateau(monitor='val_predictions_loss',
factor=0.1,
patience=10,
verbose=1,
mode='auto',
min_delta=0.00001,
C0oldown=0,
min__lr=0)
history=model.fit_generator(my_train_generator,validation_data=my_vaild_generator,epochs=EPOCH,steps_per_epoch=train_generator.n/batch_size
,validation_steps=vaild_generator.n/batch_size,callbacks=[checkpoint,reduce_lr,earlyStop])
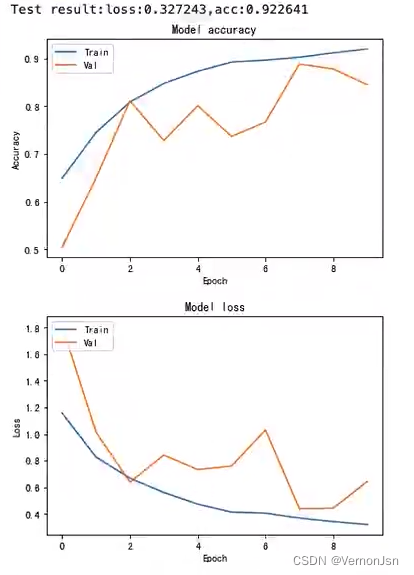
训练结果:

3.6 模型测试
#=====模型测试=========
testmodel=load_model (modelfilepath)
loss,predictions_loss,aux1_loss, aux2_loss, predictions_acc,aux1_acc, aux2_acc=testmodel. evaluate_generator(my_test_generator,steps=test_generator.n/batch_size)
#绘制训练&验证的准确率值
plt.plot(history.history['predictions_acc'])
plt.plot(history.history['val_predictions_acc'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train','Val'],loc='upper left')
plt.show()
#绘制训练&验证的损失值
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train','Val'],loc='upper left')
plt.show()
测试结果:
版权归原作者 VernonJsn 所有, 如有侵权,请联系我们删除。